AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)
1. 前言
随着信息技术和互联网的发展, 我们已经步入了一个信息过载的时代,这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战:
- 信息消费者:如何从大量的信息中找到自己感兴趣的信息?
- 信息生产者:如何让自己生产的信息脱颖而出, 受到广大用户的关注?
为了解决这个矛盾, 推荐系统应时而生, 并飞速前进,在用户和信息之间架起了一道桥梁,一方面帮助用户发现对自己有价值的信息, 一方面让信息能够展现在对它感兴趣的用户前面。 推荐系统近几年有了深度学习的助推发展之势迅猛, 从前深度学习的传统推荐模型(协同过滤,矩阵分解,LR, FM, FFM, GBDT)到深度学习的浪潮之巅(DNN, Deep Crossing, DIN, DIEN, Wide&Deep, Deep&Cross, DeepFM, AFM, NFM, PNN, FNN, DRN), 现在正无时无刻不影响着大众的生活。
推荐系统通过分析用户的历史行为给用户的兴趣建模, 从而主动给用户推荐给能够满足他们兴趣和需求的信息, 能够真正的“懂你”。 想上网购物的时候, 推荐系统在帮我们挑选商品, 想看资讯的时候, 推荐系统为我们准备了感兴趣的新闻, 想学习充电的时候, 推荐系统为我们提供最合适的课程, 想消遣放松的时候, 推荐系统为我们奉上欲罢不能的短视频…, 所以当我们淹没在信息的海洋时, 推荐系统正在拨开一层层波浪, 为我们追寻多姿多彩的生活!
这段时间刚好开始学习推荐系统, 通过王喆老师的《深度学习推荐系统》已经梳理好了知识体系, 了解了当前推荐系统领域各种主流的模型架构和技术。 所以接下来的时间就开始对这棵大树开枝散叶,对每一块知识点进行学习总结。 所以接下来一块目睹推荐系统的风采吧!
这次整理重点放在推荐系统的模型方面, 前面已经把传统的推荐模型梳理完毕, 下面正式进入深度学习的浪潮之巅。在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推挤系统和计算广告领域全面进入了深度学习时代, 时至今日, 依然是主流。 在进入深度学习时代, 推荐模型主要有下面两个进展:
- 与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
- 深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
所以, 后面开始尝试整理深度学习推荐模型,它们以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化,它们的演化关系依然拿书上的一张图片, 便于梳理关系脉络, 对知识有个宏观的把握:
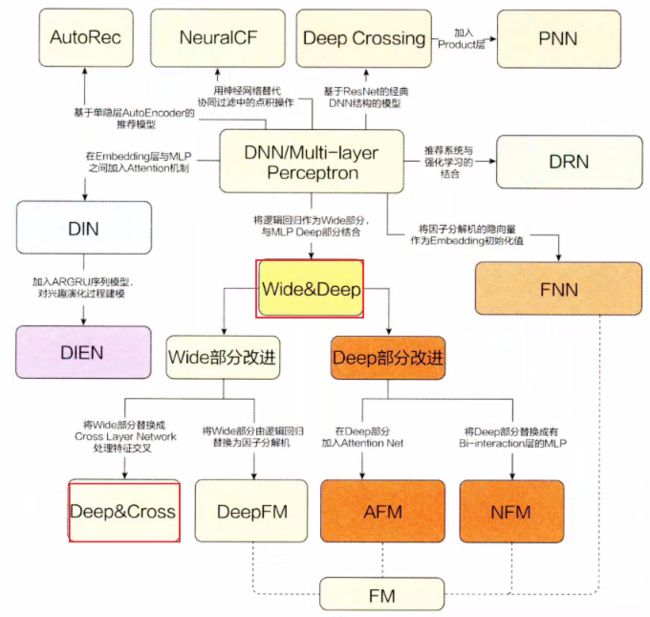
今天是深度学习模型整理的第三篇, 整理在组合的角度完成进阶的两个模型Wide&Deep和Deep&Cross模型, 从上面图里面也会看到Wide&Deep的重要性, 是处于一个核心的地位, 后面的很多深度学习模型都是基于此模型的架构进行的改进。 所以该模型的提出在业界是有非常大的影响力的。 而Deep&Cross是W&D的一个进阶版本, 用一个Cross网络替换了Wide部分, 使得自动进行特征交互成为了可能, 所以借着整理W&D的机会就一块整理了这个进阶版本的模型, 一块来学习学习这哥俩。
这篇文章的主角就是W&D和D&C, 首先会从W&D开始, 介绍该模型提出的动机以及记忆和泛化能力, 然后介绍该模型的结构原理以及原论文中的一些细节, 之后就是pytorch复现该模型在cretio数据集上完成推荐任务。 关于D&C模型, 也是同样的思路, 因为这个模型是在W&D的基础上改进的W部分, 所以有了前面的基础这个模型介绍起来会非常简单, 这次主要是介绍改进的Cross部分的原理和模型结构, 最后pytorch复现该模型在上面的数据集上也玩一下, 对比一下这俩模型的效果。这篇文章虽然也是两个模型, 但是运算并不是太复杂, 思路也很清晰, 效果也很突出, 也是非常适合入门的模型, 人家的这种思想咱得了解一下。
大纲如下:
- Wide&Deep模型的动机(why 会有这样的一个组合思路)
- Wide&Deep模型的结构原理和论文中的一些细节
- Wide&Deep模型的pytorch实现
- Deep&Cross模型的结构原理
- Deep&Cross模型的pytorch实现
- 总结
Ok, let’s go!
