Java:从原理入手,自己动手实现一个好用的Excel导入导出工具集
前言
现在市面上已经有很多优秀的excel处理工具组件,比如出自阿里的 EasyExcel,已经很好用了,我们为什么还要自己动手去实现一个呢?
答:因为每个项目需求不一样,万一项目里有一些奇形怪状的需求,现有组件无法很好的满足,是不是需要自己去定制?有现成的工具类固然是一件好事,但是当现成的工具类无法满足当前需求的时候,如果我们能参考这些工具的实现原理,自己去动手撸一个差不多功能的组件,并且加上自己想要的功能,还运用到实际项目中去检验,是不是一件很有成就感的事?
背景
本文准备实现的这个excel读取导出组件是2018年还在上家公司的时候写的,那时做的是一个物联网项目,经常需要做一些导入、导出excel的操作,而且导入、导出的需求中还有一些本来很正常,但是当前组件没有的功能,比如数据表中一个字段(card_type)存的是一个varchar类型的枚举值如下:
![]()
导出的时候我们要导出对应的中文注释,其实这个也比较好弄,要么在查出数据集合的时候在sql语句中就处理好,要么就是查出原始数据后在代码中来转换。
假如现在能在导出工具中自动就处理了呢?
比如我们定义一个注解,注解上有一个字段可以定义要转换的映射关系(如下面TestBean中@ExcelField注解中的parseJson信息),导入导出的时候工具类读取到这个字段定义的映射关系,在读取excel的时候帮我们把表格中的中文转义为英文,写出的时候能帮我们把英文转义成中文并且写到excel表格中,这样是不是很方便?
@ExcelSheet
@Data
public class TestBean {
@ExcelField(name = "卡类型", parseJson = "{'A':'语音卡', 'B':'流量卡', 'AA':'体验卡', 'BB':'流量短信卡','C':'流量池卡', 'D':'短信卡'}")
String cardType;
}
或者导出的时候要求根据不同的用户导出不同的字段,比如导出实体bean中定义了1~9九个字段,要求A用户导出的时候只导出1,2,3,9字段,B用户导出的时候只导出1,4,5,7,9字段,如果这样的需求多了,我们在代码里手动去处理就显得很繁琐。
上面这个需求我故意没实现,就当一个习题吧,看有没有同学能搞定
下面我们就来看看怎么自己动手来优雅的搞定这些需求!
代码中主要应用到了
自定义注解、反射等基础功能,在处理大表的时候,引入了流式处理,避免内存溢出问题,当然这个组件只是实现了最基础的导入导出功能,像单元格合并这些就没去实现,有兴趣的同学在搞清楚原理后可以自己动手去实现一下
下面先把代码贴出来,大家最好建个java项目手动跑一遍验证一下,项目结构如下:

一、引入相关依赖
核心依赖用到了poi(用到了其中的一些类)、流式处理组件xlsx-streamer,其它组件可以选择性依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.yinchdgroupId>
<artifactId>excelartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<slf4j-version>1.7.7slf4j-version>
<log4j-version>1.2.17log4j-version>
<xlsx-streamer-version>2.1.0xlsx-streamer-version>
<commons-lang3-version>3.5commons-lang3-version>
<fastjson-version>1.2.53fastjson-version>
<servlet-version>3.1.0servlet-version>
<poi-version>4.0.1poi-version>
properties>
<dependencies>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>${log4j-version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j-version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j-version}version>
dependency>
<dependency>
<groupId>com.monitorjblgroupId>
<artifactId>xlsx-streamerartifactId>
<version>${xlsx-streamer-version}version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>${poi-version}version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>${commons-lang3-version}version>
dependency>
<dependency>
<groupId>javaxgroupId>
<artifactId>javaee-apiartifactId>
<version>7.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>javax.servlet-apiartifactId>
<version>${servlet-version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>${fastjson-version}version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.18version>
<scope>providedscope>
dependency>
dependencies>
project>
二、定义@ExcelSheet注解
该注解主要用于对应excel文件的sheet表单,name可以指定excel中sheet表单的名称,如果指定了name,在使用ExcelReader读取excel的时候,可以定向去读此name的表单,如果不指定,则默认读取excel中第一个表单,headColor主要用于ExcelWriter导出的时候使用,可以指定导出来的标题行的颜色;
package com.yinchd.excel;
import org.apache.poi.hssf.util.HSSFColor;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Excel与实体之间的映射
* 添加注解的格式为 :
* eg:@ExcelSheet(name="用户列表", headColor=HSSFColor.HSSFColorPredefined.LIGHT_GREEN)
* name:Excel中sheet的名称,headColor:标题头的颜色
* @author yinchd
* @since 2018-02-13
*/
@Target({
java.lang.annotation.ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface ExcelSheet {
/**
* sheet表单名称
*/
String name() default "";
/**
* 统一的表头颜色
*/
HSSFColor.HSSFColorPredefined headColor() default HSSFColor.HSSFColorPredefined.LIGHT_GREEN;
}
excel文件中的sheet表单,表单名称对应name属性
![]()
导出excel的标题颜色,标题颜色对应headColor属性
![]()
三、定义@ExcelField注解
该注解主要标识在字段属性上,用来设置各个字段的参数
package com.yinchd.excel;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 字段注解,用于实体属性与Excel值之间的映射关系
* eg:@ExcelField(name="名称", index=1, width=30*256, parseJson="{'1': '有效', '2': '无效')
* 其中name为必填,其它可以选填
* @author yinchd
* @since 2018-02-13
*/
@Target({
java.lang.annotation.ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface ExcelField {
/**
* 导入时:name的值代表我们导入的excel文件中的列标题,在具体解析excel的过程中,会将实际读到的标题与ExcelField注解中name中定义值的作对比,据此判断导入文件是否合法;
