B站视频课《PyTorch深度学习实践》笔记-第3讲-梯度下降算法
Gradient Descent是我们训练模型时常用的一种算法。
回顾上一讲:
我们要构建一个学习系统,第一步是选择一个best model,其中最简单的模型是linear model 。所以在上一讲针对所用的那个数据集,然后使用了一个最简化的线性模型。
穷举法这种方式,在权重数量多的时候,不好用。
分治法,目标函数曲线是凸函数时可用。否则,找到的是局部最优点,很可能错过目标点。并且,当权重数量级很大时,也不能用。
综上,用另外一种更好用的寻找最优值的算法。
Gradient Descent Algorithm
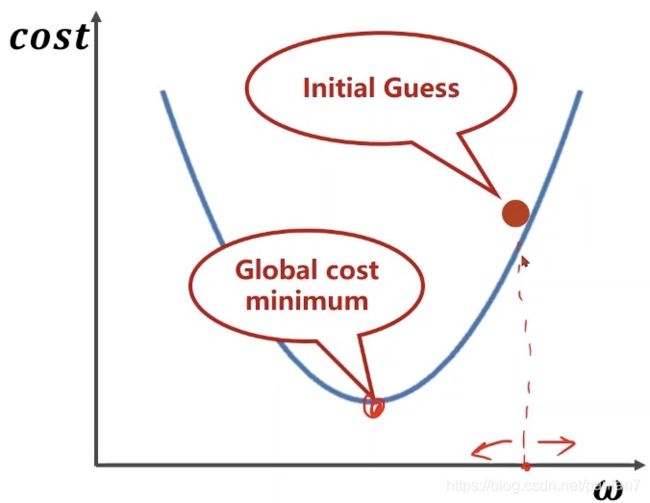
假设有一个如上图的cost function,初始点如上图红点位置,要到达的是波谷那一点(目标点)。如果想要去确定最佳的权重实际上就是确定到底往数轴哪个方向运动。这里面可以通过梯度的定义来确定这个问题。
 梯度定义这里就是用目标函数对权重求导,这样就求到了上升方向。如果想下降,就求倒数的负方向。
梯度定义这里就是用目标函数对权重求导,这样就求到了上升方向。如果想下降,就求倒数的负方向。
 是学习率,表示往前走多远,一般取值会比较小,如果取得特别大可能无法收敛。这就是梯度算法的核心公式。
是学习率,表示往前走多远,一般取值会比较小,如果取得特别大可能无法收敛。这就是梯度算法的核心公式。
从算法的思想上可以看到,每次迭代都朝着下降最快的方向去往前走一步,实际上这是算法设计中的“贪心”思想,只看眼前最好的选择。
贪心算法不一定能得到最优的结果,用梯度下降也是一样,但是能得到局部区域的最优结果。
所以说,如果我们的损失函数如下图,我们没办法达到最优点。所以在优化问题中把这种函数叫做非凸函数。

所以说,用梯度下降算法很难去找到一个全局最优。但是,在深度学习中,为什么会大量使用梯度下降作为最基本的算法呢?
因为,在深度学习中,它的目标函数,以前大家认为里面有很多的局部最优点,我们训练的时候会陷入到局部最优,没法找到全局最优。
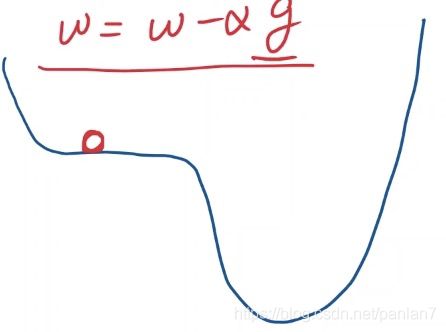
但实际上,后来大家发现,在深度神经网络里面,它的损失函数当中,并没有非常多的局部最优点,但是它存在一种特殊的点——鞍点。
鞍点这个位置梯度为零。到达这一点后,就不会再移动了,陷入到鞍点之中。
 (一维情形)
(一维情形) 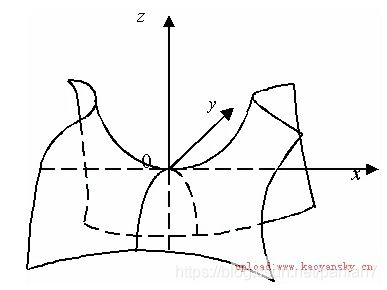 (二维情形的“马鞍面”,即双曲抛物面)
(二维情形的“马鞍面”,即双曲抛物面)
所以,在深度学习中要解决的最大的问题,并不是局部最优,这个比较容易克服,最大的问题是鞍点问题,一旦陷入鞍点,便无法进行迭代。

