Rasa的官网 项目的github地址:Rasa_wechat 视频讲解(正文+编程+QA):bilibili
本篇文章大量参考基于Rasa_NLU的微信chatbot、另一篇,并融入一些自己的理解和需求,可以结合在一起看。
对话系统==聊天盒子==chatbot (一种是纯聊天型;一种是针对特定商业型)
NLU(Natural Language Understanding,自然语言理解),主要是意图识别+实体识别
DM(Dialogue Management,对话管理),主要是对话状态维护+数据库查询
NLG(Natural Language Generation,自然语言生成),主要是生成交互的自然语言
Rasa是rasa.ai提供的开源工具,支持Python 2和3,可以本地部署,自己针对实际需求训练和调整模型,在商业chatbot设计上应用较多。Rasa既支持英文,又支持中文,甚至支持任何语言,主要包含两大模块:rasa_nlu和rasa_core。
rasa_nlu是负责自然语言理解的,包括意图识别+实体识别;rasa_core是根据得到的意图(intent)和实体(entity)进行语言回复的(即,next_action)。
1.安装Rasa
pip install rasa_core (安装) pip install -U rasa_core (更新)
pip install rasa_nlu[tensorflow] (安装)
2.对话流程的伪代码
input_string="" ##输入
intent_object=intent(input_string) ##意图识别
response=policy(intent_object) ##回复生成
print(response) ##返回用户
3.以一个简单的对话为例:
A:input_string="我饿了"
机器处理过程:intent_object=intent("我饿了") response=policy(intent_object)="你想吃什么?"
机器人:print("你想吃什么?")
准备两种材料,一是NLU自然语言理解模块需要的,二是DM对话管理模块需要的
·训练数据:nlu examples + dialogue stories
·配置文件:nlu config + dialogue domain
3.1)自然语言理解 Rasa_nlu
针对用户的问题,NLU模块的任务是:意图识别+实体识别
意图识别:在句子级别进行分类(类似,文本分类),明确意图;
实体识别:在词级别找出用户问题的关键实体,进行实体槽填充(slot filling)
eg:用户说:“我想吃汉堡”,NLU模块首先识别出用户的意图“寻找餐馆”,其次识别出关键实体“汉堡”。有了意图和关键实体,就方便后面对话管理模块进行后端数据库的查询或是有缺失信息而来继续多轮对话补全或其他缺失的实体槽。【可以理解为,我们要从用户的输入中,提出越多越精确的关键词,将这些关键词们作为我们回答的依据,找到最匹配当前场景,当前状态的话进行回复。 可以扩展用户的信息包括{意图:寻找餐馆,关键实体:汉堡,时间:22:28,地点:北京中关村地铁站,天气:小雨,.......},后台根据这些信息,为用户提供一个恰当的回复。】
对用户输入语句进行理解的NLU工具很多,大多都是以服务的方式提供,如Google的API.ai,Microsoft的Luis.ai,Facebook的Wit.ai等。事实上,申请到这类API的话用几行代码即可完成一个chatbot,亦可参考使用图灵机器人和api.ai相关接口。如果想从零开始动手实现NLU,推荐阅读Do-it-yourself NLP for bot developers。
3.2)Rasa_NLU的一个中文对话系统例子:rasa_nlu_chi
首先需要构建示例,作为意图识别和实体识别的训练数据:放在/data/nlu.json里

实体还可以扩展到多个词, 而且value不一定要是你句子中的词,这样一来,就能将同义词、误拼映射到同一个值上,比如下面这个例子:

Rasa也支持Markdown格式的训练语料
3.3)参考下面链接打一个简单的中文单轮对话模型
https://terrifyzhao.github.io/2018/09/17/Rasa使用指南01.html
3.3.1 安装Rasa
pip install rasa_core
pip install rasa_nlu[tensorflow]
3.3.2搭建stories对话场景
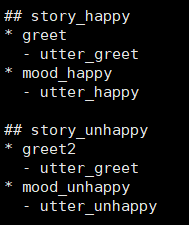
stories可以理解为对话的场景流程,可以告诉机器多轮对话场景下怎么处理,例如:我们希望的流程:用户问好--->机器人问用户今天过得怎么样--->用户反馈情绪--->机器根据不同的情绪进行回复,这里包含两个流程,一个是正面情绪的流程,一个是负面情绪的流程,因此需要写两个story,编写story。
## story标题
* 意图
- 动作
3.3.3搭建domain
domain可以理解为机器的知识库,其中定义:意图、动作、对应动作反馈的内容
intent 意图
action 动作
templates 回答模板
entities 实体
slots 词槽

