迁移学习就是把已经训练好的模型、参数,迁移至另外的一个新模型上使得我们不需要从零开始重新训练一个新model。
举例来说,我们可以train好一个用于Cifar 10的CNN,然后把這个训练出来的模型套用至其他图像分类的数据上,甚至是使用这个模型作为一个特征提取的工具,串接传统的SVM方法。
总之,迁移学习的主旨在于解决数据标记困难、数据取得不易的问题。

为什么叫迁移学习呢?因为我们是把别的模型学习到的参数架构等信息迁移到了当前的目标问题上,以帮助我们更好的解决当前问题。
所谓别的模型是建立在怎样的训练集之上呢?可以料想,若是训练集和我们目标任务的训练集相差很大,那么迁移效果可能不会太好。上图给出了训练集的两种情形:一是和目标任务训练集的领域相同(比如都是动物图片)但任务不同(目标任务是猫狗分类,而此任务是象虎分类);二是领域不同(目标任务训练集是真实图片,此训练集是卡通图片)但任务相同(都是猫狗分类)。
为什么要找这样的训练集来协助我们构建模型呢?因为目标任务的数据集小啊!这一点和半监督学习其实很类似,但是不同点在于半监督学习中的无标签样本的种类也是属于目标任务数据集的,只是没有标签,而迁移学习的额外的数据种类和目标任务数据集不同,想依靠这样的数据来提升我们的模型表现是比半监督学习要困难的。
下面是几个例子:
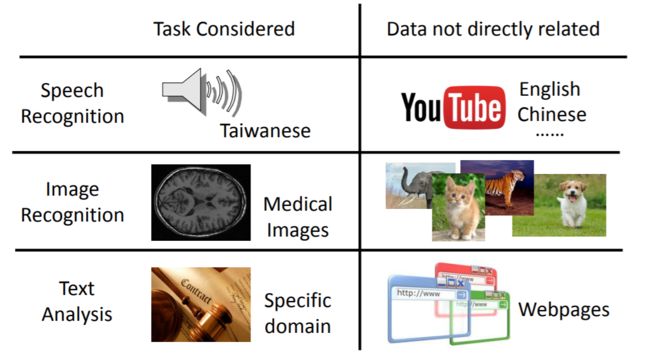
想要做台语的语音识别但数据集太少,可以考虑使用英语和中文的语料库来帮助训练
想要做医疗图像识别诊断,可以考虑使用其它种类图片来帮助训练
想要做法律文本的分析,可以用其它领域的语料库来帮助训练
以上任务真的行得通吗?不确定。但是我们至少可以用迁移学习试试,说不定可以提升模型的表现。迁移学习具体来说可以分成以下四类:
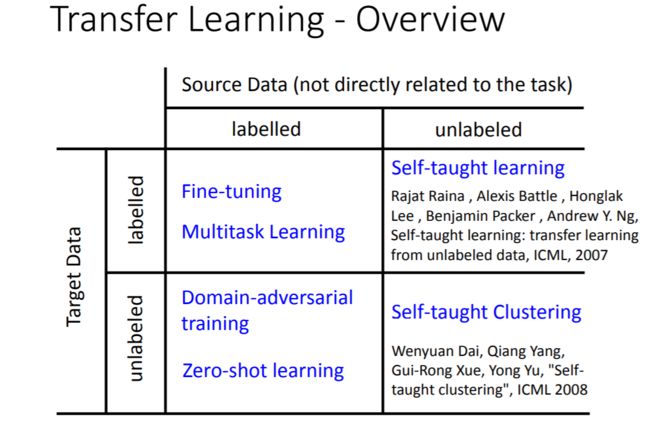
听名字好像个个都很高大上的样子……不过实际上它们的思路都是共通的,名字不同大概只是为了区分这四种情况吧……