2. Wide&Deep模型的提出动机
2.1 聊聊背景
在CTR预估任务中,线性模型仍占有半壁江山。利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:首先,特征工程需要耗费太多精力。其次,因为模型是强行记住这些组合特征的,所以对于未曾出现过的特征组合,权重系数为0,无法进行泛化。

为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,现实世界是没有银弹的。基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。关于这一点, 我感觉作者在论文中说的很好且形象:

简单解释一下就是embedding的这种思路, 如果碰到了共现矩阵高度稀疏且高秩(比如user有特殊的爱好, 或者item比较小众), ,很难非常效率的学习出低维度的表示。这种情况下,大部分的query-item都没有什么关系。但是dense embedding会导致几乎所有的query-item预测值都是非0的,这就导致了推荐过度泛化,会推荐一些不那么相关的物品。相反,简单的linear model却可以通过cross-product transformation来记住这些exception rules。
所以根据上面的分析, 我们发现简单的模型, 比如协同过滤, 逻辑回归等,能够从历史数据中学习到高频共现的特征组合能力, 但是泛化能力不足;而像矩阵分解, embedding再加上深度学习网络, 能够利用相关性的传递性去探索历史数据中未出现的特征组合, 挖掘数据潜在的关联模式, 但是对于某些特定的场景(数据分布长尾, 共现矩阵稀疏高秩)很难有效学习低纬度的表示, 造成推荐的过渡泛化。 既然这两种模型的优缺点都这么的互补, 为啥不组合一下子他俩呢?
2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式, 奠定了后面深度学习模型的基础。 这个是一个里程碑式的改变, 但仔细看看人家的模型架构, 会发现并没有多复杂, 甚至比之前的PNN, Neural CF等都简单。但是人家的这种思想却是有着重大意义的。 后面我们会具体学习这个结构, 但是在这之前, 想借着王喆老师书上的例子聊聊“Memorization"和”Generalization"。
2.2 记忆能力和泛化能力
"记忆能力"可以被理解为模型直接学习并利用历史数据中物品和特征的“共现频率”的能力。 一般来说, 协同过滤、逻辑回归这种都具有较强的“记忆能力”, 由于这类模型比较简单, 原始数据往往可以直接影响推荐结果, 产生类似于“如果点击A, 就推荐B”这类规则的推荐, 相当于模型直接记住了历史数据的分布特点, 并利用这些记忆进行推荐。
以谷歌APP推荐场景为例理解一下:
假设在Google Play推荐模型训练过程中, 设置如下组合特征: AND(user_installed_app=netflix, impression_app=pandora), 它代表了用户安装了netflix这款应用, 而且曾在应用商店中看到过pandora这款应用。 如果以“最终是否安装pandora”为标签,可以轻而易举的统计netfilx&pandora这个特征与安装pandora标签之间的共现频率。 比如二者的共现频率高达10%, 那么在设计模型的时候, 就希望模型只要发现这一特征,就推荐pandora这款应用(像一个深刻记忆点一样印在脑海), 这就是所谓的“记忆能力”。 像逻辑回归这样的模型, 发现这样的强特, 就会加大权重, 对这种特征直接记忆。
但是对于神经网络这样的模型来说, 特征会被多层处理, 不断与其他特征进行交叉, 因此模型这个强特记忆反而没有简单模型的深刻。
"泛化能力“可以被理解为模型传递特征的相关性, 以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。比如矩阵分解, embedding等, 使得数据稀少的用户或者物品也能生成隐向量, 从而获得由数据支撑的推荐得分, 将全局数据传递到了稀疏物品上, 提高泛化能力。再比如神经网络, 通过特征自动组合, 可以深度发掘数据中的潜在模式,提高泛化等。

所以, Wide&Deep模型的直接动机就是将两者进行融合, 使得模型既有了简单模型的这种“记忆能力”, 也有了神经网络的这种“泛化能力”, 这也是记忆与泛化结合的伟大模式的初始尝试。下面就来具体看一下W&D模型的结构。
3. Wide&Deep模型的结构原理和论文中的一些细节
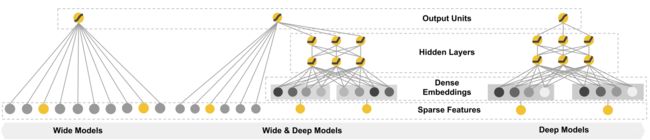
经典的W&D的模型如下面中间的图所示(左边的是wide部分, 也就是一个简单的线性模型, 右边是deep部分, 一个经典的DNN模型)

W&D模型把单输入层的Wide部分和Embedding+多层的全连接的部分连接起来, 一起输入最终的输出层得到预测结果。 单层的wide层善于处理大量的稀疏的id类特征, Deep部分利用深层的特征交叉, 挖掘在特征背后的数据模式。 最终, 利用逻辑回归, 输出层部分和Deep组合起来, 形成统一的模型。
3.1 Wide部分
Wide部分是一个广义的线性模型, 公式如下:
y = W T X + b y=W^TX+b y=WTX+b
输入的 X = [ x 1 , x 2 , . . x d ] X=[x_1, x_2, ..x_d] X=[x1,x2,..xd]包括原始特征和转换的特征, 还有一些离散的id类特征给它(神经网络那边是不喜欢这种高稀疏的离散id特征的, 巧了,wide这边喜欢)。 其中一种比较重要的转换操作就是cross-product transformation(原始特征的交互特征),公式如下:
