WordCount案例对文本文件所有单词数进行统计
目标:使用mapReduce对文本文件所有单词进行统计
先准备一个hello.txt文件,内容如下
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark fish tom jim
jim hello
在正式编写MapReduce程序之前,先把hdfs集群起来,如果起来后可以访问http://192.168.31.133:9870,如果出现此页面就说明已经起来了
以下为项目整体结构
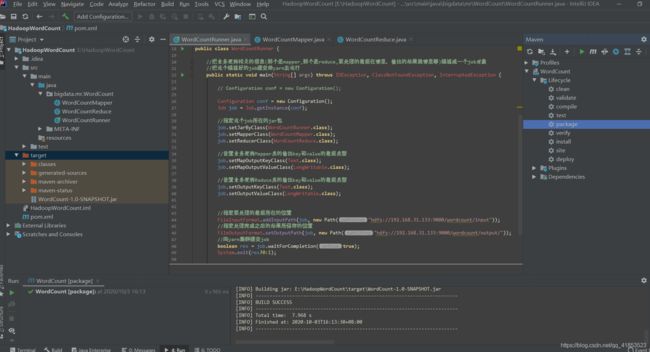
主要有三个java文件,分别是WordCountmapper,WordCountReduce,Driver(WordCountRunner)三部分。
- 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
- Mapper的输入数据是KV对的形式(KV的类型可自定义)
- Mapper的输出数据是KV对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- map()方法(maptask进程)对每一个<K,V>调用一次
- Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer的业务逻辑写在reduce()方法中
- Reducetask进程对每一组相同k的
- 用户自定义的Mapper和Reducer都要继承各自的父类
- 整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
工具使用IDEA 2019.3,maven,hadoop3.2.1
pom.xml文件中导入
org.apache.hadoop
hadoop-hdfs
2.8.3
org.apache.hadoop
hadoop-common
2.8.3
org.apache.hadoop
hadoop-mapreduce-client-core
2.8.3
org.apache.hadoop
hadoop-mapreduce-client-jobclient
2.8.3
接下来编写Mapper文件
package bigdata.mr.WordCount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author yangdz
* @create 2020-10-03 11:53
*/
public class WordCountMapper extends Mapper {
//map()生命周期:框架每传一行数据就会被调用一次
//key:这一行起始点在文件的偏移量
//value:这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行的数据转换成String
String line = value.toString();
//将获取的一行按空格切分成各个单词
String[] words = line.split(" ");
//遍历数组,输出单词<单词,1>
for(String word:words){
context.write(new Text(word),new LongWritable((long)1));
}
}
} 接下来在编写Reducer文件
package bigdata.mr.WordCount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author yangdz
* @create 2020-10-03 12:05
*/
public class WordCountReduce extends Reducer {
//reduce生命周期:mr框架每传递进来一个key组,reduce方法就会被调用一次
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//定义一个计数器
long count =0L;
//遍历这一组kv所有的v,累加到count中
for(LongWritable value:values){
count+=value.get();
}
context.write(key,new LongWritable(count));
}
} 最后编写Driver文件
package bigdata.mr.WordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountRunner {
//把业务逻辑相关的信息(那个是mapper,那个是reduce,要处理的数据在哪里,输出的结果放哪里等)描述成一个job对象
//把这个描述好的job提交给yarn去运行
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指定这个job所在的jar包
job.setJarByClass(WordCountRunner.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//设置业务逻辑Mapper类的输出key和value的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置业务逻辑Reduce类的输出key和value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.31.133:9000/wordcount/input"));
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.31.133:9000/wordcount/output/"));
//向yarn集群提交job
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}接下来就是打包放到服务器上去运行,我是使用maven来打包,先clean下,在进行package,最后生成的jar包在target目录下,使用xftp上传至服务器。


以上为上传上去的jar包(这个jar包可以上传到hdfs集群服务器的任意节点上面)。由于之前有在Driver文件中指定读取和处理完成后的结果存放到hdfs中的文件路径,如果之前没有创建/wordcount/input,需要使用hadoop fs -mkdir -p /wordcount/input来创建文件夹,把最开始的hello.txt文件放到/wordcount/input目录下,

启动命令如下图所示(hadoop jar WordCount-1.0-SNAPSHOT.jar bigdata.mr.WordCount.WordCountRunner /wordcount/input /wordcount/output)hadoop jar里面有我们上传程序中所有需要依赖的jar,WordCountRunner是指定程序运行的主类,/wordcount/input指定hdfs中需要读取文件的path, /wordcount/output是处理后最终结果存放的路径(以上是在137服务器上运行的)

在程序运行期间,流程大概是这样:
- 在启动一个mr程序的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
- maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
- 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
- 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
- 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
- MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
- Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储。
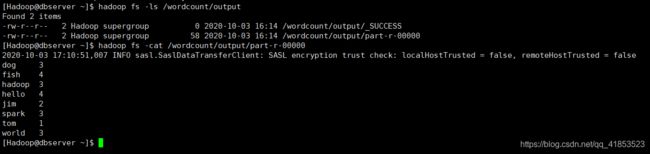
在133服务器上输入以下命令就可以看到最后处理后文件的结果了
当然也可以打开http:192.168.31.133:8088查看执行的任务

