浅入浅出redis----II
文章目录
-
- 事务
- 持久化
-
- RDB
- AOF
- 发布订阅
- 主从复制
-
-
- 哨兵模式
-
- redis缓存穿透、击穿和雪崩
-
-
- 缓存穿透
- 缓存击穿
- 缓存雪崩
-
事务
和mysql一样,redis的事务就是一组命令的集合,在事务执行过程中,会按照顺序执行;不一样的是,redis的单条命令是保证原子性的,但是redis的事务不保证原子性。redis事务也没有隔离级别的概念;
-
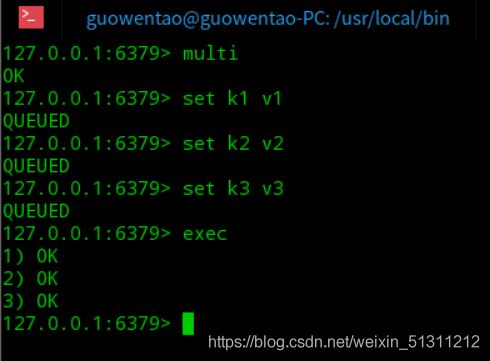
开启事务 – multi
-
命令入队 – …
-
执行命令 – exec
-
放弃事务 – discard
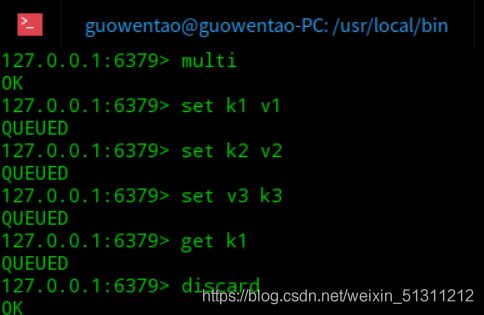
放弃事务后,之前的操作都不会生效
而事务的异常又分两种:编译时异常和运行时异常
-
编译时异常
当执行事务时,输入的语句存在是个错误命令时(例如语句参数不正确),整个事务的语句都不会执行
-
运行时异常
当执行事务时,输入的语句存在语法错误时,除了该命令其他命令都正常执行(这一点就和mysql有很大区别)
持久化
redis是基于内存的数据库,没有I/O操作,因此redis数据的读写是单线程的,但是redis本身为了防止服务器异常退出,也支持两种持久化方式,但是此持久本质上是为了下次启动时数据的一个恢复,若是真的想持久的存储数据,mysql还是占优势的。
RDB
原理:redis会单独fork一个子进程在指定的时间间隔内将内存中的数据
快照写入磁盘,恢复时将快照文件读入内存;
持久化数据时会先将数据写入到一个临时的edb文件中,因为将数据写入磁盘需要时间,而在这时间内得保证数据得完整性,(写入磁盘是由子进程进行的,主进程不涉及IO操作,主进程就可以继续处理一些请求,保证了一个高性能)将数据完整的写入临时文件中,再用这个临时文件去替换上一次持久化好的文件
因此它的缺点也很明显,RDB最后一次持久化的数据就可能丢失了(既然是最后一次持久化,就说明数据还没写完主机就宕机了),redis最短时间是60s一次持久化操作,因此它最多丢失前59s处理的数据。
rdb的持久化数据在dump.rdb里边保存着
而rdb持久化触发的条件有三个
-
save规则满足的情况下,会自动触发rdb操作
-
执行flushall命令时,会有参数提示触发rdb操作
-
退出redis时,也会有参数提示触发rdb操作
-
优点:适合大规模数据恢复
-
缺点:
1.需要一定的时间间隔进行持久化操作,如果redis意外宕机,那最后一次持久化的数据就丢失了。
2.fork子进程,需要占用一定的内存空间。
-
AOF
原理:将所有写操作(history)的命令都记录下来,恢复时将所有命令执行一遍。(与RDB不同之处:一个保存的是命令,一个是快照文件(数据))
AOF保存文件是appendonly.aof
redis默认的是RDB持久化方式,AOF需要手动开启,两者不冲突,因为存的东西不一样。而AOF默认持久化方式是每秒执行一次,也有每次操作执行一次持久化的。
-
优点:每一次修改都可以恢复,完整性较高
-
缺点:
1.每秒执行一次的话,最多丢失1s的数据;
2.存储的数据文件大小:aof远远大于rdb
3.aof运行效率慢于rdb
发布订阅
发布订阅是一种消息通信模式,订阅者提前订阅消息,发布者发布消息后,redis推送给订阅者
注意:订阅者订阅后会原地阻塞,等待着发布者发布对应的消息。
主从复制
主从复制就是将一个redis服务器的数据,复制到其他redis服务器,前者和后者分别对应的是主节点和从节点,数据的复制是单向的!
