- 序言
- 示例 1: 操纵单元格
- 示例 2: 操纵行列区间
- 结论
原文Org as a spreadsheet system: using Emacs lisp as formulas, 由 Bastien 编辑,维护。本文只做学习之用。
序言
本教程介绍如何在Org表中使用Emacs Lisp作为公式。 如果想要了解如何使用Org作为电子表格系统的一般教程,请阅读这个教程。 还可以查看有关此主题的完整Org文档。
示例 1: 操纵单元格
下面是一个简单的表格:
| First name | Last Name | |
|---|---|---|
| John | Doe | [email protected] |
| Jennie | Duh | [email protected] |
你会很容易就注意到第三列模式: [firstname].[lastname]@emacs.edu 。 给出 First name 和 Last name ,很容易计算 Email 列的结果。
首先将光标放在第三列中:
现在键入 C-c } 显示表的坐标(引用)。
对于每一行,需要将第一列(使用 $1 访问)的内容连接到点("."),然后连接到第二列(使用 $2 访问)的单元格, 最后连接到字符串 "@emacs.edu"。 使用 Emacs Lisp 编写的公式如下所示:
'(concat (downcase $1) "." (downcase $2) "@emacs.edu")
现在复制这个公式,在右下角的字段中键入 C-c = 来插入列公式2,然后粘贴公式。 点击 RET 将立即将结果插入此单元格( [email protected] ),并在表格的底部添加 #+TBLFM 行。
警告:请注意初始引用 ( initial quote ) :公式是表达式本身 (expression itself) ,而不是其值。 当 $1 和 $2 引用将被正确的字符串替换时,该表达式将只有一个含义,然后通过在 #+TBLFM 上键入 C-c C-c 来应用该表达式。
经过公式计算表格如下:
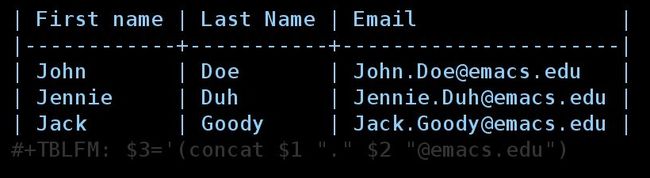
在执行公式时, $1 和 $2 将被解释并由这些单元格的值替换为字符串:不需要用 " 括起 $1 。
如果需要强制 $1 和 $2 被解释为数字,请在 Emacs lisp 表达式的末尾添加标志 ;N 。 参见下面表格:
| First name | Last Name | Maths | French | Mean |
|---|---|---|---|---|
| John | Doe | 12 | 16 | 14 |
| Jennie | Duh | 15 | 9 | 12 |
使用如下公式计算第五列:
#+TBLFM: $5='(/ (+ $3 $4) 2);N
作为一个练习,尝试写出下面表第五列的Emacs lisp公式:
| First name | Last Name | Maths | French | Mean |
|---|---|---|---|---|
| John | Doe | 12 | 16 | John: 14 |
| Jennie | Duh | 15 | 9 | Jennie: 12 |
前四列的值是目前已知的,在此基础上构造出第五列。 (提示:参阅 Emacs lisp 函数 string-to-number 和 number-to-string 。)
解决方案 :不能使用 ;N 标志,因为它会强制将单元格解释为数字,如果这样做,将无法访问第一行单元格的值。 所以一个方案就是使用 string-to-number 和 number-to-string, 如下所示:
#+TBLFM: $5='(concat $1 ": " (number-to-string (/ (+ (string-to-number $3) (string-to-number $4)) 2)))
另一个解决方案是使用 ;L 标志:单元格内容不是被直接解释成字符串或数字,而是直接插入到 Emacs lisp 表达式中。 所以上面的公式可以安全地被下面这个更精简的代替:
#+TBLFM: $5='(concat "$1" ": " (number-to-string (/ (+ $3 $4) 2)));L
注意 "$1" 的双引号:因为在字面上插入 First name 将意味着 "it is an Emacs lisp symbol" 。 所以,当使用 ;L 标志时,添加双引号确保引用被解释为一个字符串。
示例 2: 操纵行列区间
假设有以下表格
| Col1 | Col2 | Col3 | Col4 | Col5 |
|---|---|---|---|---|
| ? | ? | in Col1 and Col2 (no duplicates) | only in Col1 | only in Col2 |
| ? | ? | … | … | … |
| ? | ? | … | … | … |
Col1 和 Col2 包含字符串。
第三列的第一个单元格包含一个字符串,这个字符串由 Col1 和 Col2 中的所有字符串去重后组成。 Col4 包含仅在 Col1 (不在 Col2 )中的字符串,而 Col5 包含仅在 Col2 (不在 Col1 )中的字符串。
如何使用Emacs lisp公式来自动计算出结果?
