针对在校大学生的C语言入门学习——链表
- 看到标题可能大家会觉得我怎么说话不算,不是说好的这次要给大家带来《学生管理系统》项目吗?其实我没有食言,只是整个项目太大了,一篇文章很难说完。
- 为什么这次要聊一聊链表呢,因为《学生管理系统》肯定是要对学生的数据进行各种操作。既然涉及到了大量的数据,选择一个合适的数据结构来存放数据就是这个项目成功的关键。无论是从实际效果考虑,还是以大家的学习基础考虑,链表都是一个非常不错的选择。
- 今天给大家带来一个我对链表的封装,链表是所有数据结构中最好实现的数据结构。对数据结构的封装也都是围绕增、删、改、查四大功能,下面我们开始。
结构体封装
typedef struct Node
{
void* data;
struct Node* next;
struct Node* pre;
}Node;
typedef struct Link
{
Node* head;
Node* tail;
int size;
}Link;
- Node结构体是链表节点的结构体封装,可以看出我使用的是一个双向链表。data之所以定义成void*类型,因为我的链表可以存放任何类型数据。void*在C语言中是泛型。
- Link结构体是我对链表的封装,每创建一个链表都会有一个Link实例与之对应。在Link中我分别保存了头尾指针和链表的长度。
创建链表
Node* createNode(void* data)
{
Node* node = (Node*)malloc(sizeof(Node));
node->data = data;
node->pre = NULL;
node->next = NULL;
return node;
}
Link* createLink()
{
Link* l = (Link*)malloc(sizeof(Link));
l->head = createNode(NULL);
l->tail = l->head;
l->size = 0;
return l;
}
- createNode函数是创建链表中的一个节点,参数data是这个节点中存放的数据。节点要在堆空间创建。大家看我前面的内容就会知道,堆空间的变量生命周期是自定义的。非常适合保存大量数据。既不会因为栈空间生命周期过短而丢失数据,也不会因为静态空间生命周期过长而浪费内存。每个节点创建出来都会默认把next和pre指针置NULL。野指针是不允许出现的。
- createLink函数是创建一个链表实例,初始时候会有一个无数据的节点作为头节点,head和tail指针都指向这个空头。以后添加新节点的时候会移动tail指针。
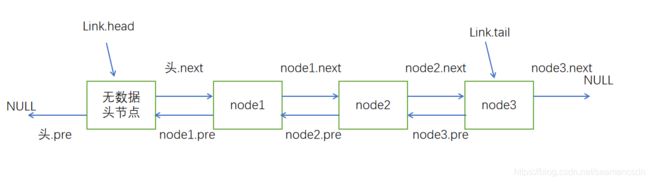
- 上图就是我这个双向链表的结构。另外建议大家在写链表的时候多画图,因为链表的编码需要大量的指针操作,稍微不慎就会指向错误。新手写链表时边写边画是一个好办法。
删除链表
void deleteLink(Link* l)
{
Node* node = l->head;
while(node != NULL)
{
Node* t = node;
node = node->next;
free(t->data);
free(t);
}
free(l);
}
- 删除链表的思路就是遍历每个节点,然后逐个释放。但是有一个问题要注意,一旦节点被释放了,那么指向节点的指针就是野指针。我们不能通过野指针移动到下一个节点。所以函数中定义了指针t用来指向要删除的节点。然后先移动,再删除节点。free(t->data);是释放节点中的数据。free(t);是释放当前节点。两个free缺一不可,避免造成内存泄漏。最后释放整个链表实例。
增
void addNode(Link* l, Node* node)
{
l->tail->next = node;
node->pre = l->tail;
l->tail = node;
l->size++;
}
void addItem(Link* l, void* data)
{
Node* node = createNode(data);
addNode(l, node);
}
- addNode函数是向链表中添加一个新的节点(Node实例),参数1是插入链表的指针,参数2是插入节点的指针。这个插入就是向链表尾部插入。我没有做在任意位置插入节点的函数,大家需要的话可以自己编写。需要注意的是向尾部插入节点后一定要改变tail指针的指向,tail始终指向链表中最后一个节点。这个函数因为使用了Node类型,所以我不会在头文件中声明addNode,不让用户使用这个函数。数据结构的封装一定要隐藏自己的结构信息,不给用户胡乱操作的机会。
- addItem函数是我想让用户使用的函数,因为用户只需要传递链表实例指针和数据指针就可以了。
- 注意:C语言是面向过程的语言,想像面向对象语言那样封装的滴水不漏是不可能的,这里我们尽力而为就好了。
查
void* getItem(Link* l, int index)
{
Node* node = l->head->next;
int i;
for(i = 0;i < index;i++)
{
node = node->next;
}
return node->data;
}
- getItem函数是通过遍历链表的方式来获取指定索引位置的数据。这是链表的天然缺陷,因为链表每个元素在内存中不连续,所以没有办法像数组那样以O(1) 的时间复杂度来获取指定索引位置的元素。
- 现在出现了一个很严重的问题,如果用户使用getItem函数遍历链表的话,效率将是灾难性的。举例子,获得第一个数据需要遍历的节点个数是1,访问第二个时需要遍历的节点个数是2,依次类推。每访问一个元素都会把链表从头遍历一遍,反反复复浪费了很多时间。
- 遍历链表最有效的方式就是使用指针遍历,但是我们为了链表结构的安全性,不允许用户获得链表中指向任何节点的指针。问题似乎卡在了这里。好在我们是站在巨人的肩膀上看问题,这个问题早已被大神破解。
-
迭代器遍历
- 迭代器遍历的思路就是把链表的节点指针再进行一层封装,就是迭代器实例。提供一个函数移动迭代器就可以了。请看下面代码。
typedef struct Iterator
{
Node* node;
