PaddleNLP实战——LIC2021关系抽取任务基线(附代码)
PaddleNLP实战——LIC2021关系抽取任务基线
目录
- PaddleNLP实战——LIC2021关系抽取任务基线
-
- 一、关系抽取基线
-
- 评价方法
- 1.1 快速复现基线Step1:构建模型
- 1.2 快速复现基线Step2:加载并处理数据
- 1.3 快速复现基线Step3:定义损失函数和优化器,开始训练
- 1.4 快速复现基线Step4:提交预测结果
- 二、Tricks
-
- 2.1 尝试更多的预训练模型
- 2.2 模型集成
- 参考资料
相关系列笔记:
论文阅读:DuEE:A Large-Scale Dataset for Chinese Event Extraction in Real-World Scenarios(附数据集地址)
PaddleNLP实战——LIC2021事件抽取任务基线(附代码)
PaddleNLP实战——LIC2021关系抽取任务基线(附代码)
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。对于给定的自然语言句子,根据预先定义的schema集合,抽取出所有满足schema约束的SPO三元组。
例如,「妻子」关系的schema定义为: { S_TYPE: 人物, P: 妻子, O_TYPE: { @value: 人物 } }
该示例展示了如何使用PaddleNLP快速复现LIC2021关系抽取比赛基线并进阶优化基线。
# 安装paddlenlp最新版本
!pip install --upgrade paddlenlp
%cd relation_extraction/
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Requirement already up-to-date: paddlenlp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.0.0rc16)
Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.1.1)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: numpy>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (1.16.4)
Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.22.1)
Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.0.0)
Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (7.1.2)
Requirement already satisfied, skipping upgrade: six>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.21.0)
Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (2.22.0)
Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.7.1.1)
Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.8.53)
Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.8.2)
Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.14.0)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: scipy>=0.17.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2019.3)
Requirement already satisfied, skipping upgrade: Jinja2>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.10.3)
Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.8.0)
Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.23)
Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (2.0.1)
Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (16.7.9)
Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.10.0)
Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.4)
Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.4.10)
Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (5.1.2)
Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (1.25.6)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2019.9.11)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2.8)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (3.0.4)
Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (7.0)
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (1.1.0)
Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (0.16.0)
Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (3.9.9)
Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (0.18.0)
Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.2.0)
Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.6.0)
Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.6.1)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.5->Flask-Babel>=1.0.0->visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (0.6.0)
Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (7.2.0)
/home/aistudio/relation_extraction
一、关系抽取基线
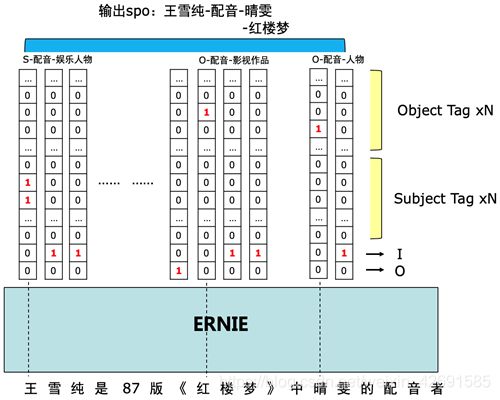
针对 DuIE2.0 任务中多条、交叠SPO这一抽取目标,比赛对标准的 ‘BIO’ 标注进行了扩展。 对于每个 token,根据其在实体span中的位置(包括B、I、O三种),我们为其打上三类标签,并且根据其所参与构建的predicate种类,将 B 标签进一步区分。给定 schema 集合,对于 N 种不同 predicate,以及头实体/尾实体两种情况,我们设计对应的共 2N 种 B 标签,再合并 I 和 O 标签,故每个 token 一共有 (2N+2) 个标签,如下图所示。
评价方法
对测试集上参评系统输出的SPO结果和人工标注的SPO结果进行精准匹配,采用F1值作为评价指标。注意,对于复杂O值类型的SPO,必须所有槽位都精确匹配才认为该SPO抽取正确。针对部分文本中存在实体别名的问题,使用百度知识图谱的别名词典来辅助评测。F1值的计算方式如下:
F1 = (2 * P * R) / (P + R),其中
• P = 测试集所有句子中预测正确的SPO个数 / 测试集所有句子中预测出的SPO个数
• R = 测试集所有句子中预测正确的SPO个数 / 测试集所有句子中人工标注的SPO个数
1.1 快速复现基线Step1:构建模型
该任务可以看作一个序列标注任务,所以基线模型采用的是ERNIE序列标注模型。
PaddleNLP提供了ERNIE预训练模型常用序列标注模型,可以通过指定模型名字完成一键加载。PaddleNLP为了方便用户处理数据,内置了对于各个预训练模型对应的Tokenizer,可以完成文本token化,转token ID,文本长度截断等操作。
文本数据处理直接调用tokenizer即可输出模型所需输入数据。
import os
import json
from paddlenlp.transformers import ErnieForTokenClassification, ErnieTokenizer
label_map_path = os.path.join('data', "predicate2id.json")
if not (os.path.exists(label_map_path) and os.path.isfile(label_map_path)):
sys.exit("{} dose not exists or is not a file.".format(label_map_path))
with open(label_map_path, 'r', encoding='utf8') as fp:
label_map = json.load(fp)
num_classes = (len(label_map.keys()) - 2) * 2 + 2
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=(len(label_map) - 2) * 2 + 2)
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
inputs = tokenizer(text="请输入测试样例", max_seq_len=20)
[2021-04-12 08:24:15,835] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-04-12 08:24:15,838] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams
100%|██████████| 390123/390123 [00:05<00:00, 68401.29it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-04-12 08:24:26,844] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|██████████| 89/89 [00:00<00:00, 4123.60it/s]
1.2 快速复现基线Step2:加载并处理数据
从比赛官网下载数据集,解压存放于data/目录下并重命名为train_data.json, dev_data.json, test_data.json.
