python自动化办公、Excel数据处理方法总结
目录
- 0. 阅前须知
- 1. 读取(打开)excel
- 2. 不规则数据结构pd.read读取
- 3. xw选取数据转成dataframe
- 4. xw定位行列位置,将处理结果填入表中
- 5. xw追加(粘贴)数据并向下应用公式
- 5.5. xw粘贴数据方法的限制
- 6. 使用xw临时打开python内数据为一个excel表格
- 7. 时间处理
- 8. xw插入行并复制内容
- 9. xw遍历sheet,按需选取
- 10. 列字母与列数字转化
- 11. dataframe重置多层表头为单层表头
- 12. 代码替代excel公式(pandas列计算)
- 13. 数据拼接concat和merge
- 14. 遍历文件夹下所有文件
- 15. 存档数据更新,并封装为一个函数
- 16. vlookup功能的类似实现
- 17. 数据去重的处理(pivot_table和groupby)
- 18. 压缩包解压
- 19. 自动发送邮件(简易)
- 20. 连接数据库
- 22. Jupyter Notebook引用自己写的代码文件
- 23. 按某列空白值折叠表格
- 24. 对某列空白值做向下填充
- 25. 模拟键鼠操作浏览器(了解)
- 26. 删除变量释放内存
- 27. 一些不常见的报错
-
- 27.1 dataframe保存csv编码错误UnicodeEncodeError
- 27.2 内存不足MemoryError
0. 阅前须知
1、主定位是一篇个人笔记,轻分享经验,所以并不一定的最优的代码方案,有更好的思路欢迎交流
2、代码都只是核心功能部分(所以有些变量定义会省略)
3、excel数据处理的核心思路是读取excel获取数据,用pandas等工具处理好后再放回excel,所有方法围绕该思路展开
1. 读取(打开)excel
常用两种方法(还有其他可操作库,因为没有用过不作介绍了)
一种是pandas的read
import pandas as pd
filepath = ...
# 读取excel
df = pd.read_excel(filepath)
# 读取csv
df = pd.read_csv(filepath)
"""上述两个read常用的参数有:
1、sheet_name=['sheet1'] 如果文件里有多个sheet,需要指定读取哪一个,默认0
2、skiprows=n 跳过文件的前n行
3、nrows=n 只取文件的前n行
4、usecols=['a','b','c'] 如果文件行列数不规则,可以指定选取需要的a,b,c列
"""
另一种的使用xlwings库,网上基础教程比较完善,基本框架如下:
import xlwings as xw
app=xw.App(visible=False,add_book=False) #前三行代码固定
app.display_alerts=False
app.screen_updating=False
readpath = 'E:/..略..' #文件路径
wb = app.books.open(readpath) #打开文件,定义为一个workbook变量
sht = wb.sheets[0] #选取目标sheet,可使用数字表示sheet顺序,0即选取第一个,常用在只有一个sheet的情况,多个sheet时推荐使用字符串具体指定,且能在一次打开中多次切换sheet
df = pd.DataFrame(sht.range("A1:D10").value) #选取目标区域转化成dataframe,以进行后续的加工处理
##
# 这里做数据处理
##
wb.save() #默认原文件保存,若在此处传入其他路径,就相当于另存为
wb.close() #关闭workbook
app.quit() #关闭app
"""
注意事项:
1、使用xw时,文件会被占用,此时手动打开excel会让你以只读方式打开
只有wb.close()或app.quit()后,才会将文件释放出来
如果xw这部分直接写在一个函数里,遇到报错后进程没有结束,文件无法释放出来,因为在函数内也就无法手动quit,通常只能restart kernel
所以建议与try..except搭配使用,以确保任何意外下总是释放文件,个人常用框架为:
app=xw.App(visible=False,add_book=False)
app.display_alerts=False
app.screen_updating=False
try:
...
except Exception as e:
print(type(e), e) #打印错误
app.quit()
2、理论上可以在一个app下操作多次excel,通常为了不出现冲突,每次完成一个excel操作后我都会app.quit(),别的地方需要时再新定义一个app即可。
3、经验上wb.close()不是必须的,对于中间步骤的数据文件,如果一次打开了很多个,我会偷懒在调用结束后直接app.quit()
之后在打开excel时会看到提示上次未正常关闭的文件,但是问题不大,一般都忽略
4、对于数据量较大,文件内除数据外还有大量公式、格式、透视表的excel,xw的打开速度会快于pd.read,数据结构简单单纯数据量大pd.read也很快
5、运行过程中偶尔会出现类似com_error: (-2147023174, 'RPC 服务器不可用。', None, None)的错误
经验上可以检查一下指定sheet时是不是给了一个不存在的sheet name,但更多时候重新运行一遍就可以了,且在运行期间尽量不去手动关闭其他的excel表
"""
第3点图注
2. 不规则数据结构pd.read读取

如果数据结构是n*m,则读取十分方便,不需要额外操作,如果结构是混合组成的,像上图那样只需要提取中间一部分的内容,且每次(不同的文件)所需要内容所在位置并不完全一样(如果位置固定也简单很多),这时需要判断起止位置,把目标截取出来,尽管如此仍需要数据结构具有一定的规律用以作为判断条件,对图上例子如下:
import csv
file_path = ....