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ { 0 , 1 } \phi_{k}(\mathbf{x})=\prod_{i=1}^{d} x_{i}^{c_{k i}} \quad c_{k i} \in\{0,1\} ϕk(x)=i=1∏dxickicki∈{ 0,1}
如果两个特征同时为1的时候, 这个特征就是1, 否则就是0, 这是一种特征组合, 往往我们在特征工程的时候常常会做一些这种特征。 比如
And(gender=female, language=en)=1, 当且仅当gender=female, language=en的时候, 否则就是0.
作者说:

对于wide部分训练时候使用的优化器是带正则的FTRL算法(Follow-the-regularized-leader),我们可以把FTRL当作一个稀疏性很好,精度又不错的随机梯度下降方法, 该算法是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。 例如, Google W&D期望wide部分发现这样的规则:用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。 所以对于稀疏性的规则的考量, 和具体的业务场景有关。同样, 这部分的输入特征也是有讲究的, 后面会看谷歌的那个例子。
这里再补充一点上面wide部分使用FTRL算法的原因, 也就是为啥这边要注重模型稀疏性质的原因, 上面的压缩模型权重,减少服务的时候存储压力是其一, 还有一个是来自工业上的经验, 就是对模型的实时更新更加有利, 能够在实时更新的时候, 尽量的加大实时的那部分数据对于参数更新的响应速度,不至于用实时数据更新好久也没有更新动原来的大模型。毕竟它注重稀疏性质,一旦察觉到新来的这部分数据某些特征变了, 就立即加大权重或者直接置为0, 这样就能只记住实时数据的关键特征了, 使得模型能够更好的实时服务。 deep端的这种普通梯度下降的方式是不行的,这种都是一般使用类似L2正则的方式, 更新参数的时候尽量的慢慢减小所有的w参数, 更新起来是会很慢的, 不太能反应实时变化。 像FTRL这种, 用的类似于L1正则的方式, 这俩的区别是显然的了。
3.2 Deep部分
该部分主要是一个Embedding+MLP的神经网络模型。大规模稀疏特征通过embedding转化为低维密集型特征。然后特征进行拼接输入到MLP中,挖掘藏在特征背后的数据模式。
a ( l + 1 ) = f ( W l a ( l ) + b l ) \boldsymbol{a}^{(l+1)}=f\left(W^{l} a^{(l)}+\boldsymbol{b}^{l}\right) a(l+1)=f(Wla(l)+bl)
输入的特征有两类, 一类是数值型特征, 一类是类别型特征(会经embedding)。我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。 对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
3.3 Wide & Deep
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:
P ( Y = 1 ∣ x ) = σ ( w w i d e T [ x , ϕ ( x ) ] + w d e e p T a ( l f ) + b ) P(Y=1 \mid \mathbf{x})=\sigma\left(\mathbf{w}_{w i d e}^{T}[\mathbf{x}, \phi(\mathbf{x})]+\mathbf{w}_{d e e p}^{T} a^{\left(l_{f}\right)}+b\right) P(Y=1∣x)=σ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)
作者这里还说了一个joint training的细节, joint training和ensemble还是有区别的:

3.4 谷歌的推荐系统
wide&deep模型本身的结构非常简单的,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分是用好该模型的一个前提, 我们有必要了解一下这个模型到底应该怎么使用, 从谷歌的推荐系统中看看这个模型的使用:
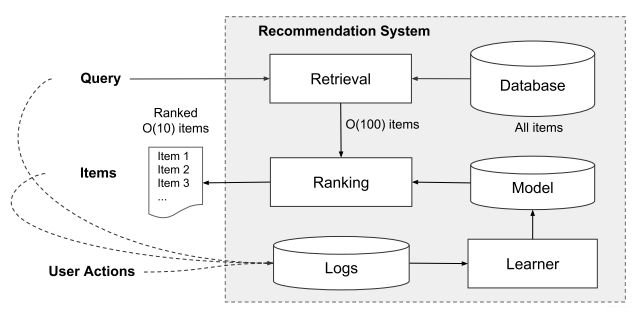
这个就是Google Play推荐系统的结构, 与一般的推荐系统不同的是,Google Pay是通过检索来实现推荐的召回,将大规模的App应用缩小到小规模(例如100)的相关应用。然后在通过用户特征、上下文特征、用户行为特征等来建立推荐模型,估计用户点击每个App的概率分数,按照分数进行排序,推荐Top K个App。具体的Wide&Deep模型如下:

我们重点看看这两部分的输入特征:
- Deep部分: 全量的特征向量, 包括用户年龄(age), 已安装应用数量(#app installs), 设备类型(device class), 已安装应用(installed app), 曝光应用impression app)等特征。 其中, 已安装应用, 曝光应用等类别型特征, 需要经过embedding层输入连接层, 而数值型的特征和前面的特征拼接起来直接输入连接层, 经过3层的Relu全连接层。