我们可以加载自定义数据集。通过继承paddle.io.Dataset,自定义实现__getitem__ 和 __len__两个方法。
from typing import Optional, List, Union, Dict
import numpy as np
import paddle
from tqdm import tqdm
from paddlenlp.utils.log import logger
from data_loader import parse_label, DataCollator, convert_example_to_feature
from extract_chinese_and_punct import ChineseAndPunctuationExtractor
class DuIEDataset(paddle.io.Dataset):
"""
Dataset of DuIE.
"""
def __init__(
self,
input_ids: List[Union[List[int], np.ndarray]],
seq_lens: List[Union[List[int], np.ndarray]],
tok_to_orig_start_index: List[Union[List[int], np.ndarray]],
tok_to_orig_end_index: List[Union[List[int], np.ndarray]],
labels: List[Union[List[int], np.ndarray, List[str], List[Dict]]]):
super(DuIEDataset, self).__init__()
self.input_ids = input_ids
self.seq_lens = seq_lens
self.tok_to_orig_start_index = tok_to_orig_start_index
self.tok_to_orig_end_index = tok_to_orig_end_index
self.labels = labels
def __len__(self):
if isinstance(self.input_ids, np.ndarray):
return self.input_ids.shape[0]
else:
return len(self.input_ids)
def __getitem__(self, item):
return {
"input_ids": np.array(self.input_ids[item]),
"seq_lens": np.array(self.seq_lens[item]),
"tok_to_orig_start_index":
np.array(self.tok_to_orig_start_index[item]),
"tok_to_orig_end_index": np.array(self.tok_to_orig_end_index[item]),
# If model inputs is generated in `collate_fn`, delete the data type casting.
"labels": np.array(
self.labels[item], dtype=np.float32),
}
@classmethod
def from_file(cls,
file_path: Union[str, os.PathLike],
tokenizer: ErnieTokenizer,
max_length: Optional[int]=512,
pad_to_max_length: Optional[bool]=None):
assert os.path.exists(file_path) and os.path.isfile(
file_path), f"{file_path} dose not exists or is not a file."
label_map_path = os.path.join(
os.path.dirname(file_path), "predicate2id.json")
assert os.path.exists(label_map_path) and os.path.isfile(
label_map_path
), f"{label_map_path} dose not exists or is not a file."
with open(label_map_path, 'r', encoding='utf8') as fp:
label_map = json.load(fp)
chineseandpunctuationextractor = ChineseAndPunctuationExtractor()
input_ids, seq_lens, tok_to_orig_start_index, tok_to_orig_end_index, labels = (
[] for _ in range(5))
dataset_scale = sum(1 for line in open(file_path, 'r'))
logger.info("Preprocessing data, loaded from %s" % file_path)
with open(file_path, "r", encoding="utf-8") as fp:
lines = fp.readlines()
for line in tqdm(lines):
example = json.loads(line)
input_feature = convert_example_to_feature(
example, tokenizer, chineseandpunctuationextractor,
label_map, max_length, pad_to_max_length)
input_ids.append(input_feature.input_ids)
seq_lens.append(input_feature.seq_len)
tok_to_orig_start_index.append(
input_feature.tok_to_orig_start_index)
tok_to_orig_end_index.append(
input_feature.tok_to_orig_end_index)
labels.append(input_feature.labels)
return cls(input_ids, seq_lens, tok_to_orig_start_index,
tok_to_orig_end_index, labels)
data_path = 'data'
batch_size = 32
max_seq_length = 128
train_file_path = os.path.join(data_path, 'train_data.json')
train_dataset = DuIEDataset.from_file(
train_file_path, tokenizer, max_seq_length, True)
train_batch_sampler = paddle.io.BatchSampler(
train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
collator = DataCollator()
train_data_loader = paddle.io.DataLoader(
dataset=train_dataset,
batch_sampler=train_batch_sampler,
collate_fn=collator)
eval_file_path = os.path.join(data_path, 'dev_data.json')
test_dataset = DuIEDataset.from_file(
eval_file_path, tokenizer, max_seq_length, True)
test_batch_sampler = paddle.io.BatchSampler(
test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
test_data_loader = paddle.io.DataLoader(
dataset=test_dataset,
batch_sampler=test_batch_sampler,
collate_fn=collator)
[2021-04-12 08:27:21,552] [ INFO] - Preprocessing data, loaded from data/train_data.json
100%|██████████| 171293/171293 [05:17<00:00, 538.88it/s]
[2021-04-12 08:32:39,914] [ INFO] - Preprocessing data, loaded from data/dev_data.json
100%|██████████| 20674/20674 [00:38<00:00, 543.74it/s]
1.3 快速复现基线Step3:定义损失函数和优化器,开始训练
在该基线上,我们选择均方误差作为损失函数,使用paddle.optimizer.AdamW作为优化器。
在训练过程中,模型保存在当前目录checkpoints文件夹下。同时在训练的同时使用官方评测脚本进行评估,输出P/R/F1指标。 在验证集上F1可以达到69.42。
import paddle.nn as nn
class BCELossForDuIE(nn.Layer):
def __init__(self, ):
super(BCELossForDuIE, self).__init__()
self.criterion = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, logits, labels, mask):
loss = self.criterion(logits, labels)
mask = paddle.cast(mask, 'float32')
loss = loss * mask.unsqueeze(-1)
loss = paddle.sum(loss.mean(axis=2), axis=1) / paddle.sum(mask, axis=1)
loss = loss.mean()
return loss
from utils import write_prediction_results, get_precision_recall_f1, decoding
@paddle.no_grad()
def evaluate(model, criterion, data_loader, file_path, mode):
"""
mode eval:
eval on development set and compute P/R/F1, called between training.
mode predict:
eval on development / test set, then write predictions to \
predict_test.json and predict_test.json.zip \
under args.data_path dir for later submission or evaluation.