}Iterator;
Iterator createIterator(Link* l)
{
Iterator iter;
iter.node = l->head->next;
return iter;
}
int iteratorEnd(Iterator iter)
{
return iter.node==NULL;
}
Iterator nextIterator(Iterator iter)
{
Iterator newIter;
newIter.node = iter.node->next;
return newIter;
}
- 通过这段代码你会发现迭代器的操作就是对指针node的操作,只不过这些操作不让用户直接完成,而是调用我提供的接口函数来完成。这样能保证结构安全。下面写一段代码来测试我们目前的链表性能。
#include
#include "link.h"
int main(void)
{
int arr[10] = {
44,44,8,45,21,5,90,45,5,5};
Link* l = createLink();
int i;
for(i = 0;i < 10;i++)
{
int* data = (int*)malloc(sizeof(int));
*data = arr[i];
addItem(l, data);
}
Iterator iter;
for(iter = createIterator(l);
!iteratorEnd(iter);
iter = nextIterator(iter))
{
int* data = (int*)iteratorData(iter);
printf("%d ", *data);
}
printf("\n");
deleteLink(l);
return 0;
}
- 测试代码中我使用int类型作为数据,这样简单又直观。link.h写我们定义过的结构体和函数的声明。测试逻辑是将数组中的数据分别插入链表,然后使用迭代器遍历链表并打印每个数据。以上就是我们查的部分,也是数据结构中最重要最难写的部分。
改
void updateItem(Iterator iter, void *data)
{
free(iter.node->data);
iter.node->data = data;
}
void updateItemByIndex(Link *l, int index, void *data)
{
Iterator iter = createIterator(l);
int i;
for(i = 0;i < index;i++)
{
iter = nextIterator(iter);
}
updateItem(iter, data);
}
- 修改我给用户提供两个接口函数。updateItem以迭代器修改是用在用户遍历链表的时候随时修改。updateItemByIndex以索引修改是方便用户修改指定的元素。修改要注意的是原来的数据一定要释放,然后Node的data指针指向新的数据。下面是一段测试代码。
#include
#include "link.h"
int main(void)
{
int arr[10] = {
44,44,8,45,21,5,90,45,5,5};
Link* l = createLink();
int i;
for(i = 0;i < 10;i++)
{
int* data = (int*)malloc(sizeof(int));
*data = arr[i];
addItem(l, data);
}
int* data = (int*)malloc(sizeof(int));
*data = 100;
updateItemByIndex(l, 0, data);
Iterator iter;
for(iter = createIterator(l);
!iteratorEnd(iter);
iter = nextIterator(iter))
{
int* data = (int*)iteratorData(iter);
if(*data == 45)
{
int* newData = (int*)malloc(sizeof(int));
*newData = 54;
updateItem(iter, newData);
}
}
for(iter = createIterator(l);
!iteratorEnd(iter);
iter = nextIterator(iter))
{
int* data = (int*)iteratorData(iter);
printf("%d ", *data);
}
printf("\n");
deleteLink(l);
return 0;
}
删
Iterator removeItem(Link* l, Iterator iter)
{
Iterator newIter;
newIter.node = iter.node->next;
iter.node->pre->next = iter.node->next;
if(iter.node->next != NULL)
{
iter.node->next->pre = iter.node->pre;
}
free(iter.node->data);
free(iter.node);
l->size--;
return newIter;
}
void removeItemByIndex(Link* l, int index)
{
Iterator iter = createIterator(l);
int i;
for(i = 0;i < index;i++)
{
iter = nextIterator(iter);
}
removeItem(l, iter);
}
- 删除和修改一样,我提供了两个接口函数。removeItem函数是以迭代器删除,用户在遍历时可以使用这种方式删除。removeItemByIndex函数用户可以删除指定索引的数据。需要注意的点比较多,首先是删除节点需要分别free(iter.node->data)和free(iter.node),链表的长度也要减1。迭代器删除节点后原来的迭代器就成为了野指针,所以在删除后我会返回一个指向删除节点下一个节点的迭代器实例。下面测试代码。