* 导出时:name的值代表是实体字段对应的中文名称,比如有个字段叫‘hobby’,ExcelField注解中name的值是‘爱好’,则导出的excel文件中hobby列的表头为‘爱好’;
* eg:@ExcelField(name = "hobby")
* 默认忽略大小写
*/
String name();
/**
* 列宽,默认会自动根据内容适应宽度
* eg:@ExcelField(width = 30*256)
* 参见org.apache.poi.hssf.usermodel.HSSFSheet#setColumnWidth(int, int)中的参数定义说明
*/
int width() default 0;
/**
* 字段排序权重,用于对字段顺序顺序进行排序,不指定值的话默认按实体中定义的字段顺序排序
* 导入的时候,如果实体中定义的字段顺序和表格中的表头顺序不一致,可以通过指定sortWeight来调整顺序,默认按sortWeight的值从小到大来排序
* 导出的时候也一样,根据sortWeight来调整导出列的顺序
* 注意:有一种情况,有些字段指定了权重,有些没指定,这些没指定的权重值默认值为0,排序的时候会排到前面去,所以这点大家注意一下,
* 所以sortWeight的值要么都指定,要就都不指定,用默认排序就好
*/
int sortWeight() default 0;
/**
* 时间格式
* eg: "yyyy-MM-dd HH:mm:ss" , "yyyy-MM-dd"
*/
String dateFormat() default "yyyy-MM-dd HH:mm:ss";
/**
* 自定义转换参数,导出的时候比如字段值是枚举或者想转义成其它字符,这里可以定义一个json串,key为待转的字段,value为想转义出来值
* eg:convertJson="{'1': '有效', '2': '无效', '3': '正常'}"
*/
String parseJson() default "";
}
三、Excel读取工具:ExcelReader
基本原理是先用StreamingReader(流式引擎)将excel读成workbook,然后我们基于反射的原理来将数据映射成一个个实体
package com.yinchd.excel;
import com.monitorjbl.xlsx.StreamingReader;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.*;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
import java.util.*;
import java.util.stream.Collectors;
/**
* ExcelReader,通过流式方法读取excel,避免读取大文件时出现内存溢出问题
* @author yinchd
* @since 2018/2/14 14:26
**/
@Slf4j
public class ExcelReader {
/**
* 数据格式化工具类
*/
private static final DataFormatter DF = new DataFormatter();
/**
*
* 根据文件路径、数据起始值读取文件到集合 List中
* eg: List personList = ExcelReader.getListByFilePath(filePath, Person.class); // 读全部行
* eg: List personList = ExcelReader.getListByFilePath(filePath, Person.class, 1, 100); // 1, 100 分别为行的下标
*
* @param filePath 文件绝对路径 eg: e:/xxx/xxx.xlsx
* @param clazz 需要将表格内容读成的类型,如: Person.class
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @param 数据类型
* @return List
*/
@SneakyThrows
public static <T> List<T> getListByFilePath(String filePath, Class<T> clazz, int... dataStartOrEndIndex) {
try (Workbook wb = getWorkbookByFile(new File(filePath))) {
return readWorkbook(clazz, wb, dataStartOrEndIndex);
}
}
/**
*
* 根据输入流、数据起始值读取文件到List中
* eg: List personList = ExcelReader.getListByInputStream(inputStream, Person.class); // 读全部行
* eg: List personList = ExcelReader.getListByInputStream(inputStream, Person.class, 1, 100); // 1, 100 分别为行的下标
*
* @param inputStream excel文件输入流
* @param clazz 需要将表格内容读成的类型,如:读成Person类型 eg: Person.class
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @param 数据类型
* @return List
*/
@SneakyThrows
public static <T> List<T> getListByInputStream(InputStream inputStream, Class<T> clazz, int... dataStartOrEndIndex) {
try (Workbook wb = getWorkbookByInputStream(inputStream)) {
return readWorkbook(clazz, wb, dataStartOrEndIndex);
}
}
/**
*
* 读取指定列的数据到List中
* eg: List personList = ExcelReader.getColumnListByFilePath(filePath, 3); // 读第一个sheet的第4列到集合中
*
* @param filePath 文件绝对路径 eg: e:/xxx/xxx.xlsx
* @param columnIndex 要读取列的下标
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @return 指定类型的集合
*/
@SneakyThrows
public static List<String> getUniLineListByFilePath(String filePath, int columnIndex, int... dataStartOrEndIndex) {
try (Workbook wb = getWorkbookByFile(new File(filePath))) {
return getListByColumnIndex(wb, columnIndex, dataStartOrEndIndex);
}
}
/**
* 读取指定列的数据到List中
* eg: List personList = ExcelReader.getColumnListByInputStream(inputStream, 3); // 读第一个sheet的第4列到集合中
* @param inputStream excel文件输入流
* @param columnIndex 要读取列的下标
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @return 指定类型的集合
*/
@SneakyThrows
public static List<String> getUniLineListByInputStream(InputStream inputStream, int columnIndex, int... dataStartOrEndIndex) {
try (Workbook wb = getWorkbookByInputStream(inputStream)) {
return getListByColumnIndex(wb, columnIndex, dataStartOrEndIndex);
}
}
/**
* 根据输入流和指定要读取的sheet下标值来获取表格的物理数据总条数(可能包含空行)
* eg: int count = ExcelReader.getPhysicalRowCountByInputStream(inputStream); // 获取excel文件中第一个表单的物理数据总行数(有可能包含空行)