"""
model.eval()
probs_all = None
seq_len_all = None
tok_to_orig_start_index_all = None
tok_to_orig_end_index_all = None
loss_all = 0
eval_steps = 0
for batch in tqdm(data_loader, total=len(data_loader)):
eval_steps += 1
input_ids, seq_len, tok_to_orig_start_index, tok_to_orig_end_index, labels = batch
logits = model(input_ids=input_ids)
mask = (input_ids != 0).logical_and((input_ids != 1)).logical_and(
(input_ids != 2))
loss = criterion(logits, labels, mask)
loss_all += loss.numpy().item()
probs = F.sigmoid(logits)
if probs_all is None:
probs_all = probs.numpy()
seq_len_all = seq_len.numpy()
tok_to_orig_start_index_all = tok_to_orig_start_index.numpy()
tok_to_orig_end_index_all = tok_to_orig_end_index.numpy()
else:
probs_all = np.append(probs_all, probs.numpy(), axis=0)
seq_len_all = np.append(seq_len_all, seq_len.numpy(), axis=0)
tok_to_orig_start_index_all = np.append(
tok_to_orig_start_index_all,
tok_to_orig_start_index.numpy(),
axis=0)
tok_to_orig_end_index_all = np.append(
tok_to_orig_end_index_all,
tok_to_orig_end_index.numpy(),
axis=0)
loss_avg = loss_all / eval_steps
print("eval loss: %f" % (loss_avg))
id2spo_path = os.path.join(os.path.dirname(file_path), "id2spo.json")
with open(id2spo_path, 'r', encoding='utf8') as fp:
id2spo = json.load(fp)
formatted_outputs = decoding(file_path, id2spo, probs_all, seq_len_all,
tok_to_orig_start_index_all,
tok_to_orig_end_index_all)
if mode == "predict":
predict_file_path = os.path.join(data_path, 'predictions.json')
else:
predict_file_path = os.path.join(data_path, 'predict_eval.json')
predict_zipfile_path = write_prediction_results(formatted_outputs,
predict_file_path)
if mode == "eval":
precision, recall, f1 = get_precision_recall_f1(file_path,
predict_zipfile_path)
os.system('rm {} {}'.format(predict_file_path, predict_zipfile_path))
return precision, recall, f1
elif mode != "predict":
raise Exception("wrong mode for eval func")
from paddlenlp.transformers import LinearDecayWithWarmup
learning_rate = 2e-5
num_train_epochs = 5
warmup_ratio = 0.06
criterion = BCELossForDuIE()
# Defines learning rate strategy.
steps_by_epoch = len(train_data_loader)
num_training_steps = steps_by_epoch * num_train_epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_ratio)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])])
# 模型参数保存路径
!mkdir checkpoints
import time
import paddle.nn.functional as F
# Starts training.
global_step = 0
logging_steps = 50
save_steps = 10000
num_train_epochs = 2
output_dir = 'checkpoints'
tic_train = time.time()
model.train()
for epoch in range(num_train_epochs):
print("\n=====start training of %d epochs=====" % epoch)
tic_epoch = time.time()
for step, batch in enumerate(train_data_loader):
input_ids, seq_lens, tok_to_orig_start_index, tok_to_orig_end_index, labels = batch
logits = model(input_ids=input_ids)
mask = (input_ids != 0).logical_and((input_ids != 1)).logical_and(
(input_ids != 2))
loss = criterion(logits, labels, mask)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
loss_item = loss.numpy().item()
if global_step % logging_steps == 0:
print(
"epoch: %d / %d, steps: %d / %d, loss: %f, speed: %.2f step/s"
% (epoch, num_train_epochs, step, steps_by_epoch,
loss_item, logging_steps / (time.time() - tic_train)))
tic_train = time.time()
if global_step % save_steps == 0 and global_step != 0:
print("\n=====start evaluating ckpt of %d steps=====" %
global_step)
precision, recall, f1 = evaluate(
model, criterion, test_data_loader, eval_file_path, "eval")
print("precision: %.2f\t recall: %.2f\t f1: %.2f\t" %
(100 * precision, 100 * recall, 100 * f1))
print("saving checkpoing model_%d.pdparams to %s " %
(global_step, output_dir))
paddle.save(model.state_dict(),
os.path.join(output_dir,
"model_%d.pdparams" % global_step))
model.train()
global_step += 1
tic_epoch = time.time() - tic_epoch
print("epoch time footprint: %d hour %d min %d sec" %
(tic_epoch // 3600, (tic_epoch % 3600) // 60, tic_epoch % 60))
