Spark 是专门为大数据处理设计的通用计算引擎,是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校 AMP 实验室开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的 MapReduce 计算模型。高效的支撑更多计算模式,包括交互式查询和流处理。Spark 的一个主要特点是能够在内存中进行计算,即使依赖磁盘进行复杂的运算,Spark 依然比 MapReduce 更加高效。(2.3.3)
Spark 的四大特性:speed,easy to use,Generality,Runs Everywhere
Spark 生态包含了:Spark Core、Spark Streaming、Structured Streaming、Spark SQL、Graphx 和机器学习相关的库等。
学习 Spark 我们应该掌握:
(1)Spark Core:
Spark的集群搭建和集群架构(Spark 集群中的角色)
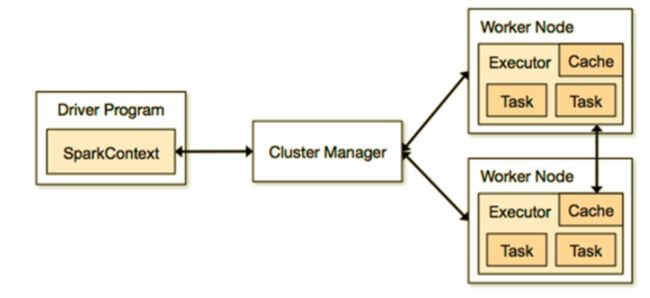
spark集群的web管理界面: http://master主机名:8080
spark-shell --master local[2]
Scala:
//1、构建sparkConf对象 设置application名称和master地址
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2、构建sparkContext对象,该对象非常重要,它是所有spark程序的执行入口
// 它内部会构建 DAGScheduler和 TaskScheduler 对象
val sc = new SparkContext(sparkConf)
//设置日志输出级别
sc.setLogLevel("warn")
sc.textFile("file:///home/hadoop/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect
spark--->List(1,1,1)
sc.textFile("file:///home/hadoop/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
val rdd1 = sc.parallelize(List(1,1,2,3,3,4,5,6,7))
Java:
//1、创建SparkConf对象
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount").setMaster("local[2]");
//2、构建JavaSparkContext对象
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
Spark Cluster 和 Client 模式的区别
yarn-cluster模式下提交任务示例:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/kkb/install/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
如果运行出现错误,可能是虚拟内存不足,可以添加参数
- vim yarn-site.xml
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn-client模式下提交任务示例:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/kkb/install/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
最大的区别就是Driver端的位置不一样。
yarn-cluster: Driver端运行在yarn集群中,与ApplicationMaster进程在一起。
yarn-client: Driver端运行在提交任务的客户端,与ApplicationMaster进程没关系,经常用于进行测试
Spark 的弹性分布式数据集 RDD(Resilient Distributed Dataset)
1、分区的列表
2、函数在每个分区上计算
3、一个RDD会依赖其他多个RDD
4、RDD的分区函数(hashPartitioner,RangerPartitioner)Option(Some,Node)
5、为了提高效率,存储每个partition位置可选,计算减少数据IO
- 掌握 Spark RDD 编程的算子 API(Transformation 和 Action 算子)
1、transformation算子
根据已经存在的rdd转换生成一个新的rdd, 它是延迟加载,它不会立即执行
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) | 重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner) | 重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
2、 action算子
它会真正触发任务的运行, 将rdd的计算的结果数据返回给Driver端,或者是保存结果数据到外部存储介质中
| 动作 | 含义 |
|---|---|
| reduce(func) | reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素, 比如说rdd的数据量达到了10G, rdd.collect这个操作非常危险,很有可能出现driver端的内存不足 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
spark connection to mysql
personRDD.foreachPartition( iter =>{
//把数据插入到mysql表操作
//1、获取连接
val connection: Connection = DriverManager.getConnection("jdbc:mysql://node03:3306/spark","root","123456")
//2、定义插入数据的sql语句
val sql="insert into person(id,name,age) values(?,?,?)"
