来源:An Imbalanced Malicious Domains Detection Method Based on Passive DNS Traffic Analysis,北京科技大学
一、背景知识
1、“域名”和“标签”有什么区别?
来源:http://www.trademark-clearinghouse.com/help/faq/what-difference-between-%E2%80%9Cdomain-name%E2%80%9D-and-%E2%80%9Clabel%E2%80%9D
https://en.wikipedia.org/wiki/Domain_Name_System#Domain_name_syntax
子域名和域名,三级域名和二级域名详解
子域名->三级域名
域名->二级域名
as the domain name is commonly equated with the second level domain, and the subdomain is commonly equated with the third level domain.
https://icannwiki.org/SLD
术语“域名”是由两个或多个级别组成的名称,例如“商标- clearinghouse.com”。一个标签是一个域名的一部分,例如,“trademark-clearinghouse”来自于“trademark-clearinghouse.com”。
域名由一个或多个部分组成,技术上称为标签(label),它们通常由点连接,并由点分隔,比如example.com。标签可以包含0到63个字符。为根区域保留长度为0的空标签。完整域名的文本表示长度不得超过253个字符
2、URL、域、子域、主机名等之间的区别是什么?
来源:https://www.sistrix.com/ask-sistrix/onpage-optimisation/what-is-the-difference-between-a-url-domain-subdomain-hostname-etc/
“URL”是“统一资源定位器”的缩写,通常用于指网站或互联网地址,而实际的目标通常是目录或特定路径。
URL通常由几个部分组成。为了了解结构和组件,我们将分解如下的示例URL:


3.基于被动DNS流量分析分析恶意域名
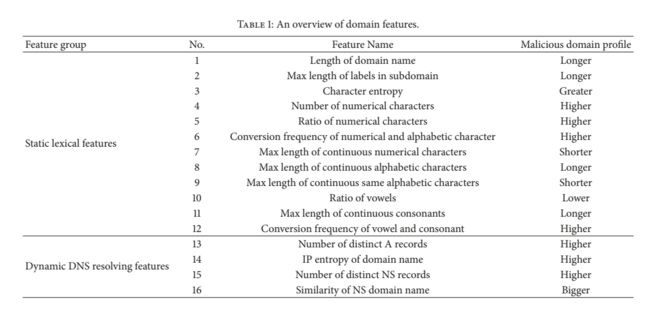
对一些特征的统计分析的结果进行选择以在图1中示出。从这些特征中我们可以发现,这些特征具有较强的区分恶意域和良性域的能力。在本节中,我们将介绍12个静态词法特征和4个动态DNS解析特征,以及构建这些特征来分析恶意域的动机。

3.1 静态的词汇特征。为了避免被发现,攻击者通常使用域生成算法(domain generation algorithm, DGA)来动态生成大量的随机域名。这些恶意域名的词法特征与良性域名有很大区别。我们构造了12个静态词法特征来分析恶意域名。
到目前为止,短域名几乎已经注册;因此,DGA生成的恶意域名大多比良性域名长。恶意域名子域中标签的最大长度通常也较长(即,由点分隔的部分)。因此,我们基于长度度量构造了两个特征:第一,域名长度(特征1),第二,子域标签的最大长度(特征2)。
DGA生成的域名最显著的特性是字符的分布是随机的。我们知道信息熵的定义是由随机数据来源[17]产生的平均信息量。因此,我们使用信息熵来测量字符的无序性。
设d为域名,m为d中不同字符数,定义熵(d)为d的字符熵(特征3)
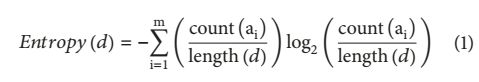
其中ai (i = 1…)m)表示d中的一个字符,count(ai)是d中的ai个数,length(d)是d的长度,如果d的字符熵值较大,则更有可能识别出d是恶意的。
此外,恶意域名是由恶意软件使用,而不是人类使用,所以它们不容易记住或人类发音。因此,恶意域名中数字字符和字母字符的出现也是非常重要的指示符号。在此基础上,我们构建了五个特征:数字字符数(特征4)、数字字符比(特征5)、数字字符和字母字符的转换频率(特征6)、连续数字字符的最大长度(特征7)、连续字母字符的最大长度(特征8),以及连续相同字母字符的最大长度(特征9)。
众所周知,英语字母表中的辅音字母要比元音字母多得多。因此,在随机恶意域名中,元音(Feature 10)的比例较小,连续辅音(Feature 11)的长度较长,元音与辅音(Feature 12)的转换频率较高。
3.2 动态DNS解析特性。使用DNS进行的互联网规模的攻击不可避免地会留下一些足迹,这些足迹隐藏在DNS解析记录中,因此我们可以挖掘这些足迹(即, DNS解析功能)以配置恶意域名。在本节中,我们将介绍4个来自DNS解析记录的动态解析特性。
为了规避黑名单和抵制被窃取,恶意域名服务器返回的DNS答案通常包含多个DNS a记录(即,地址纪录)或NS纪录(即,名称服务器记录)。而且狡猾的攻击者通常不会针对特定的名称服务器或IP范围。因此,我们构建了四个统计特征:A记录的显著数量(特征13),域名的IP熵(特征14),NS记录的显著数量(特征15),NS域名的相似性(特征16)。
不同A记录的数量(特性13)记录DNSDB中解析的IP地址总数。此外,构造了域名的IP熵(特征14)来度量这些解决的IP地址的离散度。设d为域名,S为解析后的IP地址集,n为S中不同IP/16前缀的个数。我们将IP_ENTROPY(d)定义为域名的IP熵(Feature 14)。
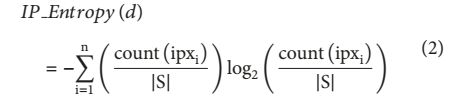
ipxi(i=1....n)意味着S中IP/16前缀,count(ipxi)是S中ipxi的数量,|S|是S的大小。如果d的IP熵值更大,那么d被识别成恶意域名的可能性就更大。
不同的NS记录(特性15)记录DNSDB中解析的名称服务器的总数。此外,构造了NS域名的相似度(特征16)来度量这些名称服务器之间的差异。计算每对域名服务器名之间的编辑距离,然后将这些距离的平均值定义为NS域名的相似度。如果d的NS域名相似度较大,则更有可能被识别为恶意。