# Does final evaluation.
print("\n=====start evaluating last ckpt of %d steps=====" %
global_step)
precision, recall, f1 = evaluate(model, criterion, test_data_loader,
eval_file_path, "eval")
print("precision: %.2f\t recall: %.2f\t f1: %.2f\t" %
(100 * precision, 100 * recall, 100 * f1))
paddle.save(model.state_dict(),
os.path.join(output_dir,
"model_%d.pdparams" % global_step))
print("\n=====training complete=====")
=====start training of 0 epochs=====
epoch: 0 / 2, steps: 0 / 5352, loss: 0.721817, speed: 100.65 step/s
epoch: 0 / 2, steps: 50 / 5352, loss: 0.710706, speed: 4.35 step/s
epoch: 0 / 2, steps: 100 / 5352, loss: 0.681220, speed: 4.33 step/s
epoch: 0 / 2, steps: 150 / 5352, loss: 0.608591, speed: 4.17 step/s
epoch: 0 / 2, steps: 200 / 5352, loss: 0.418718, speed: 4.30 step/s
epoch: 0 / 2, steps: 250 / 5352, loss: 0.307587, speed: 4.31 step/s
epoch: 0 / 2, steps: 300 / 5352, loss: 0.260866, speed: 4.29 step/s
epoch: 0 / 2, steps: 350 / 5352, loss: 0.229669, speed: 4.28 step/s
epoch: 0 / 2, steps: 400 / 5352, loss: 0.205042, speed: 4.28 step/s
epoch: 0 / 2, steps: 450 / 5352, loss: 0.180981, speed: 4.29 step/s
epoch: 0 / 2, steps: 500 / 5352, loss: 0.161323, speed: 4.29 step/s
epoch: 0 / 2, steps: 550 / 5352, loss: 0.143654, speed: 4.29 step/s
epoch: 0 / 2, steps: 600 / 5352, loss: 0.126170, speed: 4.29 step/s
epoch: 0 / 2, steps: 650 / 5352, loss: 0.110170, speed: 4.28 step/s
epoch: 0 / 2, steps: 700 / 5352, loss: 0.098008, speed: 4.13 step/s
epoch: 0 / 2, steps: 750 / 5352, loss: 0.086216, speed: 4.28 step/s
epoch: 0 / 2, steps: 800 / 5352, loss: 0.076197, speed: 4.29 step/s
epoch: 0 / 2, steps: 850 / 5352, loss: 0.067776, speed: 4.27 step/s
epoch: 0 / 2, steps: 900 / 5352, loss: 0.060580, speed: 4.29 step/s
epoch: 0 / 2, steps: 950 / 5352, loss: 0.053458, speed: 4.29 step/s
epoch: 0 / 2, steps: 1000 / 5352, loss: 0.049620, speed: 4.28 step/s
epoch: 0 / 2, steps: 1050 / 5352, loss: 0.045512, speed: 4.30 step/s
epoch: 0 / 2, steps: 1100 / 5352, loss: 0.041225, speed: 4.26 step/s
epoch: 0 / 2, steps: 1150 / 5352, loss: 0.038455, speed: 4.28 step/s
epoch: 0 / 2, steps: 1200 / 5352, loss: 0.033661, speed: 4.20 step/s
epoch: 0 / 2, steps: 1250 / 5352, loss: 0.031614, speed: 4.31 step/s
epoch: 0 / 2, steps: 1300 / 5352, loss: 0.030919, speed: 4.32 step/s
epoch: 0 / 2, steps: 1350 / 5352, loss: 0.028184, speed: 4.15 step/s
epoch: 0 / 2, steps: 1400 / 5352, loss: 0.022967, speed: 4.30 step/s
epoch: 0 / 2, steps: 1450 / 5352, loss: 0.022758, speed: 4.27 step/s
epoch: 0 / 2, steps: 1500 / 5352, loss: 0.020432, speed: 4.25 step/s
epoch: 0 / 2, steps: 1550 / 5352, loss: 0.019004, speed: 4.27 step/s
epoch: 0 / 2, steps: 1600 / 5352, loss: 0.017774, speed: 4.23 step/s
epoch: 0 / 2, steps: 1650 / 5352, loss: 0.016835, speed: 4.25 step/s
epoch: 0 / 2, steps: 1700 / 5352, loss: 0.016313, speed: 4.27 step/s
epoch: 0 / 2, steps: 1750 / 5352, loss: 0.014991, speed: 4.26 step/s
epoch: 0 / 2, steps: 1800 / 5352, loss: 0.013867, speed: 4.24 step/s
epoch: 0 / 2, steps: 1850 / 5352, loss: 0.013067, speed: 4.30 step/s
epoch: 0 / 2, steps: 1900 / 5352, loss: 0.012588, speed: 4.28 step/s
epoch: 0 / 2, steps: 1950 / 5352, loss: 0.012091, speed: 4.22 step/s
epoch: 0 / 2, steps: 2000 / 5352, loss: 0.011783, speed: 4.26 step/s
epoch: 0 / 2, steps: 2050 / 5352, loss: 0.014299, speed: 4.25 step/s
epoch: 0 / 2, steps: 2100 / 5352, loss: 0.010042, speed: 4.28 step/s
epoch: 0 / 2, steps: 2150 / 5352, loss: 0.010234, speed: 4.24 step/s
epoch: 0 / 2, steps: 2200 / 5352, loss: 0.010122, speed: 4.30 step/s
epoch: 0 / 2, steps: 2250 / 5352, loss: 0.008944, speed: 4.22 step/s
