《Python网络爬虫实战》读书笔记1
文章目录
- Python与网络爬虫
-
- robots与Sitemap
- 查看网站所用的技术
- 数据采集
- 文件与数据的存储
-
- CSV的读写
- 使用数据库
-
- 使用MySQL
- 使用SQLite3
- 使用SQLAlchemy
- JavaScript与动态内容
-
- 使用Selenium
-
- 初步使用
- 触发豆瓣的搜索
- 让页面进行滚动
- 拖拽元素到指定位置
- PyV8与Splash
- 一个更好的js引擎---splash
- 表单与模拟登录
-
- 在Python中使用Cookie
-
- requests的Cookie功能
- 通过Session获取Cookie
- 模拟登陆网站
-
- HTTP基本认证
- 验证码
- Python与文本分析
-
- jieba
-
- 使用jieba分词
- jieba关键词提取
- jieba新建自定义分词器
- 其他的功能
- 其他一些使用
- SnowNLP
- NLTK
- 文本分类与聚类
- 全文所涉及的代码下载地址
- 参考链接
Python与网络爬虫
robots与Sitemap
robots文件指出该网站的信息爬取限制,在爬取的时候,检查这一文件中的内容可以降低爬虫程序被网站的反爬虫机制封禁的风险。比如下面是百度的robots文件:
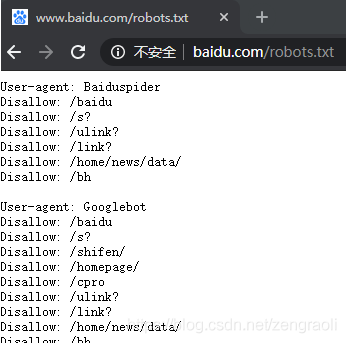
该文件的内容介绍请参考:百度百科robots
Python3自带的robotoparser工具可以解析该文件并指导自己的爬虫,从未执行一些限制;比如下面的代码,使用百度的user_agent,如果遵守robots协议,是不允许爬取taobao的;如果修改成自定义的user_agent则没有这个限制
import urllib.robotparser as urobot
import requests
url = "https://www.taobao.com/"
rp = urobot.RobotFileParser()
rp.set_url(url + "/robots.txt")
rp.read()
# user_agent = 'Baiduspider' # cannot scrap because robots.txt banned you!
user_agent = 'Myspider' # seems good
if rp.can_fetch(user_agent, 'https://www.taobao.com/product/'):
site = requests.get(url)
print('seems good')
else:
print("cannot scrap because robots.txt banned you!")
robots.txt有时候还会定义一个sitemap(站点地图),在sitemap中会列出该网站的页面,有助于访问者以及搜索引擎的爬虫找到网站中的各个页面
查看网站所用的技术
在Python中可以使用wad模块来检测网站使用的技术类型
pip install wad
pip install six
可以使用如下代码
import wad.detection
det = wad.detection.Detector()
url = "http://www.12306.cn"
json_data = det.detect(url)
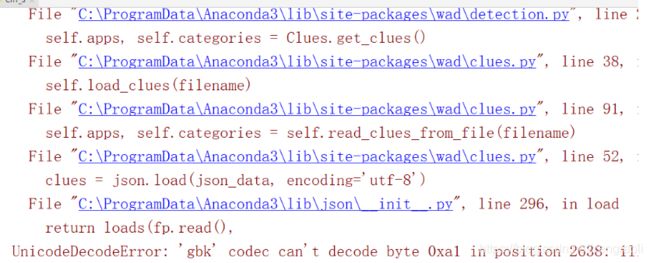
print(json_data)
很方便的查看12306所用的技术,可惜我没执行出来,还是老老实实的自己用chrome分析吧
数据采集
第一个完整的例子,试着爬取360新闻的数据,通过解析页面的数据用bs拿到的数据如下:
- 新闻的标题
- 新闻的链接
- 新闻的时间(要求转换成具体的年月日)

本例子的核心亮点可能就只有这个时间转换了,用的是arrow库,一个比datetime更方便的高级API库,单独使用arrow库的一个例子
#!/usr/bin/env python
# encoding: utf-8
import arrow
data_str_list = ["6天前", "2020-04-13"]
if __name__ == "__main__":
for data_str in data_str_list:
if len(data_str) < 6:
output_date = arrow.now().replace(days=-int(data_str[:1])).date()
else:
output_date = arrow.get(data_str[:10], 'YYYY-MM-DD').date()
print(output_date) # 2020-04-14 # 2020-04-13
因此使用到本例中,完整代码如下
import requests
from bs4 import BeautifulSoup
import arrow
urls = [
u'https://news.so.com/ns?q=北京&pn={}&tn=newstitle&rank=rank&j=0&nso=10&tp=11&nc=0&src=page'
.format(i) for i in range(10)
]
for i, url in enumerate(urls):
print(url, "=======")
r = requests.get(url)
bs1 = BeautifulSoup(r.text)
items = bs1.find_all('a', class_='news_title')
t_list = []
for one in items:
t_item = []
if '360' in one.get('href'):
continue
t_item.append(one.get('href'))
t_item.append(one.text)
date = [one.next_sibling][0].find('span', class_='pdate').text
if len(date) < 6:
date = arrow.now().replace(days=-int(date[:1])).date()
else:
date = arrow.get(date[:10], 'YYYY-MM-DD').date()
t_item.append(date)
t_list.append(t_item)
for one in t_list:
print(one[1], one[0], one[2])
得到的每一个新闻项如下
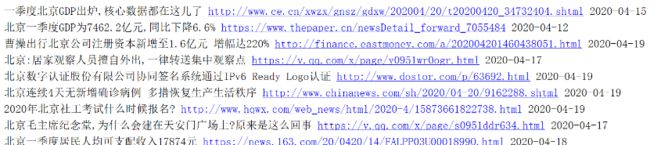
文件与数据的存储
CSV的读写
#!/usr/bin/env python
# encoding: utf-8
import csv
def write_to_csv():
res_list = [['A', 'B', 'C'], [1, 2, 3], [4, 5, 6], [7, 8, 9]]
with open('output.csv', 'a', newline='') as f: # newline可以让输出不带上换行
writer = csv.writer(f, delimiter=',')
writer.writerows(res_list)