//3、获取PreParedStatement
try {
val ps: PreparedStatement = connection.prepareStatement(sql)
//4、获取数据,给?号 赋值
iter.foreach(line =>{
ps.setString(1, line._1)
ps.setString(2, line._2)
ps.setInt(3, line._3)
//设置批量提交
ps.addBatch()
})
//执行批量提交
ps.executeBatch()
} catch {
case e:Exception => e.printStackTrace()
} finally {
if(connection !=null){
connection.close()
}
spark connection to Hbase
usersRDD.foreachPartition(iter =>{
//4.1 获取hbase的数据库连接
val configuration: Configuration = HBaseConfiguration.create()
//指定zk集群的地址
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181")
val connection: Connection = ConnectionFactory.createConnection(configuration)
//4.2 对于hbase表进行操作这里需要一个Table对象
val table: Table = connection.getTable(TableName.valueOf("person"))
//4.3 把数据保存在表中
try {
iter.foreach(x => {
val put = new Put(x(0).getBytes)
val puts = new util.ArrayList[Put]()
//构建数据
val put1: Put = put.addColumn("f1".getBytes, "gender".getBytes, x(1).getBytes)
val put2: Put = put.addColumn("f1".getBytes, "age".getBytes, x(2).getBytes)
val put3: Put = put.addColumn("f2".getBytes, "position".getBytes, x(3).getBytes)
val put4: Put = put.addColumn("f2".getBytes, "code".getBytes, x(4).getBytes)
puts.add(put1)
puts.add(put2)
puts.add(put3)
puts.add(put4)
//提交数据
table.put(puts)
})
} catch {
case e:Exception =>e.printStackTrace()
} finally {
if(connection !=null){
connection.close()
}
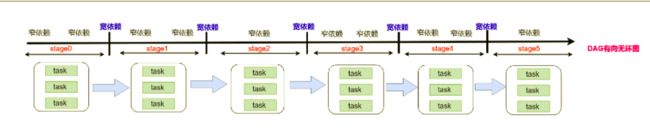
Spark DAG(有向无环图)
一个Job会被拆分为多组Task,每组任务被称为一个stage
stage表示不同的调度阶段,一个spark job会对应产生很多个stage(ShuffleMapStage,ResultStage)
由于划分完stage之后,在同一个stage中只有窄依赖,没有宽依赖,可以实现流水线计算,
stage中的每一个分区对应一个task,在同一个stage中就有很多可以并行运行的task。
划分完stage之后,每一个stage中有很多可以并行运行的task,后期把每一个stage中的task封装在一个taskSet集合中,最后把一个一个的taskSet集合提交到worker节点上的executor进程中运行。
rdd与rdd之间存在依赖关系,stage与stage之前也存在依赖关系,前面stage中的task先运行,运行完成了再运行后面stage中的task,也就是说后面stage中的task输入数据是前面stage中task的输出结果数据。
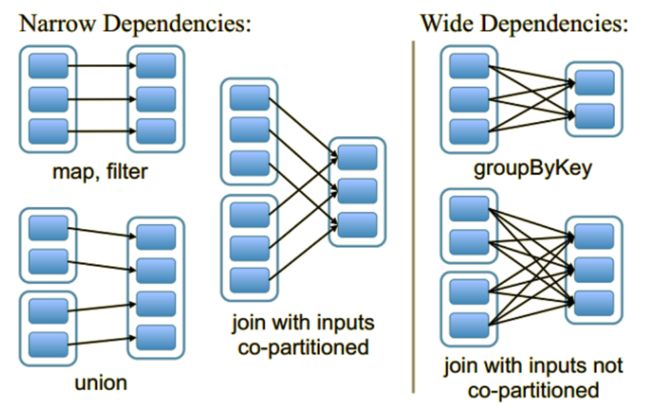
RDD 的依赖关系,什么是宽依赖和窄依赖
窄依赖(narrow dependency)和宽依赖(wide dependency)
所有的窄依赖不会产生shuffle
所有的宽依赖会产生shuffle
RDD 的血缘机制
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区
RDD的Lineage会记录RDD的元数据信息和转换行为,lineage保存了RDD的依赖关系,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
RDD 缓存机制
RDD通过persist方法或cache方法可以将前面的计算结果缓存, 程序运行完成后对应的缓存数据就自动消失
Spark 的任务调度和资源调度
任务调度: (1) Driver端运行客户端的main方法,构建SparkContext对象,在SparkContext对象内部依次构建DAGScheduler和TaskScheduler
(2) 按照rdd的一系列操作顺序,来生成DAG有向无环图
