百度飞桨PaddlePaddle图像分割7日打卡营入门及心得
课程安排
- 前言
- 一、paddlepaddle与图像分割
-
- 1.paddlepaddle介绍
- 2.什么是图像分割?
- 二、课程内容
-
- 1.预习内容
- 2. 图像分割
-
- DAY1
- DAY2
- DAY3
- DAY4
- DAY5
- DAY6
- 总结
前言
这次的百度飞桨图像分割7日打卡营是一次难得的对于图像分割的入门学习,之前的对于python的学习比较基础,图像识别这一块也比较难懂,这次的课程有顶会技术大牛的讲解,在学习过程中对于图像处理和分割有了一些入门知识掌握,很开心可以打卡完并结营。下面的内容就简要的总结一下这几天的学习内容吧!
一、paddlepaddle与图像分割
1.paddlepaddle介绍
飞桨 (PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,2016 年正式开源,是全面开源开放、技术领先、功能完备的产业级深度学习平台。飞桨源于产业实践,始终致力于与产业深入融合。目前飞桨已广泛应用于工业、农业、服务业等,服务 210 多万开发者,与合作伙伴一起帮助越来越多的行业完成 AI 赋能。
2.什么是图像分割?
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像素赋予相同的编号。
二、课程内容
1.预习内容
入门第一课-Python快速入门
入门第二课-Notebook基础操作
入门第三课-Debug基础教学
入门第四课-PaddlePaddle快速入门
入门第五课-PaddleSeg快速体验
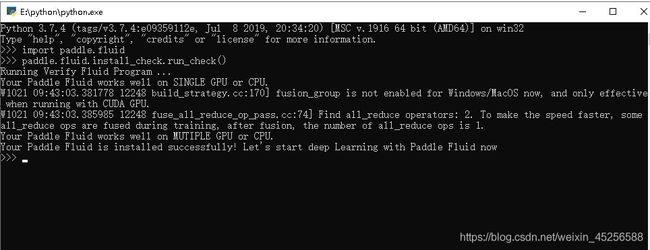
这部分比较简单,不涉及什么代码编写内容,就简单装个paddlepaddle即可(图示成功安装结果):
2. 图像分割
DAY1
1.图像分割综述
2.语义分割初探
3.环境搭建与飞桨动态图实战演示
4.语义分割的数据格式和处理
DAY2
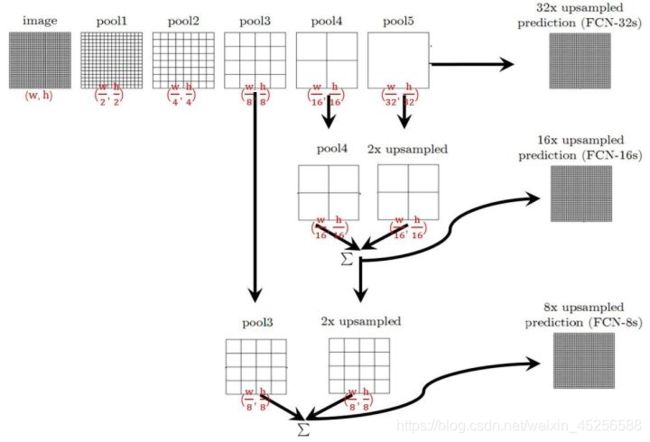
1.FCN全卷积网络结构详解
2.飞桨中的上采样操作实践
3.飞桨实现FCN
原理示意图
fnc8s实现代码:
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable
from paddle.fluid.dygraph import Conv2D
from paddle.fluid.dygraph import Conv2DTranspose
from paddle.fluid.dygraph import Dropout
from paddle.fluid.dygraph import BatchNorm
from paddle.fluid.dygraph import Pool2D
from paddle.fluid.dygraph import Linear
from vgg import VGG16BN
class FCN8s(fluid.dygraph.Layer):
# TODO: create fcn8s model
def __init__(self,num_classes=59):
super(FCN8s,self).__init__()
backbone=VGG16BN(pretrained=False)
self.layer1 = backbone.layer1
self.layer1[0].conv._padding = [100,100]
self.pool1 = Pool2D(pool_size=2,pool_stride=2,ceil_mode=True)
self.layer2 = backbone.layer2
self.pool2 = Pool2D(pool_size=2,pool_stride=2,ceil_mode=True)
self.layer3 = backbone.layer3
self.pool3 = Pool2D(pool_size=2,pool_stride=2,ceil_mode=True)
self.layer4 = backbone.layer4
self.pool4 = Pool2D(pool_size=2,pool_stride=2,ceil_mode=True)
self.layer5 = backbone.layer5
self.pool5 = Pool2D(pool_size=2,pool_stride=2,ceil_mode=True)
self.fc6 = Conv2D(512,4096,7,act='relu')
self.fc7 = Conv2D(4096,4096,1,act='relu')
self.drop6 = Dropout()
self.drop7 = Dropout()
self.score = Conv2D(4096,num_classes,1)
self.score_pool3 = Conv2D(256,num_classes,1)
self.score_pool4 = Conv2D(512,num_classes,1)
self.up_output = Conv2DTranspose(num_channels=num_classes,
num_filters=num_classes,
filter_size=4,
stride =2,
bias_attr=False)
self.up_pool4 = Conv2DTranspose(num_channels=num_classes,
num_filters=num_classes,
filter_size=4,
stride =2,
bias_attr=False)
self.up_final = Conv2DTranspose(num_channels=num_classes,
num_filters=num_classes,
filter_size=16,
stride =16,
bias_attr=False)
def forward(self,inputs):
x=self.layer1(inputs)
x=self.pool1(x)
x=self.layer2(x)
x=self.pool2(x)
x=self.layer3(x)
x=self.pool3(x)
pool3= x
x=self.layer4(x)
x=self.pool4(x)
pool4= x
x=self.layer5(x)
x=self.pool5(x)
x=self.fc6(x)
x=self.drop6(x)
x=self.fc7(x)
x=self.drop7(x)
x=self.score(x)
x=self.up_output(x)
up_output = x
x=self.score_pool4(pool4)
x = x [:,:,5:5+up_output.shape[2],5:5+up_output.shape[3]]
up_pool4 =x
