python可视化:Plotting with pandas and seaborn
第二节Plotting with pandas and seaborn
matplotlib是一个基础的工具。可以用它的基本组件进行绘图:数据显示(线、条、框、散点等)、图例、标题、刻度标签等注释。
在pandas中,有时我们的数据由多列组成,包含行名和列名。使用pandas内置函数可以简化DataFrame和Series对象的可视化。
另一个库是seaborn,这是Michael Waskom创建的一个统计图形库。Seaborn简化了许多常见的可视化类型的创建。
(一)线图
Series和DataFrame对象都有plot属性,可以进行一些基本的图形绘制,在默认参数下,plot()是画线图,下面是一个Series对象的线型图:
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
print(s)In [1]: import pandas as pd
In [2]: s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
In [3]: s
Out[3]:
0 0.361239
10 -0.973009
20 -0.399783
30 -0.375723
40 0.300891
50 -1.181079
60 -1.154158
70 -1.203589
80 -0.697191
90 -0.255197
dtype: float64
In [4]: s.plot()
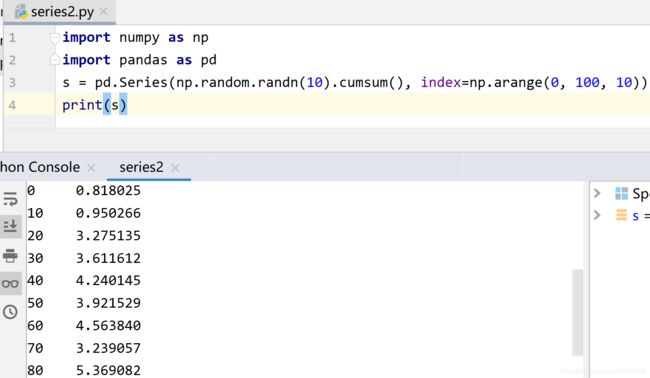
对于DataFrame对象的plot画图来说,每一列有不同的线来表示,并且自动生成图例说明:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0, 100, 10))
print(df)
print(df.plot.line())In [5]: df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0, 100, 10))
df
Out[5]:
A B C D
0 -0.191194 0.124733 0.149630 -0.847222
10 0.315815 -0.098679 -0.745160 -1.272139
20 -0.221957 -0.235838 -0.177400 -0.785572
30 0.668440 -0.531222 -0.097362 -0.064981