Rasa Core的任务是在获得用户的意图后,选择正确的action,这些action就定义在domain中以utter_开头的内容,每一个action会根据templates中的情况来返回对应的内容。(注,此例子中没有定义词槽与实体,所以domain中暂时没有。)
3.3.4训练对话模型
下一步就是用神经网络去训练我们的Core模型了,我们可以直接执行以下命令,训练的模型将会存储在models/dialogue文件夹下。
python -m rasa_core.train -d domain.yml -s stories.md -o models/dialogue
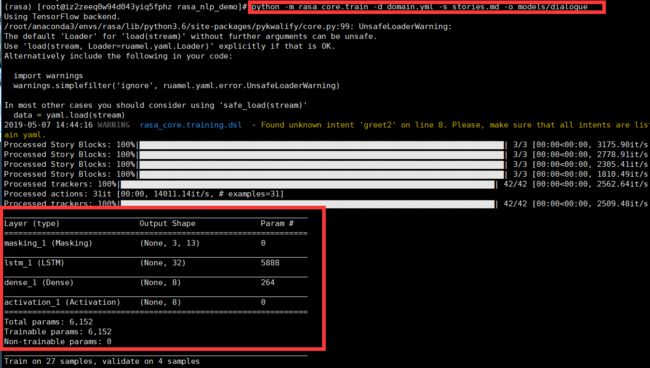
可以看到,训练过程采用了一个神经网络,结构为:masking->lstm->dense->activation,这里简单介绍下masking层,在nlp领域,输入的内容可能不是一样长的,为了能统一处理数据需要定长,因此某些值需要补0或者截取多余内容,但是补0的部分其实是没有意义的,masking层能让这些补0的部分不参与之后的计算,从而提升运算效率。
3.3.5尝试和机器人交流
用训练好的模型来运行我们的机器人,执行以下命令
python -m rasa_core.run -d models/dialogue
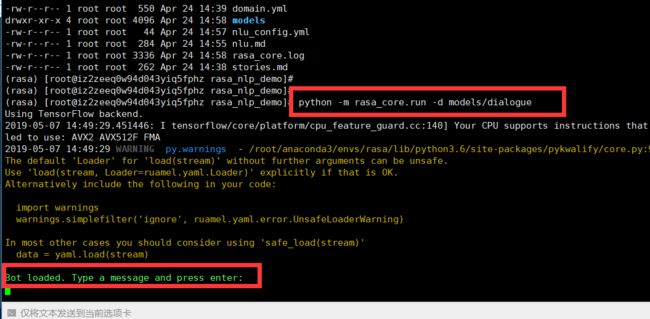

此时我们的机器人还无法判断用户的意图,只能根据输入的意图返回特定的答案,所以我们只能输入一些结构化的数据,例如输入我们之前在domian中定义好的意图,输入的信息需要以 /开头,我们可以直接输入意图 /greet,当然,如果你想让机器人回答更多的内容,请在stories与domain中添加更多的内容。
简单总结:
1]安装rasa 2]搭建stories对话场景,即编写stories.md文件 3]搭建domain,即编写domain.yml文件
4]训练对话模型 python -m rasa_core.train -d domain.yml -s stories.md -o models/dialogue
5]尝试和机器人交流 python -m rasa_core.run -d models/dialogue
以上是一个能够运行的简单模型,未添加意图识别。
3.4)参考下面链接打一个简单的中文单轮对话模型(能够进行意图识别)
https://terrifyzhao.github.io/2018/09/17/Rasa使用指南01.html
3.4.1添加nlu模块,配置nlu.md意图文件
rasa_nlu理解用户句子,输出意图、关键词等
首先定义一个对应的意图可能会出现的文本内容文件nlu.md

3.4.2添加nlu模块,配置nlu_config.yml文件
我们还需要一个nlu的配置文件,nlu_config.yml,由于我们是中文系统,所以language对应的是zh,如果你需要英文的对话请修改为en。

3.4.3训练具有意图识别的模型
准备好之后就可以开始训练NLU模型了,执行以下命令
python -m rasa_nlu.train -c nlu_config.yml --data nlu.md -o models --fixed_model_name nlu --project current --verbose
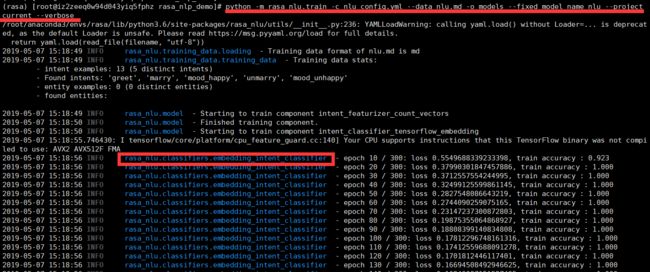
3.4.4尝试和机器人对话
添加完NLU模型之后我们就能让机器识别自然语言了,我们执行下以下命令。
python -m rasa_core.run -d models/dialogue -u models/current/nlu

重要参考资料:
【1】基于Rasa_NLU的微信chatbot
【2】https://terrifyzhao.github.io/2018/09/17/Rasa使用指南01.html