x=up_pool4 + up_output
x=self.score_pool3(pool3)
x=x[:,:,9:9+up_pool4.shape[2],9:9+up_pool4.shape[3]]
up_pool3=x
x= up_pool3 +up_pool4
x= self.up_final(x)
x=x[:,:,31:31+inputs.shape[2],31:31+inputs.shape[3]]
return x
def main():
with fluid.dygraph.guard():
x_data = np.random.rand(2, 3, 512, 512).astype(np.float32)
x = to_variable(x_data)
model = FCN8s(num_classes=59)
model.eval()
pred = model(x)
print(pred.shape)
if __name__ == '__main__':
main()
vgg实现代码:
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable
from paddle.fluid.dygraph import Conv2D
from paddle.fluid.dygraph import Dropout
from paddle.fluid.dygraph import BatchNorm
from paddle.fluid.dygraph import Pool2D
from paddle.fluid.dygraph import Linear
model_path = {
#'vgg16': './vgg16',
'vgg16bn': './vgg16_bn',
# 'vgg19': './vgg19',
# 'vgg19bn': './vgg19_bn'
}
class ConvBNLayer(fluid.dygraph.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size=3,
stride=1,
groups=1,
use_bn=True,
act='relu',
name=None):
super(ConvBNLayer, self).__init__(name)
self.use_bn = use_bn
if use_bn:
self.conv = Conv2D(num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size-1)//2,
groups=groups,
act=None,
bias_attr=None)
self.bn = BatchNorm(num_filters, act=act)
else:
self.conv = Conv2D(num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size-1)//2,
groups=groups,
act=act,
bias_attr=None)
def forward(self, inputs):
y = self.conv(inputs)
if self.use_bn:
y = self.bn(y)
return y
class VGG(fluid.dygraph.Layer):
def __init__(self, layers=16, use_bn=False, num_classes=1000):
super(VGG, self).__init__()
self.layers = layers
self.use_bn = use_bn
supported_layers = [16, 19]
assert layers in supported_layers
if layers == 16:
depth = [2, 2, 3, 3, 3]
elif layers == 19:
depth = [2, 2, 4, 4, 4]
num_channels = [3, 64, 128, 256, 512]
num_filters = [64, 128, 256, 512, 512]
self.layer1 = fluid.dygraph.Sequential(*self.make_layer(num_channels[0], num_filters[0], depth[0], use_bn, name='layer1'))
self.layer2 = fluid.dygraph.Sequential(*self.make_layer(num_channels[1], num_filters[1], depth[1], use_bn, name='layer2'))
self.layer3 = fluid.dygraph.Sequential(*self.make_layer(num_channels[2], num_filters[2], depth[2], use_bn, name='layer3'))
self.layer4 = fluid.dygraph.Sequential(*self.make_layer(num_channels[3], num_filters[3], depth[3], use_bn, name='layer4'))
self.layer5 = fluid.dygraph.Sequential(*self.make_layer(num_channels[4], num_filters[4], depth[4], use_bn, name='layer5'))
self.classifier = fluid.dygraph.Sequential(
Linear(input_dim=512 * 7 * 7, output_dim=4096, act='relu'),
Dropout(),
Linear(input_dim=4096, output_dim=4096, act='relu'),
Dropout(),
Linear(input_dim=4096, output_dim=num_classes))
self.out_dim = 512 * 7 * 7
def forward(self, inputs):
x = self.layer1(inputs)
x = fluid.layers.pool2d(x, pool_size=2, pool_stride=2)
x = self.layer2(x)
x = fluid.layers.pool2d(x, pool_size=2, pool_stride=2)
x = self.layer3(x)
x = fluid.layers.pool2d(x, pool_size=2, pool_stride=2)
x = self.layer4(x)
x = fluid.layers.pool2d(x, pool_size=2, pool_stride=2)
