【数据挖掘与分析】python网络爬虫学习及实践记录 | part02-网络请求(11-16)
老规矩,上笔记先上视频的清单,这里截图来一张。

加一波资源,因为有几天还有一点点视频没有看,索性把视频全都分类转码传上了B站,祈祷哪天有网没事干,或者梦里醒来有段代码看不懂,对着在线资源再刷一遍,虽然并没有这样的可能。但学习是一日不学手生,三日不学心慌,所以传>不传,正好已经审核成功了。这里贴出来,给有需要的小伙伴们, 传送门点我。
另外,最近看到一个视频,非常治愈,【卡林巴琴】《未闻花名》片尾曲 《secret base》
今天刚好把所有手头上的标注的任务告一段落,而且开始动手整理每次例会的会议纪要,包括画图等若干杂事。心里一阵轻松,时间也随之消耗,所以,学习时间不长,只是过来挖个坑。废话少说,直进
11-cookie信息的加载与保存
看三分钟回家,这里讲cookie,要补充一个点,马老师实现的那个部分,用的是session,当时去查了一下,session与cookie的区别,没有整理,需要整理。而且最好搞明白为什么上个练习无法用cookie实现。
cookie保存到本地,使用的MozillaCookieJar包,导入后加保存的文件名+文件类型。
代码实现(敲个头就溜了,因为十点了啊,南湖的娃回家要半小时啊):
# from Ruby in 2019/06/19
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookie.text')
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
resp = opener.open('http://www.baidu.com/')
cookiejar.save()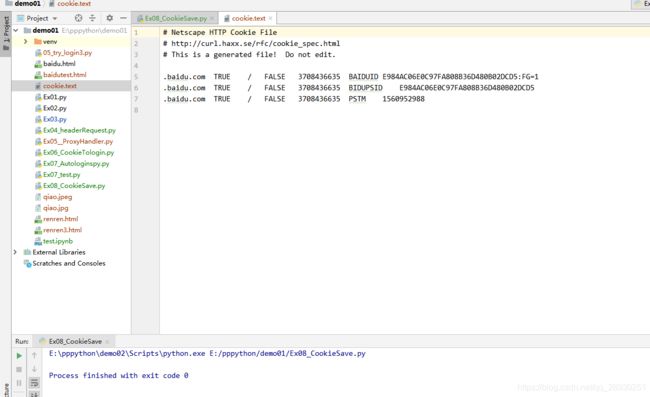
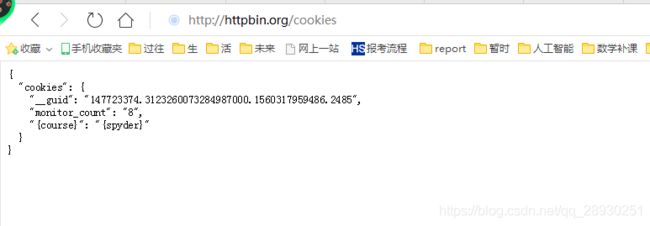
代码如上,抓下来的cookie信息如上二图。老师补充说明 上次httpbin那个网站修改cookie信息,使用的是 set?course=spyder 这种方法,经查,发现现在的用法是 /cookies/set/{name}/{value} Sets a cookie and redirects to cookie list.