def read_from_csv():
with open('output.csv', 'r') as f:
for line in f:
print(line.split(','))
if __name__ == "__main__":
write_to_csv()
read_from_csv()
使用数据库
目前比较常用的数据库或许是MySQL了
使用MySQL
在Python中使用MySQL,最简单的放肆可能是使用pymysql然后使用SQL语句进行操作了
建数据库、建表语句如下
CREATE DATABASE test_python_mysql;
USE test_python_mysql;
DROP TABLE IF EXISTS test_python_mysql_table ;
CREATE TABLE `test_python_mysql_table` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`timestrap` VARCHAR(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
使用PyMySQL进行操作MySQL
import pymysql.cursors
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='123456',
db='test_python_mysql',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
sql = "INSERT INTO `test_python_mysql_table` (`timestrap`) VALUES (%s)"
cursor.execute(sql, ('123456789'))
connection.commit()
with connection.cursor() as cursor:
sql = "SELECT `id`, `timestrap` FROM `test_python_mysql_table` WHERE `timestrap` = %s"
cursor.execute(sql, ('123456789',))
result = cursor.fetchone()
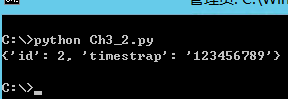
print(result)
finally:
connection.close()
输出如下:
使用SQLite3
很多情况下,可能未必用得到MySQL这么大型的数据库,只需要保存在文件数据库SQLite3即可
import sqlite3
database_name = 'new-sqlite3'
def create_table():
conn = sqlite3.connect(database_name)
print("Opened datavase successfully")
cur = conn.cursor()
cur.execute("""
CREATE TABLE `test_python_mysql_table` (
`id` integer NOT NULL PRIMARY KEY autoincrement,
`timestrap` TEXT DEFAULT NULL
);
""")
print("Table created successfully")
conn.close()
def insert_table():
conn = sqlite3.connect(database_name)
c = conn.cursor()
for i in range(3):
timestrap = 123456781 + i
insert_str = "INSERT INTO `test_python_mysql_table` (`timestrap`) VALUES ({0})".format(str(timestrap))
c.execute(insert_str)
conn.commit()
print("Records created successfully")
conn.close()
def select_from_table():
conn = sqlite3.connect(database_name)
c = conn.cursor()
cursor = c.execute("SELECT * from test_python_mysql_table; ")
for i in cursor.fetchall():
print(i)
if __name__ == "__main__":
create_table()
insert_table()
select_from_table()
使用SQLAlchemy
SQLAlchemy的出现,让我们省略了自己手写SQL语句的过程,类似在django里面使用的数据插入一般,suiran SQLAlchemy是ORM工具,但也支持传统的基于底层SQL语句的操作
使用进行SQLAlchemy建表以及增删改查:
import pymysql
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String, func
from sqlalchemy.orm import sessionmaker
pymysql.install_as_MySQLdb() # 如果没有这个语句,在导入sqlalchemy时可能会报错
Base = declarative_base()
class Test(Base):
__tablename__ = "test_python_mysql_sqlalchemy"
id = Column('id', Integer, primary_key=True, autoincrement=True)
name = Column('name', String(50))
age = Column('age', Integer)
engine = create_engine("mysql://root:123456@localhost:3306/test_python_mysql") # 如果没有test_python_mysql数据库需要先建
db_ses = sessionmaker(bind=engine)
session = db_ses()
Base.metadata.create_all(engine)
# 插入数据
user1 = Test(name='zeng1', age=26)
user2 = Test(name='zeng2', age=36)
user3 = Test(name='zeng3', age=46)
session.add(user1)
session.add(user2)
session.add(user3)
# 修改数据,使用merge()方法
user1.name = "zengraoli"
session.merge(user1)
users = session.query(Test)
print([(user.id, user.name, user.age) for user in users])
# 与上面等效的修改方式
session.query(Test).filter(Test.name=="zeng2").update({'name': "zengraoli2"})