* @param inputStream excel文件输入流
* @return 可能包含空行的物理数据总条数
*/
public static int getPhysicalRowCountByInputStream(InputStream inputStream) {
try (Workbook wb = getWorkbookByInputStream(inputStream)) {
return getPhysicalRowCountByWorkbook(wb);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 根据输入流获取表格有效数据总条数(不包含空行)
* eg: int count = ExcelReader.getRealRowCountByInputStream(inputStream); // 获取excel文件中第一个表单的真实数据总行数(不包含空行)
* @param inputStream excel文件输入流
* @return 不包含空行的有效数据总条数
*/
public static int getRealRowCountByInputStream(InputStream inputStream) {
try (Workbook wb = getWorkbookByInputStream(inputStream)) {
return getRealRowCountByWorkbook(wb);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
*
* 通过输入流创建workbook,单独调用记得关闭流(上面通过try()的方式会自动关闭流,因为他们实现了AutoCloseble)
*
* @param inputStream excel文件流
* @return Workbook对象
*/
private static Workbook getWorkbookByInputStream(InputStream inputStream) {
try {
return StreamingReader.builder()
.rowCacheSize(100) // number of rows to keep in memory
.bufferSize(4096) // buffer size to use when reading InputStream to file (defaults to 1024)
.open(inputStream);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
*
* 通过文件创建workbook,单独调用记得关闭流
*
* @param file excel文件
* @return Workbook对象
*/
private static Workbook getWorkbookByFile(File file) {
try (InputStream inputStream = new FileInputStream(file)) {
return getWorkbookByInputStream(inputStream);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 根据工作簿对象获取指定sheet表单中除去标题行后的总条数(可能包含空行),默认读取第一个sheet
* @param wb 工作簿对象
* @return 指定sheet中除去首行标题行后的物理数据条数(可能包含空行)
*/
private static int getPhysicalRowCountByWorkbook(Workbook wb) {
Sheet sheet = wb.getSheetAt(0);
return sheet.getLastRowNum();
}
/**
* 获取指定sheet表单中除去空行的实际数据条数
* @param wb workbook
* @return 去空行后的数据总条数
*/
private static int getRealRowCountByWorkbook(Workbook wb) {
Sheet sheet = wb.getSheetAt(0);
int count = 0;
for (Row row : sheet) {
int j = 0, nullCellCount = 0;
for (Iterator<Cell> ite = row.iterator(); ite.hasNext(); j++) {
Cell cell = ite.next();
if (cell == null || StringUtils.isBlank(DF.formatCellValue(cell))) {
nullCellCount ++;
}
}
if (nullCellCount >= j) {
return count;
}
count++;
}
log.debug("excel sheet total row count excluded the empty row is:{}", count);
return count;
}
/**
* 通过反射的方式将表格解析为List集合,并支持指定起始与结束行读取
* 注意:Class clazz 中必须要为需要映射的字段添加@ExcelField(name = "xxx")注解(xxx为excel文件中列的表头),逻辑中会将
* clazz中被注解修饰的字段与excel文件中的列一一对应,name的值与excel文件中列的表头一一对应
* @param clazz 需要将表格内容读成的类型,如:读成Person类型 eg: Person.class
* @param wb 工作簿对象
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @param 数据类型
* @return 指定类型的集合
*/
@SneakyThrows
private static <T> List<T> readWorkbook(Class<T> clazz, Workbook wb, int... dataStartOrEndIndex) {
List<T> dataList = new ArrayList<>();
Sheet sheet = getSheet(clazz, wb);
// 取出所有被@ExcelField修饰的字段
List<Field> fields = Arrays.stream(clazz.getDeclaredFields())
.filter(field -> !Modifier.isStatic(field.getModifiers()) // 非static个包
&& field.isAnnotationPresent(ExcelField.class) // 带@ExcelField修饰的字段
&& field.getAnnotation(ExcelField.class).name().length() > 0) // @ExcelField中name的值不为空
.sorted((f1, f2) -> {
// 根据@ExcelField中指定的index进行排序,如果没有指定index的值,则按照字段读取的自然序来排列
ExcelField f1Anno = f1.getAnnotation(ExcelField.class),
f2Anno = f2.getAnnotation(ExcelField.class);
return f1Anno.sortWeight() - f2Anno.sortWeight();
}).collect(Collectors.toList());
if (fields.size() == 0) {
throw new RuntimeException("请检查实体类中有没有为待解析的字段添加@ExcelField注解");
}
// 存储标题行(默认第一行为标题行,且@ExcelField注释中name的值为excel文件中标题的值,后面会依此来校验导入的文件是不是符合我们自定义的要求
List<String> titles = new ArrayList<>();
// 存储name与field的映射关系,用于精确读取name列下的数据到field中
Map<String, Field> fieldsMap = new HashMap<>();
for (Field field : fields) {
ExcelField anno = field.getAnnotation(ExcelField.class);
fieldsMap.put(anno.name(), field);
titles.add(anno.name().trim());
}
// 如果用户自定义了数据起始与结束行,则使用自定义值,如果没有指定,则默认从第二行开始读(默认第一行为标题行),到最后一行结束
