《Python爬取求职网第三天》——反爬虫和汇总表格
一、反爬虫
1、反爬虫介绍
反爬虫是网站限制爬虫的一种策略。它并不是禁止爬虫(完全禁止爬虫几乎不可能,也可能误伤正常用户),而是限制爬虫,让爬虫在网站可接受的范围内爬取数据,不至于导致网站瘫痪无法运行。
具体网站有哪些反爬虫措施参考文章:关于反爬虫,看这一篇就够了
2、爬取计划A:请求头(Request Headers)
通过qq音乐官网为例来讲下其中一个反爬虫的措施请求头。
我们打开qq音乐官网,按键盘上的F12打开开发者工具,点击Network标签,然后在Name(请求名称)列下随便点击一个打开
Tips:Network 记录的是从打开浏览器的开发者工具到网页加载完毕之间的所有请求。如果你在网页加载完毕后打开,里面可能就是空的,我们开着开发者工具刷新一下网页即可。
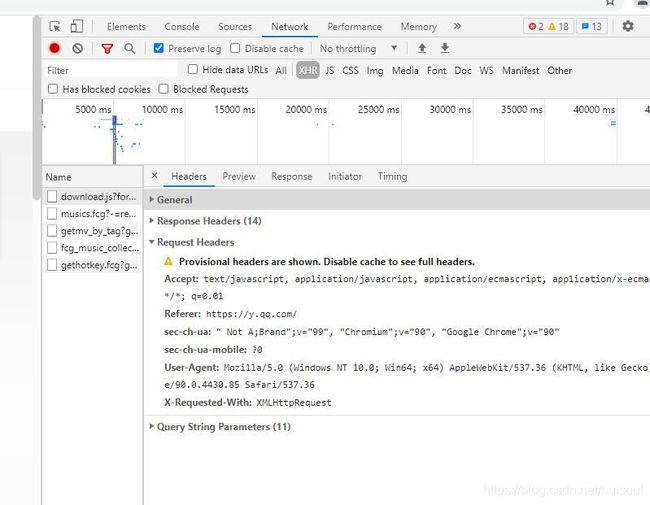
在Request Headers(请求头)下存储的就是我们访问网站时用于身份识别的信息。服务器会通过请求头里的信息来判别访问者的身份。
Tips:访问一般的网站,请求头中只需要添加User-Agent就够了,而有的网站比如微博就需要把Referer等其他请求头信息加进去,具体网站是以哪个为主要识别身份的,那么只能在实战中一个个试了。
既然知道了网站是如何识别用户身份的,我们就可以把请求头加在requests里,例如↓
import requests
from bs4 import BeautifulSoup
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
如果还要添加其他请求头字段,只用在header里以逗号为分隔隔开就好了。
3、爬取计划B:设置爬取睡眠的时间
如果我们访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制我们的 IP 访问该网站。只要我们不过分,弄到服务器负荷过大,网站还是不会限制我们的。因此,我们常常使用 time.sleep() 来降低访问的频率,其实就等于给武器冷却下,避免炸膛。
例如对某个网页进行50页的爬取时↓
import time
----中间代码省略----
for k in range(1,50):
url = 'xxx网页链接'.format(k)
time.sleep(2) #爬取一页睡眠2s
browser.get(url)
通过上面的代码,我们就将访问频率降了下来,虽然爬取速度被减慢了,但怎么也好过爬取不了吧= =
其他的爬取计划就不制定了,这两个已经足够我们后续的爬取,想要了解更多的可以参考:史上最全反爬虫方案汇总
4、robots.txt
robots.txt 是一种存放于网站根目录下的文本文件,用于告诉爬虫此网站中的哪些内容是不应被爬取的,哪些是可以被爬取的。我们只要在网站域名后加上 /robots.txt 即可查看。
二、保存爬取数据到Excel
1、导入模块
from openpyxl import Workbook # 从 openpyxl 引入 Workbook(工作簿)类
2、使用openpyxl创建Excel表格
from openpyxl import Workbook # 从 openpyxl 引入 Workbook(工作簿)类
wb = Workbook() # 选择默认的工作表
sheet = wb.active # 给工作表重命名
sheet.title = 'Python' #设置表格内的标题
wb.save('Python爬取求职网第三天.xlsx') # 保存 Excel 文件
文件夹截图↓

保存的Excel文件默认存放在Python代码同目录下,这里我们能看到通过上面的代码,一个名为‘学习Python第三天’的Excel表格已经生成了。
3、往创建的表格内存放数据
存放数据的方法一般分为:格输入和行输入
- 格输入↓
sheet['A1'] = '天数' # 往 A1 单元格写入天数
- 行输入↓
如果只有一行数据的时候,我们可以通过将各单元格的值以逗号分隔,将其装进一个列表内。
row = ['天数', '文章名', '点赞数']# 写入一行数据
sheet.append(row) #调用append()函数把以一行数据填进表格
但大多数情况下,我们输入的数据绝不止仅仅一行而已,面对多行数据时,我们需要用一个for循环遍历这个列表,然后一行行地把数据填进表格内。我们通过下面的代码看看面对大多数情况是如何存放数据的。
