深度解读 Chaos Mesh®,探索云原生混沌工程的奥秘
本篇文章整理自我司研发工程师杨可奥以及 PingCAP 工程效率负责人、Chaos Mesh 负责人周强在 GoCN 开源说上的演讲实录。
本文首先介绍了对混沌工程这一概念的描述,分享了混沌工程的动机和实践方式以及 Chaos Mesh 项目的发展情况。在后半部分,介绍了 Chaos Mesh 项目本身的架构,并涉及到在 Go 的生态环境中对容器等基本概念进行操作。干货十足,enjoy~本文首先介绍了对混沌工程这一概念的描述,分享了混沌工程的动机和实践方式以及 Chaos Mesh 项目的发展情况。在后半部分,介绍了 Chaos Mesh 项目本身的架构,并涉及到在 Go 的生态环境中对容器等基本概念进行操作。干货十足,enjoy~
混沌工程概述
现在的技术潮流在向着大规模集群、超复杂的分布式系统与微服务架构演进。在演进的过程 当中,虽然给我们带来了不少的便利,同时也带来了许多的麻烦。其中之一便是 —— 当一个节点发生错误的时候,我们无法预料它将产生怎样的蝴蝶效应。它将只牵涉到部分服务还是会让所有服务崩溃?它能够自愈吗?更可怕的是,随着计算规模的扩大,故障发生的可能性也越来越大。对于一个个人电脑用户来说,可能用到更换电脑硬盘也不曾发生过损坏;而对于服务器集群来说,每天都可能会有数块磁盘损坏需要更换。
无论是云计算的领头羊 AWS,或是面向工程师们的 GitHub,还是互联网巨头 Google,都无法逃离故障的命运。
混沌工程是一门新兴的技术学科,他的初衷是通过实验性的方法,让人们建立对于复杂分布式系统在生产中抵御突发事件能力的信心。
而混沌工程便是在这样糟糕的环境下,让开发者、运维对复杂系统仍然保持信心的方法。
混沌工程历史
混沌工程已经走过了十一个年头了。从最初Netflix提出这个概念,到 16 年 Gremlin 给出了 混动工程的商业产品,试图形成混沌工程服务的商业模式。Chaos Mesh 是在 2019 年末开源的,现在也成为了最受关注的混沌工程项目之一。
混沌工程步骤
如果想要为你管理的项目引入混沌工程,那么可以依照以下五步的循环:

不断进行这五步的循环,将对工程的稳定性产生明显的提升。以混沌工程在 TiDB 上的实验为例:
1. 我们立下期望,TiDB 在删除一个节点之后应该能够在短时间内恢复。
2. 进行了删除节点的混沌实验。
3. 发现前两次 TiDB 都在短时间内恢复了,而第三次却花了很长的时间才恢复。
4. 调查这之中是否存在一些 Bug,修复之后再次进行实验,看看还有没有这个问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WiegT62A-1618799949529)(https://oscimg.oschina.net/oscnet/up-3dff2c969e36f3ad1ff18c70a3bdf5f562f.png)]
反复多次地进行这样的步骤,都 TiDB 的稳定性就产生了一些帮助。
Chaos Mesh 的社区