Integer[] idx = getStartAndEndIndex(sheet.getLastRowNum(), dataStartOrEndIndex);
int dataStartIdx = idx[0], dataEndIdx = idx[1];
T targetClass;
int rowIndex = 0;
// StreamReader读取的workbook只是借用了poi的类,不是所有的api都支持,所以这里用的迭代器的形式
for (Iterator<Row> it = sheet.iterator(); it.hasNext() && rowIndex <= dataEndIdx; rowIndex++) {
Row row = it.next();
// 默认第一行为标题行,此处会拿到目标class里@ExcelField(name="id")的注解上的name值与此title里的数据校验
if (rowIndex == 0) {
int cellIndex = 0;
for (Iterator<Cell> rowIt = row.iterator(); rowIt.hasNext() && cellIndex < titles.size(); cellIndex++) {
Cell cell = rowIt.next();
String cellValue = DF.formatCellValue(cell);
if (!StringUtils.equals(cellValue, titles.get(cellIndex))) {
throw new IllegalArgumentException("excel中第"+ (cellIndex + 1) +"列读取到的表头:["+ cellValue +"] " +
"与您在@ExcelField(name = \"xxx\")注解上定义的值不一致,根据您定义的顺序:"+ titles +",该列的值应该为:" +
"["+ titles.get(cellIndex) +"], 请检查您是否指定了注解中index的顺序,如未指定,则检查字段在类中定义的自然顺序");
}
}
} else if (rowIndex >= dataStartIdx) {
// 读取数据行
targetClass = clazz.newInstance();
int j = 0, nullCellCount = 0;
for (Iterator<Cell> ite = row.iterator(); ite.hasNext() && j < titles.size(); j++) {
Cell cell = ite.next();
String cellValue = DF.formatCellValue(cell);
if (StringUtils.isBlank(cellValue)) {
nullCellCount ++;
}
Field field = fieldsMap.get(titles.get(j));
Object fieldValue = StringUtils.isBlank(cellValue) ? "" : FieldReflectionUtil.parseValue(field, cellValue.trim());
field.setAccessible(true);
field.set(targetClass, fieldValue);
}
if (nullCellCount >= j) {
continue;
}
dataList.add(targetClass);
}
}
return dataList;
}
/**
* 读取指定列的值到List中并过滤掉空值
* @param wb 工作簿对象
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @return 字符串类型的集合
*/
private static List<String> getListByColumnIndex(Workbook wb, int columnIndex, int... dataStartOrEndIndex) {
List<String> dataList = new ArrayList<>();
// 默认读取第1个sheet,如果单独指定了需要读取的sheet名称,则读取自定义名称的sheet
Sheet sheet = wb.getSheetAt(0);
// 数据起始行,默认第一行为标题,第二行为数据起始点
Integer[] idx = getStartAndEndIndex(sheet.getLastRowNum(), dataStartOrEndIndex);
int dataStartIdx = idx[0], dataEndIdx = idx[1];
int i = 0;
for (Iterator<Row> it = sheet.iterator(); it.hasNext() && i <= dataEndIdx; i++) {
Row row = it.next();
// 验证标题行
if (i >= dataStartIdx) {
Cell cell = row.getCell(columnIndex);
if (cell == null) {
continue;
}
String cellValue = DF.formatCellValue(cell);
if (StringUtils.isBlank(cellValue)) {
continue;
}
dataList.add(cellValue);
}
}
return dataList;
}
/**
* 计算读取数据的起始行与结束行,如果用户有传值,则读取用户自定义数据范围,如果用户没有传值,则使用默认值
* @param sheetLastRowIndex sheet中最后一行的下标值
* @param dataStartOrEndIndex 数据起始行、数据结束行(非必填,注意,起始和结束行的值都是下标值,下标值是从0开始,如第一行的下标值为0)
* @return 数据起始行与结束行
*/
private static Integer[] getStartAndEndIndex(int sheetLastRowIndex, int... dataStartOrEndIndex) {
int startIndex = 1, endIndex = sheetLastRowIndex;
if (dataStartOrEndIndex != null && dataStartOrEndIndex.length >= 1) {
if (dataStartOrEndIndex.length == 2 && dataStartOrEndIndex[0] <= dataStartOrEndIndex[1]) {
startIndex = dataStartOrEndIndex[0];
endIndex = dataStartOrEndIndex[1];
} else if (dataStartOrEndIndex.length == 1) {
startIndex = dataStartOrEndIndex[0];
}
}
return new Integer[]{
startIndex, endIndex};
}
/**
* 读取工作簿中的默认sheet(默认读取第1个sheet)或者用户指定sheet名称的sheet
* @param clazz 目标类
* @param wb 工作簿
* @return sheet
*/
private static <T> Sheet getSheet(Class<T> clazz, Workbook wb) {
Sheet sheet = null;
if (clazz != null && clazz.isAnnotationPresent(ExcelSheet.class)) {
ExcelSheet sheetAnno = clazz.getAnnotation(ExcelSheet.class);
if (sheetAnno.name().length() > 0) {
sheet = wb.getSheet(sheetAnno.name());
}
}
if (sheet == null) {
sheet = wb.getSheetAt(0);
}
return sheet;
}
}
字段转为真实类型的工具集 FieldReflectionUtil:
package com.yinchd.excel;
import java.lang.reflect.Field;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public final class FieldReflectionUtil {
public static Byte parseByte(String value) {
try {