# 删除数据
session.query(Test).filter(Test.id==4).delete()
# 查询数据
users = session.query(Test)
print([(user.id, user.name, user.age) for user in users])
# 按条件查询
user = session.query(Test).filter(Test.age < 40).first() # 取出来第一个
print(user.name)
# 在结果中进行统计
user_count = session.query(Test.name).order_by(Test.name).count()
avg_age = session.query(func.avg(Test.age)).first()
sum_age = session.query(func.sum(Test.age)).first()
print(user_count, avg_age, sum_age)
session.close()
涉及到的建表语句,类似如下,如果以及存在该变,SQLAlchemy则会跳过建表过程
USE test_python_mysql;
DROP TABLE IF EXISTS test_python_mysql_sqlalchemy ;
CREATE TABLE `test_python_mysql_sqlalchemy` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(10) DEFAULT NULL,
`age` INT(2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
输出结果如下
[(1, 'zengraoli', 26), (2, 'zeng2', 36), (3, 'zeng3', 46)]
[(1, 'zengraoli', 26), (2, 'zengraoli2', 36), (3, 'zeng3', 46)]
zengraoli
3 (Decimal('36.0000'),) (Decimal('108'),)
JavaScript与动态内容
使用Selenium
使用Selenium需要有对应的driver,可见参考链接:Windows下配置Chrome WebDriver

初步使用
开始尝试使用Selenium打开百度新闻的头条
from selenium import webdriver
import time
browser = webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
browser.get('http:www.baidu.com')
print(browser.title) # 输出:"百度一下,你就知道"
browser.find_element_by_name("tj_trnews").click() # 点击"新闻"
browser.find_element_by_class_name('hdline0').click() # 点击头条
print(browser.current_url) # 输出:http://news.baidu.com/
time.sleep(10)
browser.quit() # 退出
触发豆瓣的搜索
By是一个附加的用于网页元素定位的元素,为查找元素提供了更抽象的统一接口
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
browser.get('http://www.douban.com')
time.sleep(1)
search_box = browser.find_element(By.NAME,'q')
search_box.send_keys('网站开发')
button = browser.find_element(By.CLASS_NAME,'bn') # 等价于browser.find_element_by_class_name(',bn')
button.click()
让页面进行滚动
send_keys(Keys.PAGE_DOWN)能够模拟在浏览器中进行鼠标滚轮下滑的操作
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
import time
# 滚动页面
browser = webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
browser.get('https://news.baidu.com/')
print(browser.title) # 输出:"百度一下,你就知道"
for i in range(20):
# browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 使用执行JS的方式滚动
ActionChains(browser).send_keys(Keys.PAGE_DOWN).perform() # 使用模拟键盘输入的方式滚动
time.sleep(0.5)
browser.quit() # 退出
拖拽元素到指定位置
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.alert import Alert
browser = webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
# 切换到一个frame
browser.switch_to.frame('iframeResult') #
# 不推荐browser.switch_to_frame()方法
# 根据id定位元素
source = browser.find_element_by_id('draggable') # 被拖拽区域
target = browser.find_element_by_id('droppable') # 目标区域
ActionChains(browser).drag_and_drop(source, target).perform() # 执行动作链
alt = Alert(browser)
print(alt.text) # 输出:"dropped"
alt.accept() # 接受弹出框
PyV8与Splash
V8是一款基于C++编写的JS引擎,是一个能够用来执行JS的运行工具,只要配合网页DOM树解析,在理论上能够当做一个浏览器来使用。首先需要安装PyV8
根据该篇blog文:Windows Python 运行js模块
并没有使用书中提示的PyV8(我自己也试了一下,从github下载了那个PyV8.py文件的确比较麻烦),改用PyExecJs模块
pip install PyExecJs
测试执行js代码
import execjs
js_source = """
var hi =(function(){
function hi(){
return "Hi!";
}
return hi();
})
"""
#通过compile命令转成一个js对象
docjs = execjs.compile(js_source)
print(docjs.call("hi")) # 输出"Hi!"