40 0.984189 -1.905647 -0.124803 1.642922
50 1.850171 -2.611311 -0.531080 3.320458
60 2.005584 -2.622598 0.514610 5.187108
70 1.649588 -1.959046 0.859002 5.606145
80 2.092307 -1.198536 1.574532 5.193929
90 0.608200 -0.323660 1.634932 3.946735
In [6]: df.plot()

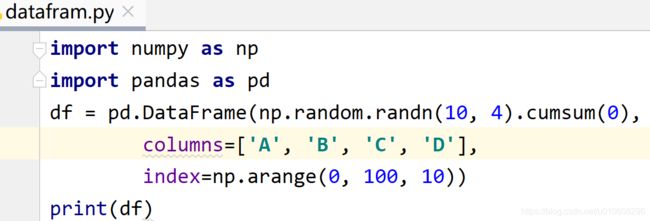
df.plot()函数和df.plot.line()函数的功能是一样的。
(二)bar图
plot.bar()和plot.barh() 分别可绘制竖着的、横着的bar图。
先来看一下Series对象的绘图:
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
print(s)a 0.458095
b 0.652800
c 0.735251
d 0.597668
e 0.331629
f 0.306810
g 0.804735
h 0.687446
i 0.803865
j 0.363527
k 0.528832
l 0.521994
m 0.127526
n 0.525101
o 0.208584
p 0.518751
dtype: float64
In [7]: data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data
Out[7]:
a 0.153508
b 0.172415
c 0.620039
d 0.859878
e 0.230167
f 0.082225
g 0.211878
h 0.933883
i 0.735628
j 0.222665
k 0.848021
l 0.784030
m 0.617523
n 0.226133
o 0.070989
p 0.113303
dtype: float64
In [8]: fig, axes = plt.subplots(2, 1)
data.plot.bar(ax=axes[0], color='k', alpha=0.7)
data.plot.barh(ax=axes[1], color='k', alpha=0.7)color='k'和alpha=0.7分别设置颜色和透明度。
再看一下Dataframe对象的绘图,bar图的分组是根据每一行的值放在一起的。
