Python入门到实战(五)自动化办公、pandas操作Excel、数据可视化、绘制柱状图、操作Word、数据报表生成、pip install国内镜像下载
Python入门到实战(五)conda使用、pandas操作Excel、数据可视化、绘制柱状图、操作Word、数据报表生成、pip install国内镜像下载
- conda使用
-
- 常用操作
- 配置VS+Conda
- Python实现办公自动化
-
- 操作Excel
-
- Pandas将数据写入Excels
- Pandas读取Excel数据并排序
- Pandas绘制数据
-
- 学习Pandas绘制柱状图
- 学习Pandas绘制叠加柱状图
- 操作Word
-
- 添加数据
- pip install xx 切换国内镜像服务器下载,解决下载慢的问题
- ImportError: DLL load failed while importing etree: 找不到指定的模块
- 案例 统计学生成绩 数据报表的生成(Excel+Word)
conda使用
常用操作
查看环境中的所有包:conda list
安装 XXX 包:conda install XXX
删除 XXX 包:conda remove XXX :
列出所有环境:conda env list
查看版本:conda–version
更新:conda update conda
创建环境:conda create -n
删除环境:conda remove -n
删除指定环境:conda env remove -n XXX
激活环境:active
退出环境:deactivate
配置VS+Conda
我配置三个环境变量,C:\Anaconda3;C:\Anaconda3\Scripts;C:\Anaconda3\Library\bin
在进入VSCode从Python.pythopath中改到Anaconda目录下重启VS后即可使用

Python实现办公自动化
1 将Excel文件读入计算机
2 操作excel 数据可视化操作(pandas)
3 操作word (python-word)
操作Excel
Pandas将数据写入Excels
Series与DataFrame:
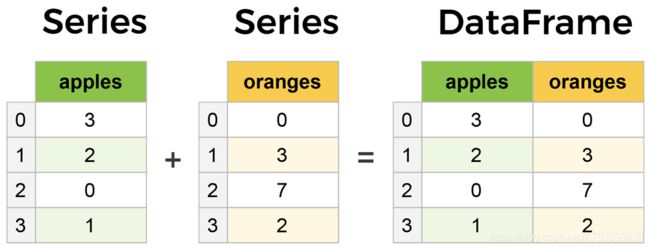
In [1]: import pandas as pd
In [5]: df=pd.DataFrame({
...: 'id':[1,2,3],
...: 'name':['张','李四','王五'],
...: 'age':[19,20,21]
...: })
In [6]: df
Out[6]:
id name age
0 1 张 19
1 2 李四 20
2 3 王五 21
In [7]: df=df.set_index('id')
In [8]: df
Out[8]:
name age
id
1 张 19
2 李四 20
3 王五 21
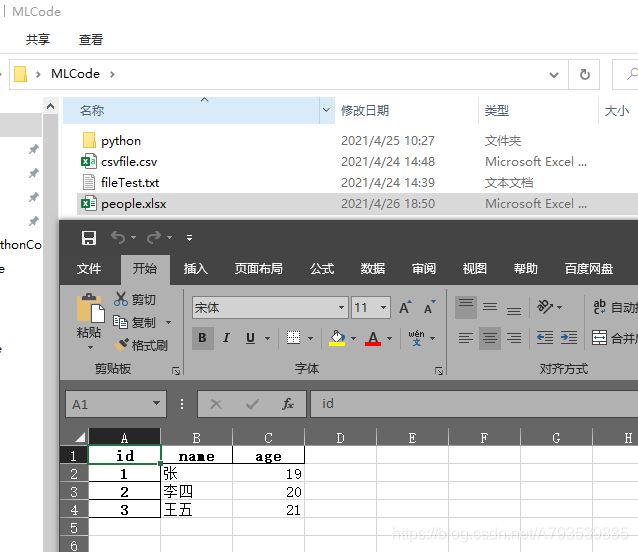
In [11]: df.to_excel(r'C:\Users\ASUS\Desktop\MLCode\people.xlsx')
结果图片:
Pandas读取Excel数据并排序
下面一段代码实现读取上头的Excel文件并进行一个排序操作
In [17]: path='C:\\Users\\ASUS\\Desktop\\MLCode\\people.xlsx'
In [18]: people=pd.read_excel(path,sheet_name='Sheet1')
In [19]: people
Out[19]:
id name age
0 1 张 19
1 2 李四 20
2 3 王五 21
In [20]: people.sort_values(by='age',ascending=False,inplace=True)
#inplace表示就地,直接修改people,若为FALSE则会返回一个对象,对people本身不会修改
In [21]: print(people)
id name age
2 3 王五 21
1 2 李四 20
0 1 张 19
Pandas绘制数据
学习Pandas绘制柱状图
想要通过Pandas可视化数据读取student里的数据并通过可视化展示,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