于是换做这种方式实现,通过下图可知,确实是改了。
老师用的mac直接点击浏览器地址栏左侧感叹号就打开了cookie文件结构,我找了一圈才发现
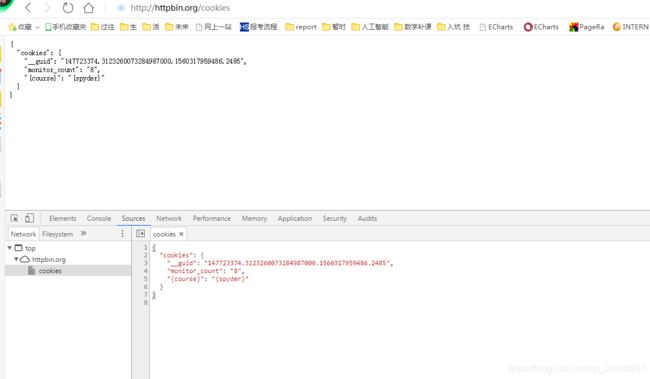 确实一致。 但是检查了一下360浏览器,始终找不到那个感叹号,于是果断换成chrome浏览器。输入设置链接后,修改cookie的值了。
确实一致。 但是检查了一下360浏览器,始终找不到那个感叹号,于是果断换成chrome浏览器。输入设置链接后,修改cookie的值了。
![]()

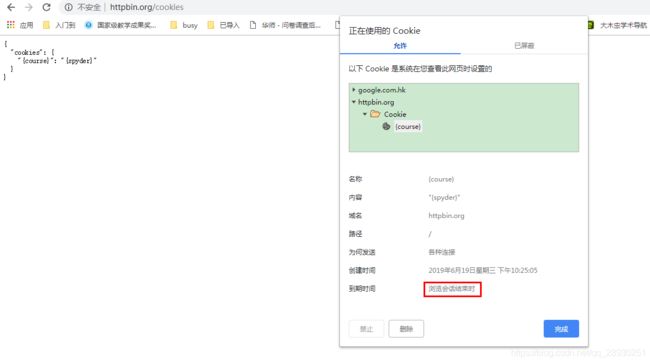
再次检查浏览器cookie发现确实已经修改了,cookie信息。
再去代码中测试发现,可以获取访问结束的cookie。
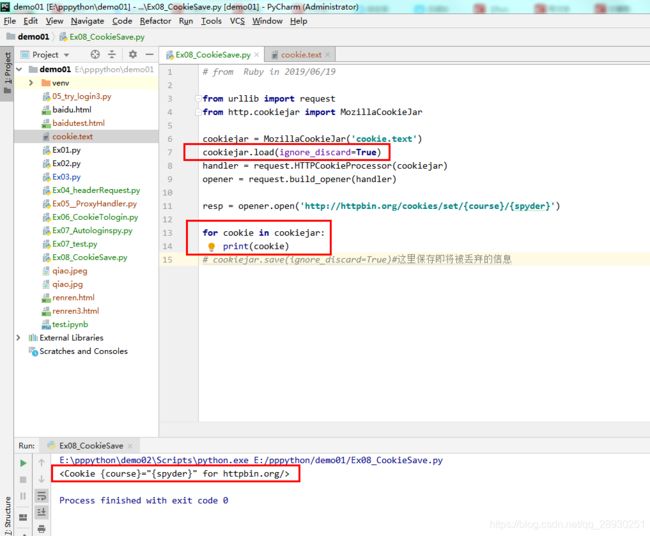
好,这部分代码ok,正好十点半。回家。
这里做一个小总结,前面跟的视频一直都在讲,urillib库,使用的是cookie的方式保存。
12-requests库的基本使用
API使用上,urllib模块较麻烦
发送“GET”请求
response = request.get("http://www.baidu.com")代码实例说明,text的用法会出现乱码,这个是str的数据类型,属于requests库,对response.content进行解码的字符串,解码需要指定解码方式,会自选择编码方式,可能会出现解码产生乱码,需使用content的方式手动解码。