首先弄清楚想要的结果:
| Col1 | Col2 | Col3 | Col4 | Col5 |
|---|---|---|---|---|
| a | a | a b c d | c | d |
| a | b | |||
| b | a | |||
| c | d |
现在从第二行开始获取第一列的值。
可通过引用 @2$1 访问左上角单元格中的“a”。 可通过引用 @5$1 访问左下方单元格上的“c”。 然后可使用 @2$1..@5$1 访问单元格区间内值。
将上面获取的区间添加到 Col3 的第一个单元格中:
| Col1 | Col2 | Col3 | Col4 | Col5 |
|---|---|---|---|---|
| a | a | a a b c | c | d |
| a | b | |||
| b | a | |||
| c | d |
公式如下:
#+TBLFM: @2$3='(mapconcat 'identity (list @2$1..@5$1) " ")
公式要怎么解读呢?
解释时,区间 @2$1..@5$1 由单元格的值替换,并用空格分隔。 所以 (list @2$1..@5$1) 变成 (list "a" "a" "b" "c") ,整个公式变成
'(mapconcat 'identity (list "a" "a" "b" "c") " ")
上面的公式大体意味着的连接 ("a" "a" "b" "c") 中元素,并在每个元素之间添加一个空格。
把问题更一般话,我很可能不知道表包含多少行。 区间 @2$1..@5$1 变成 @2$1..@>$1 其中 @> 表示“最后一行”, @>$1 表示“第一列的最后一行”。
记住:我们希望第三列包含一个字符串,这个字符串由 Col1 和 Col2 中的所有字符串去重后组成。 首先从 Col1 和 Col2 列出所有值 (list =@2$1..@>$1 @2$2..@>$2) , 然后删除重复项 (delete-dups (list @2$1..@>$1 @2$2..@>$2)), 最后把这个表达式放在上面已有的表达式中。
#+TBLFM: @2$3='(mapconcat 'identity (delete-dups (list @2$1..@>$1 @2$2..@>$2)) " ")
| Col1 | Col2 | Col3 | Col4 | Col5 |
|---|---|---|---|---|
| a | a | a b c d | c | d |
| a | b | |||
| b | a | |||
| c | d |
好的。 现在你已经知道如何操纵区间,你可以用正确的公式替换 "?"了… 记住: Col4 包含仅在 Col1 中而不在 Col2 中的字符串,而 Col5 包含仅在 Col2 中而不在 Col1 中的字符串。 (注:可以编写自己的函数并在 Emacs lisp 公式中使用它们)
Col4 和 Col5 的公式如下:
#+TBLFM: @2$4='(apply 'concat (delete-if (lambda(e) (member e (list @2$2..@>$2))) (list @2$1..@>$1)))
#+TBLFM: @2$5='(apply 'concat (delete-if (lambda(e) (member e (list @2$1..@>$1))) (list @2$2..@>$2)))
不要忘记,可以通过在表上的任何位置点击 C-c ' 来编辑表的公式: 它将打开公式编辑器,并突出显示光标所在的引用(在公式编辑器和表中)。 当需要检查引用是否正确时,公式编辑器非常方便。 此外,在该编辑器中的公式上点击 TAB 将格式化公式,这样更有助于公式编辑!
结论
请浏览Org手册(精简但准确和最新)使用Lisp作为公式的信息:请参阅在线手册 和 相关信息页。