x = self.layer5(x)
x = fluid.layers.pool2d(x, pool_size=2, pool_stride=2)
x = fluid.layers.adaptive_pool2d(x, pool_size=(7,7), pool_type='avg')
x = fluid.layers.reshape(x, shape=[-1, self.out_dim])
x = self.classifier(x)
return x
def make_layer(self, num_channels, num_filters, depth, use_bn, name=None):
layers = []
layers.append(ConvBNLayer(num_channels, num_filters, use_bn=use_bn, name=f'{name}.0'))
for i in range(1, depth):
layers.append(ConvBNLayer(num_filters, num_filters, use_bn=use_bn, name=f'{name}.{i}'))
return layers
# def VGG16(pretrained=False):
# # model = VGG(layers=16)
# # if pretrained:
# # model_dict, _ = fluid.load_dygraph(model_path['vgg16'])
# # model.set_dict(model_dict)
# # return model
def VGG16BN(pretrained=False):
model = VGG(layers=16, use_bn=True)
if pretrained:
model_dict, _ = fluid.load_dygraph(model_path['vgg16bn'])
model.set_dict(model_dict)
return model
# def VGG19(pretrained=False):
# model = VGG(layers=19)
# if pretrained:
# model_dict, _ = fluid.load_dygraph(model_path['vgg19'])
# model.set_dict(model_dict)
# return model
# def VGG19BN(pretrained=False):
# model = VGG(layers=19, use_bn=True)
# if pretrained:
# model_dict, _ = fluid.load_dygraph(model_path['vgg19bn'])
# model.set_dict(model_dict)
# return model
def main():
with fluid.dygraph.guard():
x_data = np.random.rand(2, 3, 224, 224).astype(np.float32)
x = to_variable(x_data)
# model = VGG16()
# model.eval()
# pred = model(x)
# print('vgg16: pred.shape = ', pred.shape)
model = VGG16BN()
model.eval()
pred = model(x)
print('vgg16bn: pred.shape = ', pred.shape)
# model = VGG19()
# model.eval()
# pred = model(x)
# print('vgg19: pred.shape = ', pred.shape)
# model = VGG19BN()
# model.eval()
# pred = model(x)
# print('vgg19bn: pred.shape = ', pred.shape)
if __name__ == "__main__":
main()
DAY3
1.U-Net模型与PSPNet模型详解
2.飞桨实现UNet/PSPNet
3.飞桨实现DilatedResnet
4.分割网络loss和metrics实现
U-Net模型是一种改进的FCN结构,因其结构经论文作者画出来形似字母U而得名,应用于医学图像的语义分割。它由左半边的压缩通道(Contracting Path)和右半边扩展通道(Expansive Path)组成。压缩通道是典型的卷积神经网络结构,它重复采用2个卷积层和1个最大池化层的结构,每进行一次池化操作后特征图的维数就增加1倍。在扩展通道,先进行1次反卷积操作,使特征图的维数减半,然后拼接对应压缩通道裁剪得到的特征图,重新组成一个2倍大小的特征图,再采用2个卷积层进行特征提取,并重复这一结构。在最后的输出层,用2个卷积层将64维的特征图映射成2维的输出图。
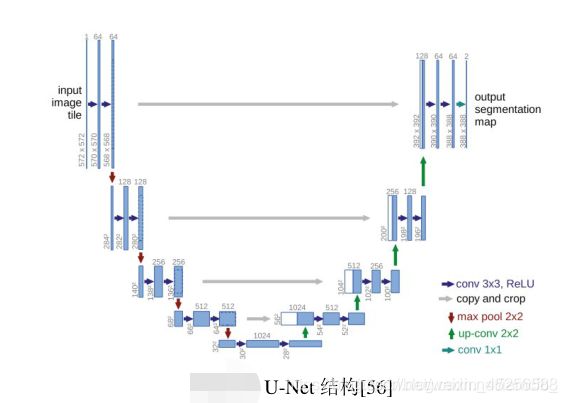
Unet实现代码:
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable, Layer, Conv2D, BatchNorm, Pool2D, Conv2DTranspose
class Encoder(Layer):
def __init__(self, num_channels, num_filters):
super(Encoder, self).__init__()
#TODO: encoder contains:
# 1 3x3conv + 1bn + relu +
# 1 3x3conc + 1bn + relu +
# 1 2x2 pool
# return features before and after pool
self.conv1 = Conv2D(num_channels, num_filters, filter_size=3, padding=1)
self.bn1 = BatchNorm(num_filters, act='relu')
self.conv2 = Conv2D(num_filters, num_filters, filter_size=3, padding=1)
self.bn2 = BatchNorm(num_filters, act='relu')
self.pool = Pool2D(pool_size=2, pool_stride=2, pool_type='max', ceil_mode=True)
def forward(self, inputs):
# TODO: finish inference part
x = self.conv1(inputs)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
x_pooled = self.pool(x)