value = value.replaceAll(" ", "");
return Byte.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseByte but input illegal input=" + value, e);
}
}
public static Boolean parseBoolean(String value) {
value = value.replaceAll(" ", "");
if (Boolean.TRUE.toString().equalsIgnoreCase(value)) {
return Boolean.TRUE;
}
if (Boolean.FALSE.toString().equalsIgnoreCase(value)) {
return Boolean.FALSE;
}
throw new RuntimeException("parseBoolean but input illegal input=" + value);
}
public static Integer parseInt(String value) {
try {
value = value.replaceAll(" ", "");
return Integer.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseInt but input illegal input=" + value, e);
}
}
public static Short parseShort(String value) {
try {
value = value.replaceAll(" ", "");
return Short.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseShort but input illegal input=" + value, e);
}
}
public static Long parseLong(String value) {
try {
value = value.replaceAll(" ", "");
return Long.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseLong but input illegal input=" + value, e);
}
}
public static Float parseFloat(String value) {
try {
value = value.replaceAll(" ", "");
return Float.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseFloat but input illegal input=" + value, e);
}
}
public static Double parseDouble(String value) {
try {
value = value.replaceAll(" ", "");
return Double.valueOf(value);
} catch (NumberFormatException e) {
throw new RuntimeException("parseDouble but input illegal input=" + value, e);
}
}
public static Date parseDate(String value, String pattern) throws ParseException {
if (pattern == null) {
pattern = "yyyy-MM-dd HH:mm:ss";
}
SimpleDateFormat dateFormat = new SimpleDateFormat(pattern);
return dateFormat.parse(value);
}
public static Object parseValue(Field field, String value) throws ParseException {
Class<?> fieldType = field.getType();
if ((value == null) || (value.trim().length() == 0)) {
return null;
}
value = value.trim();
if ((Boolean.class.equals(fieldType)) || (Boolean.TYPE.equals(fieldType))) {
return parseBoolean(value);
}
if (String.class.equals(fieldType)) {
return value;
}
if ((Short.class.equals(fieldType)) || (Short.TYPE.equals(fieldType))) {
return parseShort(value);
}
if ((Integer.class.equals(fieldType)) || (Integer.TYPE.equals(fieldType))) {
return parseInt(value);
}
if ((Long.class.equals(fieldType)) || (Long.TYPE.equals(fieldType))) {
return parseLong(value);
}
if ((Float.class.equals(fieldType)) || (Float.TYPE.equals(fieldType))) {
return parseFloat(value);
}
if ((Double.class.equals(fieldType)) || (Double.TYPE.equals(fieldType))) {
return parseDouble(value);
}
if (Date.class.equals(fieldType)) {
return parseDate(value, null);
}
throw new RuntimeException("request illeagal type, type must be Integer not int , must be Long not long etc, type=" + fieldType);
}
}
写代码验证一下效果
准备一个表格,有6列,总行数为24624,第1行为标题行,第2行到最后一行为数据行,其中第24600行塞了个空行,为了验证程序读取空行的情况
表头
![]()
数据项(随便找了个项目中的文档,因为信息涉密,我这里打点码)
1、获取表格物理总条数(包括空行)
String filePath = "D:\\Download\\test.xlsx";
FileInputStream fis = new FileInputStream(filePath);
int physicalRowCount = ExcelReader.getPhysicalRowCountByInputStream(fis);
System.out.println("表格物理总条数:" + physicalRowCount);
// 表格数据总行数:24624
2、读取表格中有效数据总条数(不包括空行)
String filePath = "D:\\Download\\test.xlsx";
FileInputStream fis = new FileInputStream(filePath);
int realRowCount = ExcelReader.getRealRowCountByInputStream(fis);
System.out.println("表格有效数据总条数:" + realRowCount);
// 表格有效数据总条数:24623
3、读取指定列的数据(根据列下标,或者指定起始行和结束行的下标)注:不包括空行
这里读取第6列(下标为5),第2行(第一行为标题行)到第101行(下标为100)的数据集合
![]()
第6列也即ZJHM(证件号码)这一列,我们来读取试一试(因为是真实数据,号码我模糊处理了),看读取出来的数据能否和表格中一致
第6列的数据第2到第101行的数据总共有:96
第6列的数据第2到第101行的数据为:[***196808192054, ***195502130675, ***196309050070, ***195112292319, ***196807214276, ***198411277530,...., ***198002284519, ***197410182013]
第2行的数据尾号为:2054,跟读取出来的数据对上了

第101行的数据尾号为:2013,与读出来的数据也对上了,证明我们读出来的数据没问题

那为什么打印结果里读取出来的数据总条数只有96行呢?