这里的Target Data就是我们目标问题的训练集,Source Data则是和目标问题无直接关系的数据集。
1、Target labeled & Source labeled
首先看两者都是有标签的情况——Fine-tuning。

这个方法的思路很简单,既然Target Data数量少,我们就先用数量较多的Source Data训练一个模型,然后使用Target Data对模型进行调优。
这里要注意的是,Source Data虽然和Target Data类型不同,但至少应该是有一定相关性的,不然基于Source Data训练出来的模型可能对后续的训练并没有太大帮助。比如上图中所说的例子,我们想对某个特定用户的音频数据进行分析,但显然单个用户的音频数据的数量是有限的,直接基于有限的数据训练可能效果并不太好,因此我们可以找多个用户的音频数据先训练一个神经网络,然后使用特定用户的音频数据对此网络进行调优。
调优过程中的一大挑战就是过拟合问题。因为Target Data的数据量很小,很容易被模型过拟合,因此我们需要对调优过程添加一定的限制。
第一种方法是Conservative Training。
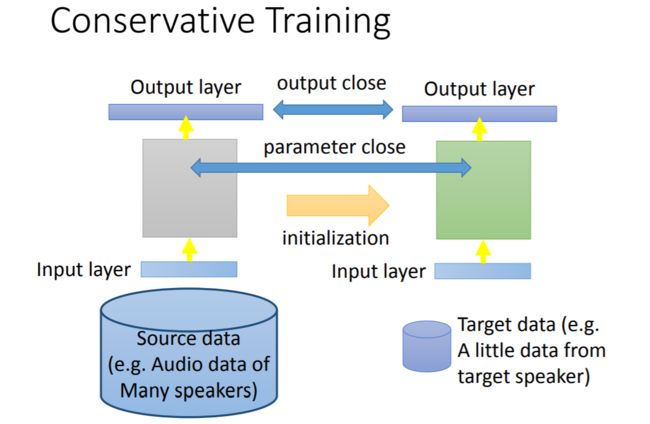
Conservative Training的思路就是让调优过程对模型的改动不要太大,也就是说在由Source Data学习所得的模型基础上,喂给模型Target Data使得模型可以拟合Target Data的同时,也使得调优后的模型依然可以使得Source Data在新模型的输出和原模型相差不大(具体实现过程中可以把输出之间的L2范数作为正则项)。
第二种方法是Layer Transfer。
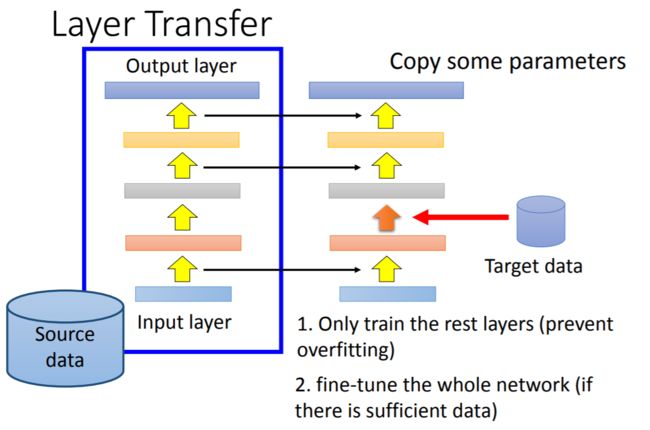
Layer Transfer的思路就是在由Source Data学习所得的模型固定某几层的参数,用Target Data对剩下几层的参数进行调优,这样也可以有效的防止过拟合。