epoch: 0 / 2, steps: 2300 / 5352, loss: 0.009281, speed: 4.34 step/s
epoch: 0 / 2, steps: 2350 / 5352, loss: 0.009252, speed: 4.25 step/s
epoch: 0 / 2, steps: 2400 / 5352, loss: 0.010335, speed: 4.26 step/s
epoch: 0 / 2, steps: 2450 / 5352, loss: 0.009249, speed: 4.29 step/s
epoch: 0 / 2, steps: 2500 / 5352, loss: 0.009273, speed: 4.24 step/s
epoch: 0 / 2, steps: 2550 / 5352, loss: 0.007440, speed: 4.28 step/s
epoch: 0 / 2, steps: 2600 / 5352, loss: 0.008797, speed: 4.29 step/s
epoch: 0 / 2, steps: 2650 / 5352, loss: 0.008859, speed: 4.28 step/s
epoch: 0 / 2, steps: 2700 / 5352, loss: 0.008952, speed: 4.32 step/s
epoch: 0 / 2, steps: 2750 / 5352, loss: 0.007367, speed: 4.29 step/s
epoch: 0 / 2, steps: 2800 / 5352, loss: 0.007996, speed: 4.19 step/s
epoch: 0 / 2, steps: 2850 / 5352, loss: 0.007748, speed: 4.30 step/s
epoch: 0 / 2, steps: 2900 / 5352, loss: 0.007244, speed: 4.29 step/s
epoch: 0 / 2, steps: 2950 / 5352, loss: 0.006419, speed: 4.25 step/s
epoch: 0 / 2, steps: 3000 / 5352, loss: 0.007522, speed: 4.29 step/s
epoch: 0 / 2, steps: 3050 / 5352, loss: 0.007346, speed: 4.25 step/s
epoch: 0 / 2, steps: 3100 / 5352, loss: 0.008252, speed: 4.27 step/s
epoch: 0 / 2, steps: 3150 / 5352, loss: 0.006726, speed: 4.29 step/s
epoch: 0 / 2, steps: 3200 / 5352, loss: 0.006741, speed: 4.25 step/s
epoch: 0 / 2, steps: 3250 / 5352, loss: 0.007330, speed: 4.31 step/s
epoch: 0 / 2, steps: 3300 / 5352, loss: 0.007728, speed: 4.30 step/s
epoch: 0 / 2, steps: 3350 / 5352, loss: 0.005440, speed: 4.31 step/s
epoch: 0 / 2, steps: 3400 / 5352, loss: 0.006389, speed: 4.26 step/s
epoch: 0 / 2, steps: 3450 / 5352, loss: 0.006755, speed: 4.26 step/s
epoch: 0 / 2, steps: 3500 / 5352, loss: 0.005665, speed: 4.26 step/s
epoch: 0 / 2, steps: 3550 / 5352, loss: 0.006122, speed: 4.20 step/s
epoch: 0 / 2, steps: 3600 / 5352, loss: 0.006181, speed: 4.26 step/s
epoch: 0 / 2, steps: 3650 / 5352, loss: 0.006389, speed: 4.26 step/s
epoch: 0 / 2, steps: 3700 / 5352, loss: 0.006517, speed: 4.23 step/s
epoch: 0 / 2, steps: 3750 / 5352, loss: 0.004906, speed: 4.26 step/s
epoch: 0 / 2, steps: 3800 / 5352, loss: 0.005490, speed: 4.24 step/s
epoch: 0 / 2, steps: 3850 / 5352, loss: 0.005950, speed: 4.08 step/s
epoch: 0 / 2, steps: 3900 / 5352, loss: 0.005796, speed: 4.21 step/s
epoch: 0 / 2, steps: 3950 / 5352, loss: 0.004934, speed: 4.28 step/s
epoch: 0 / 2, steps: 4000 / 5352, loss: 0.004503, speed: 4.27 step/s
epoch: 0 / 2, steps: 4050 / 5352, loss: 0.004397, speed: 4.28 step/s
epoch: 0 / 2, steps: 4100 / 5352, loss: 0.004144, speed: 4.18 step/s
epoch: 0 / 2, steps: 4150 / 5352, loss: 0.004736, speed: 4.28 step/s
epoch: 0 / 2, steps: 4200 / 5352, loss: 0.004336, speed: 4.29 step/s
epoch: 0 / 2, steps: 4250 / 5352, loss: 0.004310, speed: 4.26 step/s
epoch: 0 / 2, steps: 4300 / 5352, loss: 0.004534, speed: 4.25 step/s
epoch: 0 / 2, steps: 4350 / 5352, loss: 0.004380, speed: 4.20 step/s
epoch: 0 / 2, steps: 4400 / 5352, loss: 0.004350, speed: 4.28 step/s
epoch: 0 / 2, steps: 4450 / 5352, loss: 0.004721, speed: 4.30 step/s
epoch: 0 / 2, steps: 4500 / 5352, loss: 0.003458, speed: 4.18 step/s
epoch: 0 / 2, steps: 4550 / 5352, loss: 0.004181, speed: 4.27 step/s
epoch: 0 / 2, steps: 4600 / 5352, loss: 0.004579, speed: 4.23 step/s
epoch: 0 / 2, steps: 4650 / 5352, loss: 0.004575, speed: 4.19 step/s
epoch: 0 / 2, steps: 4700 / 5352, loss: 0.004307, speed: 4.27 step/s
epoch: 0 / 2, steps: 4750 / 5352, loss: 0.004365, speed: 4.31 step/s
epoch: 0 / 2, steps: 4800 / 5352, loss: 0.004365, speed: 4.29 step/s
epoch: 0 / 2, steps: 4850 / 5352, loss: 0.003723, speed: 4.30 step/s
