Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好 适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。去年,在100 TB Daytona GraySort比赛中,Spark战胜了Hadoop,它只使用了十分之一的机器,但运行速度提升了3倍。Spark也已经成为针对 PB 级别数据排序的最快的开源引擎。
Spark支持Scala、Java、Python、R等接口,本文均使用Python环境进行学习。
下载
下载地址:http://spark.apache.org/downloads.html
如下图所示,选择最新版本的Spark,Pre-built版本下载之后可以直接运行,不需要我们再次编译。在不使用集群环境时,我们可以不安装Hadoop环境直接进行运行。选择完成后就可以点击选项4中的链接进行下载。

安装
1.下载的Spark直接解压就完成了安装,Windows 用户如果把Spark 安装到带有空格的路径下,可能会遇到一些问题。所以需要把Spark 安装到不带空格的路径下,比如C:\spark 这样的目录中。
2.Spark由于是使用Scala语言编写,因此需要安装对应版本的JDK包才能正常使用。JDK同样安装到不带空格的路径下。
3.Spark启动时需要根据HADOOP_HOME找到winutils.exe,因此需要下载对应版本的环境。
1.下载winutils的windows版本
由于我们的包是2.7版本,因此下载2.7版本的环境。
2.配置环境变量
增加用户变量HADOOP_HOME,指向文件解压的目录,然后在系统变量path里增加%HADOOP_HOME%\bin 即可。
4.将spark-python文件夹下的pyspark文件夹拷贝到python对应的文件夹中。或者执行以下命令安装:
pip install PySpark
Linux环境的配置类似即可。
测试
在conf 目录下复制log4j.properties.template为log4j.properties ,这个文件用来管理日志设置。接下来找到下面这一行:
log4j.rootCategory=INFO, console
然后通过下面的设定降低日志级别,只显示警告及更严重的信息:
log4j.rootCategory=WARN, console
在spark-bin文件夹下执行pyspark命令就可以进入pyspark-shell环境。也可以为Spark设置环境变量,同以上Hadoop环境的操作。
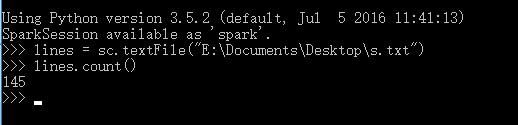
在shell中执行下列代码测试,计算文件行数:
lines = sc.textFile("E:\Documents\Desktop\s.txt")
lines.count()
测试独立应用连接spark,将下列代码保存在demo.py,执行spark-submit demo.py,命令。
# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 连接集群local,本应用名称为Demo
conf = SparkConf().setMaster('local').setAppName('Demo')
sc = SparkContext(conf=conf)
# 统计文件中包含mape的行数,并打印第一行
lines = sc.textFile("E:\Documents\Desktop\s.txt")
plines = lines.filter(lambda lines: 'mape' in lines)
print(plines.count())
print(plines.first())
sc.stop
在Spark2.0中只要创建一个SparkSession就够了,SparkConf、SparkContext和SQLContext都已经被封装在SparkSession当中,因此代码也可以写成如下:
from pyspark.sql import SparkSession
# 连接集群local,本应用名称为Demo
sc = SparkSession.builder.master("local").appName(Demo").config("spark.some.config.option", "some-value").getOrCreate()
向spark提交的运行结果如图所示:

异常处理
在windows下进行安装调试Spark时出现了多种异常状况,就我遇到的异常状况进行一下总结。
Hadoop winutils不存在异常
最开始没有配置winutils环境导致的异常,异常关键提示为:
Failed to locate the winutils binary in the hadoop binary path
F:\spark-2.2.0\bin>pyspark
Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
17/10/25 16:13:59 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)
at org.apache.hadoop.util.Shell.(Shell.java:387)
at org.apache.hadoop.hive.conf.HiveConf$ConfVars.findHadoopBinary(HiveConf.java:2327)
at org.apache.hadoop.hive.conf.HiveConf$ConfVars.(HiveConf.java:365)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:105)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at py4j.reflection.CurrentThreadClassLoadingStrategy.classForName(CurrentThreadClassLoadingStrategy.java:40)
at py4j.reflection.ReflectionUtil.classForName(ReflectionUtil.java:51)
at py4j.reflection.TypeUtil.forName(TypeUtil.java:243)
at py4j.commands.ReflectionCommand.getUnknownMember(ReflectionCommand.java:175)
at py4j.commands.ReflectionCommand.execute(ReflectionCommand.java:87)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:748)
17/10/25 16:14:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hadoop winutils版本异常
最开始下载的winutils版本是Hadoop 2.0版本,不符合Spark编译的2.7版本,因此出现了代码异常,更换版本后正常。关键异常提示为:
Caused by: org.apache.spark.sql.AnalysisException: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V;
pyspark.sql.utils.IllegalArgumentException: "Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':"
F:\spark-2.2.0\bin>pyspark
Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Traceback (most recent call last):
File "F:\spark-2.2.0\python\pyspark\sql\utils.py", line 63, in deco
return f(*a, **kw)
File "F:\spark-2.2.0\python\lib\py4j-0.10.4-src.zip\py4j\protocol.py", line 319, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o23.sessionState.
