一、bs4解析
import requests
from bs4 import BeautifulSoup
import datetime
if __name__=='__main__':
url = 'https://www.bilibili.com/v/popular/rank/all'
headers = {
//设置自己浏览器的请求头
}
page_text=requests.get(url=url,headers=headers).text
soup=BeautifulSoup(page_text,'lxml')
li_list=soup.select('.rank-list > li')
with open('bZhanRank_bs4.txt','w',encoding='utf-8') as fp:
fp.write('当前爬取热榜的时间为:'+str(datetime.datetime.now())+'\n\n')
for li in li_list:
#解析视频排行
li_rank=li.find('div',class_='num').string
li_rank='视频排行为:'+li_rank+','
#解析视频标题
li_title=li.find('div',class_='info').a.string.strip()
li_title='视频标题为:'+li_title+','
#解析视频播放量
li_viewCount=li.select('.detail>span')[0].text.strip()
li_viewCount='视频播放量为:'+li_viewCount+', '
#解析弹幕数量
li_danmuCount = li.select('.detail>span')[1].text.strip()
li_danmuCount='视频弹幕数量为:'+li_danmuCount+', '
#解析视频作者
li_upName=li.find('span',class_='data-box up-name').text.strip()
li_upName='视频up主:'+li_upName+', '
#解析综合评分
li_zongheScore=li.find('div',class_='pts').div.string
li_zongheScore='视频综合得分为:'+li_zongheScore
fp.write(li_rank+li_title+li_viewCount+li_danmuCount+li_upName+li_zongheScore+'\n')
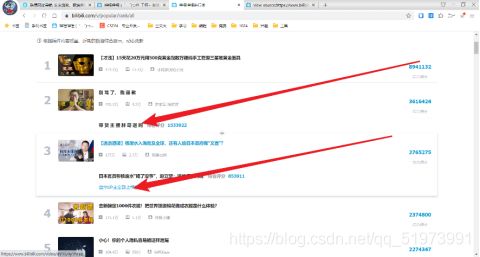
爬取结果如下:

二、xpath解析
import requests
from lxml import etree
import datetime
if __name__ == "__main__":
#设置请求头
headers = {
//设置自己浏览器的请求头
}
#设置url
url = 'https://www.bilibili.com/v/popular/rank/all'
#爬取主页面的源码文件
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
#使用etree对象进行实例化
tree = etree.HTML(page_text)
#爬取各视频的标签所在位置
li_list = tree.xpath('//ul[@class="rank-list"]/li')
#对爬取到的内容进行存储
with open('./bZhanRank.txt', 'w', encoding='utf-8') as fp:
#记录爬取数据的时间
fp.write('时间:'+str(datetime.datetime.now())+'\n\n')
# 使用循环结构,提取各标签中的所需信息
for li in li_list:
#读取视频排名
li_rank=li.xpath('.//div[@class="num"]/text()')
#[0]使用索引从列表中拿出字符串
li_rank='视频排行:'+li_rank[0]+'\n'
#读取视频标题
li_title = li.xpath('.//a/text()')
li_title='视频标题:'+li_title[0]+'\n'
#读取视频播放量
li_viewCount=li.xpath('.//div[@class="detail"]/span[1]/text()')
#.strip()去掉字符串中多余的空格
li_viewCount='视频播放量:'+li_viewCount[0].strip()+'\n'
#读取视频弹幕数量
li_barrageCount = li.xpath('.//div[@class="detail"]/span[2]/text()')
li_barrageCount='视频弹幕数量:'+li_barrageCount[0].strip()+'\n'
#读取视频up主昵称
li_upName=li.xpath('.//span[@class="data-box up-name"]//text()')
li_upName='视频up主:'+li_upName[0].strip()+'\n'
#读取视频的综合评分
li_score=li.xpath('.//div[@class="pts"]/div/text()')
li_score='视频综合评分:'+li_score[0]+'\n\n'
#存储文件
fp.write(li_rank+li_title+li_viewCount+li_barrageCount+li_upName+li_score)
print(li_rank+'爬取成功!!!!')