- Wide部分:输入仅仅是已安装应用和曝光应用两类特征。 其中已安装应用代表用户的历史行为, 而曝光应用代表当前待推荐应用。 选择这两部分是想发现当前曝光APP和用户已安装APP之间的关联关系, 以充分发挥Wide的记忆能力, 影响最终的得分。 这部分是L1正则化的FTRL优化器, 可能是因为这两个id类特征向量组合, 在维度爆炸的同时, 会让原本已经非常稀疏的multihot特征向量变得更加稀疏。 因此采用FTRL过滤掉那些稀疏特征是非常好的工程经验。
- 两者结合: 最后将两部分的特征再进行一个拼接, 输出到logistics Loss层进行输出。
这个就是W&D模型的全貌了, 该模型开创了组合模型的构造方法, 对深度学习推荐模型的发展产生了重大的影响。 下面就用pytorch搭建一个Wide&Deep模型, 完成一个电子商品推荐的任务。
这是工业上常用的一个模型, 下面整理一些工业上使用的经验:
- 像上面说的,这个模型的wide和deep端接收的特征是不一样的, wide端一般会接收一些重要的交互特征,高维的稀疏离散特征, 而deep端接收的是一些连续特征
- 这两端用的梯度下降的方式不一样, wide段用的是那种带有L1正则的那种方式,L1有特征选择的作用, 注重稀疏性些, deep端用的就是普通的梯度下降方式,带L2正则
- wide部分是直接与输出连着的, 这个其实和ResNet的那种原理有点像, 知识在某种程度上都是想通的。
- wide & deep是一种架构,不是说一定非得是这样的形式, 具体要跟着具体业务来, 还得进行扩展,比如某些特征,既不适合wide也不适合deep,而是适合FM,那就把这部分特征过一个FM, 和wide deep端的输出拼起来得到最后的输出,其实是可以任意改造的。
4. Wide&Deep模型的pytorch实现
该模型的结构不是多么复杂,所以实现起来也比较简单, 看它的架构图就会发现, 主要包括Deep和Wide两个部分,
所以搭建该网络的时候,就可以分别搭建完Deep和Wide部分之后, 把这两块拼接起来, 具体的代码如下:
class Linear(nn.Module):
"""
Linear part
"""
def __init__(self, input_dim):
super(Linear, self).__init__()
self.linear = nn.Linear(in_features=input_dim, out_features=1)
def forward(self, x):
return self.linear(x)
class Dnn(nn.Module):
"""
Dnn part
"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout: 失活率
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
最后搭建WideDeep模型, 最后的输出部分可以对Wide和Deep的输出加上一个权重得到最后的输出。
class WideDeep(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
super(WideDeep, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0, len(self.dense_feature_cols) + len(self.sparse_feature_cols)*self.sparse_feature_cols[0]['embed_dim'])
self.dnn_network = Dnn(hidden_units)
self.linear = Linear(len(self.dense_feature_cols))
self.final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
dnn_input = torch.cat([sparse_embeds, dense_input], axis=-1)
# Wide
wide_out = self.linear(dense_input)
# Deep
deep_out = self.dnn_network(dnn_input)
deep_out = self.final_linear(deep_out)
# out
outputs = F.sigmoid(0.5 * (wide_out + deep_out))
return outputs
这就是W&D模型了, 思想比较重要,模型搭建起来相对简单,但是具体使用的时候一定要根据具体的业务场景来,代码可以参考后面给出的GitHub链接, 数据集选用的cretio数据集的一小部分,只是搭建了一下模型进行了测试, 在wide和deep的输入上并没有很严格的区分,并且由于数据集太小,虽然网络在正常工作, 但是很快就过拟合了。效果并不是太好。 所以具体使用的时候一定要注意。
5. Deep&Cross模型的结构原理
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分, 其中比较典型的就是2017年斯坦福大学和谷歌的研究人员在ADKDD会议上提出的Deep&Cross模型, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。

下面就来看一下DCN的结构:模型的结构非常简洁,从下往上依次为:Embedding和Stacking层、Cross网络层与Deep网络层并列、输出合并层,得到最终的预测结果。
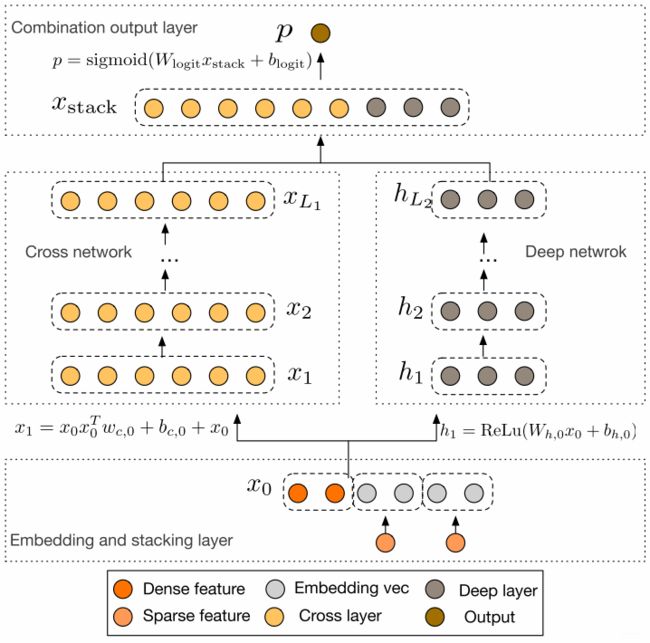
5.1 Embedding and stacking layer
Embedding层我们已经非常的熟悉了吧, 这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
