Python爬虫学习笔记-第十课(selenium上)
selenium上
- 1. 基本概念
- 2. Phantomjs快速入门
- 3. Chromedriver+selenium
-
- 3.1 快速入门
- 3.2 定位元素
- 3.3 操作表单元素
- 3.4 综合小练习
1. 基本概念
selenium是⼀个web的自动化测试⼯具,最初是为网站自动化测试而开发的,selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏。
selenium的优点是直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到,爬虫更稳定。相对的,它的缺点是代码量多,性能低。
chromedriver是⼀个驱动Chrome浏览器的驱动程序,使用它才可以驱动浏览器。
下载方式:使用淘宝镜像https://developer.aliyun.com/mirror/NPM?from=tnpm
查看浏览器版本:


下载chromedriver,需注意版本的匹配:

这里同时下载一个phantomjs驱动,后续先简单介绍一下phantomjs的使用。下载好驱动后,建议将其放入python解释器的安装路径,并将该路径写入path环境变量,方便后续代码中的使用。当然,如不想操作环境变量,也可以将其放入自己当前的工程目录下。

2. Phantomjs快速入门
Phantomjs:无头浏览器,⼀个完整的浏览器内核,包括js解析引擎,渲染引擎,请求处理等,但是不包括显示和用户交互页面的浏览器。
简单示例:模拟访问百度首页,在搜索输入框中输入“python”关键字,点击“百度一下”。
寻找搜索输入框标签:

寻找“百度一下”按钮标签:

代码:
from selenium import webdriver
# 加载驱动
driver = webdriver.PhantomJS()
# 打开网址
driver.get('https://www.baidu.com/')
# 定位输入框输入内容
driver.find_element_by_id('kw').send_keys('python')
# 点击事件
button_tag = driver.find_element_by_id('su')
button_tag.click()
# 查看当前请求的url地址
print(driver.current_url)
# 截屏
driver.save_screenshot('baidu.png')
运行结果:

图中框出的红色警告,大致意思是支持selenium的PlantomJS已经被弃用,但不影响其使用,后续我们会使用chromedriver搭配selenium。
保存到同一目录下的截图如下:

3. Chromedriver+selenium
3.1 快速入门
from selenium import webdriver
import time
# 加载Chrome驱动
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com/')
# 窗口最大化
driver.maximize_window()
time.sleep(3)
# 关闭当前窗口
driver.close()
time.sleep(1)
# 退出驱动(关闭所有窗口)
driver.quit()
运行结果:

webdriver的常用方法,找到webdriver.py文件,查看它的structure:

3.2 定位元素
示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 在搜索框中输入python
driver.find_element_by_css_selector('.s_ipt').send_keys('python')
# 通过标签名字查找,打印input标签的个数
inputTag = driver.find_elements_by_tag_name('input')
print(len(inputTag))
运行结果:


常用的元素定位方法:
- 通过id定位 id = “kw”
driver.find_element_by_id('kw').send_keys('python')
driver.find_element(By.ID, 'kw').send_keys('python')
- 通过class_name进行定位 class = “s_ipt”
driver.find_element_by_class_name('s_ipt').send_keys('python')
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('python')
- 通过name来进行定位 name = “wd”
driver.find_element_by_name('wd').send_keys('python')
driver.find_element(By.NAME, 'wd').send_keys('python')
- 通过xpath进行定位
driver.find_element_by_xpath('//input[@id="kw"]').send_keys('xuesong')
推荐使用xpath,原因在于有的标签没有id,class,name等常用属性,上述方法(by_id、by_name等)可能失效,此时使用xpath进行元素定位比较稳妥。
3.3 操作表单元素
- 使用clear方法可以清除输⼊框中的内容。
- 操作按钮有很多种方式。比如单击、右击、双击等。其中最常用的就是点击,直接调用click函数就可以。
示例代码:
from selenium import webdriver
import time
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com/')
time.sleep(2)
# 搜索框输入关键字python
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
time.sleep(1)
# 清空搜索框关键字
inputTag.clear()
time.sleep(1)
# 点击百度一下按钮
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('csdn')
time.sleep(1)
buttonTag = driver.find_element_by_id('su')
buttonTag.click()
运行结果:
selenium启动Chrome浏览器,跳转到百度首页,先是输入关键字Python,然后清空搜索框,再 输入csdn,最后点击“百度一下”,由于这是动态过程,笔者就不截图展示了。
- select元素不能直接点击。因为点击后还需要选中元素。这时候selenium就专门为select标签提供了⼀个类
from selenium.webdriver.support.ui import Select。将获取到的元素当成参数传到这个类中,创建相应的对象,以后就可以使用这个对象进行选择了。
演示url:https://www.17sucai.com/boards/53562.html