在短短的一年间, Chaos Mesh 的社区也已经不断壮大了,现在拥有了超过 3400 个星星,近 90 个贡献者,也是 CNCF Sandbox 项目。现在 Chaos Mesh 也已经拥有了涉及 Pod 的生命 周期、IO 、网络、资源压力、公有云等诸多方面的数十种不同类型的错误注入方式;还拥有一个功能丰富的仪表盘。这一切成就离不开来自社区的帮助。无论是对 Bug 的报告、对工程、设计的意见,还是直接提交代码,都是对 Chaos Mesh 项目的巨大贡献。
Chaos Mesh 整体架构
Chaos Mesh 的整体架构如图中所展示,可以自上而下分为三个部分:
1. 用户输入、观测的部分。
2. 监听资源变化,进行注入/恢复的 Controller 组件。
3. 在具体节点上进行故障注入的 Chaos Daemon。
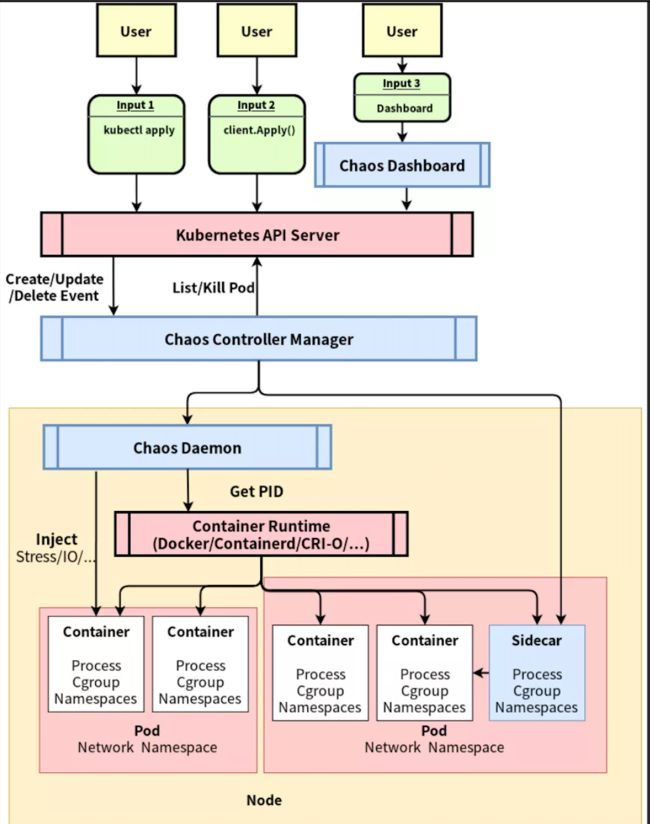
这部分文章将依照这三个部分展开,自上而下梳理 Chaos Mesh 的架构。
用户输入、观测的部分
用户输入的部分总是以用户的操作为起点,以 Kubernetes API Server 为重点,不直接和 Chaos Mesh 的 Controller 交互。一切的用户操作最终都将反映为某个 Chaos 资源的变更(比如 NetworkChaos 资源的变更)。这保障了 Chaos Mesh Controller 的事件来源的单纯性。Chaos Mesh 提供了三种输入的方式:
1. 通过 kubectl 等命令行工具,将一个 YAML 文件提交至 Kubernetes 服务器这样做能够清晰地知道提交的内容,通过 kubectl 这一 Kubernetes 用户都能熟练使用的工具,将 Chaos Mesh 的资源操作方式和 Pod、Deployment 等其他原生资源的提交方式统一起来,方便用户上手、尝试。而除了使用 kubectl apply 命令来提交一个混沌实验之外,还可以通过 kubectl describe 命令来查询实验的状态和错误信息,使用 kubectl patch 来修改实验将实验暂停、恢复。(如图,一个典型的描述网络分区的 NetworkChaos 资源文件)。

2. 通过 kubernetes/client-go 等包来对 Chaos 资源进行增删查改。这样做的好处是能够方便地集成进已有的测试流程。如果用户已经搭建好一个可编程的测试平台,那么就可以通过这种方式在任何自己期望的时机插入、恢复 混沌实验,如果说将 Chaos Mesh 提供的丰富的错误注入能力作为测试的武器库,那么可编程的方式就是使用这些武器的最灵活的方式。
3. 通过 Chaos Dashboard 提供的 Web UI 界面对混沌试验进行操作和观测。Chaos Dashboard 提供了一套友好的用户界面,同时也提供了依照 RBAC 的权限管控机制,用户需要输入自己的 Token 才能够进行操作。在这部分 UI 中用户能够管理和观察已有的错误,同时也能将错误注入归档并在将来复用。

