分布式的流行导致程序的调用关系越来越复杂,一次调用可能会涉及到十几个微服务的运转和几十个代码块的执行,特别是与订单和支付相关的业务。此外还会涉及到各个部门的沟通和协作。
当线上项目出现问题,如何在海量日志中快速有效地定位到故障点,就显得至关重要。
通过调用链,利用一个自上而下全局的调用id,把每一次请求调用过程完整的串联起来,将日志以调用id为维度进行汇总和分类,这样就可以实现对调用链的跟踪和监控。目前有许多比较成的分布式跟踪系统,如Google的Dapper,Twitter的zipkin,淘宝的鹰眼,京东的Hydra等。
今天笔者就来为大家分享一下,如何一步步通过扩展现有的日志组件,实现一个简单的调用跟踪功能,从而能够使用flowId(即调用id)来对日志进行归类,达到快速定位bug的效果。
1、生成、传递和输出flowId
如何生成flowId?这里以rest服务为例。可以让所有的Request参数就都继承一个BaseRequest,BaseRequest中包括一个flowId,
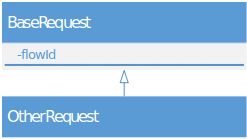
这样所有的请求都可以自带flowId,也可以随着方法地调用一层一层地传递下去,办法和思路都很简洁,但实施起来却有诸多隐患:
会对项目之前所有的Request类进行修改。
按照当前思路,日志输出的时候还需要在原有的log代码上添加相应的log输出操作。
若是无参方法,那岂不是要专门添加参数来传递这个flowId?
总的来说,代码修改量太大,回归测试点较多,容易影响现有的程序。
如何才能最方便地生成、传递和输出flowId呢? slf4j的MDC可以满足我们的要求。MDC(Mapped Diagnostic Context)为每个线程建立一个独立的存储空间,MDC 中包含的内容可以被同一线程中执行的代码所访问。开发人员可以根据需要把信息以 key/value 对的形式存储在 Map 中,当需要记录日志时,只需要从 MDC 中获取所需的信息即可,
下面介绍一下使用方法:
// 清空map所有的条目。
public static void clear();
// 根据key值返回相应的对象
public static Object get(String key);
//返回所有的key值.
public static Enumeration getKeys();
//把key值和关联的对象,插入map中
public static void put(String key, Object val),
//删除key对应的对象
public static remove(String key)
通过MDC.put(“flow-id”, flowId),将flowId放入上下文,key为flow-id,然后指定log输出格式为:
其中%X{flow-id}就是用来读取MDC里面的key为flow-id的值,即可在log中输出flowId。
2、flowId在服务之间传递
上面说到,MDC是基于上下文传递的,所以原生的MDC信息不能跨服务调用,但是flowId的使用都遵守统一的原则:在使用前赋值,在使用后销毁。这一原则可以帮助我们找到切入点,在这里,笔者就以RabbitMQ RPC为例,来说一下我的解决方案。
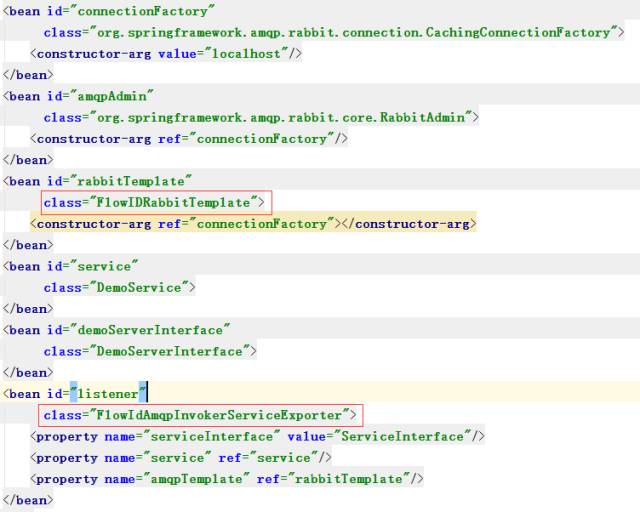
Spring AMQP提供了对rabbitMQ的封装,参考下面配置文件:

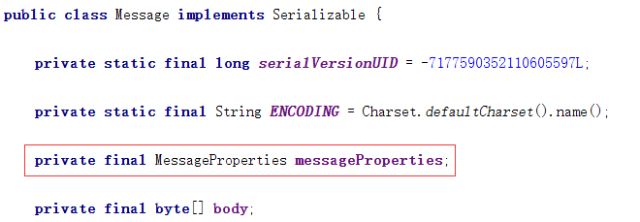
其中有两个关键类RabbitTemplate和AmqpInvokerServiceExporter,RabbitTemplate是一个消息模板类,可以通过调用RabbitTemplate 的convertSendAndReceive方法发送和接收消息消息,在发送之前会通过Message convertMessageIfNecessary(final Object object)方法来对消息进行预处理

封装成用于传递消息的Message对象,message中包括了远程接口的参数和message的一些属性MessageProperties,而MessageProperties会有一个叫做header的HashMap对象,如下图:

类之间的关系可参考下图:

参考源码截图和类关系可以得出结论:消息经过组装,处理之后发送给远程服务,并携带了headers,如果我们在消息处理的时候,覆写原来的消息处理方法convertMessageIfNecessary,把需要传递的flowId封装在header中,即可将它发送给远程服务,实现方法参考下图:

flowId已经被发送给了服务方,接下来我们研究一下服务方如何接收和输出flowId信息。
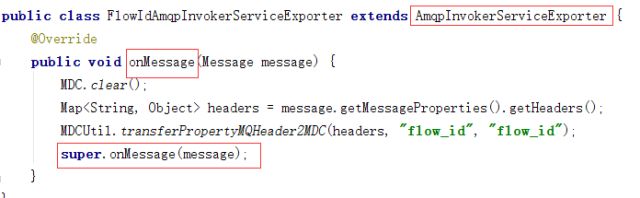
AmqpInvokerServiceExporter可以发布注册服务和监听客户端的消息,并通过AMQP传递,onMessage方法可在接收到消息之后读消息进行提取,处理和回送,所以我们可以覆写onMessage方法,在onMessage方法中取出headers中的flowId,并put到MDC中,即可成功接收flowId:
相关类关系可参考:
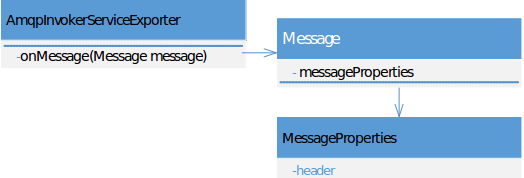
定义好了两个子类,再通过配置文件注入到上下文中,就可以生效了。
以上为大家分享了通过微调MQ相关的类,将flowID从客户端传递到服务端。Rest服务也可以通过Filter和request header实现这一功能,这里就不赘述了。
3、flowId的多线程问题
当我们在多线程场景下是,会遇到flowId为空的情况,如ThreadLocal一样,MDC信息也无法被子线程获取。 MDC提供了getCopyOfContextMap()方法来从父线程赋值MDC信息,并通过setContextMap(mdcContext)方法来赋值到子线程,这样子线程就继承了父线程的flowId。

在spring中还有一种特殊的线程启动方式,如quarz和Scheduled,没有按照我们平时的Thread.start()方式启动,但跟踪Scheduled的运行可以发现,这类方法是通过反射的方式调用的,所以笔者考虑避开线程,从job启动时执行的方法入手:自定义一个注解@FlowIdAnnotation来标记需要切入并生成flowId的方法,在Aspect中定义一个@Around方法,加入flowId生成和销毁的逻辑,即可达到需求。

写在最后
以上就是笔者本次分享的全部内容,Spring生态系统为开发者提供了一个很优秀的平台,但在我们的使用过程中难免遇到一些有特殊需求的场景,这时需要我们在原来的基础上做一些扩展。
本文以一次日志扩展抛砖引玉,期待大家分享更多、更好的DIY。
参考文献:
https://yq.aliyun.com/articles/58408
http://www.cnblogs.com/LBSer/p/3390852.html
本文作者:谭雷(点融黑帮),现就职于点融成都Data部门,毕业于四川大学,热爱排球运动,励志做一个瘦一点的程序员。