一个更好的js引擎—splash
使用docker来执行,在浏览器上访问。最大的优点:提供了十分方便的JS网页渲染服务,提供了简单的HTTP API,而且由于不需要浏览器程序,不会使用太多资源,和Selenium相比,这一点尤其突出。Splash的执行脚本是基于Lua语言编写的,支持用户自行编辑,但仍然可以通过HTTP API的方式在Python中调用,因此通过execute接口,可以显示很多更复杂的网页解析过程
表单与模拟登录
在Python中使用Cookie
Python提供了Cookielib库来对Cookie数据进行简单的处理,这个模块里主要的类有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar等
requests的Cookie功能
除了cookiejar模块,在抓取程序中使用更为广泛的是requests的Cookie功能,可以将字典结构信息作为Cookie伴随一次请求来发送
#!/usr/bin/env python
# encoding: utf-8
import requests
cookie = {
'cookiefiled1': 'value1',
'cookiefiled2': 'value2',
# 更多cookie信息
}
headers = {
'User-Agent': "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
}
url = 'https://www.douban.com'
requests.get(url, cookie=cookie, headers=headers)
通过Session获取Cookie
查看网站,登录的url何QuerySrting为
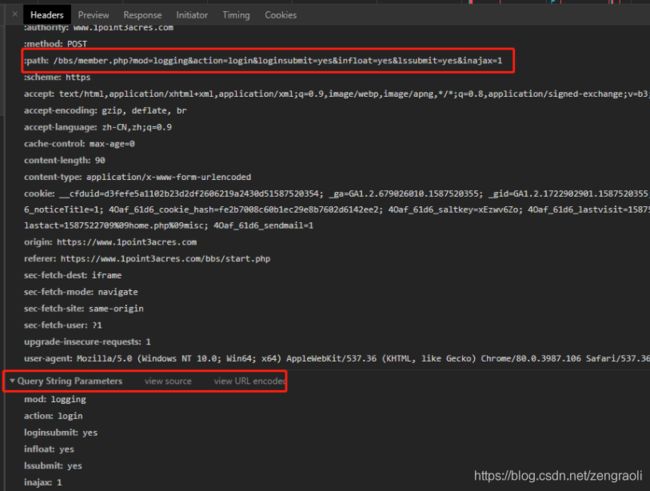
用程序来登录,并得到登录后的会话
#!/usr/bin/env python
# encoding: utf-8
import requests.cookies
headers = {
'User-Agent': "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
}
form_data = {
'username': 'zengraoli',
'password': 'Zeng123456@',
'quickforward': 'yes',
'handlekey': 'ls'
}
sess = requests.Session()
url = "https://www.1point3acres.com/bbs/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1"
sess.post(url, headers=headers, data=form_data)
print(sess.cookies)
print(type(sess.cookies))
# 从主页面中查看是否已经等了
home_url = "https://www.1point3acres.com/bbs/home.php?mod=space&do=home"
html_data = sess.get(url, headers=headers).text
print(html_data)
可以看到,访问的home_url能够对cookie进行保持

模拟登陆网站
假如遇到输入验证码登录的网站,比如微博、知乎等,则可以利用浏览器登录后,得到的cookie来进行下一步操作
下面的例子则首先利用Selenium模拟浏览器来保存豆瓣登录后的Cookie信息,用pickle保存到文件中
import selenium.webdriver
import pickle, time, os
class SeleDouban():
_path_of_chromedriver = r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe'
_browser = None
_url_homepage = 'https://www.douban.com/'
_cookies_file = 'douban-cookies.pkl'
_header_data = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36',
}
def __init__(self):
self.initial()
def initial(self):
self._browser = selenium.webdriver.Chrome(self._path_of_chromedriver)
self._browser.get(self._url_homepage)
if self.have_cookies_or_not():
self.load_cookies()
else:
print('Login first')
time.sleep(30)
self.save_cookies()
print('We are here now')
def have_cookies_or_not(self):
if os.path.exists(self._cookies_file):
return True
else:
return False
def save_cookies(self):
pickle.dump(self._browser.get_cookies(), open(self._cookies_file, "wb"))
print("Save Cookies successfully!")
