Spark技术应用(大数据生态与Spark简介)
大数据技术概述
一,大数据概念:
无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。
三次信息化浪潮:

数据产生方式的变革促成了大数据时代的来临:

二,大数据特点和特征:
1、大数据不仅数据量大,而且还快速化,多样化,价值化等多重属性
(容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息)
(种类(Variety):数据类型的多样性)
(可变性(Variability):妨碍了处理和有效地管理数据的过程)
(真实性(Veracity):数据的质量)
2、处理速度快: 从数据的生成到消耗,时间窗口非常小,可用于生成决策的时间非常少
(速度(Velocity):指获得数据的速度)
3、结构复杂: 大数据是由结构化和非结构化数据组成的
(复杂性(Complexity):数据量巨大,来源多渠道)
4、价值密度低: 价值密度低,商业价值高
(价值(value):合理运用大数据,以低成本创造高价值)
三,大数据的影响:
在科学研究上,先后经历了实验,理论,计算和数据四种范式
在思维方式方面,大数据完全颠覆了传统的思维方式
1、全样而非抽样
2、效率而非精确
3、相关而非因果
四,大数据关键技术:
1、数据采集: 利用ETL工具将分布的、异构数据源中的数据如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;或者也可以把实时采集的数据作为流计算系统的输入,进行实时处理分析
2、数据存储和管理: 利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理
3、数据处理与分析: 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据
4、数据隐私和安全: 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全
大数据俩大核心技术: 分布式存储,分布式处理
五,大数据计算模式:
大数据计算模式:批处理计算,流计算,图计算,查询分析计算。

六,代表性大数据技术:
代表性大数据技术:
Hadoop,Spark,Flink,Beam
1,Hadoop生态系统
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
具有可靠、高效、可伸缩的特点。
Hadoop的核心是:YARN,HDFS和Mapreduce
1.1 HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
1.2 Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
1.3 Yarn(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
Yarn是下一代 Hadoop 计算平台,yarn是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。
用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。该框架为提供了以下几个组件:
资源管理:包括应用程序管理和机器资源管理
资源双层调度
容错性:各个组件均有考虑容错性
扩展性:可扩展到上万个节点
2,Spark简介
Spark最初由美国加州大学伯克利分校(UC Berkeley)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
2.1 Spark的特点:
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算。
容易使用:支持使用scala、java、python和R语言进行编程,可以通过spark shell进行交互式编程。
通用性:spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件。
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
2.2 Spark架构图: 2.3 Spark生态系统:
2.3 Spark生态系统:

2.4 Hadoop与spark的对比:
2.4.1 Hadoop的缺点:
1.表达能力有限
2.磁盘IO开销大
3.延迟高
4.任务之间的衔接涉及IO开销
5.在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务。
2.4.2 spark优点:
1.spark的计算模式属于Mapduce,但不局限Map和Reduce操作,还提供了许数据操作类型,编程模型比Hadoop MapReduce更灵活。
2.spark提供了内存计算,可将中间结果放到内存中,对于迭代计算效率更高
spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制。
2.4.3 执行流程对比图:
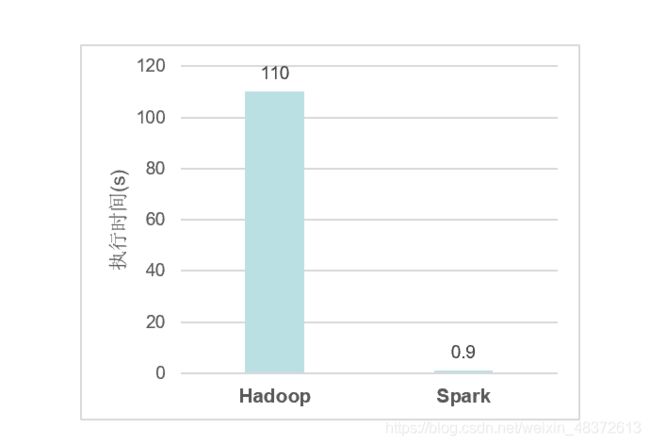
 2.4.4 执行逻辑回归时间对比:
2.4.4 执行逻辑回归时间对比:
<1> Hadoop进行迭代计算非常耗资源
<2> spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
3,Fink
Apache FIink是由 Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。
Flink以数据并行和流水线方式执行任意流数据程序, Flink的流水线运行时系统可以执行批处理和流处理程序。此外, Flink的运行时本身也支持迭代算法的执行。
3.1 Flink架构图:

