天池龙珠金融风控训练营Task02学习笔记
天池龙珠金融风控训练营Task02学习笔记
- 前言
- 学习知识点概要
- 学习内容
-
- 1.数据总体了解
-
- 补充
- 2.缺失值和唯一值
- 3.深入数据-查看数据类型
- 4.数据间相关关系
- 5.用pandas_profiling生成数据报告
- 学习问题与解答
- 学习思考与总结
前言
上节课学习了数据集及金融风控的相关指标,主要是大概了解金融风控的基本知识以及涉及的相关代码。由于太久没有用过CSDN发文,所以比较生疏,内容写得也只能算上勉勉强强,而且自己也没有附上相关的代码,实际上代码的理解也同样的重要。之后我会不断改进,并且会继续在金融风控的学习中提升自己的能力。后面的知识会更具有挑战性,希望这十五天下来自己能够坚持下去,学有所成。下面开始Task02的学习——EDA探索性数据分析。
金融风控学习地址:https://tianchi.aliyun.com/specials/activity/promotion/aicampfr
学习知识点概要
-
1.数据总体了解
- 1.1. 读取数据集并了解数据集大小,原始特征维度
- 1.2. 通过info熟悉数据类型
- 1.3. 粗略查看数据集中各特征基本统计量
-
2.缺失值和唯一值
- 2.1. 查看数据缺失值情况
- 2.2. 查看唯一值特征情况
-
3.深入数据-查看数据类型
-
3.1. 查看唯一值特征情况
-
3.2. 数值型数据
- 3.2.1. 离散数值型数据
- 3.2.2. 连续数值型数据
-
-
4.数据间相关关系
- 4.1. 特征和特征之间关系
- 4.2. 特征和目标变量之间关系
-
5.用pandas_profiling生成数据报告
学习内容
1.数据总体了解
此任务中在python中需要用到的库有
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #用于生成图像
import seaborn as sns
import datetime
import warnings
warnings.filterwarnings('ignore')
- 读取文件采用 :对象 = pd.read_csv(’[file_name].csv’)的方法
data_train = pd.read_csv('train.csv')
data_test_a = pd.read_csv('testA.csv')
#如果没有下载该数据集,可以直接读取链接(Task01有讲)
- 总体了解数据集的大小和其表头信息
data_train.shape#输出data_train长和宽
data_test_a.shape#输出data_test_a长和宽
data_train.columns#输出data_train列名
- 使用info()方法来了解整个表格的信息和数据类型
data_train.info()
- 使用describe()方法来了解整个表格的基本统计量(数量count、平均值mean、标准差std以及设置数值的统计量等)
data_train.describe()
补充
- 如果pandas读取数据时相对路径载入报错时,可以尝试使用os.getcwd()查看当前工作目录。
import os#os是操作系统的库
os.getcwd()#输出为python工作目录,可以把所要加载的数据集放在相应路径上
-
TSV与CSV的区别:
1.从名称上即可知道,TSV(Tap-Separated Values)是用制表符(Tab,’\t’)作为字段值的分隔符;CSV(Comma-Separated Values)是用半角逗号(’,’)作为字段值的分隔符;
2.从pandas类对象层次解释:Python对TSV文件的支持: Python的csv模块准确的讲应该叫做dsv模块,因为它实际上是支持范式的分隔符分隔值文件(DSV,delimiter-separated values)的。 delimiter参数值默认为半角逗号,即默认将被处理文件视为CSV。当delimiter=’\t’时,被处理文件就是TSV。 -
读取文件的部分(适用于文件特别大的场景)
用nrows参数,即仅读取几行,可以加快数据的读取:
pd.read_csv('[file_name].csv', nrows = 5)
nrows = 5就是仅读取前5行
也可以使用chunksize参数,chunksize就是每一次读取几行数据的意思,也就是所说的分块处理。
代码如下:
#设置chunksize参数,来控制每次迭代数据的大小
i = 0 # 控制输出
chunker = pd.read_csv("http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csv",chunksize=5)
for item in chunker:
print(type(item))#说明chunker中每一个块类型是一个DataFrame
#2.缺失值和唯一值
- 通过isnull().any().sum()方法来查看有(any)缺失值(isnull)的栏目的总数(sum)
print(f'There are {data_train.isnull().any().sum()} columns in train dataset with missing values.')
#f是格式化字符串,把{}格式化,在表达式会被里面的表达式所替代
#输出为There are 22 columns in train dataset with missing values.
- 查看缺失特征中缺失率大于50%的特征
have_null_fea_dict = (data_train.isnull().sum()/len(data_train)).to_dict()
#我的理解是有空值的总数除以所有数据集的总数,但得到的不是一个数吗。。。而最后是把DataFrame转换为字典。这里的代码我不太理解,希望有好心人帮忙解决QAQ。
fea_null_moreThanHalf = {
} #超半数的字典
for key,value in have_null_fea_dict.items():
if value > 0.5:
fea_null_moreThanHalf[key] = value #
fea_null_moreThanHalf
- nan(空值个数)可视化
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
得到的柱状图可以把缺失的特征及缺失率可视化。
纵向比较:如果nan存在过多,则可以考虑把这一列给删掉;如果缺失值很少则可以自行填充
横向比较:如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
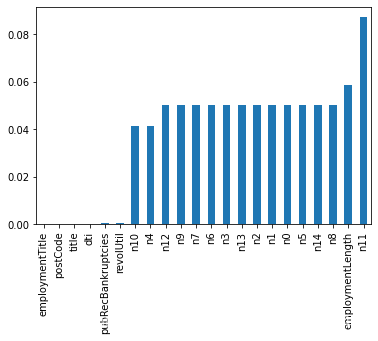
- 查看训练集测试集中特征属性只有一值的特征:nunique()方法,找出唯一值的个数。[补充:unique()方法是返回列的所有唯一值(特征的所有唯一值)]
one_value_fea = [col for col in data_train.columns if data_train[col].nunique() <= 1]
3.深入数据-查看数据类型
- 特征
1.特征由类别型特征和数值型特征组成,而数值型特征又分为连续型和离散型。
2.类别型特征有时具有非数值关系,有时也具有数值关系。比如‘grade’中的等级A,B,C等。
3.特征分箱:将数值型特征转化为WOE编码进而做标准评分卡等操作,以降低变量复杂性,减少变量噪音的影响,减少变量噪音对模型的影响,提高自变量和因变量的相关度,从而使模型更加稳定。
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns)
#把object类型排除了就说明是数字了
#数值型特征,这一行的内容是纯数字
category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
#类别性特征,可以概况为除数字外其他的内容
- 为区分数值型特征中不连续的列数和连续的列数(serial的意义是连续),可以把他们放在两个不同的列表numerical_serial_fea和numerical_noserial_fea,最后由get_numerical_serial_fea(data,feas)方法来返回其值
#过滤数值型类别特征
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)
连续型的变量可以作图来可视化,因此我们把连续性变量合并生成图像(代码不太理解)
#每个数字特征得分布可视化
# 这里画图估计需要10-15分钟
f = pd.melt(data_train, value_vars=numerical_serial_fea)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
图像为