至于选择固定哪几层的参数视具体问题而定:

语音处理的问题一般固定最后几层的参数,对前几层参数进行调优,这是因为个体由于口腔结构等差异,同样的发声方式会得到不同的声音,我们对音频数据进行处理时,前几层做的事是从声音中提取发声方式,因此前几层参数会因个体不同而不同;后几层做的事则是由发生方式得到辨识结果,这部分是具有普适性的,不因个体改变而改变。
相反,图像识别的任务中我们通常固定前几层的参数,对后几层参数进行调优,这是因为用于图像识别的神经网络前几层是用于提取简单特征的,如线条和轮廓等,这部分几乎适用于各种类型的图像;后几层则通过某种方式对低层特征进行组合得到高层特征,组合方式因特定识别任务而有所差异。
下面是Layer Transfer的一个实验结果:
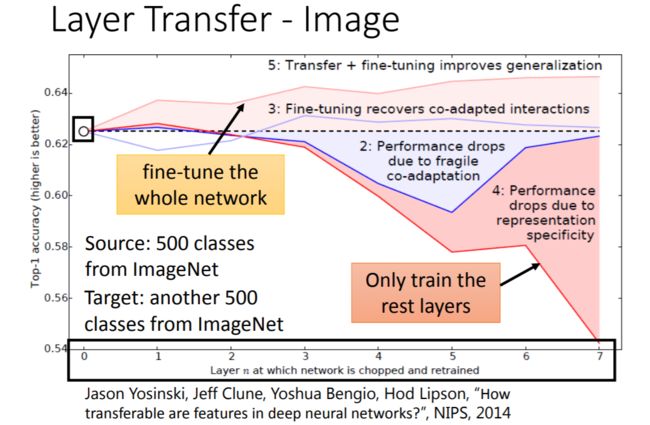
这里的Source Data和Target Data各有60w张图片,是非常大的数据集,而此时Transfer Learning对目标任务仍然可能是有帮助的。可以看到,当我们固定前几层的参数并使用Target Data对剩余几层的参数调优的时候模型效果不如直接使用Target Data训练得到的模型,但是,若我们把前几层参数用Source Data训练得到的参数进行初始化,然后用Target Data对整个模型进行调优,将得到比直接使用Target Data训练的模型更好的性能。
这和我们上面说的好像不太一样啊……我觉得这大概是因为这里的Target Data是比较充足的,所以不太需要担心过拟合问题。
接下来是Target Data和Source Data均有标签的问题中的Multitask Learning。
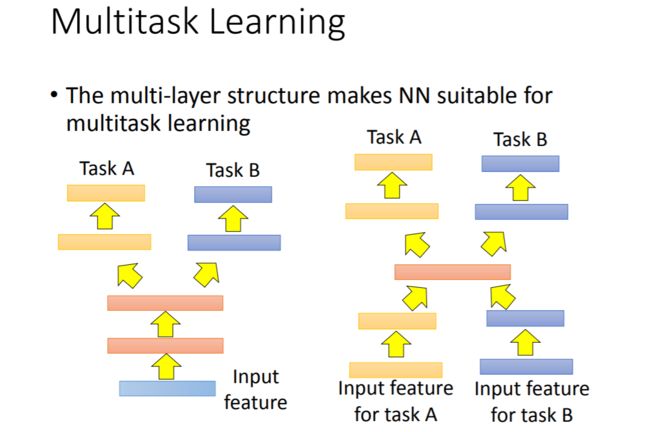
和Fine-tuning不同的是,Fine-tuning只在意在Target Data上的变现,而Multitask Learning希望兼顾在多个任务上的表现。
