python自动化(一)基础能力:1.python文件读取
1. 因为最近公司在搞自动化测试,自己学到了许多自动化测试的知识。所以决定专门写一个自动化系列的博客,方便以后查看,有需要的朋友也可以看看。。
2. 自动化测试中,我们的配置数据,测试数据等等都是使用文件的方式存放的,所以读取文件在自动化中非常的重要,第一章我们就先讲讲python读取文件常用的几种方法。
一.YAML文件读写
1.什么是yaml文件
YAML 语言(发音 /ˈjæməl/ )的设计目标,就是方便人类读写。它实质上是一种通用的数据串行化格式。它的基本语法规则如下。
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
yaml中表示字典
name: 'zhangsan'
age: 18
# 上面的内容等价于python中的:{'name': 'zhangsan', 'age': 18}
# 注意:冒号后面必须有空格
# yaml文件中使用“#”表示注释
再来一个字典中嵌套字典的例子
name: zhangsan
age: 18
address:
aa: 666
bb: 'ksd'
# 上面的内容等价于python中的:{'name': 'zhangsan', 'age': 18, 'address': {'aa': 666, 'bb': 'ksd'}}
yaml中表示列表
-
- 1
- 2
- 3
- [4,5,6]
# 上面的内容等价于python中的:[[1, 2, 3], [4, 5, 6]]
# 可以使用缩进表示列表中的元素,例如上面的1,2,3 也可以使用[]来表示,例如上面的4,5,6
列表字典混合使用
- username: zhangsan
age: 18
sss: [4,5,6]
- username: lisi
age: 22
ssss: [1,2,3]
# 上面的内容等价于python中的:[{'username': 'zhangsan', 'age': 18, 'sss': [4, 5, 6]}, {'username': 'lisi', 'age': 22, 'ssss': [1, 2, 3]}]
2.python读写YAML文件
我们知道了yaml文件的编排方式,就可以使用python来读写yaml文件了。
python中读写yaml,需要安装PyYaml库。
pip install PyYaml
python写内容到yaml文件中
# 导入第三方库
import yaml
# 准备数据
data = {
'name':'zhangsan',
'age':18,
'family':['asfdsg','afsdsag']
}
# 将data内容写入到test.yaml文件中
with open(file='./test.yaml',mode='w',encoding='utf-8') as f:
yaml.safe_dump(data,stream=f)
运行程序后,yaml文件的内容如下:
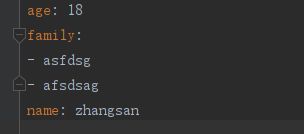
python读取yaml文件的内容
import yaml
# 注意:写入文件时要使用写(w)模式打开文件,读取文件时要使用读(r)模式打开文件
with open(file='./test.yaml',mode='r',encoding='utf-8') as f:
data = yaml.safe_load(f)
print(data)
运行程序后,效果如下:

yaml文件拓展
我们在使用yaml文件存放测试数据时,经常会有这种情况,就是多个用例的数据很大部分是重合的,那么我们有没有什么办法将重合的部分,设置为局部变量,供很多用例去调用呢?这就是我们要讲的yaml文件中的描点功能。
- 原始yaml文件数据:
- username: 'zhangsan'
homeland: 'china'
age: '18'
- username: 'zhangsan'
homeland: 'china'
age: '18'
- username: 'zhangsan'
homeland: 'china'
age: '18'
# 原始数据,三条用例中的homeland都是一样的
- 使用描点方法:
# 构建描点,通常用来存放一些通用的数据
comment: &comment
homeland: 'china'
user1:
username: 'zhangsan'
<<: *comment
age: '18'
user2:
username: 'zhangsan'
<<: *comment
age: '18'
user3:
username: 'zhangsan'
<<: *comment
age: '18'
# 使用<<: *comment,来引用comment的内容。
# 我们在使用yaml构造接口自动化用例数据时,描点可以大大减小我们的数据量。而且更改起来也十分方便,只需要更改描点中的数据。
二.json文件的读写
json数据我们应该都很熟悉了,它的格式和python中的字典很像。这里就不特意介绍了。直接开始干货
python写入内容到json文件
# 导入第三方库
import json
data = {
'username': 'zhangsan',
'age': 18
}
with open(file='./test.json',mode='w',encoding='utf-8') as f:
json.dump(data,f)
运行程序后,查看test.json文件内容如下:
![]()
python读取json文件中的内容
# 导入第三方库
import json
with open(file='./test.json',mode='r',encoding='utf-8') as f:
data = json.load(f)
print(data)
运行程序后,效果如下:
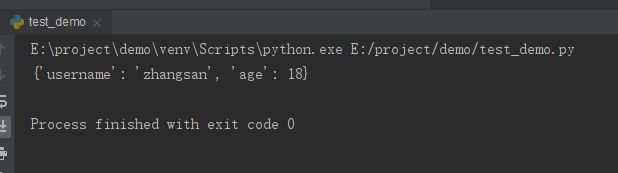
三.python读写excel文件
(1)安装
pip install openpyxl
(2)使用
创建对象(工作簿)
场景1:创建一个新的Excel文档
from openpyxl import Workbook
# 实例化一个workbook对象,用于创建,打开excel
wb = Workbook()
wb.save('test1.xlsx')
场景2:打开一个已有的excel文档
from openpyxl import Workbook,load_workbook
# 实例化一个workbook对象,用于创建,打开excel
wb =load_workbook('test1.xlsx')