In [10]: df = pd.DataFrame(np.random.rand(6, 4),
...: index=['one', 'two', 'three', 'four', 'five', 'six'],
...: columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
In [11]: df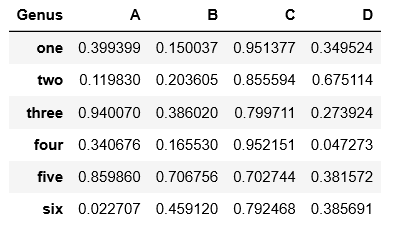
In [12]: df.plot.bar()
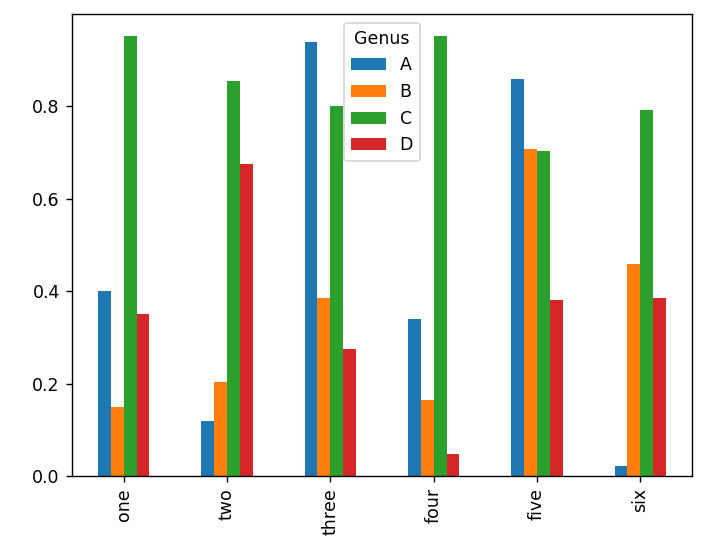
下面是把上面的图变换一下展示的方法:
In [13]: df.plot.barh(stacked=True, alpha=0.5)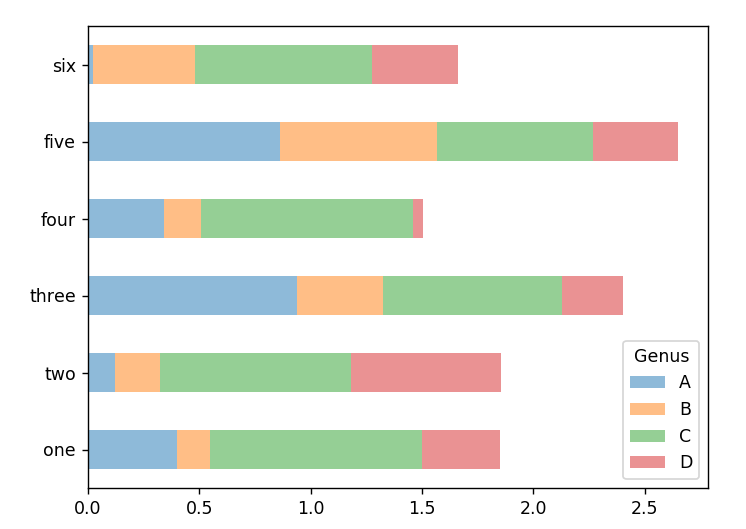
下面用本书附带的示例数据来作图,示例数据下载地址:
https://github.com/wesm/pydata-book/tree/2nd-edition/examples
In [14]: tips = pd.read_csv('example/examples/tips.csv')
tips
把其中的两列day和size两列里相互对应的数量提取出来:
In [15]: party_counts = pd.crosstab(tips['day'], tips['size'])
party_counts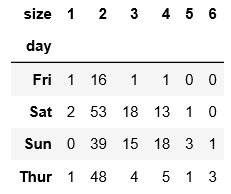
#提取上面的第2列到第5列
party_counts = party_counts.loc[:, 2:5]
party_counts
#将上面的子集每一行进行标准化,标准化后的每一行加起来是1
# Normalize to sum to 1
party_pcts = party_counts.div(party_counts.sum(1), axis=0)
party_pcts
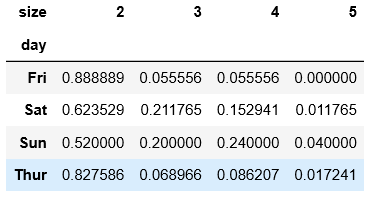
party_pcts.plot.bar()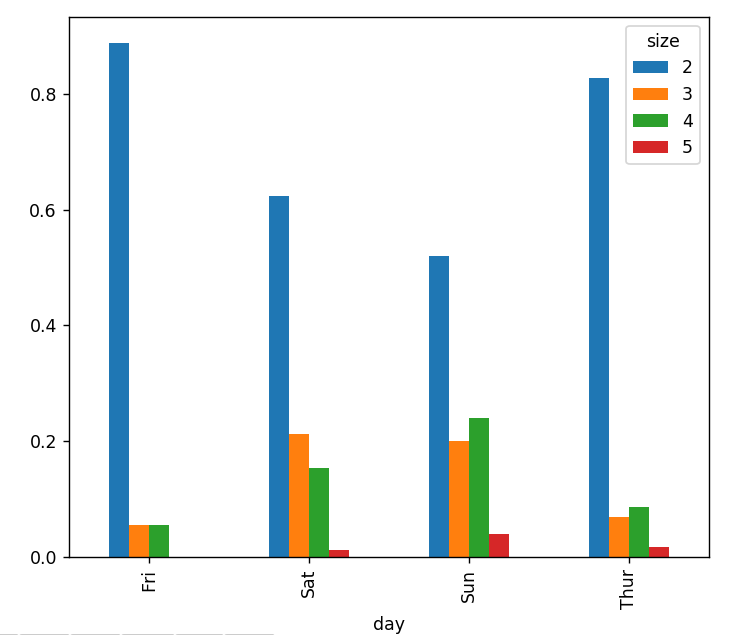
上面是利用pandas进行绘图,下面看一下利用seaborn绘图,同样是用上面的示例数据:
import seaborn as sns
tips = pd.read_csv('example/examples/tips.csv')