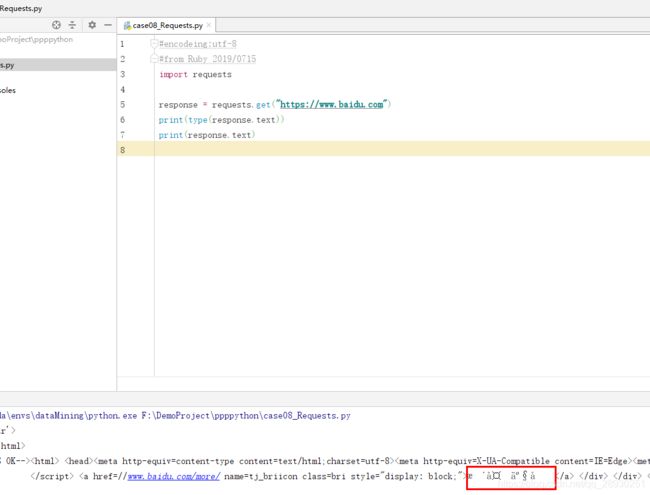
所以使用“content”用法作为对比,content的是直接从网络上抓取的数据,没有经过任何解码,是bytes类型,硬盘|网络上传输字符串都是bytes类型。这里补充decode解码用法。
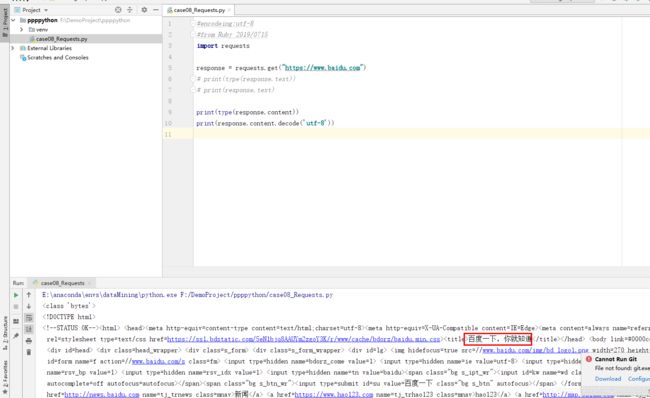
这两种获取方式,response.content和text,后者无乱码用这个,有乱码用前者然后加解码。
介绍响应内容和响应码,其中使用一个百度爬取关键字“中国”的案例,使用open读写到“baidu.html”内,经点击发现是本地的文件
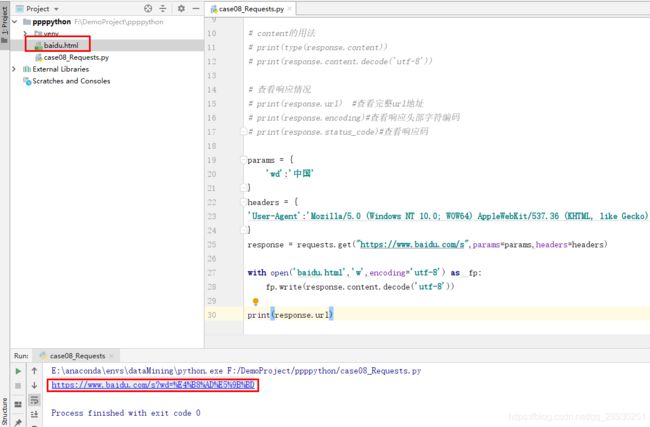
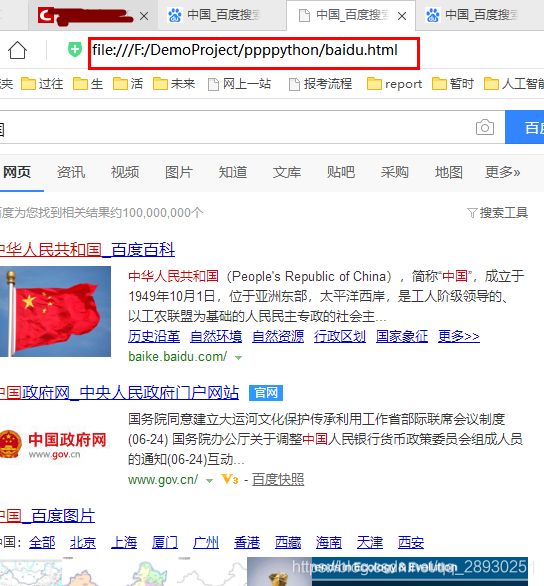 且和另外从控制台返回的响应链接、直接网页访问百度网页搜索一致,练习完成,下一个。
且和另外从控制台返回的响应链接、直接网页访问百度网页搜索一致,练习完成,下一个。
13-发送POST请求
首先介绍调用方法,如同get,也是response.post,只是后面需要补充一个data,这里老师选用“拉勾网职位信息的爬取”作为讲解案例:
拉勾网的getJson文件已经不再是post方法,所以找到直聘的网站找了一个POST方法获取了一段信息,同时打印json()下输出的类型为dict字典类型。
14-使用代理
15-处理cookie信息
这两个和前面urllib讲的重复了,把库名直接替换成requests就行,听过没有重复做笔记。
16-处理不信任的SSL证书