大数据技术之kafka (第 3 章 Kafka 架构深入 ) offset讲解
新版的 Kafka 使用一个选举出来的 controller 来监听 zookeeper,其他 node 再去和 controller 通信,这么做的目的是为了减少 zookeeper 的压力。bootstrap-servers 会自动发现其他 broker,这也是 bootstrap 的含义
前面我们讲到了消费者,接下来我们详细讲下消费者个数改变,分区重新分配是如何接着消费的
首先我们还是一样创建一个新的主题topic 主题是名字叫bigdata 这里报错原因我已经创建过了,主题已经存在

发送一条消息 hello 因为有两个分区,其中一个分区有变化,一个没有变化
![]()
我们开启一个消费者,让其中一个分区被消费
![]()
查看zookeeper ,进入zk客户端
[root@backup01 bin]# ./zkCli.sh
Connecting to localhost:2181
2020-04-06 08:54:43,793 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT
2020-04-06 08:54:43,816 [myid:] - INFO [main:Environment@100] - Client environment:host.name=backup01
2020-04-06 08:54:43,816 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_172
2020-04-06 08:54:43,817 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/local/java/jdk1.8.0_172/jre
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../build/classes:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../build/lib/*.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/slf4j-log4j12-1.7.25.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/slf4j-api-1.7.25.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/netty-3.10.6.Final.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/log4j-1.2.17.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/jline-0.9.94.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../lib/audience-annotations-0.5.0.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../zookeeper-3.4.13.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../src/java/lib/*.jar:/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin/../conf:
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.10.0-862.el7.x86_64
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root
2020-04-06 08:54:43,818 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/usr/local/hadoop/zookeeper/zookeeper-3.4.13/bin
2020-04-06 08:54:43,819 [myid:] - INFO [main:ZooKeeper@442] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@277050dc
2020-04-06 08:54:43,845 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1029] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
Welcome to ZooKeeper!
JLine support is enabled
2020-04-06 08:54:43,960 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2020-04-06 08:54:43,985 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1303] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x1000393bf830000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null 我们进入了zk客户端的根目录 看到的除了zookeeper其他都是kafka

这个controller是后面要聊的,是关于kafka的老大controller不是指定的,这个controller是争抢资源的,谁先抢到谁就是老大,正常情况下,先启动的就是老大
[zk: localhost:2181(CONNECTED) 1] get /controller
controller_epoch controller
[zk: localhost:2181(CONNECTED) 1] get /controller
{"version":1,"brokerid":0,"timestamp":"1586133981273"}
cZxid = 0x500000003
ctime = Mon Apr 06 08:46:21 CST 2020
mZxid = 0x500000003
mtime = Mon Apr 06 08:46:21 CST 2020
pZxid = 0x500000003
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x2000392dd2c0000
dataLength = 54
numChildren = 0
[zk: localhost:2181(CONNECTED) 2] 我们看到brokerid:0 ---> backup01:9092
[zk: localhost:2181(CONNECTED) 3] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 4]broker/ids 0 1 2
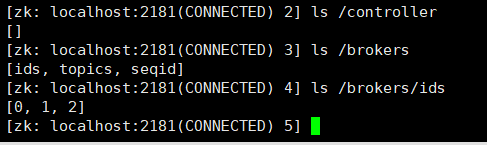
topics有5个主题
[zk: localhost:2181(CONNECTED) 2] ls /controller
[]
[zk: localhost:2181(CONNECTED) 3] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics
[secend, bigdata, three, first, __consumer_offsets]
[zk: localhost:2181(CONNECTED) 6]
在新的版本中topics中多了一个__consumer_offsets这样一个主题