x embed, i = W embed, i x i \mathbf{x}_{\text {embed, } i}=W_{\text {embed, } i} \mathbf{x}_{i} xembed, i=Wembed, ixi
其中对于某一类稀疏分类特征(如id), X e m b e d , i X_{embed, i} Xembed,i是第个 i i i分类值(id序号)的embedding向量。 W e m b e d , i W_{embed,i} Wembed,i是embedding矩阵, n e × n v n_e\times n_v ne×nv维度, n e n_e ne是embedding维度, n v n_v nv是该类特征的唯一取值个数。 x i x_i xi属于该特征的二元稀疏向量(one-hot)编码的。 【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量】。其实绝大多数基于深度学习的推荐模型都需要Embedding操作,参数学习是通过神经网络进行训练。
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking):
x 0 = [ x embed, 1 T , … , x embed, , k T , x dense T ] \mathbf{x}_{0}=\left[\mathbf{x}_{\text {embed, } 1}^{T}, \ldots, \mathbf{x}_{\text {embed, }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right] x0=[xembed, 1T,…,xembed, ,kT,xdense T]
一共 k k k个类别特征, dense是数值型特征, 两者在特征维度拼在一块。 这个操作在Deep Crossing中也有具体的实现, stacking操作也非常的常见。
5.2 Cross Network
这个就是本文最大的创新点—Cross网络了, 设计该网络的目的是增加特征之间的交互力度。 交叉网络由多个交叉层组成, 假设 l l l层的输出向量 x l x_l xl, 那么对于第 l + 1 l+1 l+1层的输出向量 x l + 1 x_{l+1} xl+1表示为:
x l + 1 = x 0 x l T w l + b l + x l = f ( x l , w l , b l ) + x l \mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l} xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
可以看到, 交叉层的操作的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量 w l w_l wl, 以及原输入向量 x l x_l xl和偏置向量 b l b_l bl。 交叉层的可视化如下:

可以看到, 每一层增加了一个 n n n维的权重向量 w l w_l wl(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。 关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂, 下面拿子耀总结的一个例子来分析一下, 具体的参考下面给出的第四篇链接。
举例: x 0 = [ x 0 1 , x 0 2 ] T , b i = 0 x_0=[x_0^1, x_0^2]^T, b_i=0 x0=[x01,x02]T,bi=0, 则
x 1 = x 0 ∗ x 0 T ∗ w 0 + x 0 = [ x 0 1 , x 0 2 ] T ∗ [ x 0 1 , x 0 2 ] ∗ [ w 0 1 , w 0 2 ] + [ x 0 1 , x 0 2 ] T = [ w 0 1 ( x 0 1 ) 2 + w 0 2 x 0 1 x 0 2 + x 0 1 , w 0 1 x 0 1 x 0 2 + w 0 2 ( x 0 2 ) 2 + x 0 2 ] T \begin{aligned} \mathbf{x}_{1} &=\mathbf{x}_{0} *\mathbf{x}_{0}^{T} * \mathbf{w}_{0}+\mathbf{x}_{0} \\ &=\left[x_{0}^{1}, x_{0}^{2}\right]^{T} *\left[x_{0}^{1}, x_{0}^{2}\right] *\left[w_{0}^{1}, w_{0}^{2}\right]+\left[x_{0}^{1}, x_{0}^{2}\right]^{T} \\ &=\left[w_{0}^{1}\left(x_{0}^{1}\right)^{2}+w_{0}^{2} x_{0}^{1} x_{0}^{2}+x_{0}^{1}, w_{0}^{1} x_{0}^{1} x_{0}^{2}+w_{0}^{2}\left(x_{0}^{2}\right)^{2}+x_{0}^{2}\right]^{T} \end{aligned} x1=x0∗x0T∗w0+x0=[x01,x02]T∗[x01,x02]∗[w01,w02]+[x01,x02]T=[w01(x01)2+w02x01x02+x01,w01x01x02+w02(x02)2+x02]T
再算一步:
x 2 = x 0 ∗ x 1 T ∗ w 1 + x 1 = [ w 1 1 x 0 1 x 1 1 + w 1 2 x 0 1 x 1 2 + x 1 1 w 1 1 x 0 2 x 1 1 + w 1 2 x 0 2 x 1 2 + x 1 2 ] T = [ w 1 1 x 0 1 ( w 0 1 ( x 0 1 ) 2 + w 0 2 x 0 1 x 0 2 + x 0 1 ) + w 1 2 x 0 1 ( w 0 1 x 0 1 x 0 3 + w 0 2 ( x 0 2 ) 2 + x 0 2 ) + w 0 1 ( x 0 1 ) 2 + w n 2 x n 1 x 0 2 + x 0 1 , … . . . ] T \begin{aligned} \mathrm{x}_{2} &=\mathrm{x}_{0} * \mathrm{x}_{1}^{T} * \mathrm{w}_{1}+\mathrm{x}_{1} \\ &=\left[w_{1}^{1} x_{0}^{1} x_{1}^{1}+w_{1}^{2} x_{0}^{1} x_{1}^{2}+x_{1}^{1} w_{1}^{1} x_{0}^{2} x_{1}^{1}+w_{1}^{2} x_{0}^{2} x_{1}^{2}+x_{1}^{2}\right]^{T} \\ &= [w_1^1x_0^1(w_0^1(x_0^1)^2+ \left.\left.w_{0}^{2} x_{0}^{1} x_{0}^{2}+x_{0}^{1}\right)+w_{1}^{2} x_{0}^{1}\left(w_{0}^{1} x_{0}^{1} x_{0}^{3}+w_{0}^{2}\left(x_{0}^{2}\right)^{2}+x_{0}^{2}\right)+w_{0}^{1}\left(x_{0}^{1}\right)^{2}+w_{n}^{2} x_{n}^{1} x_{0}^{2}+x_{0}^{1}, \ldots . . .\right]^{T} \end{aligned} x2=x0∗x1T∗w1+x1=[w11x01x11+w12x01x12+x11w11x02x11+w12x02x12+x12]T=[w11x01(w01(x01)2+w02x01x02+x01)+w12x01(w01x01x03+w02(x02)2+x02)+w01(x01)2+wn2xn1x02+x01,…...]T
这里会发现, 每一层的w和b是共享的。
这个如果不明显,写成下面这种格式:
l l l =0: x 1 = x 0 x 0 T w 0 + b 0 + x 0 \mathbf{x}_{1} =\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0} x1=x0x0Tw0+b0+x0
l = 1 : x 2 = x 0 x 1 T w 1 + b 1 + x 1 = x 0 [ x 0 x 0 T w 0 + b 0 + x 0 ] T w 1 + b 1 + x 1 l=1:\mathbf{x}_{2} =\mathbf{x}_{0} \mathbf{x}_{1}^{T} \mathbf{w}_{1}+ \mathbf{b}_{1}+\mathbf{x}_{1}=\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1} l=1:x2=x0x1Tw1+b1+x1=x0[x0x0Tw0+b0+x0]Tw1+b1+x1
l = 2 : x 3 = x 0 x 2 T w 2 + b 2 + x 2 = x 0 [ x 0 [ x 0 x 0 T w 0 + b 0 + x 0 ] T w 1 + b 1 + x 1 ] T w 2 + b 2 + x 2 l=2:\mathbf{x}_{3} =\mathbf{x}_{0} \mathbf{x}_{2}^{T} \mathbf{w}_{2}+ \mathbf{b}_{2}+\mathbf{x}_{2}=\mathbf{x}_{0} [\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}]^{T}\mathbf{w}_{2}+\mathbf{b}_{2}+\mathbf{x}_{2} l=2:x3=x0x2Tw2+b2+x2=x0[x0[x0x0Tw0+b0+x0]Tw1+b1+x1]Tw2+b2+x2
结合上面的例子和交叉网络结构, 可以发现:
-
x 1 \mathrm{x}_1 x1中包含了所有的 x 0 \mathrm{x}_0 x0的1,2阶特征的交互, x 2 \mathrm{x}_2 x2包含了所有的 x 1 , x 0 \mathrm{x}_1, \mathrm{x}_0 x1,x0的1, 2, 3阶特征的交互。 因此, 交叉网络层的叉乘阶数是有限的。 第 l l l层特征对应的最高的叉乘阶数 l + 1 l+1 l+1
-
Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。 例如两个稀疏的特征 x i , x j x_i,x_j xi,xj, 它们在数据中几乎不发生交互, 那么学习 x i , x j x_i,x_j xi,xj的权重对于预测没有任何的意义。

-
计算交叉网络的参数数量。 假设交叉层的数量是 L c L_c Lc, 特征 x x x的维度是 n n n, 那么总共的参数是:
n × L c × 2 n\times L_c \times 2 n×Lc×2
这个就是每一层会有w和b。且w维度和x的维度是一致的。 -
交叉网络的时间和空间复杂度是线性的。这是因为, 每一层都只有w和b, 没有激活函数的存在,相对于深度学习网络, 交叉网络的复杂性可以忽略不计。
-
Cross网络是FM的泛化形式, 在FM模型中, 特征 x i x_i xi的权重 v i v_i vi, 那么交叉项 x i , x j x_i,x_j xi,xj的权重为 < x i , x j >
上面的这些结论都来自于下面的第四篇文章, 具体的可以参考文章链接, 总结的非常到位。当然我这里再补充两点新的:
-
我们也要了解,对于每一层的计算中, 都会跟着 x 0 \mathrm{x}_0 x0, 这个是咱们的原始输入, 之所以会乘以一个这个,是为了保证后面不管怎么交叉,都不能偏离我们的原始输入太远,别最后交叉交叉都跑偏了。
-
x l + 1 = f ( x l , w l , b l ) + x l \mathbf{x}_{l+1}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l} xl+1=f(xl,wl,bl)+xl, 这个东西其实有点跳远连接的意思,也就是和resnet也有点相似,无形之中还能有效的缓解梯度消失现象。
5.3 Deep Network
这个就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
h l + 1 = f ( W l h l + b l ) \mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right) hl+1=f(Wlhl+bl)
5.4 组合层
这个层负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
p = σ ( [ x L 1 T , h L 2 T ] w logits ) p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right) p=σ([xL1T,hL2T]wlogits )
其中 x L 1 T \mathbf{x}_{L_{1}}^{T} xL1T h L 2 T \mathbf{h}_{L_{2}}^{T} hL2T表示交叉网络和深度网络的输出。
最后二分类的损失函数依然是交叉熵损失:
loss = − 1 N ∑ i = 1 N y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) + λ ∑ l ∥ w i ∥ 2 \text { loss }=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{i}\right\|^{2} loss =−N1i=1∑Nyilog(pi)+(1−yi)log(1−pi)+λl∑∥wi∥2
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。下面通过编码搭建一个这样的结构, 理解更加详细的细节。
6. Deep&Cross模型的pytorch实现
这里简单的看一下DCN的pytorch实现代码, 这里可以和W&D的对比, 会发现, 把原来的wide部分替换成了一个Cross网络的形式, 这个网络的实现代码如下:
class CrossNetwork(nn.Module):
"""
Cross Network
"""
def __init__(self, layer_num, input_dim):
super(CrossNetwork, self).__init__()
self.layer_num = layer_num
# 定义网络层的参数
self.cross_weights = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
self.cross_bias = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
def forward(self, x):
# x是(None, dim)的形状, 先扩展一个维度到(None, dim, 1)
x_0 = torch.unsqueeze(x, dim=2)
x = x_0.clone()
xT = x_0.clone().permute((0, 2, 1)) # (None, 1, dim)
for i in range(self.layer_num):
x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (None, dim, 1)
xT = x.clone().permute((0, 2, 1)) # (None, 1, dim)
x = torch.squeeze(x) # (None, dim)
return x
这个主要就是上面交叉网络的那个公式, 只不过具体实现的时候, 要注意一些问题, 比如我们的输入x的维度是(None, dim), 而这里的w和b都是(dim, 1)的形式, 直接按照那个公式计算的话, 是没法算的, 我们这里需要先扩展一个维度出来, 把x的形状变成(None, dim, 1), 然后与其转置相乘是一个(None, dim, dim)的维度,这里采用了pytorch里面的bmm函数进行batch维度上的矩阵乘法运算, pytorch专属。 然后与(dim, 1)的w进行矩阵乘法,使用了matmul, 这个函数也是比较的强大,之前我也没有意识到,这里简单总结一下:
关于
torch.mm, torch.bmm, torch.matmul, *, @, torch.mul这几种乘法的运算了解:
torch.mm: 矩阵乘法, 该函数一般只用来计算二维矩阵的矩阵乘法,不支持广播操作, 三维的时候会报错torch.bmm: batch层面的矩阵乘法,该函数的两个输入必须是三维矩阵且第一维度相同, 不支持广播, b × m × n b\times m\times n b×m×n与 b × n × d b\times n\times d b×n×d会得到 b × m × d b\times m \times d b×m×d的维度torch.matmul: 多维矩阵乘法, 支持广播操作, 功能比较强大, 简单的讲, 如果输入是两个二维的, 实现普通的二维矩阵乘法, 和torch.mm的用法一样, 当输入有多维的时候, 把多出的维度作为batch提出来,剩下的部分做矩阵乘法。这篇博客给的几个例子挺不错的。torch.mul: 点积运算, 支持广播,*也是同样的功能@: 也是实现矩阵乘法, 自动执行适合的矩阵乘法函数
另外就是nn.ParameterList, 这个函数在自定义网络层的时候非常有用,具体的可以参考这篇博客
DNN层的实现, 和W&D是一样的代码, 这个就不再这里展示了, 最后看一下最后的DCN, 有些地方还是改了一下:
class DCN(nn.Module):
def __init__(self, feature_columns, hidden_units, layer_num, dnn_dropout=0.):
super(DCN, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0, len(self.dense_feature_cols) + len(self.sparse_feature_cols)*self.sparse_feature_cols[0]['embed_dim'])
self.dnn_network = Dnn(hidden_units)
self.cross_network = CrossNetwork(layer_num, hidden_units[0]) # layer_num是交叉网络的层数, hidden_units[0]表示输入的整体维度大小
self.final_linear = nn.Linear(hidden_units[-1]+hidden_units[0], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
x = torch.cat([sparse_embeds, dense_input], axis=-1)
# cross Network
cross_out = self.cross_network(x)
# Deep Network
deep_out = self.dnn_network(x)
# Concatenate
total_x = torch.cat([cross_out, deep_out], axis=-1)
# out
outputs = F.sigmoid(self.final_linear(total_x))
return outputs
这里依然是要注意pytorch里面的线性层的定义和tf里面的Dense的区别,通过这几个模型的实现来看,感觉相差还是很大的, nn.Linear函数定义线性层, 但需要知道输入和输出维度,且不带激活函数。 所以这里定义线性层的时候,一定要看好输入的维度才能定义。 而tf里面的Dense层, 是直接定义某一层神经元的个数即可, 不需要输入维度, 且可以带激活函数等。 其实简单的看, pytorch是定义了层与层之间的这种过程(中间),而tf在定义单独的某一个垂直层(两端)的感觉。
这就是DCN模型了, 关于详细的代码,可以参考后面给出的GitHub链接。 就是跑了一个小demon感受了一下这个模型,其实如果真用的话,可以调用deepctr的包, 里面进行了一些优化。
7. 总结
这篇文章零零散散的整理了很长时间了, 从10月26号开始整理,到11月30号终于结束了, 中途经历了一个新闻推荐的比赛过程和开题, 没太顾得上学习和更新,说好的一个月4个模型呢, 哈哈, 没有完成, 所以借着11月30号这天,把这篇文章整理完, 后面再尝试恢复之前的计划。 这篇文章依然是挺长的,简单回顾一下。
首先, 这篇文章整理了两个模型Wide&Deep和Deep&Cross模型, 这两个模型开启了模型组合思路的先河, 从这之后, 越来越多的组合模型架构加入到了推荐模型的行列,这两个模型的思想其实比较简单,但取得了非常大的成功, 主要是因为有两大特色:
- 抓住了业务问题的本质特点, 融合了传统模型的记忆能力和深度学习模型的泛化能力
- 模型结构简单, 比较容易工程实现,训练和上线。
所以这两个模型也是比较重要的, 因为这是组合模型思路的开始,后面的很多模型,比如DeepFM, NFM等都可以看成W&D的延伸。
这篇文章主要就是整理了这两个组合模型的原理, 包括一些动机,背景, 具体的剖析了一下每个网络并且用pytorch简单的实现了一下, 顺便整理了一下pytorch的一些知识,比如矩阵的各种乘法操作等。
W&D开启了组合模型的探索之后, 后面又出现了几个FM的演化版本模型, 比如FNN, DeepFM和NFM, 下一篇尝试整理这几个模型, 来领略一下深度学习时代FM的身影 , Rush!
参考:
- 《深度学习推荐系统》 — 王喆
- Wide&Deep模型原论文
- Deep&Cross模型原论文
- Wide&Deep模型的深入理解
- Wide&Deep模型的进阶—Cross&Deep模型
- 详解 Wide&Deep 推荐框架
- 见微知著,你真的搞懂Google的Wide&Deep模型了吗?
- 推荐系统系列(六):Wide&Deep理论与实践
- Datawhale组队学习文档Wide&Deep
整理这篇文章的同时, 也刚建立了一个GitHub项目, 准备后面把各种主流的推荐模型复现一遍,并用通俗易懂的语言进行注释和逻辑整理, 今天的两个模型都已经上传, 参考的子耀的TF2.0的复现过程, 写成了Pytorch代码, 感兴趣的可以看一下
筋斗云:https://github.com/zhongqiangwu960812/AI-RecommenderSystem