with open(file_path, "r", encoding='utf8') as csvfile:
reader = csv.reader(csvfile)
tag = False #是否找到开始位置的判断变量
row = 0 #当前所在行
for i in reader: #遍历文件行,输出每行为列表形式
if i == ['A1', 'B1', 'C1']: #寻找开始行
start_row = row
tag = True
if len(i) == 0 and tag == True: #寻找结束行
end_row = row
break
row += 1
print(file_path, start_row, end_row)
temp = pd.read_csv(file_path, skiprows=start_row, usecols=[0, 1, 2]) #因为从0开始,start_row不需要-1
df = temp.iloc[:end_row-start_row-1].copy() #根据文件格式得到的式子
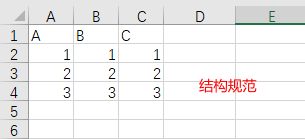
3. xw选取数据转成dataframe
对于结构规范的表,在打开表后,直接如下即可选出数据
df = pd.DataFrame(sht.used_range.value)
"""
注意此处的used_range有可能把excel的全部140多万行都选进来,因为有时候我们看到没内容的地方并不代表就是空的
这需要手动选取空白区域,删除行(或列),就可以了
"""
不同于pd.read会自动把第一行作为表头,使用xw需要手动操作一下
df = pd.DataFrame(sht.used_range.value)
df.columns = df.iloc[0].values #用第一行重置表头
df = df.drop(0) #删掉第一行
df = df.reset_index(drop=True) #重置index
若需要手动选择一定范围的数据,就使用df = pd.DataFrame(sht.range("A1:A2").value),至于range里怎么圈定范围,就有很多情况了,这个根据具体情况来。
4. xw定位行列位置,将处理结果填入表中
思路是借助dataframe,定位目标在行列中分别的位置,再还原到实际表中的位置,向该位置的单元格填入结果
# 行列坐标参考获取
last_row = pd.DataFrame(sht.range("A:A").value).last_valid_index()+1
df_ridx = pd.DataFrame(sht.range("A2:B"+str(last_row)).value) #行索引
df_cidx = pd.DataFrame(sht.range("C1:AH1").value) #列索引
# 填数
col_name = 'xxx' #目标列
pvt = xxx #pvt是一个处理好的dataframe数据
idx = df_cidx[df_cidx[0].str.contains(col_name)==True].index
cidx= idx[0] + 3 #列坐标,+3是因为上面从C列开始获取索引,还原到表中则要补上前面三列的位置
pvt_len = len(pvt)
for k in range(pvt_len):
geo = pvt.iloc[k]['country']
os = pvt.iloc[k]['os']
day = pvt.iloc[k]['date']
try:
idx = df_ridx[(df_ridx[0]==day)
&(df_ridx[1].str.contains(os)==True)
&(df_ridx[1].str.contains(geo)==True) #使用等于还是只包含某字段就好,视实际情况选择
].index
ridx = idx[0] + 2 #行坐标,+2理由与列类似
sht.range(ridx,cidx).value = pvt.iloc[k][col_name] #填数
except IndexError:
pass
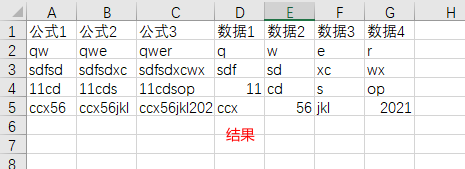
5. xw追加(粘贴)数据并向下应用公式
对应手动操作:在现有的表最后粘贴上新的数据,并将旁边的公式拉下来
图示

df_input = xxx #处理好的,待粘贴的数据
col_name = 'D' #对应上图示例
col_num = 4 #D列对应的列位置数值
last_row = sht.range('A' + str(sht.cells.last_cell.row)).end('up').row #原最后一行
sht.range(last_row+1,col_num).options(index=0,header=0,expand='table').value = df_input #粘贴数据
new_last_row = sht.range(col_name + str(sht.cells.last_cell.row)).end('up').row #贴入新数据后的最后一行
formula = sht.range((last_row,1),(last_row,col_num-1)).formula #提取公式
sht.range((last_row,1),(new_last_row,col_num-1)).options(expand='table').formula = formula #粘贴公式
#此处语句是实现了粘贴,公式粘贴后会自动变更对应的行列参数,因此达到效果
#注意粘贴公式时要带上原有公式区域的最后一行
"""
1、注意在使用这个功能时,需要在原excel中设置好公式自动更新,否则会失效!(被坑过)具体设置位置如下图所示
2、这个粘贴方法存在上限,下一点细说
"""
注意设置为自动(默认自动,一般不会动到这里,仅作须知)

5.5. xw粘贴数据方法的限制
上一点已经涉及,模拟粘贴的核心代码就是sht.range(last_row+1,col_num).options(index=0,header=0,expand='table').value = df_input #粘贴数据
这里单独说一下此方法的上限,举一个实际例子如下:
已知 result 是一个(1081119, 6)的数据集,sht 为读取的一个csv文件sheet。
可见如果截取前100万行,可以正常执行粘贴,但是全部执行的话就会报错。经查证错误代码-2147352567表示索引错误,原因就是在粘贴时数据量超出了excel表格可展示上限,导致索引错误。
从这个问题可以理解到,xw操作excel就像是系统替你打开了表格,以程序代替手动对表格进行操作,并没有超越手动表格的限制,对于更大数据量的读取存储操作,只有使用pd.read()/pd.save()这样的操作。


---------------------------------------------------------------------------
com_error Traceback (most recent call last)
<ipython-input-41-557295384336> in <module>
1 sht.used_range.clear_contents()
2 # result_ = result.iloc[:1000000]
----> 3 sht.range(1,1).options(expand='table', index=0, header=1).value = result
D:\anaconda3\lib\site-packages\xlwings\main.py in value(self, data)
1545 @value.setter
1546 def value(self, data):
-> 1547 conversion.write(data, self, self._options)
1548
1549 def expand(self, mode='table'):
D:\anaconda3\lib\site-packages\xlwings\conversion\__init__.py in write(value, rng, options)