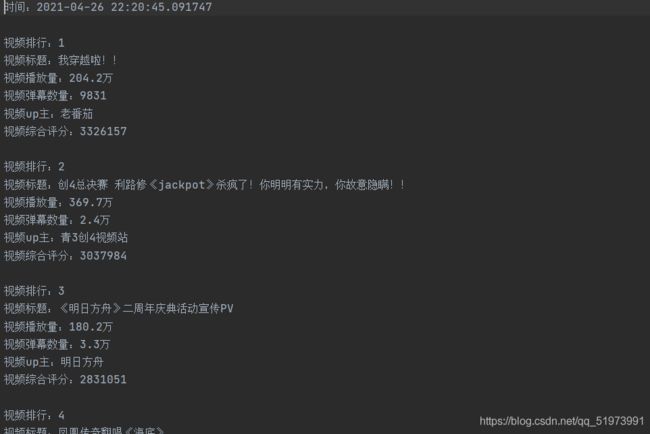
爬取结果如下:
三、xpath解析(二值化处理后展示图片)
#----------第三方库导入----------
import requests#爬取网页源代码
from lxml import etree#使用xpath进行数据解析
import datetime#添加爬取数据的时刻
from PIL import Image#用于打开和重加载图片
from cv2 import cv2#对图片进行二值化处理
from io import BytesIO#对图片进行格式转换
import re#对源代码进行正则处理
#----------函数----------
def dJpg(url,title):
"""
输入url 然后对b站webp格式的图片 进行格式转换为jpeg后 进行保存
:param url:(url)
:return:(null+保存图片文件)
"""
headers = {
//设置自己浏览器的请求头
}
resp = requests.get(url, headers=headers)
byte_stream = BytesIO(resp.content)
im = Image.open(byte_stream)
if im.mode == "RGBA":
im.load()
background = Image.new("RGB", im.size, (255, 255, 255))
background.paste(im, mask=im.split()[3])
im.save(title+'.jpg', 'JPEG')
def handle_image(img_path):
"""
对RGB三通道图片进行二值化处理
:param img_path:(图片路径)
:return:(返回处理后的图片)
"""
# 读取图片
img = cv2.imread(img_path)
# 将图片转化成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 将灰度图转化成二值图,像素值超过127的都会被重新赋值成255
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
return binary
#----------程序主入口----------
if __name__ == "__main__":
#-----变量存放-----
list_rank = [] # 存放视频标题的列表
list_pic_url = [] # 存放图片网址的列表
#-----数据解析(除图片外)-----
#设置请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.2261 SLBChan/10'
}
#设置url
url = 'https://www.bilibili.com/v/popular/rank/all'
#爬取主页面的源码文件
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
#使用etree对象进行实例化
tree = etree.HTML(page_text)
#爬取各视频的标签所在位置
li_list = tree.xpath('//ul[@class="rank-list"]/li')
#-----数据解析(图片)-----
# 由于无法对图片的网址进行标签定位,现对源代码进行正则处理
others_ex = r'"others".*?"tid"(.*?)]'
list_others = re.findall(others_ex, page_text, re.S)
# 使用循环替换掉源代码中others部分
for l in list_others:
page_text = page_text.replace(l, '')
pic_ex = r'"copyright":.*?,"pic":"(.*?)","title":".*?"'
list_pic = re.findall(pic_ex, page_text, re.S)
# 获取图片url组成部分的索引
index = list_pic[0].rfind('u002F')
#对爬取到的url关键字进行拼接组成一个完整的url
for i in list_pic:
pic_url = 'http://i1.hdslb.com/bfs/archive/' + i[index + 5:] + '@228w_140h_1c.webp'
list_pic_url.append(pic_url)
#-----数据保存-----
#对爬取到的内容进行存储
with open('./bZhanRank2.txt', 'w', encoding='utf-8') as fp:
#记录爬取数据的时间
fp.write('b站视频排行榜,'+'时间:'+str(datetime.datetime.now())+'\n')
fp.write('作者:MB\n')
fp.write('*'*10+'以下为排行榜内容'+'*'*10+'\n\n')
# 使用循环结构,提取各标签中的所需信息
for i in range(len(li_list)):
#读取视频排名
li_rank=li_list[i].xpath('.//div[@class="num"]/text()')
pic_title=li_rank#将不含中文的视频排行作为图片名称进行赋值
#[0]使用索引从列表中拿出字符串
li_rank='视频排行:'+li_rank[0]+'\n'
#读取视频标题
li_title =li_list[i].xpath('.//a/text()')
li_title='视频标题:'+li_title[0]+'\n'
#读取视频播放量
li_viewCount=li_list[i].xpath('.//div[@class="detail"]/span[1]/text()')
#.strip()去掉字符串中多余的空格
li_viewCount='视频播放量:'+li_viewCount[0].strip()+'\n'
#读取视频弹幕数量
li_barrageCount = li_list[i].xpath('.//div[@class="detail"]/span[2]/text()')
li_barrageCount='视频弹幕数量:'+li_barrageCount[0].strip()+'\n'
#读取视频up主昵称
li_upName=li_list[i].xpath('.//span[@class="data-box up-name"]//text()')
li_upName='视频up主:'+li_upName[0].strip()+'\n'
#读取视频的综合评分
li_score=li_list[i].xpath('.//div[@class="pts"]/div/text()')
li_score='视频综合评分:'+li_score[0]+'\n\n'
# 存储视频信息(除图片外)
fp.write(li_rank + li_title + li_viewCount + li_barrageCount + li_upName + li_score)
#使用函数处理图片的url并且保存为jpeg格式
dJpg(list_pic_url[i], str(pic_title))
#使用函数对jpeg格式的饿图片进行二值化处理
img = handle_image(str(pic_title) + '.jpg')
# 强制设置图片大小(为防止记事本的行列大小溢出)
img = cv2.resize(img, (120, 40))
height, width = img.shape
for row in range(0, height):
for col in range(0, width):
# 像素值为0即黑色,那么将字符‘1'写入到txt文件
if img[row][col] == 0:
ch = '1'
fp.write(ch)
# 否则写入空格
else:
fp.write(' ')
fp.write('*\n')
fp.write('\n\n\n')
print(li_rank + '爬取成功!!!!')