**监听资源变化的 Controller **
Chaos Mesh 的 Controller 总是只接受来自 Kubernetes API Server 的事件 —— 这种事件会描述“什么资源发生了什么变化”,比如一个名为 network-test 的 NetworkChaos 资源被创建了。在工程实践中,对资源的具体变化进行响应太过复杂了;而往往选择使用“同步” 的方式 —— 将资源中描述的情形向真实状态中同步,比如当 Pod 建立时会将这种描述给具象化为一个(或多个)容器;反过来的 “同步” 也是存在的,当容器意外死亡、 启动失败的时候错误状态也会同步至 Pod 中。所以无论是怎样的变化(无论是增删查改 中的哪一个),Controller 要做的都只是决定以下两件事情:
1. 现在应该注入还是应该恢复还是要等待?
2. 如果需要注入/恢复,应该怎么做?
对于第一个问题,Controller 将必要的信息存储在资源中,比如下一次要注入的时间、 下一次要恢复的时间。这样在响应变化的时候,就能通过当前时间来推断应该注入还是恢复还是等待。
而对于第二个问题,Controller 需要根据测试类型的不同进行不同的判断,比如删除 Pod 就能通过向 Kubernetes API Server 发送请求直接完成,对于公有云的混沌测试 ——比如起停虚拟机、移除磁盘则会通过每个公有云不同的 API 来完成,而其他稍稍复杂的错误注入(比如后文会提到的时间偏移和网络延迟 )就需要 Chaos Daemon 的帮助在每个节点上进行一些操作来注入。
Chaos Daemon 注入实现
要知道如何在云环境下注入,第一个问题就是弄清楚我们在注入什么 —— Pod 的实体是 Container 的话那么 Container 的实体是什么呢?在常规的语境下,Container 的一个实体指的是一个进程与它所属的 Namespace 和 Cgroup。其中 Namespace 与 Cgroup 起到了一个与其他进程隔离的作用。Namespace 控制着可见性,掌管着这个进程能够看到哪些东西(看到哪些文件、看到哪些进程);而 Cgroup 控制着资源分配:在一个 cgroup 内允许占用多少 CPU 时间、占用多少内存、产生多少 Pid。而如果要进行错误注入 —— 比如让一个容器内的 CPU 资源被吃满、让一个 Pod 与其他的 Pod 的网络连接断开,需要做的第一件事情就是侵入到对应的 Namespace 及 Cgroup 中去。
侵入 Namespace
侵入 Cgroup 的实现是颇为简单的,在进程启动之后将它加入到对应 Cgroup 的进程 名单中即可。而 Namespace 的注入在 Go 的独特线程环境下要困难一些。Chaos Mesh 借鉴了 runc 的方案,自己实现了一个chaos-mesh/nsexec 来侵入 Namespace 。实现的原理是在进程启动的时候通过设置 LD_PRELOAD 环境变量来加载一个名为nsexec.so 的动态链接库,这个动态链接库的contructor 中调用 setns 系统调用来将自身 设置到目标名字空间中去。执行流程如图所示:

这一工具相比 nsenter 这个现成工具的好处主要有两点:
1. 拥有更适合 Chaos Mesh 的信号处理机制,能够方便地控制子进程的死亡。
2. 能够和 mnt namespace 配合工作,只要是当前 mnt namespace 存在的二进制文件,都能够在目标名字空间中运行,而不需要目标名字空间中存在。在常见的distroless 的镜像中,可能不存在任何常见的二进制文件,而 nsexec 能够应对这种情况。
具体注入实现的方法
现在 Chaos Mesh 已经拥有了非常丰富的功能,受限于篇幅不可能单独介绍每一种注入的实现,更重要的可能是注入实现背后的方法和路径。在设计一个错误注入的实现时 ,依照以下的流程进行考虑被证实是非常有用的:
1. 考虑正常情况下程序工作的方式。
2. 在正常的调用途径中有哪些可注入的地方。
3. 对这些可注入的地方进行注入。
以下我们以时间偏移为例,照着这种思考范式来设计它的实现:
1. 考虑正常情况下程序工作的方式。正常情况下,一个程序是如何获得时间的呢?大部分程序会选择使用编程语言标准库中携带的函数,比如 Rust 程序会使用Instant::now(), Go 程序会使用time.Now() ,C 生态的程序会使用glibc 中的 clock_gettime 函数。而这些函数都会以 vDSO 的方式调用操作系统提供的 clock_gettime。vDSO 也是由操作系统提供的函数功能。但与系统调用不同,vDSO 由操作系统在进程启动的时候自动地加载入进程的内存空间,格式与动态链接库的 ELF 格式相同。应用程序只需要解析这段 ELF 的一些段,就能找到clock_gettime 函数 并调用它。
2. 在正常的调用途径中有哪些可注入的地方?因为 vDSO 是存在于目标进程的内存空间中的,如果我们能够修改这部分内存空间就好了。而事实上ptrace 系统调用给了我们修改另一进程的内存的能力。
3. 对这些可注入的地方进行注入,于是时间偏移的实现方式呼之欲出——只需要准备好一个有偏移的clock_gettime 的实现,用它覆盖住原有的clock_gettime 函数的实现就好了。
使用类似的方法,也同样能够破解其他类型注入的难题——比如对于文件系统的注入方式,我们可以通过 FUSE 提供一个存在延迟的文件系统,而这一文件系统以真实的磁 盘上的文件系统为存储后端即可(这样用户在恢复之后仍然能操作这些文件)。
以上为这篇文章介绍的全部内容了。如果读者对 Chaos Mesh 项目感兴趣,想要成为用户或贡献者,欢迎加入我们的 Slack Channel (CNCF Slack 的 #project-chaos-mesh 频道) 来一同讨论如何应用混沌工程、如何让 Chaos Mesh 变得更好。
构造一个稳定安全的软件服务使用环境,离不开社区的帮助。无论是使用 Chaos Mesh 还是为 Chaos Mesh 提交代码,相信都是 在迈向这一美好的目标。