Multitask Learning的思路就是让多个task同时训练网络的前几层,分别训练网络的后几层。例如上图中的Task A和Task B如果有一定的相似性,就可以同时训练。例如Task A和Task B都是图像识别任务,一个是用来做猫狗分类,一个是用来做象虎分类,那么我们就可以让它们共享网络的前几层参数。
这样做的好处是什么呢?可以在一定程度上防止过拟合,因为多任务的训练要求我们前几层提取特征的方法同时适用于多个任务,因此可以提高泛化性能。当然也可以这样理解,训练Task A时Task B的训练数据可视作noise,而noise可以提高网络的稳健性,从而取得更好的泛化效果,训练Task B时亦然。
下面是一个多任务学习的成功案例:
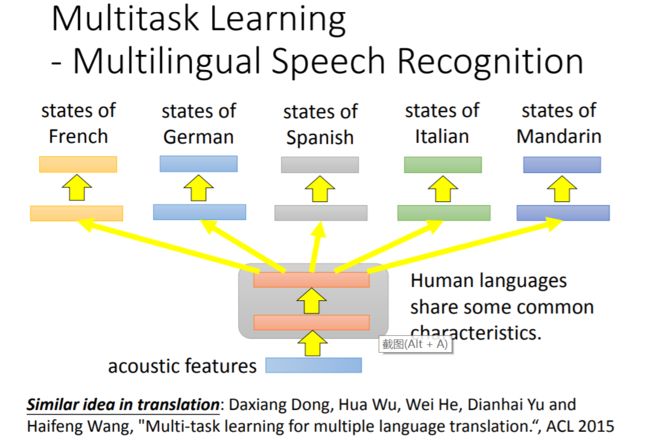
在语音识别任务方面,各国语言的语音识别是可以相互促进的,据李宏毅老师说,有人做过几十种语言的两两组合,发现这些语言的识别任务组合后性能都有所提升。
下图是中文(普通话)在欧洲语言的协助训练下性能得到提升的例子:

2、Target unlabeled & Source labeled
当Target Data无标签,Source Data有标签的时候,用Source Data来协助训练的难度就更大了。此时的任务描述如下:
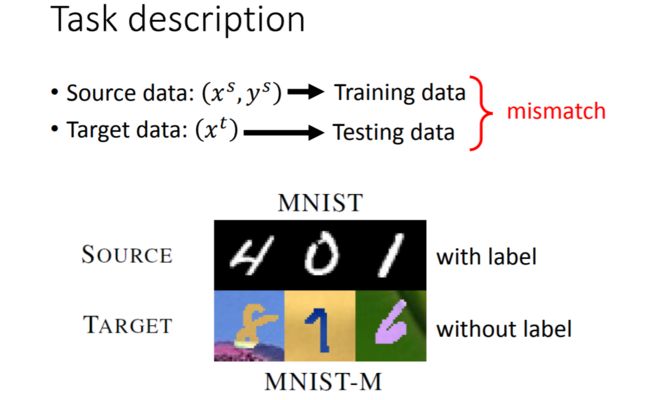
可以看到,因为Target Data无标签,我们把Target Data当作了Testing Data,而把Source Data当作Training Data。
上图的例子中,Source Data和Target Data其实都是手写数字,但由于两者背景以及颜色等相差很大,因此Source Data训练得到的分类器用于Target Data的分类效果是很差的,那么有没有可能同时使用Source Data和Target Data进行训练从而使得模型提取出的特征是数字特征而忽略背景颜色等特征呢?