40 pipeline = accessors.get(convert, convert).router(value, rng, options).writer(options)
41 ctx = ConversionContext(rng=rng, value=value)
---> 42 pipeline(ctx)
43 return ctx.value
D:\anaconda3\lib\site-packages\xlwings\conversion\framework.py in __call__(self, *args, **kwargs)
61 def __call__(self, *args, **kwargs):
62 for stage in self:
---> 63 stage(*args, **kwargs)
64
65
D:\anaconda3\lib\site-packages\xlwings\conversion\standard.py in __call__(self, ctx)
57 scalar = ctx.meta.get('scalar', False)
58 if not scalar:
---> 59 ctx.range = ctx.range.resize(len(ctx.value), len(ctx.value[0]))
60
61 self._write_value(ctx.range, ctx.value, scalar)
D:\anaconda3\lib\site-packages\xlwings\main.py in resize(self, row_size, column_size)
1793 column_size = self.shape[1]
1794
-> 1795 return Range(self(1, 1), self(row_size, column_size)).options(**self._options)
1796
1797 def offset(self, row_offset=0, column_offset=0):
D:\anaconda3\lib\site-packages\xlwings\main.py in __call__(self, *args)
1493
1494 def __call__(self, *args):
-> 1495 return Range(impl=self.impl(*args))
1496
1497 @property
D:\anaconda3\lib\site-packages\xlwings\_xlwindows.py in __call__(self, *args)
963 if len(args) == 0:
964 raise ValueError("Invalid arguments")
--> 965 return Range(xl=self.xl(*args))
966 else:
967 raise NotImplemented()
D:\anaconda3\lib\site-packages\xlwings\_xlwindows.py in __call__(self, *args, **kwargs)
149 for i in range(N_COM_ATTEMPTS + 1):
150 try:
--> 151 v = self._inner(*args, **kwargs)
152 t = type(v)
153 if t is CDispatch:
D:\anaconda3\lib\site-packages\win32com\client\dynamic.py in __call__(self, *args)
195 if invkind is not None:
196 allArgs = (dispid,LCID,invkind,1) + args
--> 197 return self._get_good_object_(self._oleobj_.Invoke(*allArgs),self._olerepr_.defaultDispatchName,None)
198 raise TypeError("This dispatch object does not define a default method")
199
com_error: (-2147352567, '发生意外。', (0, None, None, None, 0, -2146827284), None)

6. 使用xw临时打开python内数据为一个excel表格
临时以excel的形式打开一个数据,如果需要可以另存为
df = xxx
xw.view(df)
# 还有一个load方法,平时view用的更多
7. 时间处理
数据处理必绕不开和日期时间打交道,个人常用datetime模块下的date格式,因为这和excel中的日期格式可以很好的结合起来,且在代码中也方便做各种处理。
常用方法如下:
import datetime
select_date = datetime.date(2021,4,8) #手动设置日期
select_date = datetime.date.today() #今天
select_date = datetime.date.today() - datetime.timedelta(days=n) #减是往前的第n天,加号反之,days可以换成其他不过不能加减月份
select_date = select_date.date() #清洗带有多余信息的date格式,或timestamp格式
select_date = (pd.to_datetime(x)).date() #字符串x转date格式
select_date = (datetime.datetime.fromtimestamp(x)).date() #转换int格式记录的timestamp为date格式
date_str = select_date.strftime("%Y%m%d") #date格式转字符串,根据需要还可以是%Y-%m-%d,%m%d,%Y-%m-%d %H:%M:%S"等
除此之外,还有一个库可以解析所有常见的日期表达形式,有时候用这个也十分方便
from dateutil.parser import parse
parse('2021-01-01') #出来的是datetime.datetime格式
# python书上原话:dateutil可以解析几乎所有人类能够理解的日期表示形式
# 在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题
8. xw插入行并复制内容
sht.api.Rows(3).Insert() #在第三行上面插入一行
sht.api.Rows(4).Copy(sht_输出.api.Rows(3)) #原第三行现在变成第四行,复制第四行内容粘贴到第三行,若有公式则自动变化适配到第三行,
"""同样需要注意同第5条所说的自动更新问题"""
9. xw遍历sheet,按需选取
需求场景:表中sheet数量是动态的,无法固定设置是哪些sheet,又需要一次取完所有满足要求的sheet
filepath = xxx
wb = app.books.open(filepath)
sht_list = list(wb.sheets) #读取全部的sheet
sht_strlist = [str(x) for x in sht_list]
sht_strlist = [x[x.index(']')+1:-1] for x in sht_strlist] #获取sheet的名字,字符串形式
df_list = []
for sht_name in sht_strlist:
#判断部分,是不是需要的sheet
list_index = sht_strlist.index(sht_name)
sht = wb.sheets[sht_list[list_index]]
df = pd.DataFrame(sht.used_range.value)
#数据处理部分
df_list.append(df)
# 读取数据
if 'xxx' in sht_strlist: #xxx是一个sheet name
idx = sht_strlist.index('xxx')
df_xxx = df_list[idx]
#后续处理...
