Tags: MachineLearning
[TOC]
EM
EM就是Expectation Maximization,虽然读起来是一个词组,但是实际上是分为Expecation 和 Maximization两个步骤。EM算法是常用的参数隐藏变量(latent variable)估计的算法。
假设表示已观测变量集,表示隐藏变量集,为模型参数。基本思想为:若参数已知,则可根据训练数据推断出最优隐藏变量的值(E);反之,若的值已知,则可方便的对参数做极大似然估计(M)。
EM算法任何隐藏变量模型或者数据增强过程中都有很大的用处。
算法推导
假设服从:, 我们要求z的条件期望:
但我们知道q,那么此时我们可以定义损失函数为 和后验概率之间的-divergence。
上式右边第二项不依赖于q,因此上式可以重写为:
如果定义ELBO:
那么:-devergence
ELBO:

E step:
此时令z真实分布p(z)等于后验概率分布,即KL散度为0:

此时我们有了latent variable的后验概率分布,可以计算出latent variable的期望,新得到的latent variable的期望会在M步骤使用。
M step
此时我们有了在下, z的概率分布,通过最大化来计算新的参数。

算法流程

实例
这里我们先生成二维高斯分布数据,然后人为让一部分数据的y变为0(成为隐藏变量),然后通过整体数据的分布,来推测隐藏变量的分布。
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn as sns
sns.set_style("whitegrid")
sns.set_context("poster")
import pymc3 as pm
def ynew(x, mu1, mu2, s1, s2, rho):
return mu2 + rho*(s2/s1)*(x - mu1)
sig1=1
sig2=0.75
mu1=1.85
mu2=1
rho=0.82
means=np.array([mu1, mu2])
cov = np.array([
[sig1**2, sig1*sig2*rho],
[sig2*sig1*rho, sig2**2]
])
samples=np.random.multivariate_normal(means, cov, size=40)
samples_censored=np.copy(samples)
samples_censored[20:,1]=0
plt.plot(samples[:,0], samples[:,1], 'o', alpha=0.3)
plt.plot(samples_censored[:,0], samples_censored[:,1], 's', alpha=0.8)
mu1 = lambda s: np.mean(s[:,0])
mu2 = lambda s: np.mean(s[:,1])
s1 = lambda s: np.std(s[:,0])
s2 = lambda s: np.std(s[:,1])
rho = lambda s: np.mean((s[:,0] - mu1(s))*(s[:,1] - mu2(s)))/(s1(s)*s2(s))
mu1s=[]
mu2s=[]
s1s=[]
s2s=[]
rhos=[]
mu1s.append(mu1(samples_censored))
mu2s.append(mu2(samples_censored))
s1s.append(s1(samples_censored))
s2s.append(s2(samples_censored))
rhos.append(rho(samples_censored))
newys=ynew(samples_censored[20:,0], mu1s[0], mu2s[0], s1s[0], s2s[0], rhos[0])
for step in range(1,40):
samples_censored[20:,1] = newys
#M-step calculate optimized parameters for the data distribution
mu1s.append(mu1(samples_censored))
mu2s.append(mu2(samples_censored))
s1s.append(s1(samples_censored))
s2s.append(s2(samples_censored))
rhos.append(rho(samples_censored))
#E-step make guession to latent/loss variables
newys=ynew(samples_censored[20:,0], mu1s[step], mu2s[step], s1s[step], s2s[step], rhos[step])
plt.figure()
plt.plot(samples_censored[:,0], samples_censored[:,1], 's', alpha = 0.8)
plt.show()
df=pd.DataFrame.from_dict(dict(mu1=mu1s, mu2=mu2s, s1=s1s, s2=s2s, rho=rhos))
print(df)