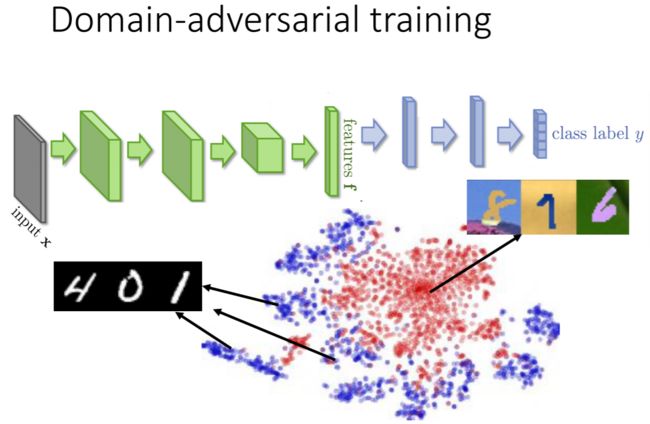
可以看到,Source Data训练得到的分类器提取出的Source Data和Target Data的特征差别很大,我们可以用Domain-adversarial training的方法使得两者提取出的特征较为相似(都是数字本身的特征)。
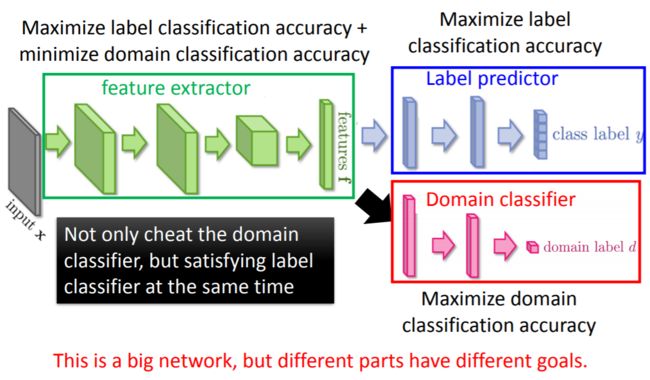
如图所示,我们的模型可以分为模型提取器、标签预测器和数据来源预测器三部分,模型提取器提取出的特征作为标签预测器和数据来源预测器的输入,我们希望标签预测器的性能是好的(这部分使用有标签的Source Data来训练),同时希望数据来源预测器的性能是差的(这部分用Source Data和Target Data同时训练),这样一来就能使得特征提取器提取出的特征是Source Data和Target Data共同具有的特征,从而可以把特征提取器和标签预测器连在一起作为最终的模型用于Target Data的预测。
那么这里怎么让数据来源预测器的性能是差的呢?很简单,把梯度下降改成梯度上升就好了,这样一来数据来源预测器的损失将不断提高,直到它彻底分不清特征是提取自哪个数据集中的数据,我们的目标就达成了。
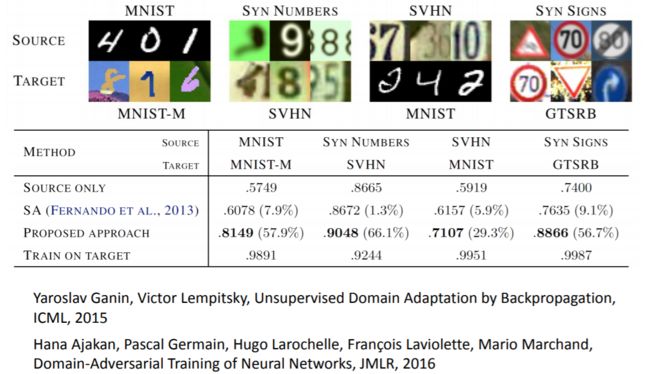
上图显示,Domain-adversarial training算法确实提高了仅由Source Data训练得到的模型的表现。
上面我们讲的是Source Data和Target Data虽有差别,但都可以用于同一项任务的情况,倘若Source Data和Target Data是用于不同任务呢?
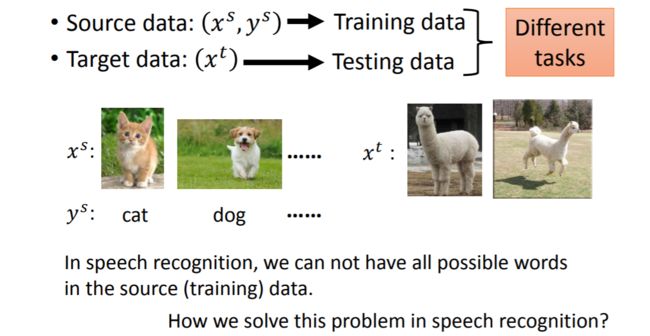