示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
import time
driver = webdriver.Chrome()
# 打开实例网站
driver.get('https://www.17sucai.com/pins/demo-show?id=5926')
time.sleep(2)
# 想要找到后续含有选项的select标签,就必须切换iframe
driver.switch_to_frame(driver.find_element_by_id('iframe'))
driver.switch_to.frame(driver.find_element_by_id('iframe'))
# 将定位到的select标签当成参数传入,创建Select对象,后续就可以进行选择操作
selectTag = Select(driver.find_element_by_class_name('nojs'))
# 操作select标签的方式
# 1. 根据值来选择
selectTag.select_by_value('JP')
# 2. 通过下标索引值来选择
# selectTag.select_by_index(1)
运行结果:

成功操作第一个select标签,选择了列表中“Japan”的值。
小拓展
百度iframe标签:IFRAME是HTML标签,作用是文档中的文档,或者浮动的框架(FRAME)。iframe元素会创建包含另外一个文档的内联框架(即行内框架)。通俗理解,iframe标签嵌入了一个与当前页面元素一样的网页内容,在上述示例中,我们想要寻找的select标签在切换后的iframe中。
- 操作非select标签
网页中第二个Try Me!虽然也是可选项,但它不是select标签,操作它和之前略有不同,需要先点击相应标签,然后进一步点击想要的值。

紧接上述代码:
divTag = driver.find_element_by_id('dk_container_country-nofake')
# 如果操作非select标签,需要先点击相应Tag
divTag.click()
time.sleep(1)
# 进一步寻找需要点击的标签
button_tag = driver.find_element_by_xpath('//*[@id="dk_container_country-nofake"]/div/ul/li[2]/a')
button_tag.click()
运行结果:

3.4 综合小练习
需求:模拟登陆豆瓣,先从二维码扫码登录转到账号密码登录,在相应输入框中分别输入账号、密码。

示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
import time
driver = webdriver.Chrome()
# 打开实例网站
driver.get('https://www.douban.com/')
time.sleep(2)
# 切换iframe
login_frame = driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')
driver.switch_to.frame(login_frame)
# 切换登录方式
account_tag = driver.find_element_by_class_name('account-tab-account')
account_tag.click()
time.sleep(1)
# 输入账号和密码
name_tag = driver.find_element_by_id('username')
name_tag.send_keys('12345678912')
time.sleep(1)
passwd_tag = driver.find_element_by_id('password')
passwd_tag.send_keys('123456')
time.sleep(1)
# 点击登录
login_tag = driver.find_element_by_class_name('btn-account')
login_tag.click()
运行结果:
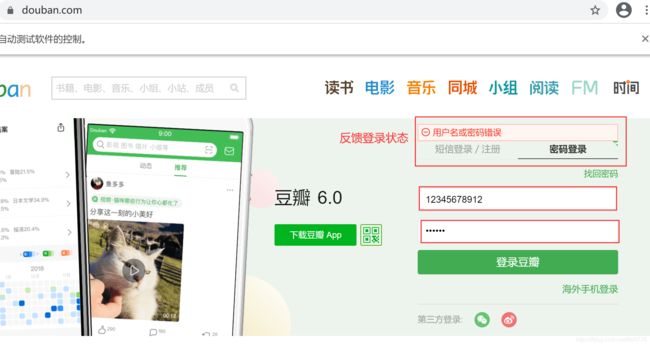
如果定位的元素出现空格(比如上述代码中的find_element_by_class_name('btn-account')),直接写元素内容会报错,解决方案有:
- 可以通过xpath进行定位;
- 如果有其他的元素例如 id name…,则通过其他的方式来进行定位;
- 可以尝试选取选择元素中的一部分。