Python实现微博爬虫,爬取新浪微博
上代码
import requests
import pandas as pd
import json
import re
user_type_dict = {
-1:'无认证',0:'个人账户',3:'非个人用户'} # 个人:个人账户仍保留橙色黄色标识,非个人用户(机构、企业、媒体等)将采用全新蓝色标识。
def get_one_page(keyword,page):
one_page_data = []
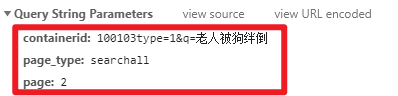
params = {
'containerid': f'100103type=1&q={keyword}',
'page_type': 'searchall',
'page': page
}
url = 'https://m.weibo.cn/api/container/getIndex?'# 请求api
response = requests.get(url,params=params).text
id_ls = re.findall('"id":"(.{16}?)",',response,re.DOTALL)
detail_url = ['https://m.weibo.cn/detail/' + i for i in id_ls]
for i in detail_url:
print(i)
response = requests.get(i).text
# print(response)
data = re.findall("var \$render_data = \[({.*})]\[0]",response,re.DOTALL)[0]
data = json.loads(data)['status']
# 发文时间
created_at_time = data['created_at']
# 文章id
log_id = data['id']
# 文章内容
log_text = data['text']
log_text = re.sub('<.*?>','',log_text)
# 发文设备
source = data["source"]
# 转发数"reposts_count": 1376,
reposts_count = data['reposts_count']
# 评论数"comments_count": 10244,
comments_count = data['comments_count']
# 点赞数"attitudes_count": 326440
attitudes_count = data['attitudes_count']
# 用户id-->"id": 1951123110,
uesr_id = data['user']['id']
# 用户昵称
uesr_screen_name = data['user']['screen_name']
# 用户验证类型-->"verified_type": 3,
user_type = data['user']['verified_type']
if user_type not in user_type_dict:
continue
user_type = user_type_dict[user_type]
one_piece_data = (created_at_time,i, log_text,source,reposts_count,comments_count,attitudes_count, uesr_id, uesr_screen_name, user_type)
column_name = ('发文时间','文章地址','文章内容','发文设备','转发数','评论数','点赞数','用户id','用户昵称','用户验证类型')
one_page_data.append(dict(zip(column_name,one_piece_data)))
print(one_piece_data)
return one_page_data
if __name__ == '__main__':
keyword = input('请输入检索话题:')
page = input('请输入获取前几页:')
all_data = []
for i in range(1,eval(page)+1):
try:
one_page_data = get_one_page(keyword, str(i))
except:
continue
all_data += one_page_data
df = pd.DataFrame(all_data)
df.to_excel('微博爬取内容4.xlsx',index = False)
设计思路
从微博手机端进行爬取
https://m.weibo.cn/

进入话题列表页面
https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D%E8%80%81%E4%BA%BA%E8%A2%AB%E7%8B%97%E7%BB%8A%E5%80%92
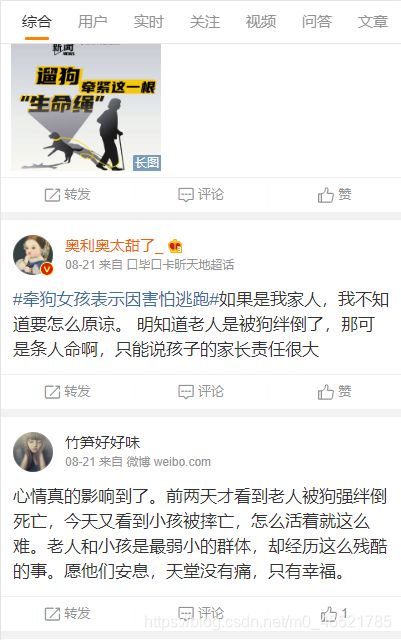
文章详情页面
https://m.weibo.cn/detail/4539964169139251

我们见到的所有的信息无非就在这两个界面,包括文章的视频播放量啊,评论数啊,点赞数啊,用户信息啊,用户评论啊,用户端类型啊等等,大家有兴趣自行探索,我只介绍如何获取正文和点赞评论转发数量以及用户类型
获取每一页的文章列表
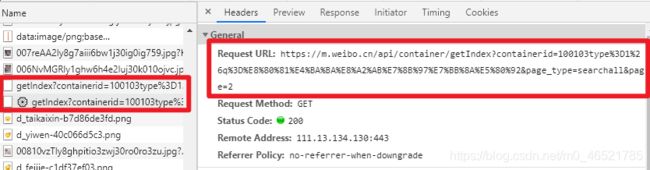
我们获取detail后面的那个标志,是文章的id和idstr以及mid,在此,我们使用id这个变量
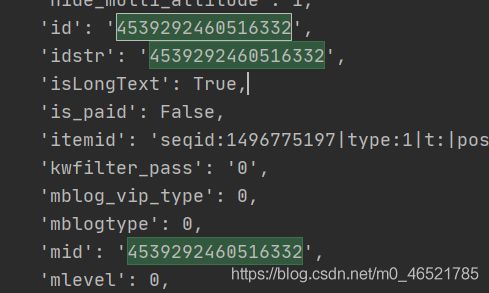
获取文章的id与短文
https://www.zhihu.com/question/22099567
个人账户仍保留橙色黄色标识,非个人用户(机构、企业、媒体等)将采用全新蓝色标识。

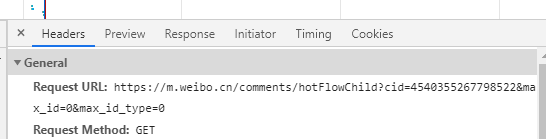
评论的id
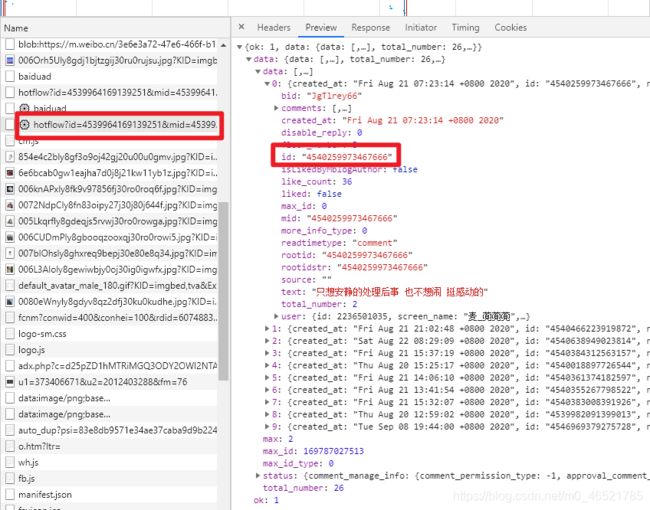
评论的详情
详情的url就是文章详情链接加上评论的id
https://m.weibo.cn/detail/4539964169139251?cid=4540355267798522
但是可以直接调用api实现,cid就是文章的id