现实生活中我们确实会面临这种类型的问题,在语音识别任务中,即使我们的训练语料很丰富,但也不能保证训练数据中包含测试集中出现所有的单词,那么使用训练集训练得到的模型遇到测试集中从未见过的单词时怎么保证结果的正确性呢?这里使用的解决方法是把识别单位由单词变成音位,然后建立一张音位与单词的对应表(字典),这样一来我们只需要从语音中提取出音位然后再查表找到对应单词就可以了。
这其实就体现了Zero-shot Learning方法的思想。
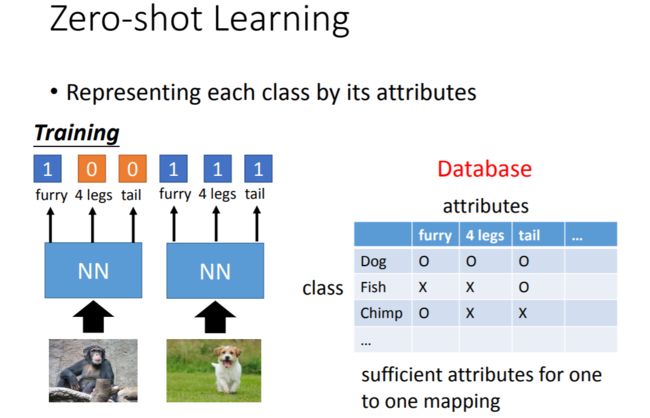
Zero-shot Learning方法的思路是把每个类拆解成一系列的属性来进行表示,比如用“是否有毛”、“是否有4条腿”、“是否有尾巴”三个属性就可以将狗、鱼和黑猩猩区分开来。
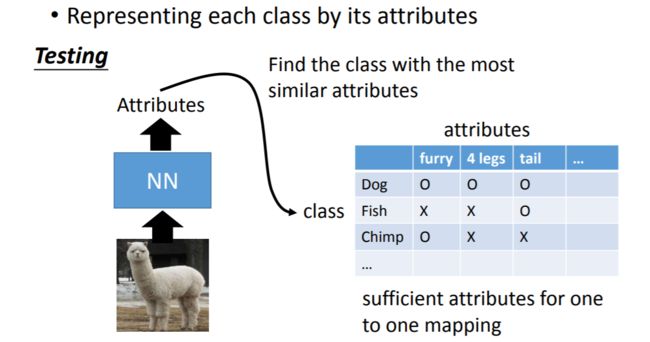
进行测试时,我们从测试样本中提取属性,然后看属性值和哪个类别最相似,就可以做出判断。
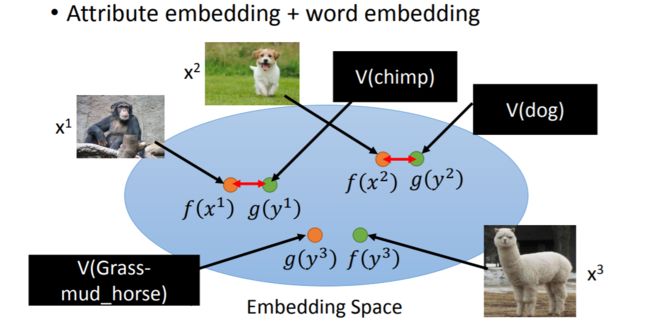
接下来的问题就是如何找到一组属性来很好地刻画类别呢?和词嵌入的思想类似,这里我们要找到一个属性空间,使得各个样本特征在此空间上的投影(通过f)距离此类样本类别在此空间上的投影(通过g)尽可能的近,距离其他类别在此空间上的投影尽可能的远。
把上述目标写成优化问题如下:

通过求解上述优化问题就可以找到一个比较好的embedding space了。实际上,这个space就相当于之前语音识别例子中的字典,我们只需要把各种物种的类别投影到这个空间上即可作为字典。在这个space中,我们可以做到对训练集中不曾出现过的样本进行识别。
下面就是一个很形象的例子:
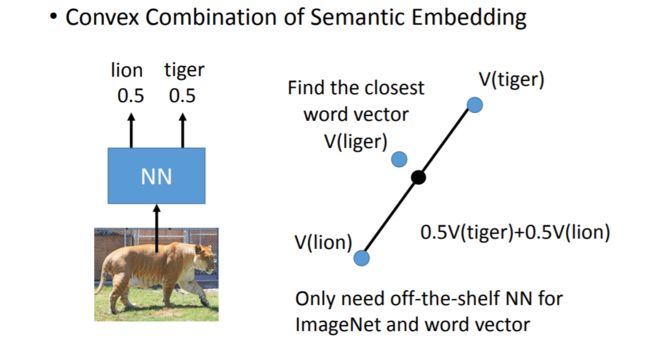
我们的训练集中可能只有老虎和狮子的样本,并没有狮虎兽,因此模型认为这张图片属于狮子和老虎的概率一半一半,这时我们可以找到狮子和老虎两个类别在space上的投影的中点,然后看距离它最近的类别投影对应哪个类别,就可以成功识别出他是狮虎兽(liger)了。