students=pd.read_excel(r'C:\Users\ASUS\Desktop\MLCode\student.xlsx')
students.sort_values(by='Score',inplace=True,ascending=False)
plt.bar(students['Name'],students.Score,color='orange')
plt.title('Student score')#名称是学生分数
plt.xlabel('Name')#横坐标是name
plt.ylabel('score')#纵坐标是score
plt.xticks(students.Name,rotation='90')#学生名旋转90读
plt.tight_layout()
plt.show()
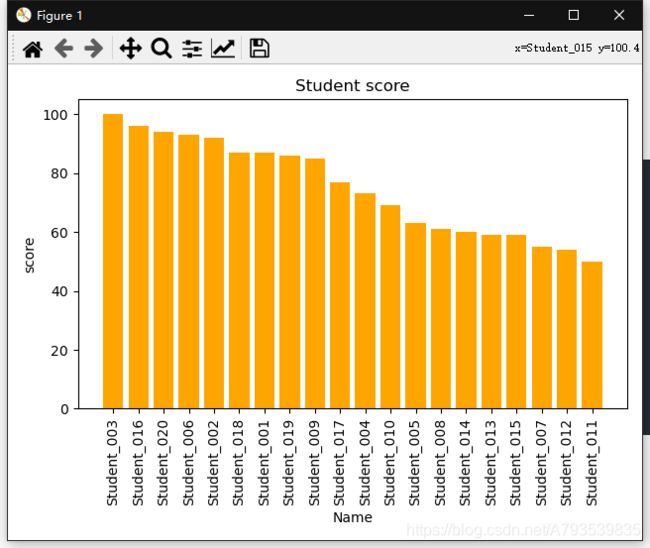
如图所示,数据成功表示
如果需要显示中文,则:
import pandas as pd
import matplotlib.pyplot as plt
students=pd.read_excel(r'C:\Users\ASUS\Desktop\MLCode\student.xlsx')
students.sort_values(by='Score',inplace=True,ascending=True)
# add chinese character support
from matplotlib.font_manager import FontProperties
font=FontProperties(fname=r"C:\Windows\Fonts\AdobeSongStd-Light.otf",size=16)
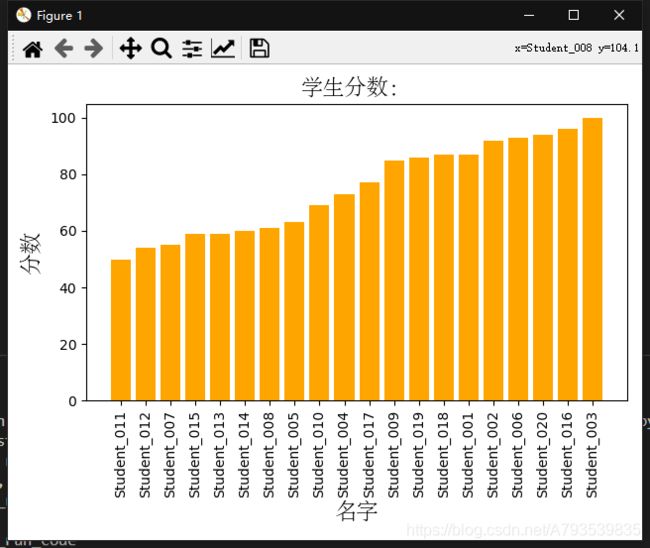
plt.bar(students['Name'],students.Score,color='orange')
plt.title('学生分数:',FontProperties=font)
plt.xlabel('名字',FontProperties=font)
plt.ylabel('分数',FontProperties=font)
plt.xticks(students.Name,rotation='90')
plt.tight_layout()
plt.show()
调库,添加中文支持,用font对象接收,同时指定FontProperties为font即可、字体可从\Windows\Fonts\文件夹目录下寻找合适的字体,效果如下:
学习Pandas绘制叠加柱状图
表中:
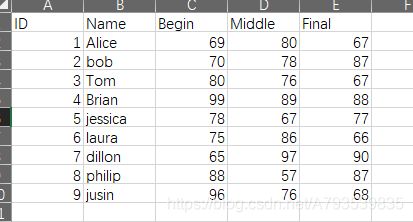
Begin代表开学初期考试,middle代表期中考,final代表期末考,目标是求和并排序绘图,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
stu=pd.read_excel(r'C:\Users\ASUS\Desktop\MLCode\threemon.xlsx')#读文件
stu['sum']=stu['Begin']+stu['Middle']+stu['Final']#求各时期考试和
stu.sort_values(by='sum',inplace=True)#排序
stu.plot.barh(x='Name',y=['Begin','Middle','Final'],stacked=True)#stack可实现叠加
plt.tight_layout()
plt.show()
结果:

操作Word
实现这个功能需要。pip install python-docx后使用Python-docx实现对Word的增删改查
新建word文档
from docx import Document
document=Document()
document.save('new.docx')
在创建了document对象后,其实就是一个实例了,你可以对它做任何操作,不过都是在内存中,当保存后,它将写入磁盘
添加数据
document.add_paragraph(‘这是一个段落’)
document.add_heading(‘这是一个标题’,level=1)
document.add_page_break() #分页符
table=document.add_table(rows=6,cols=6)