存放数据进Excel的完整代码↓
from openpyxl import Workbook
wb = Workbook() # 新建工作簿
sheet = wb.active # 选择默认的工作表
sheet.title = 'Python' # 给工作表重命名
data = [
['天数', '文章名', '点赞数'],
['第一天', 'Selenium', 0],
['第二天', 'requests和BeautifulSoup', 1],
['第三天', '反爬虫和写入文件', 2]
]
# 写入多行数据
for row in data:
sheet.append(row)
wb.save('Python爬取求职网第三天.xlsx') # 保存 Excel文件
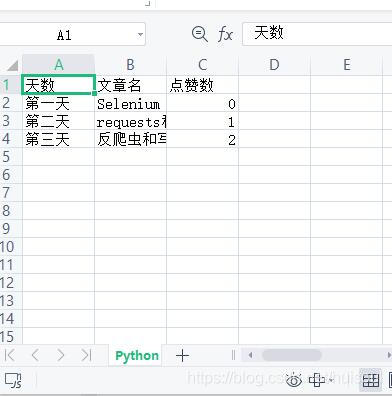
Excel表格内容截图↓
三、保存爬取数据到Csv
保存数据的文件格式除了Excel之外,还能选择保存为.Csv文件,方法只和Excel有些许不同,更重要的是相比较之下,保存为.csv的方法要更加的方便。
1、CSV介绍
CSV 全称 Comma-Separated Values,它是一种通用的、相对简单的文件格式。和 JSON 一样,CSV 也是按照一定规范书写的文本。xlsx 格式的文件是二进制的,只能被 Excel 打开。而 CSV 格式的文件是纯文本,当用 Excel 打开 CSV 文件时,会将其解析成表格形式展示。和 xlsx 文件相比,CSV文件占用空间和内容小,打开的速度也更快。但CSV文件功能受限,不能存储图表、公式、图片等。
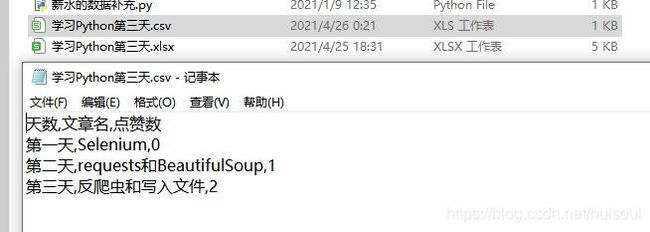
用记事本打开的话,它的名称逗号分隔值一样,每列数据都是用英文逗号分隔开的。而每行数据用换行符分隔,也就是每行数据都换行
2、导入模块
import csv
3、读取csv文件
我们把前面“Python爬取求职网第三天”的xlsx文件,将其后缀名更改为csv文件后为例

import csv
with open('学习Python第三天.csv', newline='') as file: #参数newline=''是为了让文件内容中的换行符能被正确解析
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
通过 import csv导入 csv库,然后用 open()函数打开 csv文件,将得到的 file对象传入 csv.reader() 方法进行处理,最终得到一个可读取对象。我们可以用 for循环遍历得到的可读取对象 csv_reader获取 csv 文件中的每一行数据。
Tips:如果出现编码格式错误的话,可以在open()函数里增加一个encoding参数,如‘utf-8’,‘gbk’,‘gb18030’等。
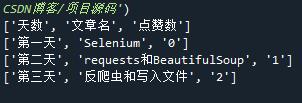
输出结果↓
4、CSV文件写入
与数据存入Excel表格的方法有些许不同,首先还是导入 csv 库,接着用 w 模式(写入模式)新建一个 csv 文件,然后将得到的 file 对象传递给 csv.writer() 方法进行处理,得到一个可写入对象,接下来就可以用它来写入 csv 文件了。
代码↓
import csv
with open('学习Python第三天.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
data = [
['天数', '文章名', '点赞数'],
['第一天', 'Selenium', 0],
['第二天', 'requests和BeautifulSoup', 1],
['第三天', '反爬虫和写入文件', 2]
]
for row in data:
csv_writer.writerow(row)
和 openpyxl 类似,CSV 文件也能逐行写入,openpyxl 调用的是 append() 方法,而 CSV供了一个更加快捷的写入多行内容的方法——writerows(),通过该方法不再需要使用 for 循环,直接将多行数据的二维列表传进去即可将表格的一行内容按顺序放到列表中作为参数传进去即可
好了,三篇文章已经把爬取网站前期准备介绍完了,下一篇文章将会向大家上一个实例,分享一下爬取一个网站的方法。
本次分享就到这里,谢谢大家!