3.2 Flink生态系统:

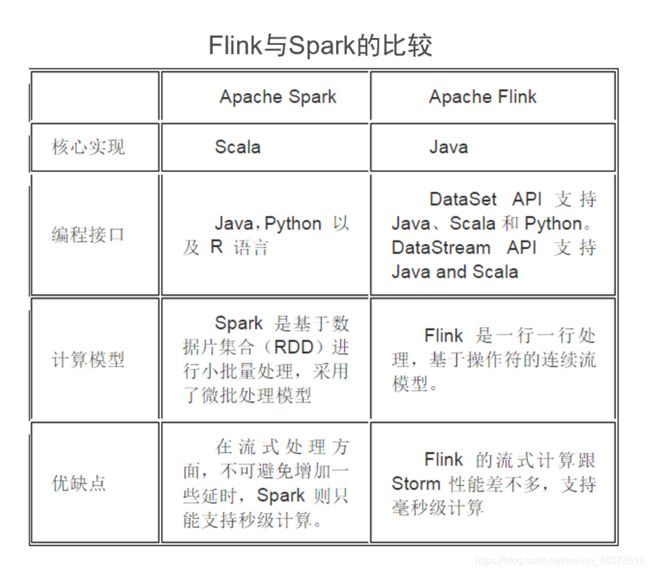
3.3 Flink与Spark的比较:
3.4 性能对比:

首先它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Fink计算性能上略好。
Spark和Flink全部都运行在 Hadoop YARN上,性能为 Flink> Spark>Hadoop(MR),迭代次数越多越明显,性能上, Flink优于 Spark和 Hadoop最主要的原因是 Flink支持增量迭代,具有对迭代自动优化的功能。
3.5 流式计算比较:
它们都支持流式计算, Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以 Spark在流式处理方面,不可避免增加一些延时。 Flink的流式计算跟 Storm性能差不多,支持毫秒级计算,而 Spark则只能支持秒级计算。
SQL支持:
都支持SQL, Spark对SQL的支持比 Flink支持的范围要大一些,另外 Spark支持对SQL的优化,而 Flink支持主要是对APl级的优化。
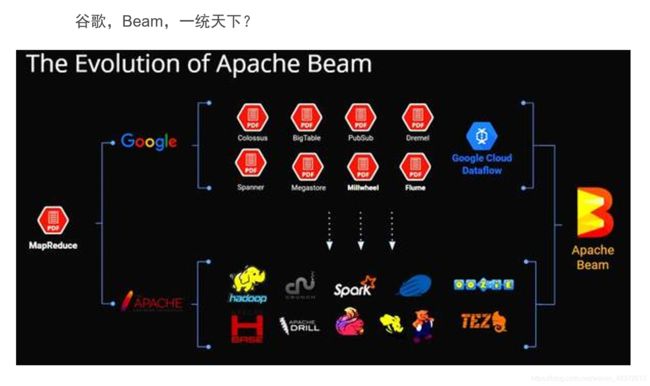
4,Beam
Apache Beam是大数据的编程模型,定义了数据处理的编程范式和接口,它并不涉及具体的执行引擎的实现,但是,基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上
目前 Dataflow、 Spark, Flink, Apex提供了对批处理和流处理的支持, GearPump提供了流处理的支持, Storm的支持也在开发中。
4.1 Apache Beam的目标是:
<1> 提供统一批处理和流处理的编程范式
<2>能运行在任何可执行的引擎之上
<3>为无限、乱序、互联网级别的数据集处理提供简单灵活、功能丰富以及表达能力十分强大的SDK。