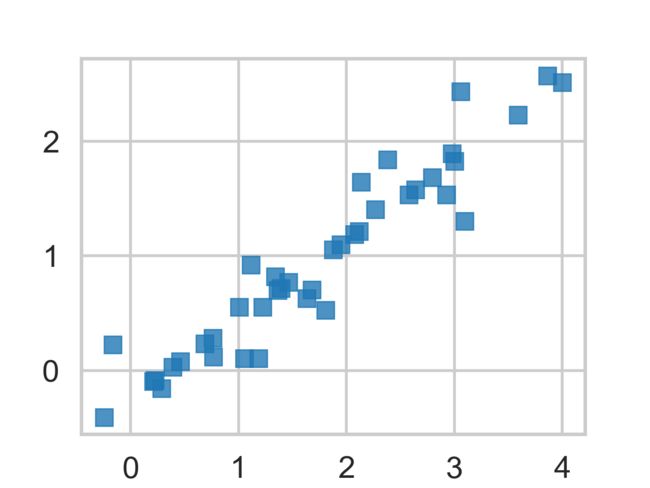
由结果可以看出EM算法较好的模拟的隐藏变量y的数据分布。
VAE
算法推导
训练
VAE和EM算法比较相似,都是生成模型的一种,都是用来解决隐藏变量问题的。
The problem being solved by a VAE is the same as the problem being solved by EM — fitting the parameters of a probability distribution to given data where the model includes latent variables not specified in the data.
对于分类问题,给定样本X,我们希望得到z, 建立模型 , 使得 p(z|X)尽量大,此时我们得到的是判别模型(discriminant model)。和判别相对的是生成模型(generative model),利用贝叶斯公式:
。
比如对于数字生成问题,你可以先随机生成一幅图片y,然后使得P(y|X)尽量大,此时就是判别模式。而我们先按照需要确定y, 然后在p(X|y)空间对X采样,此时得到的图片更加符合我们的预期。
假设我们有隐藏变量, 我们可以根据定义在上的概率函数p(z)对z进行采样,然后有函数, 。determistic函数f可以将随机变量z,映射到X空间。 通过优化参数(从样本中学习)使得映射函数生成的x和数据集中的X尽量相似。

关于p(z)的分布我们可以随机选择,这种方法效率太低,反之我们可以使用z的后验概率p(z|X)分布对z进行采样,此时z是在能够生成X的空间进行采样比随机采样复杂度要小很多。
首先我们使用任意分布q(z)逼近p(z|X), 选择KL散度衡量二者的相似性:
使用贝叶斯公式:
左右整理:
实际上我们的最后生成的q(z)是依赖与X的,因此我们将q(z)替换为q(z|X),上式改写为:
上面这个公式就是VAE中的核心公式
要使尽量小,右侧第一项尽量大,第二项尽量小。其实这里我们得到了和EM算法中相同的目标函数,EM算法中,E部分就是让KL散度为0, M部分就是让尽量大。
左侧其实就是我们需要优化的目标,右侧可以通过SDG进行优化。我们注意到右侧的第一项其实就是一个decoder:分布p将latent variable decode为X,右侧第二项就是一个encoder:分布q将X encode为Z。那么如何对右侧的公式进行优化呢?
通常我们会选择,z的先验p也是高斯分布的,那么,右侧第二项就可以写为:
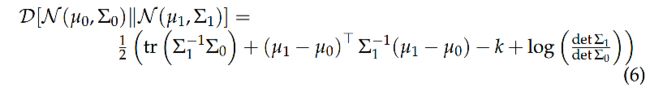
右边第一项, , X的分布依赖于q(z)的分布,如果要估计的值,需要很多的z样。我们可以通过SGD,选一个样本z,然后将P(X|z)作为对的近似。
我们要优化的总公式此时为(为KL散度;):

前面的我们提到要对z采样然后将p(X|z)作为对decoder对的近似,这相当于在模型训练的中间变量z做采样,然而SGD只能处理随机的输入,不能对中间变量进行处理,为了仍然能够使用SGD对model进行训练,VAE采用了一种叫做reparameterization trick的方法,这也是VAE区别与EM的最显著特征。相对于从采样,我们可以先采样 , 然后计算,这样和直接采样得到的分布是一样的,但是可以简化计算:
注意这个时候期望计算公式不会依赖于模型的参数。
测试
测试的时候直接输入,这个时候就没有encoder了。

最后推荐大家去看看这篇文章吧,解释的很清楚,就是要多看几遍, 也有代码实例。
实例
按照上面那篇文章自己实现的结果:

Reference
- https://people.eecs.berkeley.edu/~pabbeel/cs287-fa13/slides/Likelihood_EM_HMM_Kalman.pdf
- https://www.zhihu.com/question/27976634?sort=created
- https://am207.github.io/2017/wiki/EM.html
- https://machinethoughts.wordpress.com/2017/10/02/vae-em/
- https://github.com/cdoersch/vae_tutorial