10. 列字母与列数字转化
比如C列可以用3访问,那54对应的是哪一列呢
from openpyxl.utils import get_column_letter, column_index_from_string
# 根据列的数字返回字母
print(get_column_letter(2)) # B
# 根据字母返回列的数字
print(column_index_from_string('D')) # 4
11. dataframe重置多层表头为单层表头
通常在使用pd.pivot_table时,若设置了columns,则会在结果出现多层表头的dataframe

为了进行后续处理,需要将这个表转化成下图的样子

str1 = list(pvt.columns.get_level_values(0)[:2])
str2 = list(pvt.columns.get_level_values(0)[2:])
str3 = list(pvt.columns.get_level_values(2)[2:])
str4 = []
for i in range(len(str2)):
str4.append(str2[i]+"-"+str3[i])
new_column = str1 + str4
pvt.columns = new_column
"""
核心就是使用df.columns.get_level_values(0)这样的句子提取每一层的内容
类似的还可以把表头某一部分与表中某一行内容结合等
最后都要以列表的形式赋值给表头
"""
12. 代码替代excel公式(pandas列计算)
在excel中写入大量逻辑公式不仅阅读不便,也会让表格变得十分卡顿。作为替代,在pandas中就可以轻松写出复杂的业务逻辑,进行大量运算。其中主要的就是进行列之间的运算。
个人常用方法如下
#直接数值计算
df['新增列'] = df['A'] + df['B'] #加减乘除
#简单单列处理
df['新增列'] = df['A'].apply(lambda x: (pd.to_datetime(x)).date())
#复杂单列和多列处理,定义函数
def func(x,y,z):
....
df['新增列'] = df.apply(lambda x: func(x['A'], x['B'], x['C']), axis=1)
13. 数据拼接concat和merge
详细的介绍网上很多了,只简单说下实际体会
1)concat虽可以设置axis,但个人只用过纵向拼接(即axis=0),它适用于将多个不同来源、有公共字段的数据拼在一起,生成一个综合的数据集后续可以进行pivot等更多操作
2)merge常用于横向拼接,类似于SQL中的join操作很好理解,常用于对某几个计算结果的合并
在选用时要清楚自己需要的数据结构,虽然不常见但确实可能出现用错方法的情况
14. 遍历文件夹下所有文件
# 文件夹下多个文件
filepath_list = []
for filename in os.listdir(readpath):
if filename[0] == "~": #隐藏文件,这个可以不要
pass
else:
filepath_list.append(os.path.join(readpath, filename))
# 文件夹下多个子文件夹
if os.path.isdir(filepath):
ItemPathList = [] #子文件夹名
for dirs in os.walk(filepath):
for dir in dirs:
ItemPathList.append(dir)
result = pd.DataFrame()
if len(ItemPathList[1])<80: #此处设置子文件夹数量小于80预警
print(f'{filedate}数据量异常,需要重新导出')
for i in ItemPathList[1]:
filename = filepath + "\\" + i + "\\" + "base_data.csv" #此处子文件夹下只有一个文件,若多个再套一个循环读取
df = pd.read_csv(filename)
...
