pandas基础--1.pandas基础,Series,DataFrame
pandas是numpy的数据分析包
series(一维序列),dataframe(二维表结构)
import pandas as pd
import numpy as np
s1 = pd.Series([4,-7,6,8])#创建Series,索引为默认值
print(s1)
out:
0 4
1 -7
2 6
3 8
dtype: int64
-------------------------------------------------------------------------
s1.values #Series的值
out:array([ 4, -7, 6, 8], dtype=int64)
s1.index #索引
out:RangeIndex(start=0, stop=4, step=1)#从0开始,到4结束,不包括4,步长为1
s2 = pd.Series([4.0,6.5,-0.5,4.2],index=['d','b','a','e'])
print(s2)
out:
d 4.0
b 6.5
a -0.5
e 4.2
dtype: float64
s2['a']
out:-0.5
s2[['a','b','d','e']]
out:
a -0.5
b 6.5
d 4.0
e 4.2
dtype: float64
'a' in s2
out:True
'e' in s2
out:True
'f' in s2
out:False
#Series 可以看成是一个定长的有序字典
dict = {
'apple':5,'pen':3,'applepen':10}
s3 = pd.Series(dict)
print(s3)
out:
apple 5
pen 3
applepen 10
dtype: int64
#DataFrame
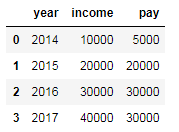
data = {
'year':[2014,2015,2016,2017],
'income':[10000,20000,30000,40000],
'pay':[5000,20000,30000,30000]}
df1 = pd.DataFrame(data)
df1
df2 = pd.DataFrame(np.arange(12).reshape(3,4))
df2

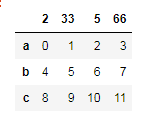
df3 = pd.DataFrame(np.arange(12).reshape((3,4)),index=['a','b','c'],columns=[2,33,5,66])
df3

df1.columns#列
out:Index(['year', 'income', 'pay'], dtype='object')
df2.index#行
out:RangeIndex(start=0, stop=3, step=1)
df1.values
out:
array([[ 2014, 10000, 5000],
[ 2015, 20000, 20000],
[ 2016, 30000, 30000],
[ 2017, 40000, 30000]], dtype=int64)
df1.describe()

df1.T# 转置

df3.sort_index(axis=1)#axis=1对列排序,axis=0对行排序

df3.sort_index(axis=0)

df3.sort_values(by=5)#对5这一列里面的值排序