(3) DAGScheduler拿到DAG有向无环图之后,按照宽依赖进行stage的划分。每一个stage内部有很多可以并行运行的task,最后封装在一个一个的taskSet集合中,然后把taskSet发送给TaskScheduler
(4)TaskScheduler得到taskSet集合之后,依次遍历取出每一个task提交到worker节点上的executor进程中运行。
(5)所有task运行完成,整个任务也就结束了
资源调度: (1) Driver端向资源管理器Master发送注册和申请计算资源的请求
(2) Master通知对应的worker节点启动executor进程(计算资源)
(3) executor进程向Driver端发送注册并且申请task请求
(4) Driver端运行客户端的main方法,构建SparkContext对象,在SparkContext对象内部依次构建DAGScheduler和TaskScheduler
(5) 按照客户端代码洪rdd的一系列操作顺序,生成DAG有向无环图
(6) DAGScheduler拿到DAG有向无环图之后,按照宽依赖进行stage的划分。每一个stage内部有很多可以并行运行的task,最后封装在一个一个的taskSet集合中,然后把taskSet发送给TaskScheduler
(7) TaskScheduler得到taskSet集合之后,依次遍历取出每一个task提交到worker节点上的executor进程中运行
(8) 所有task运行完成,Driver端向Master发送注销请求,Master通知Worker关闭executor进程,Worker上的计算资源得到释放,最后整个任务也就结束了。
Spark 任务分析
参数:
==--executor-memory== : 表示每一个executor进程需要的内存大小,它决定了后期操作数据的速度
total-executor-cores: 表示任务运行需要总的cpu核数,它决定了任务并行运行的粒度
调度模式: FIFO,FAIR -> 根据权重不同来决定谁先执行
Spark 的 CheckPoint 和容错
可以把数据持久化写入到hdfs上, 程序运行完成后对应的checkpoint数据就不会消失
sc.setCheckpointDir("hdfs://node01:8020/checkpoint")
val rdd1=sc.textFile("/words.txt")
rdd1.checkpoint
val rdd2=rdd1.flatMap(_.split(" "))
rdd2.collect
- Spark 的通信机制
自定义分区: 继承==org.apache.spark.Partitioner==, 重写==numPartitions==方法, 重写==getPartition==方法
广播变量: ==传递到各个Executor的Task上运行==, 该Executor上的各个Task再从所在节点的BlockManager获取变量,而不是从Driver获取变量,以减少通信的成本,减少内存的占用,从而提升了效率.
SparkContext.accumulator(initialValue)
==累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。可以使用累加器来进行全局的计数==
“==org.apache.spark.SparkException: Task not serializable==”
spark的任务序列化异常 : 在编写spark程序中,由于在map,foreachPartition等算子==内部使用了外部定义的变量和函数==,从而引发Task未序列化问题.
Spark shuffle 原理分析
hashshuffle
sortShuffle
bypass-sortShuffle
(2)Spark Streaming:
- 原理剖析(源码级别)和运行机制
- Spark Dstream 及其 API 操作
- Spark Streaming 消费 Kafka 的两种方式
- Spark 消费 Kafka 消息的 Offset 处理
- 数据倾斜的处理方案
- Spark Streaming 的算子调优
- 并行度和广播变量
- Shuffle 调优
(3)Spark SQL:
- Spark SQL 的原理和运行机制
- Catalyst 的整体架构
- Spark SQL 的 DataFrame
- Spark SQL 的优化策略:内存列式存储和内存缓存表、列存储压缩、逻辑查询优化、Join 的优化
(4)Structured Streaming
Spark 从 2.3.0 版本开始支持 Structured Streaming,它是一个建立在 Spark SQL 引擎之上可扩展且容错的流处理引擎,统一了批处理和流处理。正是 Structured Streaming 的加入使得 Spark 在统一流、批处理方面能和 Flink 分庭抗礼。
我们需要掌握:
- Structured Streaming 的模型
- Structured Streaming 的结果输出模式
- 事件时间(Event-time)和延迟数据(Late Data)
- 窗口操作
- 水印
- 容错和数据恢复
- Spark Mlib:
本部分是 Spark 对机器学习支持的部分,我们学有余力的同学可以了解一下 Spark 对常用的分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。可以尝试自己使用 Spark Mlib 做一些简单的算法应用。