Workbook对象属性(工作簿操作)
写excel内容:
1.打开一个新的工作簿-------Workbook()
2.创建一个execl表单页----Workbook().create_sheet(sheet名字,位置)-------不指定位置的话,默认在最后一页
3.添加或者修改sheet页的内容:
- 方法1:sheet页[编号 例如:‘A3’] = 内容
from openpyxl import Workbook,load_workbook
wb =Workbook() # 实例化一个workbook对象,用于创建,打开excel
wb1 = wb.create_sheet('ouyi') # 创建一个sheet页
wb1['A1'] = 'OUYI' #添加内容到excel
wb1['B2'] = 'haha' #添加内容到excel
wb.save('test2.xlsx') #保存工作薄
- 方法2:sheet页.cell(row=6,column=3,value=88888888):添加修改-----row表示行;column列表示
from openpyxl import Workbook,load_workbook
wb =Workbook() # 实例化一个workbook对象,用于创建,打开excel
wb1 = wb.create_sheet('ouyi2') # 创建一个sheet页
for lie in range(1,11): # 写入excel内容
for hang in range(1,11):
wb1.cell(row=hang,column=lie,value='ouyi')
wb.save('test2.xlsx') #保存工作薄
- 方法3:sheet页.append([‘X’,‘Y’,‘Z’,…])-----------在末尾一行添加内容
from openpyxl import Workbook,load_workbook
wb =Workbook() # 实例化一个workbook对象,用于创建,打开excel
wb1 = wb.create_sheet('ouyi2') # 创建一个sheet页
wb1.append(['ouyi','ojbk','afa'])
wb.save('test2.xlsx') #保存工作薄
读取excel内容
1.wb.sheetnames 输出表单页名称,返回列表
from openpyxl import Workbook,load_workbook
wb =load_workbook('test2.xlsx') # 实例化一个workbook对象,用于创建,打开excel
print(wb.sheetnames)
结果:
['Sheet', 'ouyi2']
2.wb【sheet页名称】【单元格】.value---------获取对应单元格的内容
from openpyxl import Workbook,load_workbook
wb =load_workbook('test2.xlsx') # 实例化一个workbook对象,用于创建,打开excel
result = wb['ouyi2']['A1'].value
print(result)、
结果:
ouyi
四.python读取xml文件内容
xml也是我们经常遇到的的一种标记语言,例如前端的HTML就是一种xml格式的标记语言。
python读取xml文件
xml文件格式如下:
<Layout>
<node1>
<subnode1>hahasubnode1>>
node1>
<node2>hehenode2>
<node3>
<Item ID="1">1Item>
<Item ID="2" type="sss">2Item>
<Item ID="3">3Item>
node3>
Layout>
# 导入第三方库
from xml.etree import ElementTree as ET
# 实例化一个ElementTree对象,并打开一个xml文件
wob = ET.ElementTree()
tree = wob.parse('./test.xml')
# find: 查找单个节点,如果对应的xpath路径匹配到多个节点,也只会返回第一个节点对象
e1 = tree.find('./node1/subnode1')
# 结果如下:, , ]
# xpath中添加属性查找节点
e3 = tree.findall('./node3/Item[@ID="1"]')
# 结果如下:[]
# 获取对应节点的属性值
e4 = tree.find('./node3/Item[@ID="2"]')
print(e4.attrib)
# 结果如下:{'ID': '2', 'type': 'sss'}。返回包含所有“属性名:属性值”的字典
# 获取对应节点的text
e5 = tree.find('./node2')
print(e5.text)
# 结果如下:hehe。
# 获取对应节点的标签名
e6 = tree.find('./node3/Item[@ID="2"]')
print(e6.tag)
# 结果如下:Item。
五.python读取ini文件
ini文件常常被我们用来作为项目中配置文件,而且自动化测试中页面元素也常常存放到ini文件中。所有读取ini文件也是很重要的。
ini文件格式如下:
[username]
user1 = zhangsan
user2 = lisi
[age]
user1 = 27
user2 = 26
;这里是注释
;ini文件的结构,一个ini文件通常由节、健、值组成。
;节:由方括号括起,
;健-值对:在每个节下可以有多个健-值组成的对。语法是健=值。
python读取ini文件
# 导入第三方库
from configparser import ConfigParser
# 实例化一个ConfigParser对象
wob = ConfigParser()
# 读取ini文件
wob.read('test.ini',encoding='utf-8')
# 获取文件的所有节点
print(wob.sections())
# 结果为:['username', 'age']
# 所有节点+key获取value
print(wob.get('username','user1'))
# 结果为:zhangsan
总结:到这里我们将几种常用的文件读取的方法都讲解了。例如:yaml,json,excel,xml,ini文件等。自动化测试中一般使用这些文件都够用了。如果有更高需求的同学,就需要自行百度了