epoch: 0 / 2, steps: 4900 / 5352, loss: 0.004648, speed: 4.27 step/s
epoch: 0 / 2, steps: 4950 / 5352, loss: 0.004886, speed: 4.26 step/s
epoch: 0 / 2, steps: 5000 / 5352, loss: 0.004225, speed: 4.29 step/s
epoch: 0 / 2, steps: 5050 / 5352, loss: 0.004350, speed: 4.28 step/s
epoch: 0 / 2, steps: 5100 / 5352, loss: 0.003667, speed: 4.27 step/s
epoch: 0 / 2, steps: 5150 / 5352, loss: 0.003098, speed: 4.24 step/s
epoch: 0 / 2, steps: 5200 / 5352, loss: 0.003984, speed: 4.26 step/s
epoch: 0 / 2, steps: 5250 / 5352, loss: 0.003870, speed: 4.28 step/s
epoch: 0 / 2, steps: 5300 / 5352, loss: 0.004336, speed: 4.22 step/s
epoch: 0 / 2, steps: 5350 / 5352, loss: 0.004293, speed: 4.24 step/s
epoch time footprint: 0 hour 20 min 55 sec
=====start training of 1 epochs=====
epoch: 1 / 2, steps: 48 / 5352, loss: 0.002881, speed: 4.25 step/s
epoch: 1 / 2, steps: 98 / 5352, loss: 0.003354, speed: 4.20 step/s
epoch: 1 / 2, steps: 148 / 5352, loss: 0.002854, speed: 4.27 step/s
epoch: 1 / 2, steps: 198 / 5352, loss: 0.003613, speed: 4.22 step/s
epoch: 1 / 2, steps: 248 / 5352, loss: 0.003249, speed: 4.26 step/s
epoch: 1 / 2, steps: 298 / 5352, loss: 0.003046, speed: 4.27 step/s
epoch: 1 / 2, steps: 348 / 5352, loss: 0.003595, speed: 4.25 step/s
epoch: 1 / 2, steps: 398 / 5352, loss: 0.004121, speed: 4.29 step/s
epoch: 1 / 2, steps: 448 / 5352, loss: 0.003194, speed: 4.27 step/s
epoch: 1 / 2, steps: 498 / 5352, loss: 0.003622, speed: 4.29 step/s
epoch: 1 / 2, steps: 548 / 5352, loss: 0.003387, speed: 4.26 step/s
epoch: 1 / 2, steps: 598 / 5352, loss: 0.004010, speed: 4.24 step/s
epoch: 1 / 2, steps: 648 / 5352, loss: 0.003333, speed: 4.27 step/s
epoch: 1 / 2, steps: 698 / 5352, loss: 0.003030, speed: 4.32 step/s
epoch: 1 / 2, steps: 748 / 5352, loss: 0.004185, speed: 4.29 step/s
epoch: 1 / 2, steps: 798 / 5352, loss: 0.002702, speed: 4.28 step/s
epoch: 1 / 2, steps: 848 / 5352, loss: 0.003886, speed: 4.25 step/s
epoch: 1 / 2, steps: 898 / 5352, loss: 0.003025, speed: 4.29 step/s
epoch: 1 / 2, steps: 948 / 5352, loss: 0.004369, speed: 4.32 step/s
epoch: 1 / 2, steps: 998 / 5352, loss: 0.003555, speed: 4.21 step/s
epoch: 1 / 2, steps: 1048 / 5352, loss: 0.004115, speed: 4.26 step/s
epoch: 1 / 2, steps: 1098 / 5352, loss: 0.003514, speed: 4.16 step/s
epoch: 1 / 2, steps: 1148 / 5352, loss: 0.002826, speed: 4.31 step/s
epoch: 1 / 2, steps: 1198 / 5352, loss: 0.002491, speed: 4.30 step/s
epoch: 1 / 2, steps: 1248 / 5352, loss: 0.003286, speed: 4.22 step/s
epoch: 1 / 2, steps: 1298 / 5352, loss: 0.002838, speed: 4.27 step/s
epoch: 1 / 2, steps: 1348 / 5352, loss: 0.002872, speed: 4.28 step/s
epoch: 1 / 2, steps: 1398 / 5352, loss: 0.004169, speed: 4.23 step/s
epoch: 1 / 2, steps: 1448 / 5352, loss: 0.003755, speed: 4.29 step/s
epoch: 1 / 2, steps: 1498 / 5352, loss: 0.002883, speed: 4.23 step/s
epoch: 1 / 2, steps: 1548 / 5352, loss: 0.002871, speed: 4.28 step/s
epoch: 1 / 2, steps: 1598 / 5352, loss: 0.002420, speed: 4.30 step/s
epoch: 1 / 2, steps: 1648 / 5352, loss: 0.002560, speed: 4.27 step/s
epoch: 1 / 2, steps: 1698 / 5352, loss: 0.003345, speed: 4.18 step/s
epoch: 1 / 2, steps: 1748 / 5352, loss: 0.003580, speed: 4.25 step/s
epoch: 1 / 2, steps: 1798 / 5352, loss: 0.002884, speed: 4.27 step/s
epoch: 1 / 2, steps: 1848 / 5352, loss: 0.004138, speed: 4.24 step/s
epoch: 1 / 2, steps: 1898 / 5352, loss: 0.002940, speed: 4.26 step/s
epoch: 1 / 2, steps: 1948 / 5352, loss: 0.002196, speed: 4.25 step/s
epoch: 1 / 2, steps: 1998 / 5352, loss: 0.003657, speed: 4.26 step/s
epoch: 1 / 2, steps: 2048 / 5352, loss: 0.003009, speed: 4.27 step/s
epoch: 1 / 2, steps: 2098 / 5352, loss: 0.002162, speed: 4.31 step/s