return x, x_pooled
class Decoder(Layer):
def __init__(self, num_channels, num_filters):
super(Decoder, self).__init__()
# TODO: decoder contains:
# 1 2x2 transpose conv (makes feature map 2x larger)
# 1 3x3 conv + 1bn + 1relu +
# 1 3x3 conv + 1bn + 1relu
self.up = Conv2DTranspose(num_channels, num_filters, filter_size=2, stride=2)
self.conv1 = Conv2D(num_channels, num_filters, filter_size=3, padding=1)
self.bn1 = BatchNorm(num_filters, act='relu')
self.conv2 = Conv2D(num_filters, num_filters, filter_size=3, padding=1)
self.bn2 = BatchNorm(num_filters, act='relu')
def forward(self, inputs_prev, inputs):
# TODO: forward contains an Pad2d and Concat
x = self.up(inputs)
h_diff = (inputs_prev.shape[2] - x.shape[3])
w_diff = (inputs_prev.shape[3] - x.shape[3])
x = fluid.layers.pad2d(x, paddings=[h_diff//2, h_diff - h_diff//2, w_diff//2, w_diff - w_diff//2])
x = fluid.layers.concat([inputs_prev, x], axis=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
return x
class UNet(Layer):
def __init__(self, num_classes=59):
super(UNet, self).__init__()
# encoder: 3->64->128->256->512
# mid: 512->1024->1024
#TODO: 4 encoders, 4 decoders, and mid layers contains 2 1x1conv+bn+relu
self.down1 = Encoder(num_channels=3, num_filters=64)
self.down2 = Encoder(num_channels=64, num_filters=128)
self.down3 = Encoder(num_channels=128, num_filters=256)
self.down4 = Encoder(num_channels=256, num_filters=512)
self.mid_conv1 = Conv2D(num_channels=512, num_filters=1024, filter_size=1)
self.mid_bn1 = BatchNorm(1024, act='relu')
self.mid_conv2 = Conv2D(1024, 1024, filter_size=1)
self.mid_bn2 = BatchNorm(1024, act='relu')
self.up4 = Decoder(1024, 512)
self.up3 = Decoder(512, 256)
self.up2 = Decoder(256, 128)
self.up1 = Decoder(128, 64)
self.last_conv = Conv2D(64, num_classes, filter_size=1)
def forward(self, inputs):
x1, x = self.down1(inputs)
print(x1.shape, x.shape)
x2, x = self.down2(x)
print(x2.shape, x.shape)
x3, x = self.down3(x)
print(x3.shape, x.shape)
x4, x = self.down4(x)
print(x4.shape, x.shape)
# middle layers
x = self.mid_conv1(x)
x = self.mid_bn1(x)
x = self.mid_conv2(x)
x = self.mid_bn2(x)
print(x4.shape, x.shape)
x = self.up4(x4, x)
print(x3.shape, x.shape)
x = self.up3(x3, x)
print(x2.shape, x.shape)
x = self.up2(x2, x)
print(x1.shape, x.shape)
x = self.up1(x1, x)
print(x.shape)
x = self.last_conv(x)
return x
# 测试网络
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
model = UNet(num_classes=59)
x_data = np.random.rand(1, 3, 123, 123).astype(np.float32)
inputs = to_variable(x_data)
pred = model(inputs)
print(pred.shape)
DAY4
1.Dilated Conv 原理和细节
2.ASPP模块解析
3.DeepLab系列详解
4.实现DeepLabV3/ASPP/MultiGrid
5.分割网络loss和metrics实现
Dilated/Atrous Convolution(中文叫做空洞卷积或者膨胀卷积) 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。
DAY5
1.深入解析GCN(图卷积网络)
2.Graph-based Segmentation多个方法详解 (GloRe, GCU, GINet)
3.GCN代码简要解析
4.在Pascal Context上实现GloRe
DAY6
1.实例分割与全景分割概述
2.实例分割:Mask R-CNN和SOLO
3.全景分割:PanapticFPN和UPSNet
后续部分的理解起来较难,涉及的代码也比较复杂,详细可以关注百度飞桨平台进行学习,附链接
总结
本次课程的学习增强了我对于图像分割的了解与学习,在跟着平台的学习后收获颇丰,期待后续的新课程