import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_prey = forward(x)
cost += (y_prey - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
cost_list = []
epoch_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
epoch_list.append(epoch)
cost_list.append(cost_val)
print('Epoch:', epoch, 'w= %.2f' % w, 'cost= %.2f' % cost_val)
print('Predict (after training)', 4, '{:.2f}'.format(forward(4)))
plt.plot(epoch_list, cost_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.grid()
plt.show()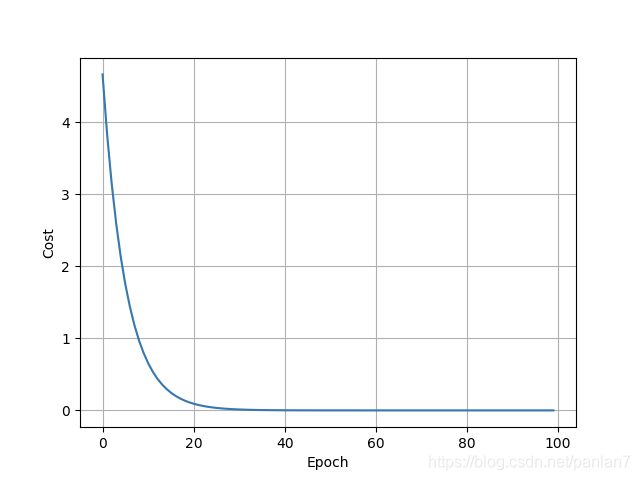
梯度下降实际上我们在深度学习的训练中用的还是挺少的,我们用的是梯度下降的一个延伸版本,叫随机梯度下降。
Stochastic Grandient Descent

为什么用随机梯度下降呢?
目标函数可能是带有鞍点的,如下图:
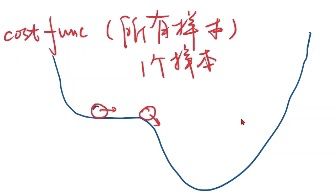
如果整个的cost function如此,它是没办法再往前走的,因为cost function是所有的样本算出来的。现在如果你每次只用其中的一次样本,因为每次拿到的数据肯定是由噪声的,就会引入随机噪声,我们即使陷入到鞍点,那么随机噪声可能会把我们向前推动。引入了这种随机性后,将来在更新的过程中就有可能跨越过这个鞍点,然后向最优值前进。随机梯度下降在深度神经网络中被证明是非常有效的方法。
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_prey = forward(x)
return (y_prey - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
print('Predict (before training)', 4, forward(4))
loss_list = []
epoch_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad
print('\tgrad: ', x, y, grad)
l = loss(x, y)
print('progress:', epoch, 'w= %.2f'% w, 'loss= %.2f'% l)
epoch_list.append(epoch)
loss_list.append(l)
print('Predict (after training)', 4, '{:.2f}'.format(forward(4)))
plt.plot(epoch_list, loss_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid()
plt.show()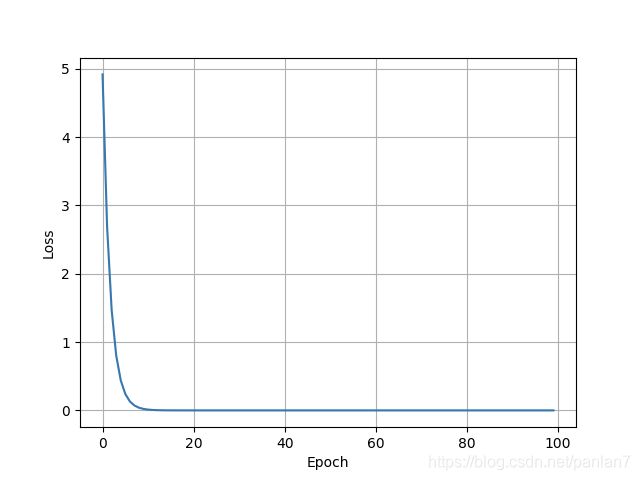
在真正的梯度学习里面,我们会遇到这样的问题。
如果用梯度下降法,计算每一个样本你在用模型给它计算时,它们之间是没有互相依赖关系的。所以这些运算是可以并行的。
但是如果用随机梯度下降,这一次的更新是基于上一次的更新结果的,两次样本之间它们是有依赖的,不能并行。
所以,如果用并行化计算这种优势,用梯度下降这种算法,效率是最高的。但是用随机梯度下降,它虽然性能比较好,但是时间复杂度太高。
所以,在深度学习里面,我们会用一种折中的方式。在性能与时间复杂度上取一个折中。这种折中叫Batch,即批量的随机梯度下降。
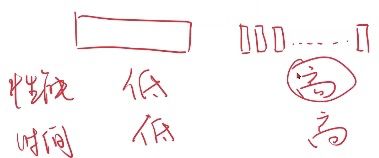
样本全部都用性能不好,单个样本分开时间复杂度高,所以若干个一组,每次用一组去求梯度,然后进行更新。
在深度学习里,默认采用的随机梯度下降SDB算法采用的就是Batch这种方法。
在原始含义中,Batch指的是全部的样本。所以我们用的其实应该叫Mini-Batch。
但现在因为都用Mini-Batch,它成为主流,所以就叫Batch了。