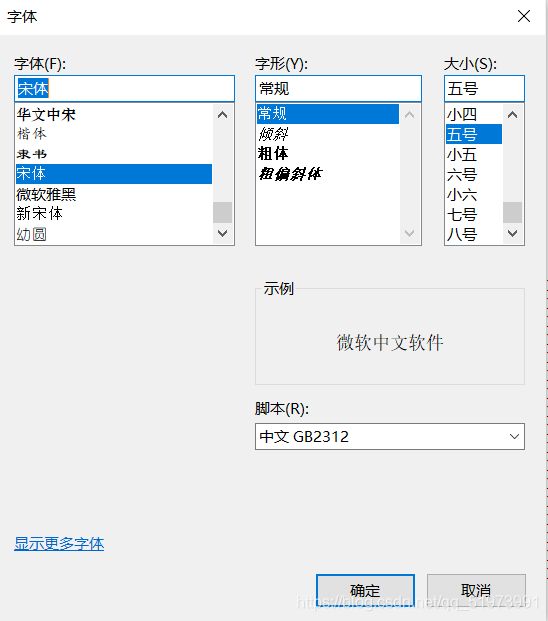
在记事本进行显示结果之前需要对记事本的格式进行下列更改以获得更好的视觉效果:
爬取结果如下:(图片展示,是下载网页中的的封面图片(webp格式),首先对其进行格式转换为jpg格式,然后对其进行二值化处理(对于像素值大于127的像素点直接赋值为0,对于像素值大于127的像素点直接赋值为1)。然后遍历所有的像素点,对于像素值为0的像素点(即为黑色),写入“1”,对于像素值为1的像素点(即为白色),写入“空格”,实现简单的图片模拟显示。)

水平线上和水平线下的图片并非一个时间点进行爬取。

上述图片为了均衡文字显示与图像显示之间的关系,所以图片大小强制设定为较小的尺寸,图片显示并不清晰。要让图片显示清晰,可以不考虑文字显现效果,将图片的尺寸设置较大并且更改记事本中的字体大小(以防串行),可以进行图片较为清晰的展示,如下图所示。

四、分析过程
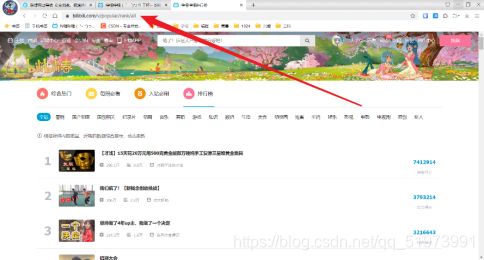
(1)获取url——获取b站视频排行榜的网址
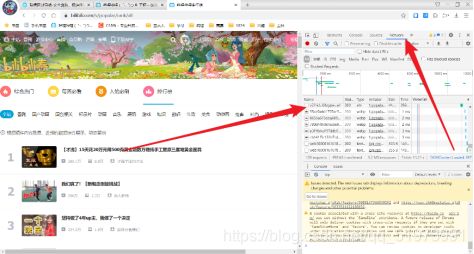
(2)获取请求头——(右击—检查),打开开发者工具,点击Network,随便选择一个数据包,复制其中的请求头即可
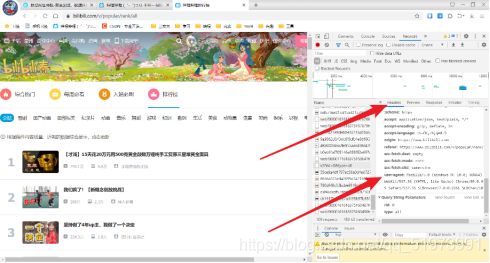
(3)网页分析——点击开发者工具左上角的抓手工具,选中页面中视频,发现每个不同的视频都存放在不同的li标签中
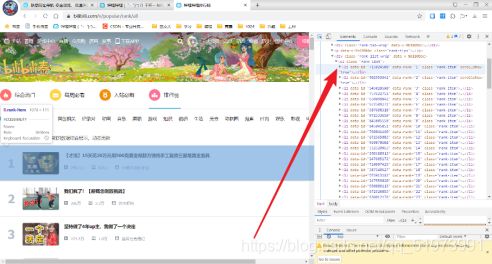