15. 存档数据更新,并封装为一个函数
数据存档表是专用存档的,里面的数据应是结构化的,且无其他无关数据区域
个人使用中以日期为索引,管理并更新数据。比如一个excel存档中有已有3.1-4.10的数据,现在在python中处理好了4.8-4.15的数据,把这部分数据更新到存档中,因为按日期索引,算法会先删去原数据中重合的4.8-4.10部分,再将新的数据拼接上去,实现更新。
需要频繁更新各种数据表时,调用这个就很方便
def UpdateData(filepath,df_new,sheet_name=0):
app = xw.App(visible=False,add_book=False)
app.display_alerts = False
app.screen_updating = False
try:
wb = app.books.open(filepath)
sht = wb.sheets[sheet_name]
df_present = pd.DataFrame(sht.used_range.value)
df_present.columns = df_present.iloc[0].values#重置表头
df_present.drop(0,inplace=True)
df_present['日期'] = df_present['日期'].apply(lambda x: x.date()) #转换日期格式
#刷新数据
new_date = list(df_new['日期'].unique())
df_present = df_present[df_present['日期'].apply(lambda x: False if x in new_date else True)]
result = pd.concat([df_present,df_new])
result = result.sort_values(by="日期" , ascending=True)
#写入
sht.used_range.clear_contents()
sht.range(1,1).options(expand='table', index=0, header=1).value = result
wb.save()
wb.close()
app.quit()
print(str(sheet_name)+"数据刷新数据完成")
except Exception as e:
app.quit()
print(type(e), e)
这个功能因为使用xlwings对表操作,会受到第5.5点所提到的限制,若要实现更大的适用范围,只需用pd.read/save对关键步骤稍作改写即可
如果不是按日期,比如按某字符串字段管理表格,也可以在此基础上修改得到
效果大概如下

16. vlookup功能的类似实现
excel中的vlookup的使用场景之一,是有一个汇总信息的sheet,相关的数据会在这里匹配对应的值
比如python中获得一个数据集 df 后,其中有一列ID不知道对应的谁,已知ID对应的姓名关系保存在一个excel中
1)如果是整列处理的话,直接把对应关系读取进来,merge到df上就可以了
2)如果逐行操作或其他个别操作,可以考虑将excel中的对应关系转成一个字典,需要的时候去匹配字典值即可
核心就是关于读取excel两列转成字典的操作:
dict_user = df_vpuser.groupby('人员ID')['姓名'].apply(lambda x: list(x)[0]).to_dict()
# 常用的是把两列转成one key one value,其实也可以将多列转成one key multi_value,根据需要选择
17. 数据去重的处理(pivot_table和groupby)
常见的在某一列计算时需要去重计数,可在pivot_table中实现
pvt = pd.pivot_table(
temp,
index=['xxx','xxx','xxx'],
values=['订单总价($)', '订单号'],
aggfunc={
'订单总价($)':'sum',
'订单号': lambda x: len(x.unique()) #unique即实现去重,len即计数
}
)
若不是直接计数,需要在去重后进行一些其他处理(主要涉及到字符串处理),可以用groupby实现,示例如下
a = df_select.groupby(['销售商品SKU', '交易状态'])
temp_list = list(a)
result = pd.DataFrame() #收集结果
for i in range(len(temp_list)):
x = temp_list[i][1] #逐个获取groupby的每一组数据
max_difference = x['商品数量'].max() - x['商品数量'].min()
unique_num = len(x['订单号'].unique()) #去重订单数
trade_str = str(list(x['订单号'].unique())) #简单组合去重后的订单号
money = x['订单总价($)'].sum()
df = x.head(1).copy() #只摘取一行数据,用于后面concat
df['订单数'] = unique_num
df['销售数量最大差值'] = max_difference
df['商品订单总价'] = money
df['订单号'] = trade_str
df = df[['销售商品SKU','交易状态','销售数量最大差值','订单数','商品订单总价','订单号']]
result = pd.concat([result, df], ignore_index=True)
"""
核心就是groupby之后的对象转成列表,然后用x = temp_list[i][1]这样的句子逐项获取每一个分组,这每一个分组就是一个dataframe,可以进行很多操作
每次处理完后就整理成一行数据的格式,拼接到结果集上面去
对于简单的去重计数,groupby和pivot_table都可以实现,且结果一样
"""
18. 压缩包解压
"""解压gz格式压缩包"""
import gzip
gz_file_path= r'D:\test\xxxx.csv.gz'
g = gzip.GzipFile(mode="rb", fileobj=open(gz_file_path, 'rb'))
with open(gz_file_path[:-3], "wb") as f:
f.write(g.read())
"""解压zip文件"""
import zipfile
import os
zip_file_path= r'D:\test\xxxx.csv.zip'
cache_path = .... #解压路径
with zipfile.ZipFile(zip_file_path, 'r') as f:
#因为zip文件可以压缩多个文件,需要遍历
for fn in f.namelist():
f.extract(fn, cache_path) # 解压,解压后中文会乱码或者不是需要文件名,下面处理
# x = fn.encode('cp437').decode('gbk') # 因为zipfile 会将所有文件名用 CP437 来编码
# x = x.replace(':', '_') # 冒号不能出现在文件名中,替换掉
fn = fn.replace(':', '_') #此处是文件名中带有时间标记,系统中解压文件已经自动把冒号替换成下划线,这里替换掉才能在下一步对应上