查看到消费者的默认50个分区信息
这里我也不知道为啥在zk客户端查看consumers(消费者组consumer-group)信息为空,,从上面的消息可以知道,我的生产者和消费者都是正常的,不知道新版本有什么特殊的改变,
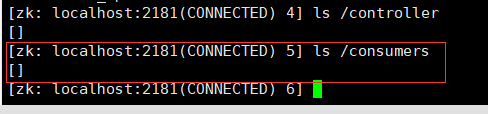
查资料可知:Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
1)修改配置文件 consumer.properties
exclude.internal.topics=false
cd /usr/local/hadoop/kafka/kafka_2.12-2.4.1/config
vim consumer.properties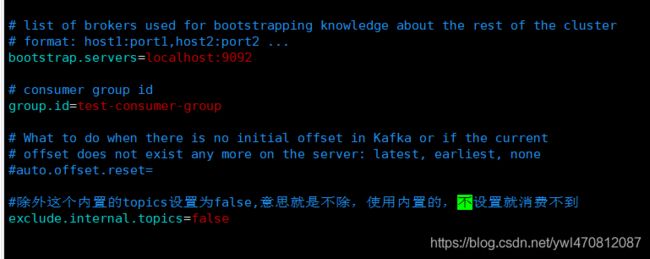
所以我们知道了新版的kafka使用__consumer_offsets想要消费生成功 必须修改consumer.properties 这个配置文件才能正常记录消费信息
__consumer_offsets这个也是个主题,正常情况下,kafka并不希望我们去获取这个主题下的数据,我们这里是为了看里面的消费情况,所以我们就设置一下
2)读取 offset (我们使用的是0.11版本之后)
0.11.0.0 之前:
bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties from-beginning
0.11.0.0 之后版本(含):
bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning ![]()
这个很关键,指定配置文件,如果不指定,那就不生效
这里抛出一个问题,为什么要使用zookeeper?
假设我们要启动一个消费者A去消费这个T1这个主题,我们连的是bootstrap-server,这个A 会把消息放到 topic 为__consumer_offsets这个主题下,那A是不是相当于__consumer_offsets这个主题的生产者,我们要消费的是__consumer_offsets,如果我们这里__consumer_offsets连的bootstrap-server,感觉这个__consumer_offsets又充当了生产者,感觉自己生产数据自己消费,有点怪怪的,所以我们这里使用了zookeeper,
但是在新的版本中
[root@backup01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning
Missing required argument "[bootstrap-server]"
我们从consumer.properties配置文件也可以只是这里用的是bootstrap.servers
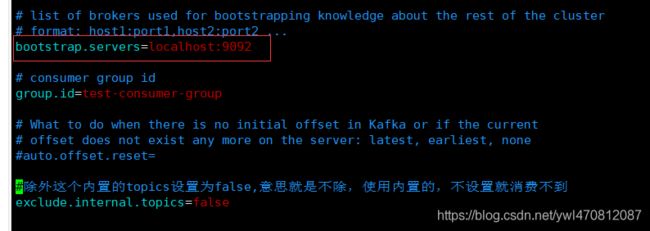
Missing required argument "[bootstrap-server]"那我们不能用zookeeper了
[root@backup01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server backup01:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning
key value形式 [test-consumer-group,__consumer_offsets,3]的hash值我们不知道,但是程序自己是能找到那个分区(50个分区中)能确定唯一的offset
假如一个消费者组的的其中一个消费者挂了,其他消费者怎么能拿到offset,接着消费呢?
因为是同一个组的,挂了之后会通知其他消费者会带着同一个组名来继续消费
我们可以发现大概1秒钟更新一次,这个提交是速度是可以改的
补充一点消费者组kafka的命令操作:
我们通过其它方式查看在kafka消费者组的信息 ,查看consumer group列表,使用--list参数
查看consumer group列表有新、旧两种命令,分别查看新版(信息保存在broker中)consumer列表和老版(信息保存在zookeeper中)consumer列表,因而需要区分指定bootstrap--server和zookeeper参数:
注意:在新的版本中老版本的查询方式已经移除,这里只提供新版本的查询方式
bin/kafka-consumer-groups.sh new--consumer --bootstrap-server backup01:9092 --list
使用kafka的bin目录下面的kafka-consumer-groups.sh命令可以查看offset消费情况,注意,如果你的offset是存在kafka集群上的,就指定kafka服务器的地址bootstrap-server:
./bin/kafka-consumer-groups.sh --bootstrap-server backup01:9092 --describe --group console-consumer-63897GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-63897 bigdata 0 - 3 - consumer-console-consumer-63897-1-255b7119-e051-4ee1-ad64-d44581be1d20 /192.168.0.120 consumer-console-consumer-63897-1
console-consumer-63897 bigdata 1 - 2 - consumer-console-consumer-63897-1-255b7119-e051-4ee1-ad64-d44581be1d20 /192.168.0.120 consumer-console-consumer-63897-1
[root@backup01 kafka_2.12-2.4.1]# ./bin/kafka-consumer-groups.sh --bootstrap-server backup01:9092 --describe --group console-consumer-69882
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-69882 bigdata 0 - 3 - consumer-console-consumer-69882-1-7df49099-2e83-4871-8468-3279b3213edb /192.168.0.120 consumer-console-consumer-69882-1
console-consumer-69882 bigdata 1 - 2 - consumer-console-consumer-69882-1-7df49099-2e83-4871-8468-3279b3213edb /192.168.0.120 consumer-console-consumer-69882-1
补充说明:
关于这个__consumer_offsets(后续再说,这里大概了解下)
抛出问题:
__consumer_offsets这个topic是由kafka自动创建的,默认50个,但是都存在一台kafka服务器上,这是不是就存在很明显的单点故障? 经测试,如果将存储consumer_offsets的这台机器kill掉,所有的消费者都停止消费了。请问这个问题是怎么解决的呢?
原因分析:
由于__consumer_offsets这个用于存储offset的分区是由kafka服务器默认自动创建的,那么它在创建该分区的时候,分区数和副本数的依据是什么? 分区数是固定的50,这个没什么可怀疑的,副本数呢?应该是一个默认值1,依据是,如果我们没有在server.properties文件中指定topic分区的副本数的话,它的默认值就是1。
__consumer_offsets是一个非常重要的topic,我们怎么能允许它只有一个副本呢?这样就存在单点故障,也就是如果该分区所在的集群宕机了的话,
我们的消费者就无法正常消费数据了。
我在笔记本上搭建了kafka集群,共3个Broker,来解决这个问题。下面是一些记录。
说明:如果你的__consumer_offsets这个topic已经被创建了,而且只存在一台broker上,如果你直接使用命令删除这个topic是会报错了,提示这是kafka内置的topic,禁止删除。可以在zookeeper中删除(我是使用ZooInspector这个客户端连上zookeeper,删除和__consumer_offsets这个topic有关的目录或节点)。