默认情况,所有的redis服务器都是主节点,一个节点可以有多个从节点,从节点需要指出其跟随的主节点
主要作用:
- 数据冗余:主从复制实现了数据的热备份,每写一次数据,都会复制到其从节点上。
- 故障恢复:主节点意外宕机时,从节点可以提供服务,实现快速的故障恢复。
- 负载均衡:主节点和从节点的读写分离,分担了服务器的负载,特别是在写少读多的情况下保证了一个高并发。
- 高可用的基石:主从复制是哨兵模式和集群能够实现的基础。
复制原理:
- **全量复制:**从节点在收到数据库文件后,将其存盘并加载到内存中
- **增量复制:**直接点将新的所有收集到的修改命令一次传给从节点
哨兵模式
自动选取主节点的模式,一般不是哨兵模式时,在主节点服务器异常退出时,从节点还能读到对应的数据只是对应的主节点(老大)状态是offline,当主节点再次上线时,还是之前从节点的主节点。
但是!哨兵模式下!哨兵是一个单独的进程,通过一定的心跳机制(通过发送命令,等待服务器响应)检测着几个服务器,一旦主节点宕机,便随机挑选一个从节点作为主节点,并通过发布订阅机制通知其他节点服务器使其更改配置文件。
一个哨兵进程往往存在隐患,假如这个哨兵也异常退出了,就会出现问题,朝中不可一日无主!
便有了多哨兵模式,就是多个哨兵进程,哨兵之间互相监测,每个哨兵都对每个节点进行检测;
一旦一个哨兵发现主节点宕机后,便会出现主观下线现象,因为一个哨兵并不能拿捏,若其他哨兵也发现了,而且当发现的哨兵数量达到一定的值时,便会进行一次投票来决定新的主节点,这个过程称为客观下线。
-
优点:
-基于主从复制模式,主从复制所有的优点它都有
-主从的主可以切换,故障可以转移,高可用性!
-哨兵模式就是主从模式的升级,选主节点由手动便自动,更方便!
-
缺点:
-哨兵模式的配置很麻烦,选项多。
redis缓存穿透、击穿和雪崩
缓存穿透
缓存穿透是指 用户要查询的数据缓存和数据库都没有,缓存一直不命中,多次去持久层数据库查询,给数据库造成很大压力。
解决办法
1.布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合的则丢弃,从而避免对持久层数据库的查询压力。
2.缓存空对象
当持久层不命中后,及时缓存返回的空对象,同时设定一个过期时间。当再次访问该值时将从缓存中获取,保护了持久层数据。
不足:
-会消耗更多的空间存储更多的key来缓存空值
-对需要保持一直性的业务有影响,可能在过期时间内,该key对应的值被存在数据库永久层里,会导致缓存层和数据层的不一致
缓存击穿
缓存击穿主要针对一些热点key,扛着大量并发,在这个key失效的瞬间,数据层瞬间压力过大甚至崩溃
解决办法
1.热点数据永不过期
根据字面意思很容易知道,在缓存层,热点数据不设置过期时间,所以不存在热点数据过期的问题。
2.加互斥锁
分布式锁:保证每个key同时只有一个线程去查询,其他线程没有获得锁只能等待,对分布式锁的考验大
缓存雪崩
缓存雪崩是在缓存击穿的基础上,大面积缓存数据失效,或者redis宕机,导致大量访问查询都落在数据层,直接崩溃!
解决办法
1.redis高可用
搭建缓存服务器集群。这样一台服务器宕机还可以继续工作
2.数据预热
在正式部署之前,先把可能的数据先访问一遍,这样大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。(这方面阿里老懂哥了!)