a_path = cache_path + '\\' + fn #原解压文件路径
b_path = zip_file_path[:-4] #需要的文件路径
os.rename(a_path, b_path) # 按可识别中文重命名路径
19. 自动发送邮件(简易)
举例一个需要发送正文、落款中带图片、需要添加附件的邮件
问题:
1、有很多邮件的构造类型和方法,没详细研究,只是折腾出一个能用的
2、目前没有解决怎么在原有邮件基础上回复全部,每次只能发新邮件
3、偶尔出现个别收件人收到邮件显示邮件损坏,无法打开,也未知原因。可能是因为他在群组邮箱中,可以尝试单独列出来作为收件人,不保证一定解决问题。
4、登录失败的时候,多重试几次也就好了
import smtplib
from email.mime.text import MIMEText # 导入 MIMEText 类
from email.mime.multipart import MIMEMultipart #导入MIMEMultipart类
from email.mime.image import MIMEImage #导入MIMEImage类
from email.mime.base import MIMEBase #MIME子类的基类
from email import encoders #导入编码器
from email.utils import formataddr
from loguru import logger
import datetime
"""自动发送日报邮件"""
def ReportDaily(file_date):
sender = 'xxx' # 发件人邮箱账号
password = 'xxx' # 发件人邮箱密码
to_receiver = ['xxx','xxx'] # 收件人邮箱账号
cc_receiver = ['xxx','xxx','xxx',....,'xxx'] # 抄送人邮箱账号
receiver = to_receiver + cc_receiver #注意最后发送邮件用的,需使用列表传入所有联系人,用字符串拼接在一起的话("xxx,xxx,xxx")只会发给第一个人
try:
#构造邮件对象MIMEMultipart对象,采用related定义内嵌资源邮件体
msg = MIMEMultipart('related')
msg['From'] = sender # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To'] = ";".join(to_receiver) #多个收件人,转成以;分隔的字符串
msg['Cc'] = ";".join(cc_receiver) #多个抄送人,转成以;分隔的字符串
# 这里收件、抄送只用于邮件头显示,实际发送使用的是前面定义的列表变量
msg['Subject'] = "日报-{d}".format(d = file_date) # 邮件的主题,也可以说是标题
#创建一个MIMEText对象,HTML元素包括文字与图片
text = """
...正文...

#注border=0,图片无边框
...落款...
"""
text_plain = MIMEText(text,'html', 'utf-8')
msg.attach(text_plain)
##图片
try:
sendimagefile = open(r'D:\test\logo.jpg','rb').read()
except FileNotFoundError:
sendimagefile = open(r'D:\test\logo.png','rb').read()
image = MIMEImage(sendimagefile)
image.add_header('Content-ID','logo') #指定文件的Content-ID,![]() ,在HTML中图片src将用到
msg.attach(image)
#构造附件
sendfile = open(f'D:\test\日报-{file_date}.xlsx','rb').read()
attachfile = MIMEBase('applocation','octet-stream') #创建对象指定主要类型和次要类型
attachfile.set_payload(sendfile) #将消息内容设置为有效载荷
attachfile.add_header('Content-Disposition','attachment',filename=('utf-8','',f'日报-{file_date}.xlsx')) #扩展标题设置
encoders.encode_base64(attachfile)
msg.attach(attachfile)
print("msg完成")
server = smtplib.SMTP_SSL("smtp.xxx.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
print("server创建成功")
server.login(sender, password) # 括号中对应的是发件人邮箱账号、邮箱密码
print("登录成功")
server.sendmail(sender, receiver, msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
print("邮件发送成功")
except Exception as e:
print("邮件发送失败")
print(type(e), e)
file_date = (datetime.date.today() - datetime.timedelta(days=1)).strftime("%m%d") #默认减一,取昨天的日期
ReportDaily(file_date)
,在HTML中图片src将用到
msg.attach(image)
#构造附件
sendfile = open(f'D:\test\日报-{file_date}.xlsx','rb').read()
attachfile = MIMEBase('applocation','octet-stream') #创建对象指定主要类型和次要类型
attachfile.set_payload(sendfile) #将消息内容设置为有效载荷
attachfile.add_header('Content-Disposition','attachment',filename=('utf-8','',f'日报-{file_date}.xlsx')) #扩展标题设置
encoders.encode_base64(attachfile)
msg.attach(attachfile)
print("msg完成")
server = smtplib.SMTP_SSL("smtp.xxx.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
print("server创建成功")
server.login(sender, password) # 括号中对应的是发件人邮箱账号、邮箱密码
print("登录成功")