因为表格里7到11行数据是空的,因为第2行到第101行总共有100条数据,去掉4个没数据的行,只剩96行有效数据,结果也没问题。
当然这个api也可以不用指定读取数据的起始与结束下标,只需指定要读取列的下标值即可,这样就是读取到整列的数据
4、读取整个表格的数据,映射为指定对象集合
我们定义一个实体与表格中的字段对应
import com.yinchd.excel.ExcelField;
import com.yinchd.excel.ExcelSheet;
import lombok.Data;
@Data
@ExcelSheet()
public class ExcelTestBean {
@ExcelField(name = "BMSAH")
String bmsah;
@ExcelField(name = "TYSAH")
String tysah;
@ExcelField(name = "XYRBH")
String xyrbh;
@ExcelField(name = "XM")
String xm;
@ExcelField(name = "ZJLX_MC")
String zjlxMc;
@ExcelField(name = "ZJHM")
String zjhm;
}
LocalTime t1 = LocalTime.now();
String filePath = "D:\\Download\\test.xlsx";
List<ExcelTestBean> all = ExcelReader.getListByFilePath(filePath, ExcelTestBean.class);
System.out.println("表格的详细数据为:" + JSON.toJSONString(all));
System.out.println("all的大小为:" + all.size());
System.out.println("读取整个表格耗时:" + Duration.between(t1, LocalTime.now()).getSeconds() + "s");
这里也可以指定数据的起始与结束行,有兴趣的同学可以试试,如:ExcelReader.getListByFilePath(filePath, ExcelTestBean.class, 1, 100)

至此,我们就将读取的功能基本实现了,当然,大家搞懂了原理,像我上面定义的如parseJson注解属性都可以用起来,这里我不讲太细,想留给感兴趣的同学自己去动手实现
下面来看看excel文件写出要怎么做
四、excel导出工具:ExcelWriter
这里我直接把ExcelWriter的代码贴出来
比如我们查出来了数据集合:List,ExcelTestBean还是上面举例用的实体
如果大家想在导出的时候自定义表单名称,则可以在@ExcelSheet(name="xxx", headColor="xxx")中指定name属性(如果不指定,则表单名称默认为当前日期,eg:2020-04-15),如果想指定标题行的颜色,则可以指定headColor的属性(如果不指定,则默认是浅绿色,大家可以看下注解定义中headColor的默认属性是什么颜色)
package com.yinchd.excel;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.hssf.util.HSSFColor;
import org.apache.poi.ss.usermodel.*;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.UnsupportedEncodingException;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
import java.nio.charset.StandardCharsets;
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;
/**
* Excel写出工具类
* @author yinchd
* @since 2018/2/14
*/
@Slf4j
public class ExcelWriter {
/**
* 导出Excel文件到用户桌面 C:\Users\xxx\Desktop
* @param fileName 文件名称
* @param dataList 数据集合
* @param 对象类型
*/
public static <T> void writeToDesktop(String fileName, List<T> dataList) {
fileName = suffixCheck(fileName);
String filePath = System.getProperties().getProperty("user.home") + "\\Desktop\\" + fileName;
try (HSSFWorkbook wb = createWorkbook(fileName, dataList);
FileOutputStream fos = new FileOutputStream(filePath)) {
wb.write(fos);
fos.flush();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 导出Excel文件到指定路径
* @param fileNameWithPath 完整路径的文件名
* @param dataList 数据集合
* @param void
*/
public static <T> void writeToPath(String fileNameWithPath, List<T> dataList) {
fileNameWithPath = suffixCheck(fileNameWithPath);
try (HSSFWorkbook wb = createWorkbook(fileNameWithPath, dataList);
FileOutputStream fos = new FileOutputStream(fileNameWithPath)) {
wb.write(fos);
fos.flush();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 通过流写出到文件,用于页面下载
* @param fileName 文件名称
* @param dataList 数据集合
* @param response response对象
* @param void
* @throws Exception 异常
*/
public static <T> void writeToPage(String fileName, List<T> dataList, HttpServletResponse response) throws Exception {
fileName = suffixCheck(fileName);
setReponseHeader(fileName, response);
try (HSSFWorkbook wb = createWorkbook(fileName, dataList);
ServletOutputStream out = response.getOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(out)) {
