hadoop3.0高可用HA配置详解
hadoop3.0高可用HA大数据平台架构硬件和部署方案(一)
http://blog.csdn.net/lxb1022/article/details/78389836
hadoop3.0高可用HA大数据平台架构软件和部署方案(二)
http://blog.csdn.net/lxb1022/article/details/78399462
1.到官网下载hadoop-3.0.0-beta1.tar.gz
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.0.0-beta1/hadoop-3.0.0-beta1.tar.gz
2、解压到安装目录/opt/,并配置环境变量:vi /etc/profile
tar -zxvf hadoop-3.0.0-beta1.tar.gz
#set java env
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/rt.jar
#set hadoop env
export HADOOP_HOME=/opt/hadoop-3.0.0-beta1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin3、配置:/opt/hadoop-3.0.0-beta1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_144
export HADOOP_HOME=/opt/hadoop-3.0.0-beta14.配置:/opt/hadoop-3.0.0-beta1/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://mycluster
mycluster唯一标识hdfs实例的nameservice ID的名称
hadoop.tmp.dir
file:///opt/hadoop-3.0.0-beta1/tmp
指定hadoop临时目录
ha.zookeeper.quorum
zookeeper1:2181,zookeeper2:2181,zookeeper:2181
指定zookeeper地址
5、配置:/opt/hadoop-3.0.0-beta1/etc/hadoop/hdfs-site.xml
dfs.nameservices
mycluster
指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致
dfs.ha.namenodes.mycluster
nn1,nn2
mycluster下面有两个NameNode,分别是nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
namenode1:9000
nn1的RPC通信地址
dfs.namenode.rpc-address.mycluster.nn2
namenode2:9000
nn2的RPC通信地址
dfs.namenode.http-address.mycluster.nn1
namenode1:50070
nn1的http通信地址
dfs.namenode.http-address.mycluster.nn2
namenode2:50070
nn2的http通信地址
dfs.namenode.shared.edits.dir
qjournal://zookeeper1:8485;zookeeper2:8485;zookeeper:8485/mycluster
指定NameNode的元数据在JournalNode上的存放位置
dfs.journalnode.edits.dir
/opt/hadoop-3.0.0-beta1/journal
新建目录,用于设置journalnode节点保存本地状态的目录,指定journalnode日志文件存储的路径
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置失败自动切换实现方式,指定HDFS客户端连接active namenode的java类
dfs.ha.fencing.methods
sshfence
配置隔离机制为ssh
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
使用隔离机制时需要ssh免密码登陆,指定秘钥的位置
dfs.ha.automatic-failover.enabled
true
指定支持高可用自动切换机制,开启自动故障转移
ha.zookeeper.quorum
zookeeper1:2181,zookeeper2:2181,zookeeper:2181
指定zookeeper地址
dfs.replication
3
指定数据冗余份数
dfs.namenode.name.dir
file:///opt/hadoop-3.0.0-beta1/name
新建name文件夹,指定namenode名称空间的存储地址
dfs.datanode.data.dir
file:///opt/hadoop-3.0.0-beta1/data
新建data文件夹,指定datanode数据存储地址
dfs.webhdfs.enabled
ture
指定可以通过web访问hdfs目录
6、配置:/opt/hadoop-3.0.0-beta1/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
/opt/hadoop-3.0.0-beta1/etc/hadoop,
/opt/hadoop-3.0.0-beta1/share/hadoop/common/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/common/lib/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/hdfs/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/mapreduce/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/yarn/*,
/opt/hadoop-3.0.0-beta1/share/hadoop/yarn/lib/*
7、配置:/opt/hadoop-3.0.0-beta1/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce
yarn.resourcemanager.ha.enabled
true
开启YARN HA
yarn.resourcemanager.ha.automatic-failover.enabled
true
启用自动故障转移
yarn.resourcemanager.cluster-id
yarncluster
指定YARN HA的名称
yarn.resourcemanager.ha.rm-ids
rm1,rm2
指定两个resourcemanager的名称
yarn.resourcemanager.hostname.rm1
namenode1
配置rm1的主机
yarn.resourcemanager.hostname.rm2
namenode2
配置rm2的主机
yarn.resourcemanager.ha.id
rm1
namenode1上配置rm1,在namenode上配置rm2
yarn.resourcemanager.zk-address
zookeeper1:2181,zookeeper2:2181,zookeeper:2181
配置zookeeper的地址
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
配置resourcemanager的状态存储到zookeeper中
yarn.resourcemanager.webapp.address.rm1
namenode1:8088
datanode1
datanode2
datanode3
8、将/opt/hadoop-3.0.0-beta1/ 复制到各个节点
scp /opt/hadoop-3.0.0-beta1/ [email protected]:/opt/9、格式化hdfs
1.三个ZK节点先启动Zookeeper
/opt/zookeeper-3.5.3-beta/bin/zkServer.sh start2.接着三个ZK节点启动journalnode
/opt/hadoop-3.0.0-beta1/sbin/hadoop-daemon.sh start journalnode3.在master节点上执行格式化
格式化namenode:/opt/hadoop-3.0.0-beta1/bin/hdfs namenode -format
格式化高可用:/opt/hadoop-3.0.0-beta1/bin/hdfs zkfc -formatZK10、启动hadoop :
/opt/hadoop-3.0.0-beta1/sbin/start-all.sh11.查看各节点进程jps
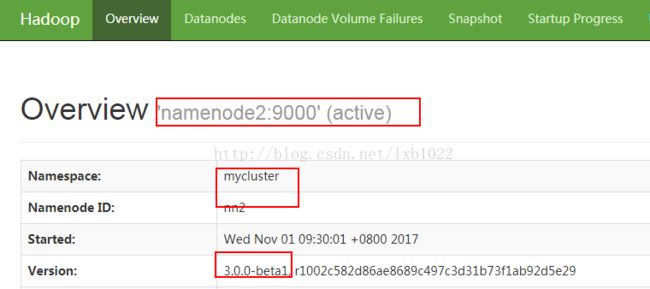
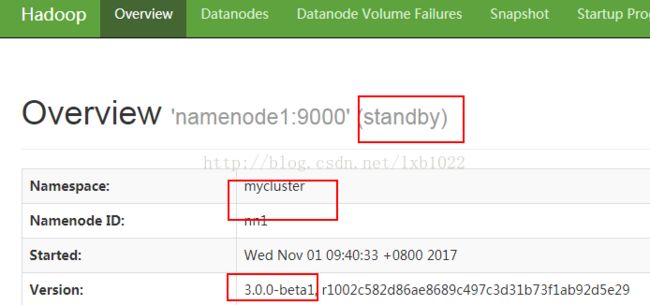
namenode1和namenode2如下图:
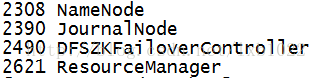
zk辅助节点进程如下图:

datanode节点进程如下图:

12、通过web页面查看: