在上一篇简单使用OpenStack创建实例 已经有三个VM,此文将在这个基础上搭建hadoop环境。做个记录,方便以后查询。
- OpenStack 下的 Ubuntu
- hadoop-2.7.3
- jdk
将材料上传到VM
可以用filezilla, xftp来上传。
安装JDK
解压
$ tar -zxvf jdk-8u121-linux-x64.tar.gz
配置
$ vim /etc/profile
在最后添加
export JAVA_HOME=/home/ubuntu/developer/jdk1.8.0_121
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
请根据你jdk解压的路径修改。
保存退出,然后更新一下。
$ source /etc/profile
注意可以可能需要切换到超级用户才能执行上面操作。
#切换超级用户
$ sudo su
测试
$ java -version

配置SSH 无密码链接
如果没有安装SSH,执行下面命令安装
# Install ssh
$ apt install ssh
# Check 22 port
$ netstat –nat
回到用户目录
即 /home/ubuntu (ubuntu 是当前用户的主目录)
$ cd ~
执行 ssh-keygen 命令, 一直回车。
$ ssh-keygen -t rsa
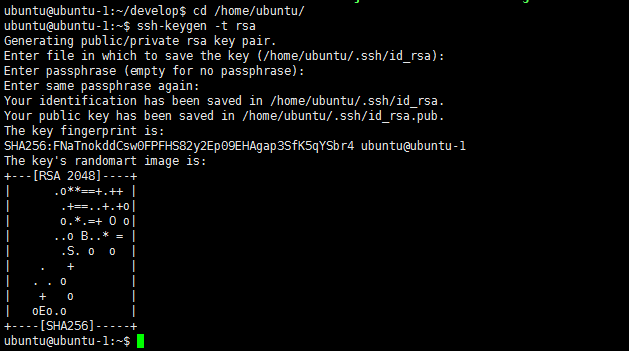
在当前用户目录下有个隐藏目录 .ssh 目录 ,进入该目录
$ cd .ssh
里面有 id_rsa.pub 文件, 将其赋值到 authorized_keys 文件
$ cp id_rsa.pub authorized_keys
然后再测试 SSH登录
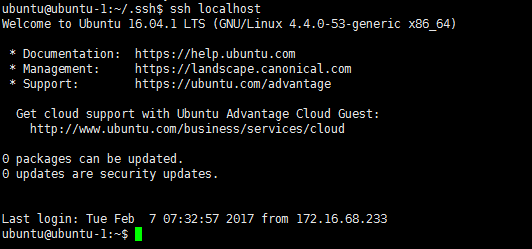
当你尝试连接本机的时候就可以直接链接不需要登录。
如果你想直接链接其他VM, 只需要将其他机器上的 id_rsa.pub 添加到authorized_keys, 这样就可以直接ssh 链接过去而不需要输入密码。 这个在后面启动hadoop 时候就很有用,启动服务就不用输入密码。
配置IP
$ sudo vim /etc/hosts
# 通过此命令配置IP映射
第一个VM的 mster
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master
第二个VM的 slave1
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master
第三个VM的 slave2
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master
配置Hadoop
首先解压 hadoop 文件
$ tar -xvf hadoop-2.7.3.tar.gz
解压完成之后进入 配置文件所在目录即 hadoop-2.7.3 目录下 etc/hadoop 内
cd /data/install/apache/hadoop-2.7.3/etc/hadoop/
接下来要配置以下几个文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves、hadoop-env.sh、yarn-env.sh
hadoop-env.sh和yarn-env.sh 配置 jdk 环境
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/ubuntu/developer/jdk1.8.0_121
core-site.xml
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
file:/home/ubuntu/developer/hadoop-2.7.3/tmp
io.file.buffer.size
131702
hdfs-site.xml
dfs.namenode.name.dir
file:/home/ubuntu/developer/hadoop-2.7.3/hdfs/name
dfs.datanode.data.dir
file:/home/ubuntu/developer/hadoop-2.7.3/hdfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
dfs.namenode.datanode.registration.ip-hostname-check
false
dfs.permissions
false
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
mapred-site.xml
默认没有这个文件 但是提供了个模板 mapred-site.xml.template
通过这个模板复制一个
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
slaves
slave1
slave2
将配置好的hadoop 文件夹复制给其他节点(slave1 和slave2)
scp -r /home/ubuntu/developer/hadoop-2.7.3 ubuntu@slave1:/home/ubuntu/developer/hadoop-2.7.3
scp -r /home/ubuntu/developer/hadoop-2.7.3 ubuntu@slave2:/home/ubuntu/developer/hadoop-2.7.3
运行启动Hadoop
1- 初始化hadoop(清空hdfs数据):
rm -rf /home/ubuntu/developer/hadoop-2.7.3/hdfs/*
rm -rf /home/ubuntu/developer/hadoop-2.7.3/tmp/*
/home/ubuntu/developer/hadoop-2.7.3/bin/hdfs namenode -format
2- 启动hdfs,yarn
/home/ubuntu/developer/hadoop-2.7.3/sbin/start-dfs.sh
/home/ubuntu/developer/hadoop-2.7.3/sbin/start-yarn.sh
3- 停止hdfs,yarn
/home/ubuntu/developer/hadoop-2.7.3/sbin/stop-dfs.sh
/home/ubuntu/developer/hadoop-2.7.3/sbin/stop-yarn.sh
4- 检查是否成功
在 master 终端敲 jps 命令

在 slave 终端敲 jps 命令
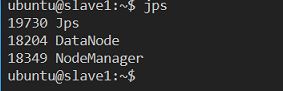
或者在master 节点看 report
$ bin/hdfs dfsadmin -report

到此, hadoop 可以正常启动。
一些常用命令
#列出HDFS下的文件
hdfs dfs -ls
#列出HDFS下某个文档中的文件
hdfs dfs -ls in
#上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功
hdfs dfs -put test1.txt test2.txt
#从HDFS获取文件并且重新命名为getin,
同put一样可操作文件也可操作目录
hdfs dfs -get in getin
#删除指定文件从HDFS上
hdfs dfs -rmr out
#查看HDFS上in目录的内容
hdfs dfs -cat in/*
#查看HDFS的基本统计信息
hdfs dfsadmin -report
#退出安全模式
hdfs dfsadmin -safemode leave
#进入安全模式
hdfs dfsadmin -safemode enter
运行WordCount官方例子
- 在 /home/ubuntu 下建立一个文件夹input, 并放几个txt文件在内
- 切换到 hadoop-2.7.3目录内
- 给hadoop创建一个 wc_input文件夹
$ bin/hdfs dfs -mkdir /wc_input
- 将 /home/ubuntu/input 内的文件传到hadoop /wc_input 内
$ bin/hdfs dfs –put /home/ubuntu/input* /wc_input
- 运行命令
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wc_input /wc_oput
- 查看结果
$ bin/hdfs dfs -ls /wc_output
$ bin/hdfs dfs -ls /wc_output/part-r-00000
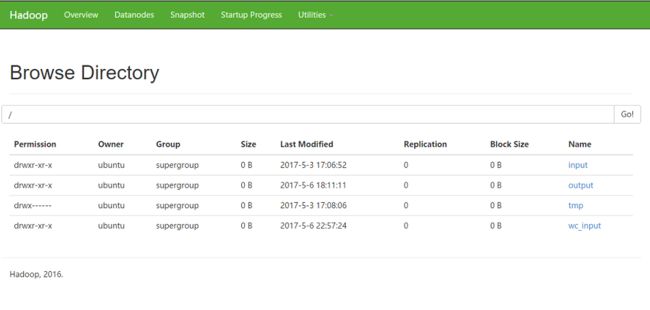
- 在浏览器上查看
http://your-floating-ip:50070/dfshealth.html
但是在此之前可能需要开通端口,为了简便我在OpenStack上将所有端口开通。


http://your-floating-ip:8088/cluster/scheduler