def load_cookies(self):
self._browser.get(self._url_homepage)
cookies = pickle.load(open(self._cookies_file, "rb"))
for cookie in cookies:
self._browser.add_cookie(cookie)
print("Load Cookies successfully!")
def get_page_by_url(self, url):
self._browser.get(url)
def quit_browser(self):
self._browser.quit()
if __name__ == '__main__':
db = SeleDouban()
time.sleep(10)
db.get_page_by_url('https://accounts.douban.com/passport/setting')
time.sleep(10)
db.quit_browser()
得到cookie成功的信息如下

得到了cookie以后,就可以使用request加载本地的Cookie来完成一些操作,比如进入个人设置查看绑定的邮箱
import requests, pickle
from lxml.html import fromstring
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
sess = requests.Session()
with open('douban-cookies.pkl', 'rb') as f:
cookie_data = pickle.load(f) # 加载cookie信息
# print(cookie_data)
for cookie in cookie_data:
sess.cookies.set(cookie['name'], cookie['value']) # 为session设置cookie信息
res = sess.get('https://accounts.douban.com/passport/setting', headers=headers).text # 访问并获得页面信息
tree = fromstring(res)
profile = tree.xpath("//div[@class='account-form-raw']/div[@class='account-form-field']/span/text()")
print("当前用户的邮箱信息为:", profile[-1])
HTTP基本认证
HTTP基本认证会使浏览器弹出要求用户输入用户名和密码的窗口,并根据输入的信息进行身份验证,比如下面的示例网站

使用requests.auth模块中的HTTPBasicAuth类即可通过该认证并下载最终图片到本地
import requests
from requests.auth import HTTPBasicAuth
url = 'https://www.httpwatch.com/httpgallery/authentication/authenticatedimage/default.aspx'
auth = HTTPBasicAuth('httpwatch', 'pw123') # 将用户名和密码作为对象初始化的参数
resp = requests.post(url, auth=auth)
with open('auth-image.jpeg','wb') as f:
f.write(resp.content)
验证码
通常验证码可以用下面三种形式来处理
- 用OCR的方法
- 手工打码
- 使用人工打码服务
自己做一个图片滑动验证码,请参考:图片滑动验证码的生成
破解图片验证码的代码如下:
# 模拟浏览器通过滑动验证的程序示例,目标是在登录时通过滑动验证
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from PIL import Image
def get_screenshot(browser):
browser.save_screenshot('full_snap.png')
page_snap_obj = Image.open('full_snap.png')
return page_snap_obj
# 在一些滑动验证中,获取背景图片可能需要更复杂的机制,
# 原始的HTML图片元素需要经过拼接整理才能拼出最终想要的效果
# 为了避免这样的麻烦,一个思路就是直接对网页截图,而不是去下载元素中的img src
def get_image(browser):
img = browser.find_element_by_class_name('geetest_canvas_img') # 根据元素class名定位
time.sleep(2)
loc = img.loc
size = img.size
left = loc['x']
top = loc['y']
right = left + size['width']
bottom = top + size['height']
page_snap_obj = get_screenshot(browser)
image_obj = page_snap_obj.crop((left, top, right, bottom))
return image_obj
# 获取滑动距离
def get_distance(image1, image2, start=57, thres=60, bias=7):
# 比对RGB的值
for i in range(start, image1.size[0]):
for j in range(image1.size[1]):
rgb1 = image1.load()[i, j]
rgb2 = image2.load()[i, j]
res1 = abs(rgb1[0] - rgb2[0])
res2 = abs(rgb1[1] - rgb2[1])
res3 = abs(rgb1[2] - rgb2[2])
if not (res1 < thres and res2 < thres and res3 < thres):
return i - bias
return i - bias
# 计算滑动轨迹
def gen_track(distance):
# 也可通过随机数来获得轨迹
# 将滑动距离增大一点,即先滑过目标区域,再滑动回来,有助于避免被判定为机器人
distance += 10
v = 0
t = 0.2
forward = []
current = 0
mid = distance * (3 / 5)
while current < distance:
if current < mid:
a = 2.35
# 使用浮点数,避免机器人判定
else:
a = -3.35
s = v * t + 0.5 * a * (t ** 2) # 使用加速直线运动公式
v = v + a * t
current += s
forward.append(round(s))
backward = [-3, -2, -2, -2, ]
return {'forward_tracks': forward, 'back_tracks': backward}
def crack_slide(browser): # 破解滑动认证
# 点击验证按钮,得到图片
button = browser.find_element_by_class_name('geetest_radar_tip')
button.click()
image1 = get_image(browser)
# 点击滑动,得到有缺口的图片
button = browser.find_element_by_class_name('geetest_slider_button')
button.click()
# 获取有缺口的图片
image2 = get_image(browser)
# 计算位移量
distance = get_distance(image1, image2)
# 计算轨迹
tracks = gen_track(distance)
# 在计算轨迹方面,还可以使用一些鼠标采集工具事先采集人类用户的正常轨迹,将采集到的轨迹数据加载到程序中
# 执行滑动
button = browser.find_element_by_class_name('geetest_slider_button')
ActionChains(browser).click_and_hold(button).perform() # 点击并保持
for track in tracks['forward']:
ActionChains(browser).move_by_offset(xoffset=track, yoffset=0).perform()
time.sleep(0.95)
for back_track in tracks['backward']:
ActionChains(browser).move_by_offset(xoffset=back_track, yoffset=0).perform()
# 在滑动终点区域进行小范围的左右位移,模仿人类的行为
ActionChains(browser).move_by_offset(xoffset=-2, yoffset=0).perform()
ActionChains(browser).move_by_offset(xoffset=2, yoffset=0).perform()
time.sleep(0.5)
ActionChains(browser).release().perform() # 松开
def worker(username, password):
browser = webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
try:
browser.implicitly_wait(3) # 隐式等待
browser.get('your target login url')
# 在实际使用时需要根据当前网页的情况定位元素
username = browser.find_element_by_id('username')
password = browser.find_element_by_id('password')
login = browser.find_element_by_id('login')
username.send_keys(username)
password.send_keys(password)
login.click()
crack_slide(browser)
time.sleep(15)
finally:
browser.close()
if __name__ == '__main__':
worker(username='yourusername', password='yourpassword')

Python与文本分析
jieba
国人开发的一个中文分词与文本分析工具,可以实现很多使用的文本分析处理,通过
pip install jieba
安装
使用jieba分词
使用jieba进行分词非常方便
- jieba.cut:接收3个参数,即待处理的字符串、是否采用全模式(cut_all)、HMM(是否使用HMM模型)
- jieba.cut_for_search():接收2个参数,即待处理的字符串和HMM,该方法适用于搜索引擎构建倒排索引分词,粒度比较细,使用频率不高,使用如下
示例使用如下
#!/usr/bin/env python
# encoding: utf-8
"""
@version: ??