wb.write(bos);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
*
* 组装工作簿
*
* @param fileName 文件名称
* @param dataList 数据集合
* @param dataList中参数类型
* @return 工作簿对象
* @throws Exception 异常
*/
public static <T> HSSFWorkbook createWorkbook(String fileName, List<T> dataList) throws Exception {
if (CollectionUtils.isEmpty(dataList)) {
throw new IllegalArgumentException("待导出的数据不能为空");
}
// 创建工作簿
HSSFWorkbook wb = new HSSFWorkbook();
Class<?> dataClass = dataList.get(0).getClass();
// 表单的名称默认指定为当前日期
String sheetName = LocalDate.now().toString();
// 表头颜色
HSSFColor.HSSFColorPredefined headColor = null;
if (dataClass.isAnnotationPresent(ExcelSheet.class)) {
ExcelSheet sheetAnno = dataClass.getAnnotation(ExcelSheet.class);
if (sheetAnno.name().length() > 0) {
sheetName = sheetAnno.name().trim();
}
// 如果@ExcelSheet注解中指定了headColor,则用指定的颜色
headColor = sheetAnno.headColor();
}
// 创建表单
HSSFSheet sheet = wb.createSheet(sheetName);
Field[] fields = dataClass.getDeclaredFields();
if (fields.length == 0) {
throw new RuntimeException("目标类中不包含任何字段,请检查");
}
List<Field> fieldList = Arrays.stream(fields)
// 过滤掉static修饰的字段,并且字段上被@ExcelField注解修饰才选为导出字段
.filter(field -> !Modifier.isStatic(field.getModifiers()) && field.isAnnotationPresent(ExcelField.class))
.collect(Collectors.toList());
// 如果没有标注解,则导出全部非静态字段
if (CollectionUtils.isEmpty(fieldList)) {
fieldList = Arrays.stream(fields)
.filter(field -> !Modifier.isStatic(field.getModifiers()))
.collect(Collectors.toList());
}
// 根据@ExcelField注解中的sortWeight值对导出列进行排序,从小到大排序,sortWeight值越小的字段越排在前面
fieldList.sort((fld1, fld2) -> {
ExcelField ano1 = fld1.getAnnotation(ExcelField.class),
ano2 = fld2.getAnnotation(ExcelField.class);
if (ano1.sortWeight() > ano2.sortWeight()) {
return 1;
} else if (ano2.sortWeight() > ano1.sortWeight()) {
return -1;
}
return 0;
});
// 创建表头的样式
HSSFCellStyle headStyle = getHeadStyle(wb, headColor);
// 创建标题行
HSSFRow titleRow = sheet.createRow(0);
// 设置标题高度(当然这里的值也可以在注解里加一个属性,能让用户自定义配置高度)
titleRow.setHeight((short) 300);
for (int i = 0, len = fieldList.size(); i < len; i++) {
Field field = fieldList.get(i);
HSSFCell cell = titleRow.createCell(i, CellType.STRING);
ExcelField anno = field.getAnnotation(ExcelField.class);
cell.setCellStyle(headStyle);
cell.setCellValue(anno == null ? field.getName() : anno.name());
if (anno != null && anno.width() > 0) {
sheet.setColumnWidth(i, anno.width());
} else {
// 列宽自动适配
sheet.autoSizeColumn(i);
}
}
// 写出数据行
for (int i = 0, len = dataList.size(); i < len; i++) {
// 默认标题行是第一行,所以数据起始行为第二行
HSSFRow row = sheet.createRow(i + 1);
Object data = dataList.get(i);
for (int j = 0, l = fieldList.size(); j < l; j++) {
Field field = fieldList.get(j);
field.setAccessible(true);
HSSFCell cell = row.createCell(j, CellType.STRING);
cell.setCellValue(formatValue(field, field.get(data)));
}
}
return wb;
}
/**
* 格式化成字符串(特别处理了date和parseJson中的字段)
* @param field 字段
* @param value 数据实体中的值
* @return 适合写入到表格中的字符串值
*/
public static String formatValue(Field field, Object value) {
Class<?> fieldType = field.getType();
if (value == null) {
return "";
}
String result = String.valueOf(value);
ExcelField anno = field.getAnnotation(ExcelField.class);
String datePattern = "yyyy-MM-dd HH:mm:ss";