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip']) #给dataframe加一列经过计算后的tip_pct列
tips.head()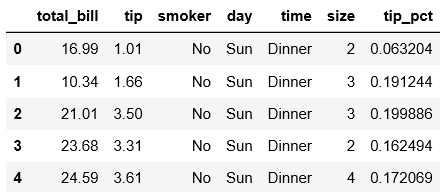
fig = plt.figure()
sns.barplot(x='tip_pct', y='day', data=tips, orient='h')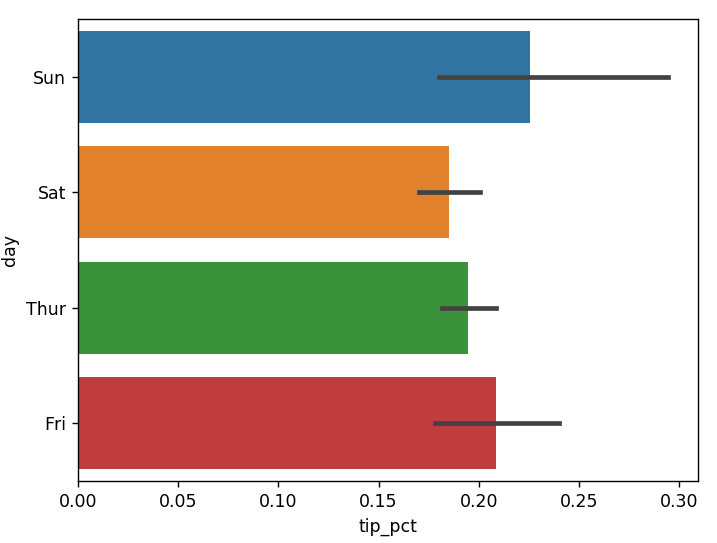
在seaborn里的绘图功能中,data的参数可以是pandas的Dataframe。其他参数可以是列名。上图中,黑色线代表95%的置信区间。
(三)Histograms and Density Plots直方图和密度图
直方图是一种条形图,离散的显示数值频率。数据点被分割成离散的,均匀间隔的bin,绘制每个数据的数量。使用上面的示例数据,我们可以绘制出小费占总账单百分比的直方图:
fig = plt.figure()
tips['tip_pct'].plot.hist(bins=50)
另一个相关的图形是密度图,它是通过计算评估数据的连续概率分布。使用plot.kde来绘制:
fig = plt.figure()
tips['tip_pct'].plot.density()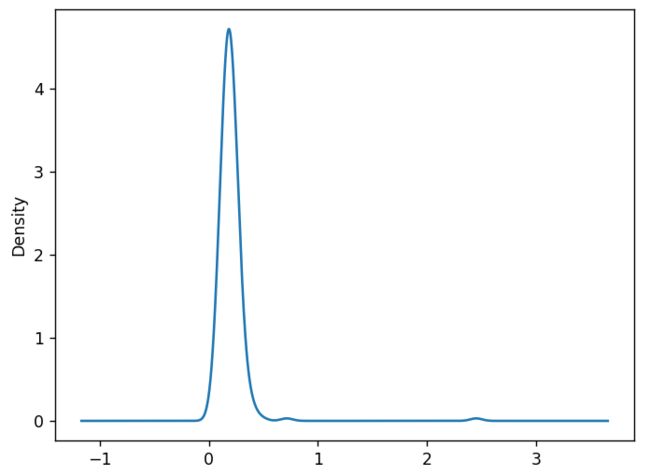
使用Seaborn的distplot函数,可以同时绘制直方图和密度图:
fig = plt.figure() #创建新图
comp1 = np.random.normal(0, 1, size=200) #创建两个随机数组
comp2 = np.random.normal(10, 2, size=200)
values = pd.Series(np.concatenate([comp1, comp2])) #数组拼接
sns.distplot(values, bins=100, color='k') #绘图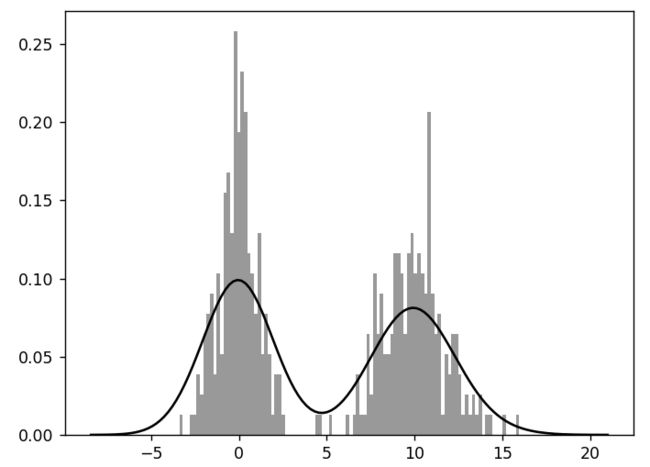
(四)散点图
散点图对于查看二维数组之间的关系还是很有用的。我们用本书的另一个示例数据microdata来做为例子。数据下载地址:https://github.com/wesm/pydata-book
macro = pd.read_csv('example/examples/macrodata.csv')
macro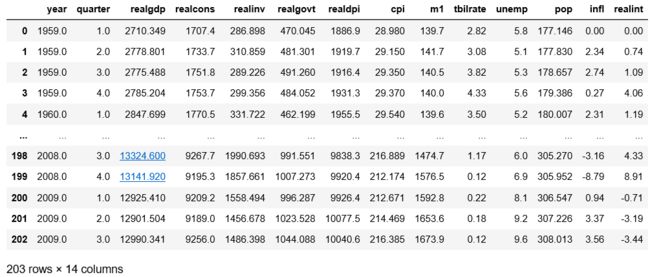