@author: zengraoli
@license: Apache Licence
@contact: [email protected]
@site:
@software: PyCharm
@file: jieba_1.py
@time: 2020/4/23 8:44
"""
import jieba
if __name__ == "__main__":
seg_list = jieba.cut("这里曾经有一座大厦", cut_all=True)
print(" / ".join(seg_list)) # 全模式
seg_list = jieba.cut("欢迎使用Python语言", cut_all=False)
print(" / ".join(seg_list)) # 精确模式
seg_list = jieba.cut("我喜欢吃苹果,不喜欢吃香蕉。") # 默认是精确模式
print(" / ".join(seg_list))
分词后的结果为

jieba关键词提取
基于TF-IDF算法的关键词提取方法:jieba.analyse.extract_tags(),使用如下
import jieba.analyse
import jieba
if __name__ == "__main__":
sentence = '''上海市(Shanghai),简称“沪”或“申”,有“东方巴黎”的美称。是中国四个中央直辖市之一,也是中国第一大城市。是中国大陆的经济、金融、贸易和航运中心。上海创造和打破了中国世界纪录协会多项世界之最、中国之最。上海位于中国大陆海岸线中部的长江口,拥有中国最大的外贸港口、最大的工业基地。'''
res = jieba.analyse.extract_tags(sentence, topK=5, withWeight=False, allowPOS=())
print(res)
取出来的关键词如下

jieba新建自定义分词器
请参考:python中的jieba分词使用手册
其他的功能
自定义词典、调整词频等
其他一些使用
#!/usr/bin/env python
# encoding: utf-8
"""
@version: ??
@author: zengraoli
@license: Apache Licence
@contact: [email protected]
@site:
@software: PyCharm
@file: jieba_1.py
@time: 2020/4/23 8:44
"""
from jieba import posseg
from jieba import tokenize
if __name__ == "__main__":
words = posseg.cut("我不明白你这句话的意思") # posseg.dt为默认磁性标注分词器
for word, flag in words:
print('{}:\t{}'.format(word, flag))
result = tokenize('它是站在海岸遥望海中已经看得见桅杆尖头了的一只航船') # tokenize方法会返回分词结果中词语在原文的起止位置
for tk in result:
print("word %s \t\t start: %d\t\t end: %d" % (tk[0], tk[1], tk[2]))
SnowNLP
是一个主打简洁、使用的中文处理模块,模仿TextBlib编写,拥有更多的功能
SnowNLP中的主要方法如下:
#!/usr/bin/env python
# encoding: utf-8
"""
@version: ??
@author: zengraoli
@license: Apache Licence
@contact: [email protected]
@site:
@software: PyCharm
@file: jieba_1.py
@time: 2020/4/23 8:44
"""
from snownlp import SnowNLP
s = SnowNLP('我来自中国,喜欢吃饺子,爱好是游泳。') # 分词
print(s.words)# 输出 :['我', '来自', '中国', ',', '喜欢', '吃', '饺子', ',', '爱好', '是', '游泳', '。']
# 情感极性概率
print(s.sentiments) # positive的概率,输出:0.9959503726200969
# 文字转换为拼音
print(s.pinyin) # 输出:['wo', 'lai', 'zi', 'zhong', 'guo', ',', 'xi', 'huan','chi', 'jiao', 'zi', ',', 'ai', 'hao', 'shi', 'you', 'yong', '。']
s = SnowNLP(u'「繁體中文」的叫法在臺灣也很常見。')# 繁简转换
print(s.han) # 输出:「繁体中文」的叫法在台湾也很常见。
NLTK
提供了对语料与模型等的内置管理器

更多使用请参考:【Python+中文自然语言处理】(一) NLTK库
文本分类与聚类
下面的例子使用NLTK做了一个简单的分类任务—借助内置的names语料库,通过朴素贝叶斯分类来判断一个输入的名字是男名还是女名
def gender_feature(name):
return {'first_letter': name[0],
'last_letter': name[-1],
'mid_letter': name[len(name) // 2]}
# 提取姓名中的首字母、中位字母、末尾字母为特征
import nltk
import random
from nltk.corpus import names
# 获取名字-性别的数据列表
male_names = [(name, 'male') for name in names.words('male.txt')]
female_names = [(name, 'female') for name in names.words('female.txt')]
names_all = male_names + female_names
random.shuffle(names_all)
# 生成特征集
feature_set = [(gender_feature(n), g) for (n, g) in names_all]
# 拆分为训练集和测试集
train_set_size = int(len(feature_set) * 0.7)
train_set = feature_set[:train_set_size]
test_set = feature_set[train_set_size:]
classifier = nltk.NaiveBayesClassifier.train(train_set)
for name in ['Ann','Sherlock','Cecilia']:
print('{}:\t{}'.format(name,classifier.classify(gender_feature(name))))
全文所涉及的代码下载地址
https://download.csdn.net/download/zengraoli/12366948
参考链接
- Windows下配置Chrome WebDriver
- python3 用execjs执行JS代码
- python中的jieba分词使用手册
- 【Python+中文自然语言处理】(一) NLTK库