python爬虫 ajax爬取个人微博 傻瓜版教程
python爬虫 ajax爬取个人微博 傻瓜版教程
- 前言
- 饭前开胃菜(没学过的web前端和AJAX爬虫的必看!!)
- 一整体思路
- 二丶分析URL
- 三丶页面解析
- 四丶写入文件
- 五丶完整代码
- 六丶最后
前言
大家好我是墨绿 头顶还是总一有抹绿的男人。我知道没人看我写的博客 没事 我就是写 我就是玩!!(其实不是 求求了 点点赞 看看孩子吧)这篇讲的是使用ajax方法实现的数据抓取 与之前的requests有很大不同 来吧 开席!!
还是老规矩 不想听我唠嗑的可以点击最后一个目录 获取代码

饭前开胃菜(没学过的web前端和AJAX爬虫的必看!!)
- 再开始之前 我提下我对使用ajxa方法爬虫的理解。我简单的提一下web前端知识,一个网页界面通常是由html和css标签语言构成的他们就相当于我们人体的皮肤,形成了我们所看到网页界面,而JS和ajax等就相当于人体骨骼帮助人们运动,形成了一系列的功能如我们所看到的轮播图的切换(在浏览器中这称为渲染页面)。
- 有时候我们使用的是requests请求 然后返回抓取页面的数据,但有些时候requests返回的结果却不一样没有或者乱码,这可能是因为浏览器中的页面可能是由JS和ajax或者特定算法生成的,所以我们才无法获取原本的页面。按照web的发展趋势来看异步加载的ajax请求将会越来越多,所以我们在学习爬虫的时候也要学会ajax方法的爬虫。
- 什么是Ajax?
它不是一门编程语言,而是利用JS在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
简单的来说就是你必须点加载才能看到下面的数据 而微博的数据刷新就是使用的这个方法。
求求你们不要嫌弃我啰嗦!!

一整体思路
其实爬过微博的都知道 微博的移动端 yyds!!!他是真的好爬 电脑端真的是太麻烦了。所以我们爬虫也从移动端入手。在移动端中下滑即可更新为一个新的页面了。
二丶分析URL
这里以《python3网络爬虫开发实践》作者崔庆才微博为例(我本来想拿自己微博的 但我怕你们看到我太帅了 爱上我本人所以还是算了 哈哈哈哈)
进入微博界面 F12 点击移动端 -》网络-》XHR(下面全为json文件)

又到了我们的细品URL环节 一次性下滑三次 即可查看三个页面的url了 必须下滑到更新数据为止
记住getIndex?type…开头的则是移动端微博的网址了 我们点击第一页页面 即可查看详细数据 页面解析需要根据图中右边的网址才能进行 接下来我们先继续分析url

细品之后我们发现 type value containerid的值始终如一 type为uid value为用户id containerid就是10736+用户id!!哦豁 直接芙湖!

在以前的文章中 页面还是根据page=1来判断的 现在不同是根据since_id来判断的
引用文本
since_id的获取我参考以下链接
链接: https://blog.csdn.net/weixin_44489501/article/details/104119556.
我参考此文章为基础来实现了我的代码
链接: https://blog.csdn.net/qq_24994275/article/details/116036503.
简单来说就是 上一页的数据中有下一页的sin_id的值 (怎么获取的建议细品上面的网址 我在这不啰嗦了)

上代码!
base_url = "https://m.weibo.cn/api/container/getIndex?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"}
params = {
"type": "uid",
"value": "2830678474",
"containerid": "1076032830678474"
}
url = base_url + urlencode(params) # 利用urlencode进行网页的拼接
三丶页面解析
因为是json格式的文件 所以我们先要提取内容进行解析处理
url = base_url + urlencode(params) # 利用urlencode进行网页的拼接
time.sleep(2)
resquest = requests.get(url=url, headers=headers)
data = resquest.content.decode("utf-8") # 获取网页内容
user_dict = json.loads(data) # data 得到的为字符串 利用json转为字典
# 获取since_id 并且自动加人
params["since_id"] = user_dict["data"]["cardlistInfo"]["since_id"]
#当第一次循环的时候就会获得下一页的id 然后赋值 等到下一页开始传入参数的时候 则会开始自动传入
params = params # 传入url的params参数
# 数据的解析
html = json.loads(data) # 网页==json格式
json格式如下