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]#取其中的4列
trans_data = np.log(data).diff().dropna() #取每一列里相邻两个元素之间的差值,然后再取log
trans_data
在使用regplot进行绘图,可以绘制散点图以及拟合回归线:
fig = plt.figure()
sns.regplot('m1', 'unemp', data=trans_data)
plt.title('Changes in log %s versus log %s' % ('m1', 'unemp'))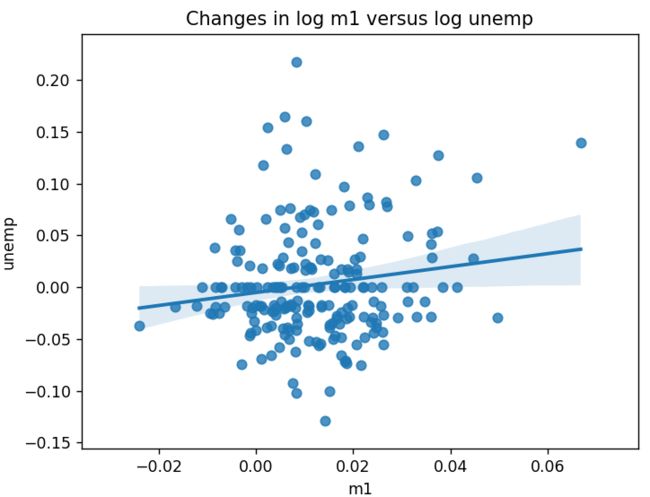
seaborn还有一个方便的配对图函数pairplot,它支持沿对角线放置每个变量的直方图或密度图:
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})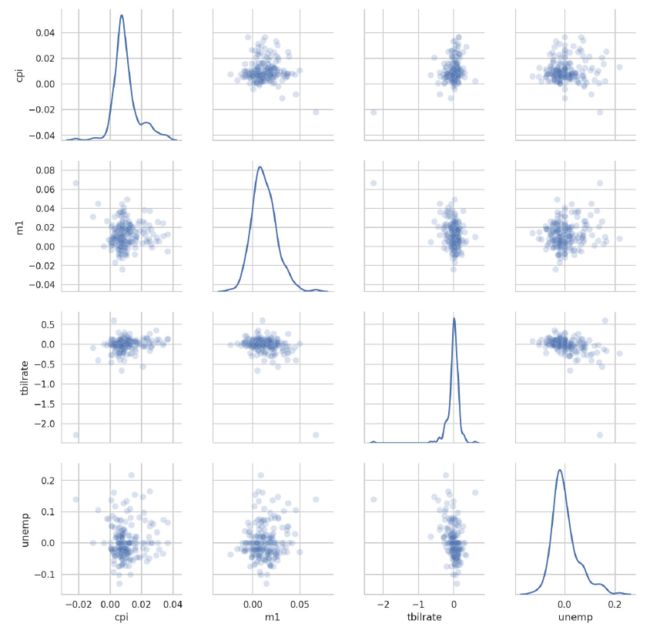
(五)网格图和分类数据
如果我们的数据有额外的分组维度,该如何展示呢?可以使用seaborn的内置函数factorplot来画图。比如还是上面的tips示例数据,我们要把是否是smoker分成两个维度来展示:
#需要注意的是,在python3.7里,factorplot函数被替换成了catplot
sns.catplot(x='day', y='tip_pct', hue='time', col='smoker',
kind='bar', data=tips[tips.tip_pct < 1])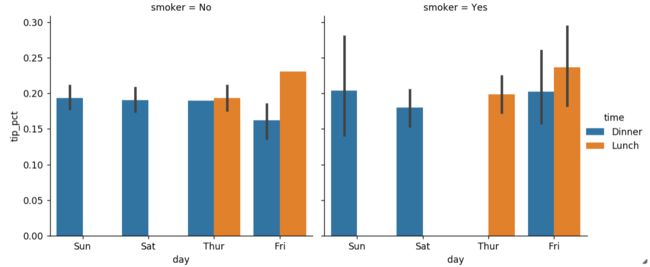
根据上面的time的值,我们可以把上面的两幅图拆分成4幅图:
sns.factorplot(x='day', y='tip_pct', row='time',
col='smoker',
kind='bar', data=tips[tips.tip_pct < 1])
另外,seaborn也可以画箱图:
sns.factorplot(x='tip_pct', y='day', kind='box',
data=tips[tips.tip_pct < 0.5])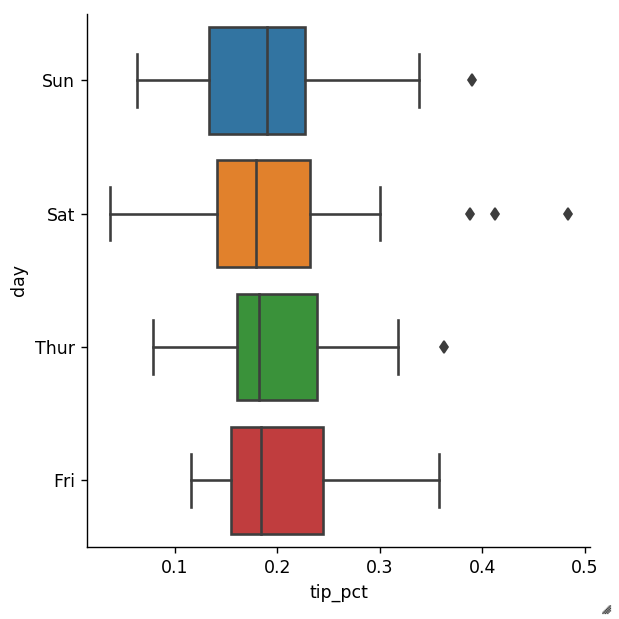
以上是关于seaborn画图的简要介绍,如果想了解更多可以去seaborn的官网,网站做的也是很清爽的。https://seaborn.pydata.org/