epoch: 1 / 2, steps: 2148 / 5352, loss: 0.002524, speed: 4.26 step/s
epoch: 1 / 2, steps: 2198 / 5352, loss: 0.002588, speed: 4.28 step/s
epoch: 1 / 2, steps: 2248 / 5352, loss: 0.002743, speed: 4.31 step/s
epoch: 1 / 2, steps: 2298 / 5352, loss: 0.002255, speed: 4.26 step/s
epoch: 1 / 2, steps: 2348 / 5352, loss: 0.003633, speed: 4.30 step/s
epoch: 1 / 2, steps: 2398 / 5352, loss: 0.002488, speed: 4.31 step/s
epoch: 1 / 2, steps: 2448 / 5352, loss: 0.002564, speed: 4.27 step/s
epoch: 1 / 2, steps: 2498 / 5352, loss: 0.002715, speed: 4.32 step/s
epoch: 1 / 2, steps: 2548 / 5352, loss: 0.002240, speed: 4.27 step/s
epoch: 1 / 2, steps: 2598 / 5352, loss: 0.002332, speed: 4.29 step/s
epoch: 1 / 2, steps: 2648 / 5352, loss: 0.002317, speed: 4.29 step/s
epoch: 1 / 2, steps: 2698 / 5352, loss: 0.002979, speed: 4.22 step/s
epoch: 1 / 2, steps: 2748 / 5352, loss: 0.002951, speed: 4.28 step/s
epoch: 1 / 2, steps: 2798 / 5352, loss: 0.002859, speed: 4.20 step/s
epoch: 1 / 2, steps: 2848 / 5352, loss: 0.003190, speed: 4.25 step/s
epoch: 1 / 2, steps: 2898 / 5352, loss: 0.002822, speed: 4.27 step/s
epoch: 1 / 2, steps: 2948 / 5352, loss: 0.001922, speed: 4.25 step/s
epoch: 1 / 2, steps: 2998 / 5352, loss: 0.002181, speed: 4.24 step/s
epoch: 1 / 2, steps: 3048 / 5352, loss: 0.002438, speed: 4.31 step/s
epoch: 1 / 2, steps: 3098 / 5352, loss: 0.001835, speed: 4.26 step/s
epoch: 1 / 2, steps: 3148 / 5352, loss: 0.002860, speed: 4.28 step/s
epoch: 1 / 2, steps: 3198 / 5352, loss: 0.002489, speed: 4.22 step/s
epoch: 1 / 2, steps: 3248 / 5352, loss: 0.002574, speed: 4.23 step/s
epoch: 1 / 2, steps: 3298 / 5352, loss: 0.002109, speed: 4.29 step/s
epoch: 1 / 2, steps: 3348 / 5352, loss: 0.002587, speed: 4.16 step/s
epoch: 1 / 2, steps: 3398 / 5352, loss: 0.002031, speed: 4.27 step/s
epoch: 1 / 2, steps: 3448 / 5352, loss: 0.003532, speed: 4.31 step/s
epoch: 1 / 2, steps: 3498 / 5352, loss: 0.003243, speed: 4.25 step/s
epoch: 1 / 2, steps: 3548 / 5352, loss: 0.002701, speed: 4.26 step/s
epoch: 1 / 2, steps: 3598 / 5352, loss: 0.002815, speed: 4.27 step/s
epoch: 1 / 2, steps: 3648 / 5352, loss: 0.002458, speed: 4.28 step/s
epoch: 1 / 2, steps: 3698 / 5352, loss: 0.002668, speed: 4.25 step/s
epoch: 1 / 2, steps: 3748 / 5352, loss: 0.002385, speed: 4.26 step/s
epoch: 1 / 2, steps: 3798 / 5352, loss: 0.002186, speed: 4.27 step/s
epoch: 1 / 2, steps: 3848 / 5352, loss: 0.003757, speed: 4.27 step/s
epoch: 1 / 2, steps: 3898 / 5352, loss: 0.002339, speed: 4.23 step/s
epoch: 1 / 2, steps: 3948 / 5352, loss: 0.002287, speed: 4.25 step/s
epoch: 1 / 2, steps: 3998 / 5352, loss: 0.003288, speed: 4.28 step/s
epoch: 1 / 2, steps: 4048 / 5352, loss: 0.002677, speed: 4.23 step/s
epoch: 1 / 2, steps: 4098 / 5352, loss: 0.002587, speed: 4.24 step/s
epoch: 1 / 2, steps: 4148 / 5352, loss: 0.002182, speed: 4.24 step/s
epoch: 1 / 2, steps: 4198 / 5352, loss: 0.002209, speed: 4.28 step/s
epoch: 1 / 2, steps: 4248 / 5352, loss: 0.003369, speed: 4.13 step/s
epoch: 1 / 2, steps: 4298 / 5352, loss: 0.002609, speed: 4.26 step/s
epoch: 1 / 2, steps: 4348 / 5352, loss: 0.002384, speed: 4.29 step/s
epoch: 1 / 2, steps: 4398 / 5352, loss: 0.002895, speed: 4.25 step/s
epoch: 1 / 2, steps: 4448 / 5352, loss: 0.003119, speed: 4.27 step/s
epoch: 1 / 2, steps: 4498 / 5352, loss: 0.002288, speed: 4.26 step/s
epoch: 1 / 2, steps: 4548 / 5352, loss: 0.003341, speed: 4.25 step/s
epoch: 1 / 2, steps: 4598 / 5352, loss: 0.002699, speed: 4.26 step/s
epoch: 1 / 2, steps: 4648 / 5352, loss: 0.002447, speed: 4.24 step/s
=====start evaluating ckpt of 10000 steps=====