document.add_picture(‘xx.jpg’,width=Inches(1.25))
pip install xx 切换国内镜像服务器下载,解决下载慢的问题
pip install python-docx总是安装失败吗?就像下面这样,或者速度太慢
(base) C:\Users\ASUS> pip install python-docx
Collecting python-docx
Downloading python-docx-0.8.10.tar.gz (5.5 MB)
|███████▌ | 1.3 MB 1.2 kB/s eta 1:00:46
下了5分钟,就下载了这么一点,让人绝望。
因为服务器在境外,默认下载源也都是在国外。这个时候就可以通过国内镜像服务器下载,
pip国内的一些镜像还有:
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
修改方法就是在打pip install XX后加上-i参数,指定pip源,如:pip install python-docx -i https://mirrors.bfsu.edu.cn/pypi/web/simple/
具体代码如下
(base) C:\Users\ASUS> pip install python-docx -i https://mirrors.bfsu.edu.cn/pypi/web/simple/
Looking in indexes: https://mirrors.bfsu.edu.cn/pypi/web/simple/
Collecting python-docx
Downloading https://mirrors.bfsu.edu.cn/pypi/web/packages/e4/83/c66a1934ed5ed8ab1dbb9931f1779079f8bca0f6bbc5793c06c4b5e7d671/python-docx-0.8.10.tar.gz (5.5 MB)
|████████████████████████████████| 5.5 MB 3.3 MB/s
Requirement already satisfied: lxml>=2.3.2 in c:\software\anaconda\lib\site-packages (from python-docx) (4.6.1)
Building wheels for collected packages: python-docx
Building wheel for python-docx (setup.py) ... done
Created wheel for python-docx: filename=python_docx-0.8.10-py3-none-any.whl size=184495 sha256=63b082dbe118cb159bfba8e59a24cb64c1c7e8c4ceebc7477b2d6d1418d94ffb
Stored in directory: c:\users\asus\appdata\local\pip\cache\wheels\35\ba\36\4560ae617c53624d0f4026667ece078b5441eb6e49ef3ed0f0
Successfully built python-docx
Installing collected packages: python-docx
Successfully installed python-docx-0.8.10
ImportError: DLL load failed while importing etree: 找不到指定的模块
其实我是要用Document但是却提示我
from lxml import etree
ImportError: DLL load failed while importing etree: 找不到指定的程序
这个时候,先卸载,
PS C:\Users\ASUS\Desktop\MLCode> pip uninstall lxml
Found existing installation: lxml 4.6.1
Uninstalling lxml-4.6.1:
Would remove:
c:\software\anaconda\lib\site-packages\lxml-4.6.1.dist-info\*
c:\software\anaconda\lib\site-packages\lxml\*