: java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1053)
at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)
at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession.sessionState$lzycompute(SparkSession.scala:129)
at org.apache.spark.sql.SparkSession.sessionState(SparkSession.scala:126)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:280)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.sql.AnalysisException: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:193)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:105)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:93)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:35)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:289)
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1050)
... 16 more
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
at org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode(NativeIO.java:524)
at org.apache.hadoop.fs.RawLocalFileSystem.mkOneDirWithMode(RawLocalFileSystem.java:478)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirsWithOptionalPermission(RawLocalFileSystem.java:532)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:305)
at org.apache.hadoop.hive.ql.exec.Utilities.createDirsWithPermission(Utilities.java:3679)
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:597)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:554)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)
at org.apache.spark.sql.hive.client.HiveClientImpl.(HiveClientImpl.scala:191)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:264)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:362)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:266)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
... 25 more
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "F:\spark-2.2.0\bin\..\python\pyspark\shell.py", line 45, in
spark = SparkSession.builder\
File "F:\spark-2.2.0\python\pyspark\sql\session.py", line 179, in getOrCreate
session._jsparkSession.sessionState().conf().setConfString(key, value)
File "F:\spark-2.2.0\python\lib\py4j-0.10.4-src.zip\py4j\java_gateway.py", line 1133, in __call__
File "F:\spark-2.2.0\python\pyspark\sql\utils.py", line 79, in deco
raise IllegalArgumentException(s.split(': ', 1)[1], stackTrace)
pyspark.sql.utils.IllegalArgumentException: "Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':"
访问权限权限异常
由于windows与Linux权限的区别,在windows启动Spark时需要在tmp文件夹由于权限问题,无法写入导致的异常。使用管理员权限启动cmd,并且提前使在对应盘根目录下创建tmp文件夹,问题解决。关键异常提示:
Caused by: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: ---------
F:\spark-2.2.0\bin>pyspark
Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Traceback (most recent call last):
File "F:\spark-2.2.0\python\pyspark\sql\utils.py", line 63, in deco
return f(*a, **kw)
File "F:\spark-2.2.0\python\lib\py4j-0.10.4-src.zip\py4j\protocol.py", line 319, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o23.sessionState.
: java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1053)
at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)
at org.apache.spark.sql.SparkSession$$anonfun$sessionState$2.apply(SparkSession.scala:130)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession.sessionState$lzycompute(SparkSession.scala:129)
at org.apache.spark.sql.SparkSession.sessionState(SparkSession.scala:126)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:280)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: ---------;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:193)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:105)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:93)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:35)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:289)
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1050)
... 16 more
Caused by: java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: ---------
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.spark.sql.hive.client.HiveClientImpl.(HiveClientImpl.scala:191)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:264)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:362)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:266)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
... 25 more
Caused by: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: ---------
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:612)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:554)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)
... 39 more
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "F:\spark-2.2.0\bin\..\python\pyspark\shell.py", line 45, in
spark = SparkSession.builder\
File "F:\spark-2.2.0\python\pyspark\sql\session.py", line 179, in getOrCreate
session._jsparkSession.sessionState().conf().setConfString(key, value)
File "F:\spark-2.2.0\python\lib\py4j-0.10.4-src.zip\py4j\java_gateway.py", line 1133, in __call__
File "F:\spark-2.2.0\python\pyspark\sql\utils.py", line 79, in deco
raise IllegalArgumentException(s.split(': ', 1)[1], stackTrace)
pyspark.sql.utils.IllegalArgumentException: "Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':"