本文只获取以下三个内容 其他内容原理相同 用pyquery获取text内容 其他的则是python中获取字典中值的方法
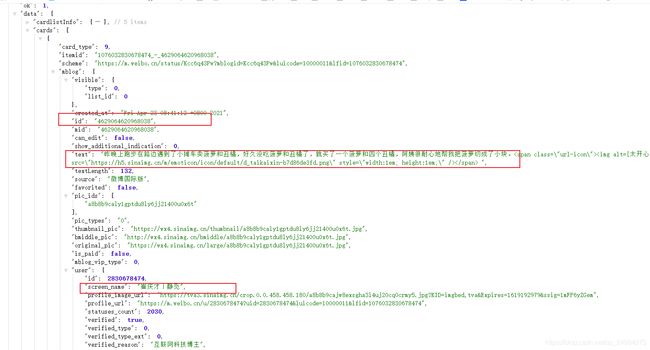
def parse_page(html):
items = html.get('data').get('cards') # 一页数据确定为十条 精准划分数据
for item in items: # 遍历一页数据==10条 item为一条
yield (
pq(item["mblog"]['text']).text(), # 文本内容
item["mblog"]['id'], # 用户id
item["mblog"]['user']['screen_name'] # 用户名字
)
四丶写入文件
这次不用csv文件写入了 改用excel写入!csv写入 内容的宽度会飘忽不定。我在这里设置了个变量 来判断是否是第一次写入 因为如果不是第一次写入的话就不是创建文件了 是追加数据
def excel(items):
#第一次写入
newTable = "test.xls"#创建文件
wb = xlwt.Workbook("encoding='utf-8")
ws = wb.add_sheet('sheet1')#创建表
headDate = ['文本内容', 'id', '用户名字']#定义标题
for i in range(0,3):#for循环遍历写入
ws.write(0, i, headDate[i], xlwt.easyxf('font: bold on'))
index = 1#行数
for data in items:#items是十条数据 data是其中一条(一条下有三个内容)
for i in range(0,3):#列数
print(data[i])
ws.write(index, i, data[i])#行 列 数据(一条一条自己写入)
index += 1#等上一行写完了 在继续追加行数
wb.save(newTable)
def another(items, j):#如果不是第一次写入 以后的就是追加数据了 需要另一个函数
index = (j-1) * 10 + 1#这里是 每次写入都从11 21 31..等开始 所以我才传入数据 代表着从哪里开始写入
data = xlrd.open_workbook('test.xls')
ws = xlutils.copy.copy(data)
# 进入表
table = ws.get_sheet(0)
for test in items:
for i in range(0, 3):#跟excel同理
print(test[i])
table.write(index, i, test[i]) # 只要分配好 自己塞入
# table.write(index, 0, test[0]) # 第0 行 第5列 写入数据
# table.write(index, 1, test[1]) # 第0 行 第5列 写入数据
# table.write(index, 2, test[2]) # 第0 行 第5列 写入数据
print('_______________________')
index += 1
ws.save('test.xls')
五丶完整代码
# ajax爬取微博
import requests
from urllib.parse import urlencode
import json
import time
from pyquery import PyQuery as pq
import xlwt
import xlutils.copy
import xlrd
def parse_page(html):
items = html.get('data').get('cards') # 一页数据确定为十条 精准划分数据
for item in items: # 遍历一页数据==10条 item为一条
yield (
pq(item["mblog"]['text']).text(), # 文本内容
item["mblog"]['id'], # 用户id
item["mblog"]['user']['screen_name'] # 时间
)
def excel(items):
#第一次写入
newTable = "test.xls"#创建文件
wb = xlwt.Workbook("encoding='utf-8")
ws = wb.add_sheet('sheet1')#创建表
headDate = ['文本内容', 'id', '用户名字']#定义标题
for i in range(0,3):#for循环遍历写入
ws.write(0, i, headDate[i], xlwt.easyxf('font: bold on'))
index = 1#行数
for data in items:#items是十条数据 data是其中一条(一条下有三个内容)
for i in range(0,3):#列数
print(data[i])
ws.write(index, i, data[i])#行 列 数据(一条一条自己写入)
index += 1#等上一行写完了 在继续追加行数
wb.save(newTable)
def another(items, j):#如果不是第一次写入 以后的就是追加数据了 需要另一个函数
index = (j-1) * 10 + 1#这里是 每次写入都从11 21 31..等开始 所以我才传入数据 代表着从哪里开始写入
data = xlrd.open_workbook('test.xls')
ws = xlutils.copy.copy(data)
# 进入表
table = ws.get_sheet(0)
for test in items:
for i in range(0, 3):#跟excel同理
print(test[i])
table.write(index, i, test[i]) # 只要分配好 自己塞入
# table.write(index, 0, test[0]) # 第0 行 第5列 写入数据
# table.write(index, 1, test[1]) # 第0 行 第5列 写入数据
# table.write(index, 2, test[2]) # 第0 行 第5列 写入数据
print('_______________________')
index += 1
ws.save('test.xls')
def main(page):
j = 1
base_url = "https://m.weibo.cn/api/container/getIndex?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"}
params = {
"type": "uid",
"value": "2830678474",
"containerid": "1076032830678474"
}
judge = True#用来判断是否为第一次
while (j <= page): # 利用n控制页,想爬取多少页自己设置
time.sleep(2.5)
# 网页的获取
url = base_url + urlencode(params) # 利用urlencode进行网页的拼接
time.sleep(2)
resquest = requests.get(url=url, headers=headers)
data = resquest.content.decode("utf-8") # 获取网页内容
user_dict = json.loads(data) # data 得到的为字符串
# 获取since_id 并且自动加人
params["since_id"] = user_dict["data"]["cardlistInfo"]["since_id"]
#当第一次循环的时候就会获得下一页的id 然后赋值 等到下一页开始传入参数的时候 则会开始自动传入
params = params # 传入url的params参数
# 数据的解析
html = json.loads(data) # 网页==json格式
test = parse_page(html) # 返回一页的数据
if judge:
excel(test)
judge = False
else:
another(test, j)
print('完成第' + str(j) + '页————————————————————')
j = j + 1
main(4)#4为要爬取的页数
结果
空出来的代表发的表情 表情可以截出文字版的 只不过我懒得弄了 大家自己看着来吧

六丶最后
今天的墨绿小剧场就到这里结束了 很多地方写的不好 多多包涵 还是那句 有问题发表到评论区 能回答一定回答 下次见!!