#include
#include "link.h"
int main(void)
{
int arr[10] = {
44,44,8,45,21,5,90,45,5,5};
Link* l = createLink();
int i;
for(i = 0;i < 10;i++)
{
int* data = (int*)malloc(sizeof(int));
*data = arr[i];
addItem(l, data);
}
removeItemByIndex(l, 2);
Iterator iter = createIterator(l);
while(!iteratorEnd(iter))
{
int* data = (int*)iteratorData(iter);
if(*data == 45)
{
iter = removeItem(l, iter);
}
else
{
iter = nextIterator(iter);
}
}
for(iter = createIterator(l);
!iteratorEnd(iter);
iter = nextIterator(iter))
{
int* data = (int*)iteratorData(iter);
printf("%d ", *data);
}
printf("\n");
deleteLink(l);
return 0;
}
- 遍历删除时需要注意的问题是如果删除了元素,那么使用removeItem的返回值就已经实现了迭代器的移动,此时不可以再使用nextIterator移动迭代器,会使得遍历跳项。
排序
- 我们还有最后一个任务就是排序。因为链表不支持像数组一样的随机访问元素,所以链表能使用的排序方法很受限制。既然是因为元素不连续而受限制,那我们让其连续不就可以了吗!这里模仿hash映射的原理将链表的每个元素指针映射到一个数组中,然后对数据进行排序,可以使用任何高效的排序方法。排序完成后再根据数组顺序重组链表即可。下面代码我使用快速排序。
void sortArr(Node** arr, int start, int end, int(*cmp)(void*, void*))
{
if(start >= end)
return;
int left = start;
int right = end;
void* mv = arr[(start+end)/2]->data;
while(left < right)
{
while(left<right && cmp(mv, arr[left]->data)==1)
{
left++;
}
while(left<right && cmp(mv, arr[right]->data)!=1)
{
right--;
}
if(left<right)
{
Node* t = arr[left];
arr[left] = arr[right];
arr[right] = t;
}
}
sortArr(arr, start, left-1, cmp);
sortArr(arr, left+1, end, cmp);
}
void sort(Link* l, int(*cmp)(void*, void*))
{
int size = l->size;
Node** arr = (Node**)malloc(sizeof(Node*)*size);
Node* node = l->head->next;
int i;
for(i = 0;i < size;i++)
{
arr[i] = node;
node = node->next;
}
sortArr(arr, 0, size-1, cmp);
l->tail = l->head;
l->size = 0;
for(i = 0;i < size;i++)
{
addNode(l, arr[i]);
}
l->tail->next = NULL;
free(arr);
}
- 快速排序的算法我不多说。排序首先我在堆空间创建一个和链表等长的数组,数组用来存放每个节点的指针。因为数组元素是指针,所以指向这个数组的指针就得定义成二级指针。关于这个问题可以参考我前面的《针对在校大学生的C语言入门学习——高级语法》。
- 因为我的链表是一个泛型链表,所以我不可能知道用户存放的是什么类型的数据。但是排序就得比较,不知道数据类型怎么比较呢?我的解决方案就是定义函数指针。我只是把排序算法写好,至于数据的比较方法有用户来提供。也就是说用户需要自己写比较的函数,然后传递给我的函数指针参数。请看下面测试代码。
#include
#include "link.h"
int cmp(void* num1, void* num2)
{
int* a = num1;
int* b = num2;
if(*a > *b)
{
return 1;
}
else if(*a < *b)
{
return -1;
}
else
{
return 0;
}
}
int main(void)
{
int arr[10] = {
44,44,8,45,21,5,90,45,5,5};
Link* l = createLink();
int i;
for(i = 0;i < 10;i++)
{
int* data = (int*)malloc(sizeof(int));
*data = arr[i];
addItem(l, data);
}
sort(l, cmp);
Iterator iter;
for(iter = createIterator(l);
!iteratorEnd(iter);
iter = nextIterator(iter))
{
int* data = (int*)iteratorData(iter);
printf("%d ", *data);
}
printf("\n");
deleteLink(l);
return 0;
}
总结
- 链表虽然不难,但其数据结构的本质很考验一个程序员的功力。同学们阅读或者编写链表代码时如果思路不能畅通,一定要边写边画。假以时日便能信手拈来。我的链表就封装到这里,后面的学生管理系统看它大显身手吧!本课源码下载点击。
-