-
观察图形是否符合正态分布,如果不符可以尝试使用log化,观察数值型变量分布是否符合正态分布,因为一些模型会要求数据正态,过于偏态可能会影响模型预测结果。
以下给出栏目loanAmnt正态化前和正态化后的代码,主要是理解好作图代码的含义。
#Ploting Transaction Amount Values Distribution
plt.figure(figsize=(16,12))
plt.suptitle('Transaction Values Distribution', fontsize=22)
plt.subplot(221)
sub_plot_1 = sns.distplot(data_train['loanAmnt'])
sub_plot_1.set_title("loanAmnt Distribuition", fontsize=18)
sub_plot_1.set_xlabel("")
sub_plot_1.set_ylabel("Probability", fontsize=15)
plt.subplot(222)
sub_plot_2 = sns.distplot(np.log(data_train['loanAmnt']))
sub_plot_2.set_title("loanAmnt (Log) Distribuition", fontsize=18)
sub_plot_2.set_xlabel("")
sub_plot_2.set_ylabel("Probability", fontsize=15)

4.数据间相关关系
- 单一变量可视化:
plt.figure(figsize=(8, 8))
sns.barplot(data_train["employmentLength"].value_counts(dropna=False)[:20],
data_train["employmentLength"].value_counts(dropna=False).keys()[:20])
plt.show()

- y值不同可视化x某个特征的分布
1.类别型变量(统计各个类别的数量)
以下以isDefault栏目为例
train_loan_fr = data_train.loc[data_train['isDefault'] == 1]
train_loan_nofr = data_train.loc[data_train['isDefault'] == 0]
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 8))
train_loan_fr.groupby('grade')['grade'].count().plot(kind='barh', ax=ax1, title='Count of grade fraud')
train_loan_nofr.groupby('grade')['grade'].count().plot(kind='barh', ax=ax2, title='Count of grade non-fraud')
train_loan_fr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax3, title='Count of employmentLength fraud')
train_loan_nofr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax4, title='Count of employmentLength non-fraud')
plt.show()