server.sendmail(sender, receiver, msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
print("邮件发送成功")
except Exception as e:
print("邮件发送失败")
print(type(e), e)
file_date = (datetime.date.today() - datetime.timedelta(days=1)).strftime("%m%d") #默认减一,取昨天的日期
ReportDaily(file_date)
20. 连接数据库
python接入数据库可以直接把数据拿到pandas中处理,有时不用在sql中写复杂的逻辑取数,只需要把基础数据集取下来即可
这个也是多的不懂,只是搞了个能用的
import pymysql
from sshtunnel import SSHTunnelForwarder #因为登录公司远程数据库,使用到跳板机
def get_data(sql_text):
with SSHTunnelForwarder(
('address', port), # 指定ssh登录的跳转机的address,端口号
ssh_username='xxx', # 跳转机的用户
ssh_password='xxx', # 跳板机用户的密码
remote_bind_address=('address', port)) as server: # mysql服务器的address,端口号
conn = pymysql.connect(host='xxx',
port=server.local_bind_port,
user='xxx', # 数据库用户名
passwd='xxx', # 数据库密码
charset='utf8',
db='xxx', # 数据库名称
autocommit=False) # 如果修改数据库自动提交
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_text)
result = cursor.fetchall()
data = pd.DataFrame(result)
cursor.close() # 关闭游标
conn.close() # 关闭连接
return data
sql = "select * from table_test"
get_data(sql)
22. Jupyter Notebook引用自己写的代码文件
在PyCharm中可以直接Import自己写的功能,这个功能在notebook中需要稍微配置一下
先在notebook目录下放一个py文件,里面贴入如下内容
import io, os,sys,types
from IPython import get_ipython
from nbformat import read
from IPython.core.interactiveshell import InteractiveShell
class NotebookFinder(object):
"""Module finder that locates Jupyter Notebooks"""
def __init__(self):
self.loaders = {
}
def find_module(self, fullname, path=None):
nb_path = find_notebook(fullname, path)
if not nb_path:
return
key = path
if path:
# lists aren't hashable
key = os.path.sep.join(path)
if key not in self.loaders:
self.loaders[key] = NotebookLoader(path)
return self.loaders[key]
def find_notebook(fullname, path=None):
"""find a notebook, given its fully qualified name and an optional path
This turns "foo.bar" into "foo/bar.ipynb"
and tries turning "Foo_Bar" into "Foo Bar" if Foo_Bar
does not exist.
"""
name = fullname.rsplit('.', 1)[-1]
if not path:
path = ['']
for d in path:
nb_path = os.path.join(d, name + ".ipynb")
if os.path.isfile(nb_path):
return nb_path
# let import Notebook_Name find "Notebook Name.ipynb"
nb_path = nb_path.replace("_", " ")
if os.path.isfile(nb_path):
return nb_path
class NotebookLoader(object):
"""Module Loader for Jupyter Notebooks"""
def __init__(self, path=None):
self.shell = InteractiveShell.instance()
self.path = path
def load_module(self, fullname):
"""import a notebook as a module"""
path = find_notebook(fullname, self.path)
print ("importing Jupyter notebook from %s" % path)
# load the notebook object
with io.open(path, 'r', encoding='utf-8') as f:
nb = read(f, 4)
# create the module and add it to sys.modules
# if name in sys.modules:
# return sys.modules[name]
mod = types.ModuleType(fullname)
mod.__file__ = path
mod.__loader__ = self
mod.__dict__['get_ipython'] = get_ipython
sys.modules[fullname] = mod
# extra work to ensure that magics that would affect the user_ns
# actually affect the notebook module's ns
save_user_ns = self.shell.user_ns
self.shell.user_ns = mod.__dict__
try:
for cell in nb.cells:
if cell.cell_type == 'code':
# transform the input to executable Python
code = self.shell.input_transformer_manager.transform_cell(cell.source)