if (anno != null) {
datePattern = anno.dateFormat();
// 如果@ExcelField注解中定义了parseJson的json转义字符串,则这里进行转义
if (StringUtils.isNotBlank(anno.parseJson())) {
JSONObject jso = JSON.parseObject(anno.parseJson());
result = jso.getString(String.valueOf(value));
}
}
// 日期单独转换
if (Date.class.equals(fieldType)) {
SimpleDateFormat dateFormat = new SimpleDateFormat(datePattern);
result = dateFormat.format(value);
}
return result;
}
private static HSSFCellStyle getHeadStyle(HSSFWorkbook wb, HSSFColor.HSSFColorPredefined headColor) {
// title样式
HSSFCellStyle headStyle = wb.createCellStyle();
if (headColor != null) {
headStyle.setFillForegroundColor(headColor.getIndex());
headStyle.setFillPattern(FillPatternType.SOLID_FOREGROUND);
headStyle.setFillBackgroundColor(headColor.getIndex());
}
headStyle.setAlignment(HorizontalAlignment.CENTER); // 左右居中
headStyle.setVerticalAlignment(VerticalAlignment.CENTER); // 上下居中
headStyle.setBorderBottom(BorderStyle.THIN); // 下边框
headStyle.setBorderLeft(BorderStyle.THIN);// 左边框
headStyle.setBorderTop(BorderStyle.THIN);// 上边框
headStyle.setBorderRight(BorderStyle.THIN);// 右边框
// 创建样式字体
HSSFFont font = wb.createFont();
font.setFontName("宋体"); // 设置字体名称
font.setBold(true); // 设置字体为粗体
font.setFontHeightInPoints((short) 11); // 设置字体大小
return headStyle;
}
private static void setReponseHeader(String fileName, HttpServletResponse response) throws UnsupportedEncodingException {
response.reset();
response.setHeader("Content-Type", "application/vnd.ms-excel");
response.setHeader("Content-Disposition", "attachment; filename=\"" +
new String(fileName.getBytes("gbk"), StandardCharsets.ISO_8859_1) + "\"");
}
private static String suffixCheck(String fileName) {
if (!(fileName.endsWith(".xls") || fileName.endsWith("xlsx"))) {
fileName += ".xlsx";
}
return fileName;
}
}
下面来导出一个文件试一下(本来想读库的数据来测试的,这里偷个懒,直接用ExcelReader读出来的数据再执行导出吧
先原样导出测试一下(这里选择的是导到桌面的api: writeToDesktop)
LocalTime t1 = LocalTime.now();
String filePath = "D:\\Download\\test.xlsx";
List<ExcelTestBean> all = ExcelReader.getListByFilePath(filePath, ExcelTestBean.class);
System.out.println("表格的详细数据为:" + JSON.toJSONString(all));
System.out.println("all的大小为:" + all.size());
System.out.println("读取整个表格耗时:" + Duration.between(t1, LocalTime.now()).getSeconds() + "s");
ExcelWriter.writeToDesktop("导出测试", all);
在桌面上来看一下导出的文件

再点开看一下数据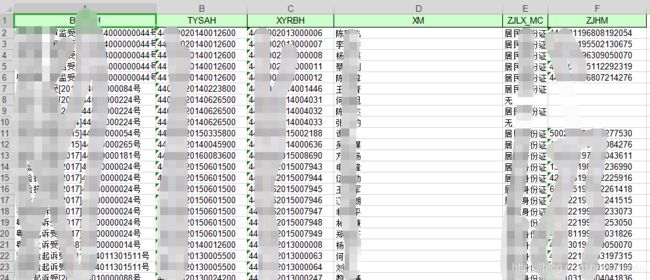
数据都导出来的了,因为上一步读取的时候把空行去除了,所以这里比原表少一行数据,看来也没问题

而且我们在@ExcelField没有指定width(即列宽),代码根据每列数据的长度自动调整了列宽

这里数据都被导出来了,可以看到,我们把最基本的导出功能实现了,组件支持自定义标题行颜色、列宽(举例中没演示,建议大家自己动手测试),数据跨列合并或者跨行合并这里没有去实现,其实这些功能只要有思路都不难。
使用
上面我把这个excel导入导出组件单独抽成了一个本地 java项目进行了大致的演示,使用的是读取的是本地的excel文件,当然实际项目中使用的时候更多的是集成到web项目中,db作为数据源,从db中读取数据供页面下载,或者解析用户在web页面上上传的excel文件(一般是我们指定了模板,用户填数据导入)然后将数据保存到db。
总结
上面这个组件最核心的实现就是用到了反射 和 注解,如果对这两个核心基础功能不熟的同学建议先去了解这两个功能的用法,再来结合本文的代码看是如何实现的,流式处理引擎是为了解决解析大数据量的表格可能会导致的内存溢出问题(这里我没细测最大能支持多大的表格,之前处理10w级的数据没什么问题,如果测试发现问题的同学欢迎到评论区给我留言)
标题说的是从原理入手,如果真有人问我原理是什么,我可能会先问下他对代码的实现思路理解的如何,因为核心实现就是用到了Java基础中学到的功能:反射 和 注解。剩下的就是检验你对这些基础的掌握程度。
当然,代码反映的只是我的实现思路,限于水平,可能会有bug或者不优的地方,希望大家在看、用的时候能去发现问题并尝试解决,对代码有疑问的或者发现bug的同学欢迎在评论区给我留言或者提出宝贵意见,希望大家能共同进步~
(这篇文章拖了很久才写完,之前一直没有写博客的习惯,要写也是做笔记 ,自己能看懂就行,现在发现写博客总结也不是个容易的事,但是写博客一方面会检验自己对知识的梳理程度,另一方面也在考察自己组织语言的能力,希望以后能坚持下去)