2.连续型变量(用连续的x和y坐标衡量)
以下以loanAmnt为例
fig, ((ax1, ax2)) = plt.subplots(1, 2, figsize=(15, 6))
data_train.loc[data_train['isDefault'] == 1] \
['loanAmnt'].apply(np.log) \
.plot(kind='hist',
bins=100,
title='Log Loan Amt - Fraud',
color='r',
xlim=(-3, 10),
ax= ax1)
data_train.loc[data_train['isDefault'] == 0] \
['loanAmnt'].apply(np.log) \
.plot(kind='hist',
bins=100,
title='Log Loan Amt - Not Fraud',
color='b',
xlim=(-3, 10),
ax=ax2)

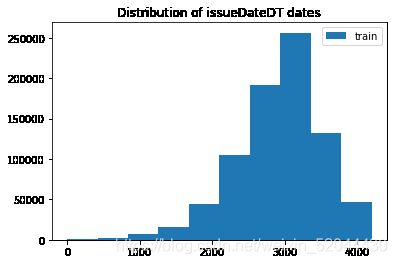
- 转化成时间格式
#转化成时间格式 issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数
data_train['issueDate'] = pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
data_train['issueDateDT'] = data_train['issueDate'].apply(lambda x: x-startdate).dt.days
plt.hist(data_train['issueDateDT'], label='train');
plt.legend();
plt.title('Distribution of issueDateDT dates');
#train 和 test issueDateDT 日期有重叠 所以使用基于时间的分割进行验证是不明智的
- 柱状图
total = len(data_train)
total_amt = data_train.groupby(['isDefault'])['loanAmnt'].sum().sum()
plt.figure(figsize=(12,5))
plt.subplot(121)##1代表行,2代表列,所以一共有2个图,1代表此时绘制第一个图。
plot_tr = sns.countplot(x='isDefault',data=data_train)#data_train‘isDefault’这个特征每种类别的数量**
plot_tr.set_title("Fraud Loan Distribution \n 0: good user | 1: bad user", fontsize=14)
plot_tr.set_xlabel("Is fraud by count", fontsize=16)
plot_tr.set_ylabel('Count', fontsize=16)
for p in plot_tr.patches:
height = p.get_height()
plot_tr.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/total*100),
ha="center", fontsize=15)
percent_amt = (data_train.groupby(['isDefault'])['loanAmnt'].sum())
percent_amt = percent_amt.reset_index()
plt.subplot(122)
plot_tr_2 = sns.barplot(x='isDefault', y='loanAmnt', dodge=True, data=percent_amt)
plot_tr_2.set_title("Total Amount in loanAmnt \n 0: good user | 1: bad user", fontsize=14)
plot_tr_2.set_xlabel("Is fraud by percent", fontsize=16)
plot_tr_2.set_ylabel('Total Loan Amount Scalar', fontsize=16)
for p in plot_tr_2.patches:
height = p.get_height()
plot_tr_2.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/total_amt * 100),
ha="center", fontsize=15)

- 透视图
#透视图 索引可以有多个,“columns(列)”是可选的,聚合函数aggfunc最后是被应用到了变量“values”中你所列举的项目上。
pivot = pd.pivot_table(data_train, index=['grade'], columns=['issueDateDT'], values=['loanAmnt'], aggfunc=np.sum)
5.用pandas_profiling生成数据报告
import pandas_profiling
pfr = pandas_profiling.ProfileReport(data_train)
pfr.to_file("./example.html")
学习问题与解答
1.data_train.isnull().sum()/len(data_train)这行代码是什么意思呢?我没有搞懂他最后得到的结果究竟是什么;
2.pandas_profiling无法安装库,不知道怎么解决QAQ
学习思考与总结
Task02主要讲解了数据分析及可视化的一些方法,也是基本操作。掌握下来没有太大的问题,可能是可视化图像方面我比较生疏,后面的代码也是囫囵吞枣,一知半解。代码应该要勤加练习,才能够熟练掌握,只是表面理解没有实操其实是优点徒劳的。这一点我做的一般。本章只是基本对数据集的数据进行分析,是为后面的机器学习做关键的铺垫,因此,后面的学习非常需要前面的熟练掌握。为此,接下来应该自行继续巩固基本的数据分析方法以及相关的代码,后续的机器学习才能够更轻松学下去。希望这十五天自己能学有所获,再接再厉。