# run the code in themodule
exec(code, mod.__dict__)
finally:
self.shell.user_ns = save_user_ns
return mod
sys.meta_path.append(NotebookFinder())
完了就是这样

之后在码字的时候使用import Ipynb_importer激活这个功能,就可以引用啦
import Ipynb_importer
import basic_function as bf
放在一起偶尔会出现问题,所以第一句我会单独放一个cell,大概效果如下
23. 按某列空白值折叠表格
比如源数据中一个订单号下面有多个商品会做展开,然而我只需要订单维度的数据,即按订单收起数据使订单列没有空值

df.dropna(subset=['订单号'], inplace=True) # 摘掉空值
24. 对某列空白值做向下填充
还是上面那个例子,现在要做商品维度的数据,需要对订单号向下填充,按商品收起数据,这样就保留每个商品出单的订单号
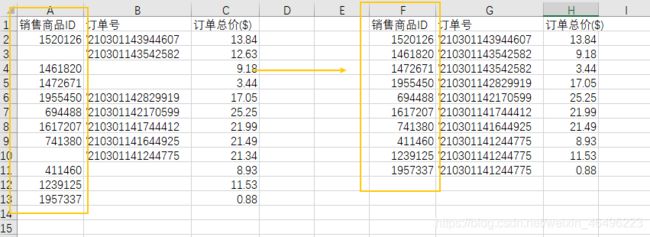
df['销售商品ID'].fillna(method='ffill', inplace=True) #参数ffill就是取前一个值填充
df.dropna(subset=['销售商品ID'], inplace=True) # 摘掉ID列的空值
25. 模拟键鼠操作浏览器(了解)
主要是借助selenium这个库,需要结合xml解析、正则式查找等方法定位网页元素位置,执行模拟的点击、输入等操作
实际工作中受限于一些具体情况,没有能够实际运用过
多的也没搞懂
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
options = Options()
options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe" #浏览器路径,好像只能用指定chrome版本
driver = webdriver.Chrome(executable_path = r'D:\test\chromedriver.exe',options=options) #驱动,需要单独去下载一个
driver.get('https://www.baidu.com') #打开网址
wait = WebDriverWait(driver,10)
"""
Selenium的官方文档说,不同的WebDriver和浏览器行为可能会有所不同。有的浏览器不一定等web页面完全加载完成,就返回了。
当然通常我们希望的是加载完毕,再返回,不然可能页面上有的元素还没有出现,后续的操作可能有问题。
这样还需要加入一些其他的代码等待某个关键的页面元素出现再进行后续操作。
Selenium 3的Chrome WebDriver驱动相应的chrome浏览器是会等待页面完全加载完成才返回的。
"""
26. 删除变量释放内存
删除变量指令本身很简单
import gc
result = pd.DataFrame()
for x in filepath_list:
temp = fromDataToDataframe(x)
result = pd.concat([result,temp], ignore_index=True)
del temp #删除变量释放空间,否则容易爆内存
gc.collect()
time.sleep(1)
需要知道的是python对变量和内存的分配,上面的例子中每一次循环temp都是体积大于3G的文件集,然而每一次temp并不是覆盖上一次的temp,而是新分配一个内存地址出来,temp在新的一轮循环中指向新的地址,之前的变量的数据依然存在于内存中,所以随着循环次数增加,内存占用量会急速上升,很容易就内存不足。
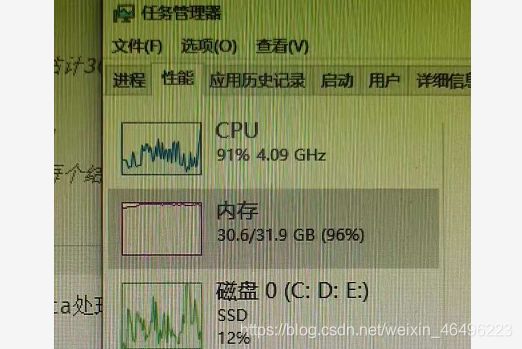
这个时候首先尝试优化程序,及时删除变量释放内存。
实在不行,加内存。
使用虚拟内存是很糟糕的选择,因为固态的读写速度只是内存条的零头,会让运行时间直接往10倍去翻

27. 一些不常见的报错
27.1 dataframe保存csv编码错误UnicodeEncodeError
对此有经验的请教教我啊!
在保存csv文件时遇到过编码错误
UnicodeEncodeError: 'utf-8' codec can't encode characters in position xxxx-xxxx: surrogates not allowed
根据网上其他博文的说法是因为python没有办法对这个字符串利用utf-8进行解码,因为没有合适的字符映射到该编码,大部分问题出现在字符串中存在以\u开头的字符串,python会认为这是一个unicode编码,于是想办法把它解码成一个字符串,但发现编码映射表中没有这样的字符与之对应(可能这个编码是一个emoji表情)
实际上我所遇到的情况极有可能就是某一个地方的字符有emoji表情,但是具体在那个位置很难(几乎无法)定位出来,对此我并没有十分有效的解决办法(下面会提供一个很暴力的解法),试图找过类似于统一dataframe编码格式的方法,并没有什么结果。
考虑到这个数据是从data数据文件中解析出来的,我尝试过指定编码格式和异常处理方式来打开原文件:
with open(dataFilePath,'r',encoding='utf-8',errors='replace') as f:
...
即便如此,在后续保存时依旧会报错
网上说可以对这类异常的字符串进行如下操作:x.encode('utf-8', 'replace').decode('utf-8'),但是对于dataframe并不能直接应用这种方法,我想到的只有使用applymap遍历了…经过实际的尝试,有如下暴力处理方法:
def error_handle(data):
def replace_item(x):
try:
str(x).encode('utf-8')
return x
except UnicodeEncodeError:
print('出现一次编码错误')
return np.nan
data = data.applymap(lambda x: replace_item(x))
return data
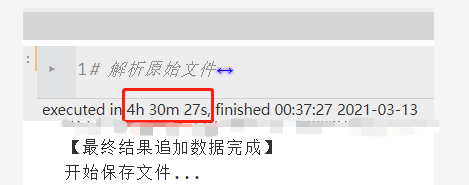
这种全部遍历会运行较长时间,同时在文件体积足够大时,出现了下一个问题
27.2 内存不足MemoryError
对此有经验的请教教我啊!
对于上条记录的使用场景,一般都是百万行的数据处理,虽然处理起来很吃内存但是也能够完成。但是在一次处理千万行数据的过程中,报出了内存错误
MemoryError: Unable to allocate 4.44 GiB for an array with shape (40, 14899795) and data type object
当时是执行到applymap这一步报错了,内存容量上还富裕15G,所以应该不是内存不够导致的。对于这个问题网上也没有找到有效的解决方案,我大概猜测是jupyter notebook一次性能分配的内存是有限制的。找到一篇类似情况的文章:链接
按其方法加大上限后,依旧报错(可能是分配的上限还是不够大),最后没办法只有减小数据量,拆分成两个数据分别保存。