2-selenium-选择元素的基本方法
目录
-
-
-
- 根据 ID 选择
- 根据 CLASS 选择
- 根据 tag 名选择元素
-
- WebElement
- 等待界面元素出现
-
-
有一定前端基础的人会发现,F12 或 ctrl+shift+c 会进入源代码中,可以查看到每一部分对应的块(HTML 元素)。
而我们进行每一部分操作的时候,就需要先找到对应的元素,后面才能进行操作。
比如:
进入百度首页,查看 HTML 元素。
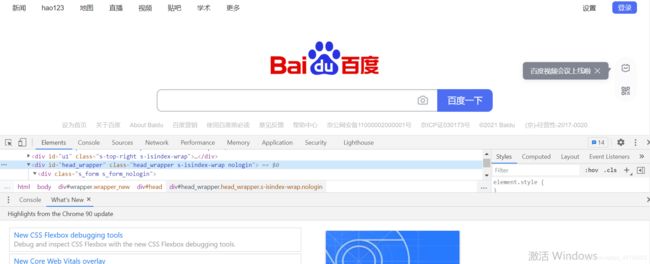
默认进入之后直接进到 elements 页面
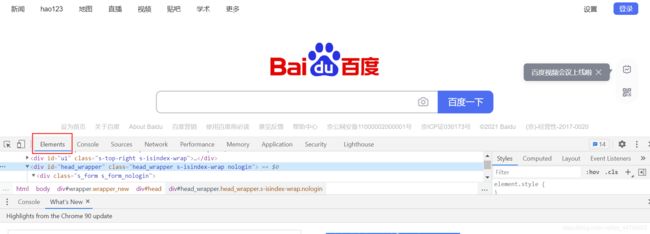
点击左上角的鼠标,然后点击页面的任意元素,就可以查看对应的 HTML 标签了。
这里我点击了搜索框。就可以看到对应的 ID 以及 CLASS 等信息。

根据 ID 选择
根据规范, 如果元素有id属性 ,这个id 必须是当前html中唯一的。
所以我们需要找到特定元素时,一般是找他的 ID。
比如这个搜索框,它的 ID 就是 kw 。
wd.find_element_by_id('kw')
使用了 WebDriver 对象 的方法 find_element_by_id
这行代码运行是,就会发起一个请求通过 浏览器驱动 转发给浏览器,告诉它,需要选择一个id为 kw 的元素。
浏览器,找到id为kw的元素后,将结果通过 浏览器驱动 返回给 自动化程序, 所以 find_element_by_id 方法会 返回一个 WebElement 类型的对象。
这个WebElement 对象可以看成是对应 页面元素 的遥控器。
我们通过这个WebElement对象,就可以 操控 对应的界面元素。
比如:
1 调用这个对象的 send_keys 方法就可以在对应的元素中 输入字符串;
2 调用这个对象的 click 方法就可以 点击 该元素。
根据 CLASS 选择
就像一个 学生张三 可以定义类型为 中国人 或者 学生一样, 中国人 和 学生 都是 张三 的 类型。
元素也有类型, class 属性就用来标志着元素类型 ,
比如
<body>
<div class="plant"><span>土豆块</span></div>
<div class="plant"><span>土豆泥</span></div>
<div class="plant"><span>土豆片</span></div>
<div class="animal"><span>哆啦A梦</span></div>
<div class="animal"><span>哆啦B梦</span></div>
<div class="animal"><span>哆啦C梦</span></div>
</body>
所有的植物元素都有个class属性 值为 plant。
所有的动物元素都有个class属性 值为 animal。
如果我们要选择 所有的 动物, 就可以使用方法 find_elements_by_class_name 。
注意element后面多了个s
wd.find_elements_by_class_name('animal')
find_elements_by_class_name 方法返回的是找到的符合条件的 所有元素 (这里有3个元素), 放在一个列表中返回。
而如果我们使用 find_element_by_class_name (注意少了一个s) 方法, 就只会返回第一个元素。
补充:
元素也可以有 多个class类型 ,多个class类型的值之间用 空格 隔开,比如
<span class="chinese student">张三</span>
张三既是中国人,也是学生,空格隔开表示两个 CLASS 属性。
注意,真正查找 CLASS 元素时,不能这样子写,只能写两个语句。
element = wd.find_elements_by_class_name('chinese student')
分成这两个语句
element = wd.find_elements_by_class_name('chinese')
element = wd.find_elements_by_class_name('student')
根据 tag 名选择元素
直接举例说明,我们可以直接通过 find_elements_by_tag_name 来查找 tag 名为 div 的元素。
也就是标签为 div 的所有元素。
from selenium import webdriver
wd = webdriver.Chrome()
wd.get('https://www.baidu.com/')
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象
elements = wd.find_elements_by_tag_name('div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常。
WebElement
不仅 WebDriver对象有 选择元素 的方法, WebElement对象 也有选择元素的方法。
WebElement对象 也可以调用 find_elements_by_xxx, find_element_by_xxx 之类的方法
WebDriver 对象 选择元素的范围是 整个 web页面, 而
WebElement 对象 选择元素的范围是 该元素的内部。
element = wd.find_element_by_id('container')
# 限制 选择元素的范围是 id 为 container 元素的内部。
spans = element.find_elements_by_tag_name('span')
for span in spans:
print(span.text)
等待界面元素出现
在我们进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
假设我们点击了某搜索框之后,
element = wd.find_element_by_id('kw')
element.send_keys('Python\n')
# id 为 1 的元素 就是第一个搜索结果
element = wd.find_element_by_id('1')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
因为我们的代码执行的速度比 百度服务器响应的速度 快。
百度还没有来得及返回搜索结果,我们就执行了如下代码
element = wd.find_element_by_id('1')
所以可以直接考虑 sleep 等待几秒再执行搜索 id=1 的操作。
但是如何来设定休眠时间呢,太长或太短都不行。
selenium 提供一种解决方案 implicitly_wait
当发现元素没有找到的时候, 并不 立即返回 找不到元素的错误。
而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,
或者超出指定最大等待时长,这时才 抛出异常(如果是 find_elements 之类的方法, 则是返回空列表)。
Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait
该方法接受一个参数, 用来指定 最大等待时长。
wd.implicitly_wait(10)
所以一段代码中,通常在获取网页之前就设定该时间
from selenium import webdriver
wd = webdriver.Chrome()
# 设置最大等待时长为 10秒
wd.implicitly_wait(10)
wd.get('https://www.baidu.com')
element = wd.find_element_by_id('kw')
element.send_keys('Python\n')
element = wd.find_element_by_id('1')
print (element.text)
同时需要注意,有了implicitwait, 可以彻底不用sleep吗?
不是的,有的时候我们等待元素出现,仍然需要sleep。