100%|██████████| 646/646 [08:04<00:00, 1.33it/s]
eval loss: 0.002434
precision: 64.70 recall: 62.10 f1: 63.37
saving checkpoing model_10000.pdparams to checkpoints
epoch: 1 / 2, steps: 4698 / 5352, loss: 0.002275, speed: 0.10 step/s
epoch: 1 / 2, steps: 4748 / 5352, loss: 0.002032, speed: 4.26 step/s
epoch: 1 / 2, steps: 4798 / 5352, loss: 0.002255, speed: 4.19 step/s
epoch: 1 / 2, steps: 4848 / 5352, loss: 0.003138, speed: 4.28 step/s
epoch: 1 / 2, steps: 4898 / 5352, loss: 0.001771, speed: 4.28 step/s
epoch: 1 / 2, steps: 4948 / 5352, loss: 0.002749, speed: 4.24 step/s
epoch: 1 / 2, steps: 4998 / 5352, loss: 0.003003, speed: 4.28 step/s
epoch: 1 / 2, steps: 5048 / 5352, loss: 0.002809, speed: 4.24 step/s
epoch: 1 / 2, steps: 5098 / 5352, loss: 0.001894, speed: 4.29 step/s
epoch: 1 / 2, steps: 5148 / 5352, loss: 0.002233, speed: 4.28 step/s
epoch: 1 / 2, steps: 5198 / 5352, loss: 0.002597, speed: 4.27 step/s
epoch: 1 / 2, steps: 5248 / 5352, loss: 0.002875, speed: 4.30 step/s
epoch: 1 / 2, steps: 5298 / 5352, loss: 0.001676, speed: 4.26 step/s
epoch: 1 / 2, steps: 5348 / 5352, loss: 0.002207, speed: 4.24 step/s
epoch time footprint: 0 hour 29 min 20 sec
=====start evaluating last ckpt of 10704 steps=====
100%|██████████| 646/646 [07:57<00:00, 1.35it/s]
eval loss: 0.002349
precision: 62.01 recall: 62.44 f1: 62.22
=====training complete=====
1.4 快速复现基线Step4:提交预测结果
将训练保存的模型加载后进行预测。
NOTE: 注意设置用于预测的模型参数路径。
!bash predict.sh
+ export CUDA_VISIBLE_DEVICES=0
+ CUDA_VISIBLE_DEVICES=0
+ export BATCH_SIZE=8
+ BATCH_SIZE=8
+ export CKPT=./checkpoints/model_10000.pdparams
+ CKPT=./checkpoints/model_10000.pdparams
+ export DATASET_FILE=./data/test_data.json
+ DATASET_FILE=./data/test_data.json
+ python run_duie.py --do_predict --init_checkpoint ./checkpoints/model_10000.pdparams --predict_data_file ./data/test_data.json --max_seq_length 512 --batch_size 8
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
[2021-04-12 14:42:04,394] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-04-12 14:42:04,395] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams
100%|████████████████████████████████| 390123/390123 [00:05<00:00, 67876.65it/s]
W0412 14:42:10.218497 113 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0412 14:42:10.223258 113 device_context.cc:372] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-04-12 14:42:16,808] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|█████████████████████████████████████████| 89/89 [00:00<00:00, 4363.55it/s]
[2021-04-12 14:42:16,941] [ INFO] - Preprocessing data, loaded from ./data/test_data.json
100%|████████████████████████████████████| 50583/50583 [03:43<00:00, 225.96it/s]
=====start predicting=====
20%|███████▎ | 1259/6322 [24:34<3:12:58, 2.29s/it]
(未完待续)
预测结果会被保存在data/predictions.json,data/predictions.json.zip,其格式与原数据集文件一致。
之后可以使用官方评估脚本评估训练模型在dev_data.json上的效果。如:
python re_official_evaluation.py --golden_file=dev_data.json --predict_file=predicitons.json.zip [–alias_file alias_dict]
输出指标为Precision, Recall 和 F1,Alias file包含了合法的实体别名,最终评测的时候会使用,这里不予提供。
之后在test_data.json上预测,然后预测结果(.zip文件)至评测网站。
二、Tricks
2.1 尝试更多的预训练模型
基线采用的预训练模型为ERNIE,PaddleNLP提供了丰富的预训练模型,如BERT,RoBERTa,Electra,XLNet等 参考PaddleNLP预训练模型介绍
如可以选择RoBERTa large中文模型优化模型效果,只需更换模型和tokenizer即可无缝衔接。
from paddlenlp.transformers import RobertaForTokenClassification, RobertaTokenizer
model = RobertaForTokenClassification.from_pretrained(
"roberta-wwm-ext-large",
num_classes=(len(label_map) - 2) * 2 + 2)
tokenizer = RobertaTokenizer.from_pretrained("roberta-wwm-ext-large")
2.2 模型集成
使用多个模型进行训练预测,将各个模型预测结果进行融合。
参考资料
https://aistudio.baidu.com/aistudio/competition/detail/65