Proceed (y/n)? y
Successfully uninstalled lxml-4.6.1
卸载完成后,在安装,用中科大镜像安装
PS C:\Users\ASUS\Desktop\MLCode> pip install lxml -i https://mirrors.bfsu.edu.cn/pypi/web/simple/
Looking in indexes: https://mirrors.bfsu.edu.cn/pypi/web/simple/
Collecting lxml
Downloading https://mirrors.bfsu.edu.cn/pypi/web/packages/e7/bc/9e7f38333767146191afbb17simple/6ffd2c1d553589a11b7e499f12aacc6cf5cd/lxml-4.6.3-cp38-cp38-win_amd64.whl (3.5 MB)
|████████████████████████████████| 3.5 MB 3.3 MB/s
Installing collected packages: lxml 6ffd2c1d553589a11b7e499f12aacc6cf5cd/lxml-4.6.3-cp38-cp38-win_amd64.whl (3.5 MB)
Successfully installed lxml-4.6.3
这样就成功了
希望能有所帮助
案例 统计学生成绩 数据报表的生成(Excel+Word)
大致需求:
统计学生的分数,做从高到低排序,在导出的word中有成绩分析报告title、第一名学生成绩和总共多少名考生参与了考试、
表格数据如下:
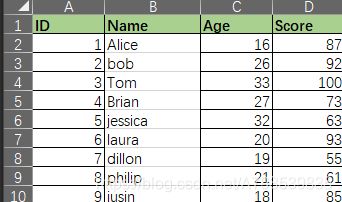
代码:
from docx import Document
import pandas as pd
import matplotlib.pyplot as plt
imgname='chart.jpg'
stu=pd.read_excel(r'C:\Users\ASUS\Desktop\MLCode\student.xlsx')
stu.sort_values(by='Score',inplace=True,ascending=False)
plt.bar(stu.Name,stu.Score,color='orange')
plt.title('Score Chart')
plt.xlabel('Name:')
plt.ylabel('Score:')
plt.tight_layout()
plt.savefig(imgname)
docu=Document()
#标题
p=docu.add_heading('班里学生成绩情况:',level=0)
f_stu=stu.iloc[0,:]['Name']#绝对位置去获取
f_score=stu.iloc[0,:]['Score']#分数
p=docu.add_paragraph('班里的第一名是:')
p.add_run(f'{str(f_stu)}分数为:{str(f_score)}').bold=True
#班里情况
p1=docu.add_paragraph(f'有{len(stu.Name)}名学生考试了,总体情况如下:')
table=docu.add_table(rows=len(stu.Name)+1,cols=2)
table.cell(0,0).text='学生姓名:'
table.cell(0,1).text='学生分数:'
for i,(index,row) in enumerate(stu.iterrows()):
table.cell(i+1,0).text=str(row['Name'])
table.cell(i+1,1).text=str(row['Score'])
docu.add_picture(imgname)
docu.save('studentsReport.docx')
print('finish')
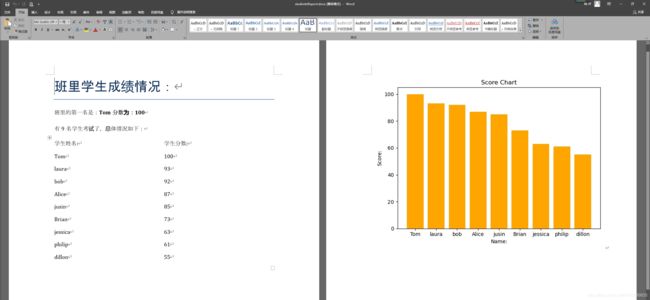
运行结果
c:\Users\ASUS\Desktop\MLCode\report.py'
finish
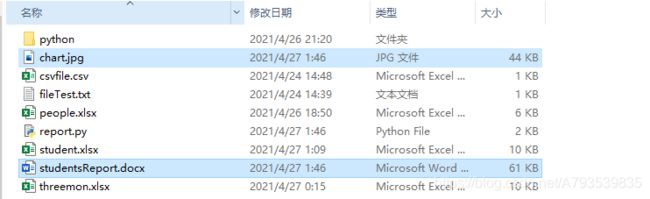
在目录下都有新建文件:
以上为自动化办公的入门操作学习