分布式训练 -GPU训练
起初为调用大规模的模型训练,单卡GPU是不够使用的,需要借用服务器的多GPU使用。就会涉及到单机多卡,多机多卡的使用。在这里记录一下使用的方式和踩过的一些坑。文中若有不足,请多多指正。
由于分布式的内容较多,笔者准备分几篇来讲一次下深度学习的分布式训练,深度学习的框架使用的是Pytorch框架。
----1.分布式训练的理论基础
----2.GPU训练
----3.单机多卡的使用
----4.多机多卡的使用
首先第一个问题:我们为什么要用GPU训练? GPU 训练有哪些好处?
不急不急,让我们带着问题慢慢来看这篇文章。
大家有时间的话可以看看这个视频,Nvidia发布的一个关于GPU和CPU对比的视频,看完后会有一丝丝的感受。
还有一个自身的感受,在做一些实验的时候,刚开始为了跑一下,在自己实验室电脑上(没有装GPU)跑一轮花费20分钟。当时的心情直接崩溃,后来转到实验室的工作站上,显卡是3090。一轮只需要20秒,恩,你没有看错,得确实20秒。差距不是一般的大。
很简单的理解:GPU的出现就是加速计算,节约时间。
有很多博主详细的讨论了CPU和GPU的区别,有想要看的小伙伴可以点解下面的链接:
CPU和GPU跑深度学习差别有多大
今天我们详细来讨论一下Pytorch中如何使用GPU来训练我们自己的神经网络:
理论

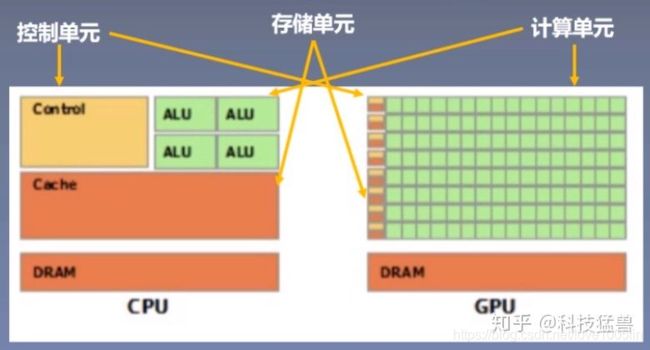
Pytorch中想要进行张量的计算,就必须都在CPU或者都在GPU上,不可以一个在GPU,一个在CPU上,这样会直接报错!!!
那么Pytorch是如何解决数据是在CPU合适GPU上这个问题的呢?
to 函数:
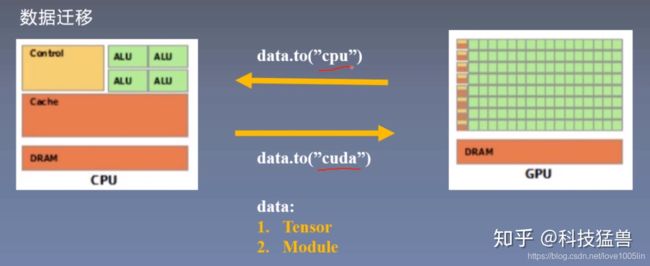
注意,to函数的对象要么是你的数据Tensor,要么是你的模型Module。
举个例子:

第1个例子:to函数用来转换数据的类型。第3个例子:to函数用来转换模型的数据类型。
第2个例子:to函数把数据x迁移到GPU上。第4个例子:to函数把模型迁移到GPU上。
区别:张量不执行inplace(执行之后重新构建一个新的张量),模型执行inplace(执行之后不重新构建一个新的张量)。
例1:Tensor cuda 的使用
import torch
import torch.nn as nn
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ========================== tensor to cuda
# flag = 0
flag = 1
if flag:
x_cpu = torch.ones((3, 3))
print("x_cpu:\ndevice: {} is_cuda: {} id: {}".format(x_cpu.device, x_cpu.is_cuda, id(x_cpu)))
x_gpu = x_cpu.to(device)
print("x_gpu:\ndevice: {} is_cuda: {} id: {}".format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)))
结果:

这段代码首先创建一个张量x,先放在CPU里面,之后再把它迁移到GPU里面,我们打印一些信息看看。注意,两次的结果id不一样,正好说明了代码重新构建了一个新的张量x。
注意这里有个值得说明的地方是你可能还听说过x_gpu = x_cpu.cuda()这个指令,但这是PyTorch 0.x的用法,所以弃用了。
例2:Module cuda 的使用
flag = 1
if flag:
net = nn.Sequential(nn.Linear(3, 3))
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
net.to(device)
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
结果:

这段代码首先创建一个Module,先放在CPU里面,之后再把它迁移到GPU里面,我们打印一些信息看看。注意,两次的结果id一样,正好说明了代码不重新构建了一个新的张量x。
例3:数据模型全进GPU
flag = 1
if flag:
output = net(x_gpu)
print("output is_cuda: {}".format(output.is_cuda))
结果:
![]()
但如果的你的数据和模型不全在GPU里面,报错,比如说下面这句话:
output = net(x_cpu)
结果:
![]()
torch.cuda 常用方法:
import torch
# 打印当前可见可用GPU数目
print(torch.cuda.device_count())
# 获取GPU名字
print(torch.cuda.get_device_name())
# 为当前GPU设置随机种子
torch.cuda.manual_seed(1)
# 为所有可见可用GPU设置随机种子
torch.cuda.manual_seed_all(123)
# 设置主GPU为哪一个物理GPU(不推荐)
torch.cuda.set_device(1)
# 推荐 通过设置环境变量确定使用那些GPU
import os
os.environ.setdefault("CUDA_VISINLE_DEVICES","2,3")
结果:

控制当前的脚本可见的GPU数量。
比如说我机器上4块GPU,但是用了上边这条命令以后,脚本就只能用物理GPU(2,3)了,对应着逻辑GPU(0,1)。这样可以限制这个脚本可以使用的GPU数量,便于多个实验同时做。
在知道了如何将数据和模型转移到GPU上后,那我们会考虑如何使用来多GPU呢?下面我们看下多GPU的分发并行机制,在下一篇文章中会再更加细致地讲解。