(4)网页分析——选中页面中视频的标题,发现标题内容存放在一个a标签的文本内容中,剩下的视频信息寻找方式同上述。
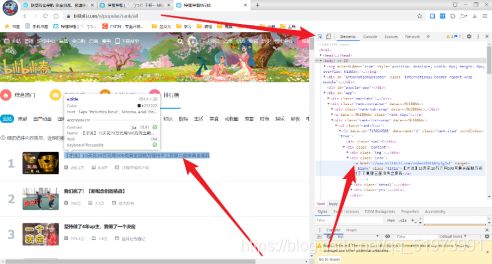
(5)网页分析——在查看到视频播放量信息时,发现其存放在span标签下,含有空格,在编写代码时,使用strip()方法进行去除空格
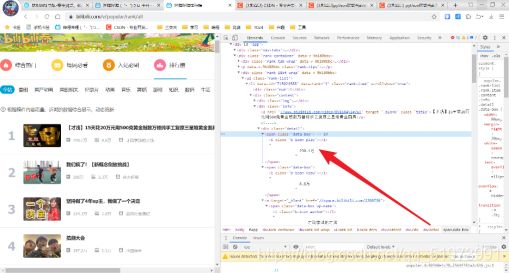
(6)调试代码——调试代码时,爬取的图片url的列表为空
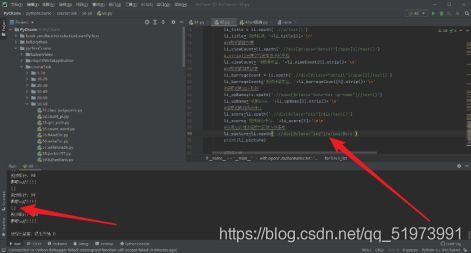
(7)排错——检查图片url存放标签位置,发现位置正确
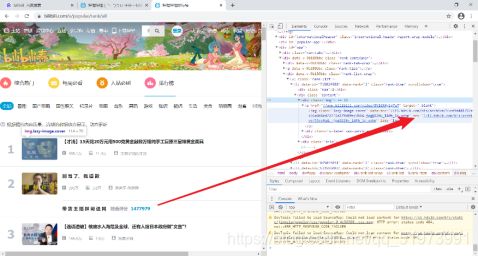
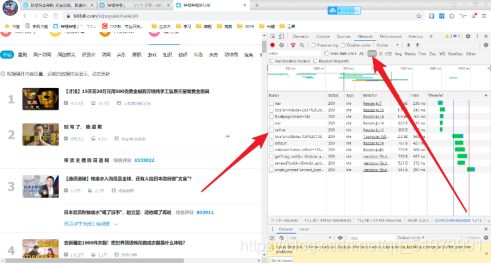
(8)排错——爬取信息为空,可能网页为减轻加载负担,使用的是JavaScript异步加载,在开发者工具中,点击XHR,在数据包中寻找存放图片url的数据包,发现并不存在
(9)排错——(右键—查看网页源代码),在源代码中搜索图片的url,发现所有图片的url全部存放在网页源代码的最后面,可以考虑使用正则表达式进行解析
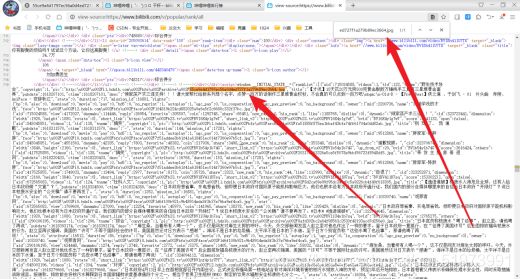
(10)排错——使用正则解析的过程中,返现others列表,此列表为部分视频下方的视频推荐,需进行删除,否则影响正则表达式进行解析
到此这篇关于Python爬虫之爬取哔哩哔哩热门视频排行榜的文章就介绍到这了,更多相关Python爬取B站排行榜内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!