1.hive> show functions;
这些都是内置的函数
如何查看函数怎么使用?
1)hive> desc function upper;

2)hive> desc function extended upper;

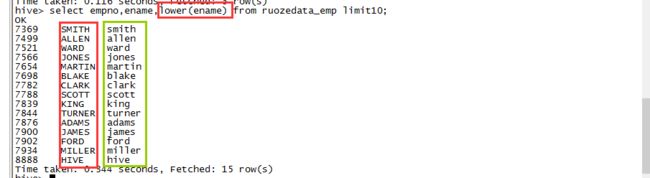
试用一下lower函数
hive> select empno,ename,lower(ename) from ruozedata_emp limit10;
2.常用函数
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
首先建一张表格
hive> create table dual(x string);
hive> insert into table dual values('');

0)from_unixtime函数 用法为将时间戳转换为时间格式
语法: from_unixtime(bigint unixtime[, string format]) 返回值为string
例如 hive>select from_unixtime(1326988805,'yyyyMMddHH') from test;
如果为字段转换的话,则为 select from_unixtime(time,'yyyyMMddHH') from test;
字段time如果为string类型,应该转换为int类型 select from_unixtime(cast(time as int),'yyyyMMddHH') from test;
1)hive> select unix_timestamp() from dual;
OK
1529248169
获取当前时间的时间戳

hive> select unix_timestamp("2018-08-08 20:08:08") from dual;
OK
1533730088

2)hive> select current_date from dual;
OK
2018-06-17
3)hive> select current_timestamp from dual;
OK
2018-06-17 23:13:47.207
4)hive> select to_date("2018-08-08 20:08:08") from dual;
OK
2018-08-08
5)hive> select year("2018-08-08 20:08:08") from dual;
OK
2018
hive> select month("2018-08-08 20:08:08") from dual;
OK
8
hive> select day("2018-08-08 20:08:08") from dual;
OK
8
hive> select hour("2018-08-08 20:08:08") from dual;
OK
20
hive> select minute("2018-08-08 20:08:08") from dual;
OK
8
hive> select second("2018-08-08 20:08:08") from dual;
OK
8
这些函数,在分区的时候会用得到
6)hive> select date_add("2018-08-08",10) from dual;
OK
2018-08-18
hive> select date_sub("2018-08-08",10) from dual;
OK
2018-07-29
7)hive> select cast(current_timestamp as date) from dual;
OK
2018-06-17
进行类型转换的函数
8)hive> select substr("abcdefg",2) from dual;
OK
bcdefg
hive> select substr("abcdefg",2,3) from dual;
OK
bcd

9)把字符串连起来

10)按指定的分隔符把字符串连起来

hive> select concat_ws(".","192","168","137","141") from dual;
OK
192.168.137.141
11)hive> select length("192.168.137.141") from dual;
OK
15
12)

hive> select split("192.168.137.141","\\.") from dual;
OK
["192","168","137","141"]
3.explode
hive> select * from hive_wc;
hive> select split(sentence,",") from hive_wc;
hive> select explode(split(sentence,",")) from hive_wc;

hive> select word, count(1) as c
> from (select explode(split(sentence,",")) as word from hive_wc) t
> group by word;

4.json_tuple

hive> create table rating_json(json string);
hive> load data local inpath '/home/hadoop/data/rating.json' into table rating_json;
hive> select * from rating_json limit 10;

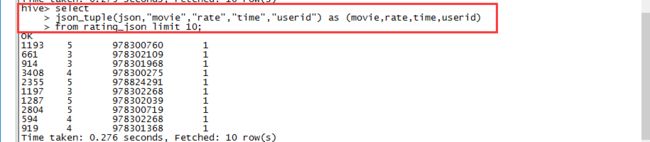
hive> select
> json_tuple(json,"movie","rate","time","userid") as (movie,rate,time,userid)
> from rating_json limit 10;
5.分析函数
hive> create table hive_rownumber(id int,age int, name string, sex string)
> row format delimited fields terminated by ',';
hive> load data local inpath '/home/hadoop/data/hive_row_number.txt' into table hive_rownumber;
hive> select * from hive_rownumber;

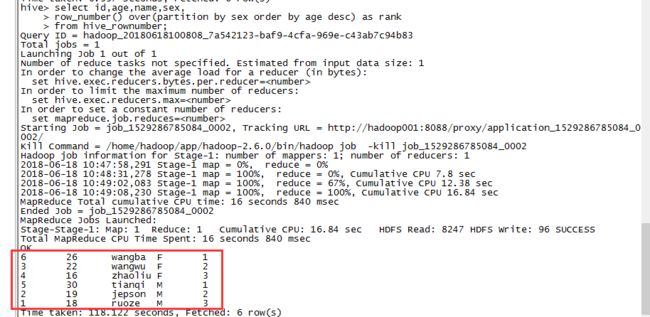
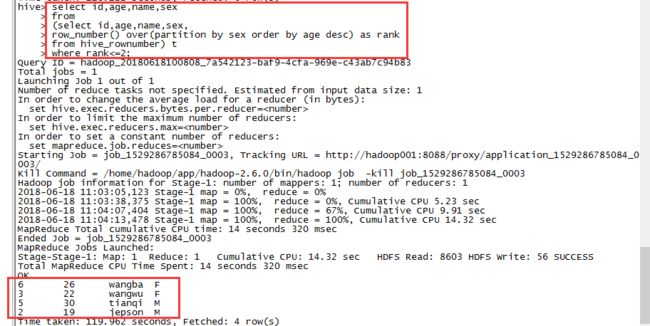
Q:查询出每种性别中年龄最大的2条数据
A:首先我们先按性别分组并按年龄降序排列
hive> select id,age,name,sex,
> row_number() over(partition by sex order by age desc) as rank
> from hive_rownumber;
然后取出rank<=2的数据
hive> select id,age,name,sex
> from
> (select id,age,name,sex,
> row_number() over(partition by sex order by age desc) as rank
> from hive_rownumber) t
> where rank<=2;
6.用户自定义函数UDF(User-Defined Functions)
UDF: 一进一出 upper lower substring
UDAF:Aggregation聚合函数 多进一出 count max min sum ...
UDTF: Table-Generation 一进多出
在此使用idea编了一个jar包hive-1.0.jar,rz至/home/hadoop/lib/目录下,里边自定义了函数sayhello
hive> add jar /home/hadoop/lib/hive-1.0.jar;
hive> CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
hive> show functions;

试一下函数能不能用
hive> show databases;
hive> use ruozedata;
hive> show tables;
hive> select sayhello("ruoze") from dual;

这种方式添加的函数是临时的,只对当前session(黑窗口)有效,重新打开一次hive就失效了,所以我们需要创建一个永久的函数
[hadoop@hadoop001 lib]$ hdfs dfs -mkdir /lib
[hadoop@hadoop001 lib]$ hdfs dfs -put hive-1.0.jar /lib
[hadoop@hadoop001 lib]$ hdfs dfs -ls /lib
Found 1 items
-rw-r--r-- 1 hadoop supergroup 3219 2018-06-18 12:22 /lib/hive-1.0.jar
hive> CREATE FUNCTION sayRuozeHello AS 'com.ruozedata.bigdata.HelloUDF'
> USING JAR 'hdfs://192.168.137.141:9000/lib/hive-1.0.jar';

hive> list jars;
hive> show functions;
hive> select ruozedata.sayruozehello("ruoze") from dual;
OK
Hello:ruoze
打开一个新的窗口后,经试验也是可以使用的
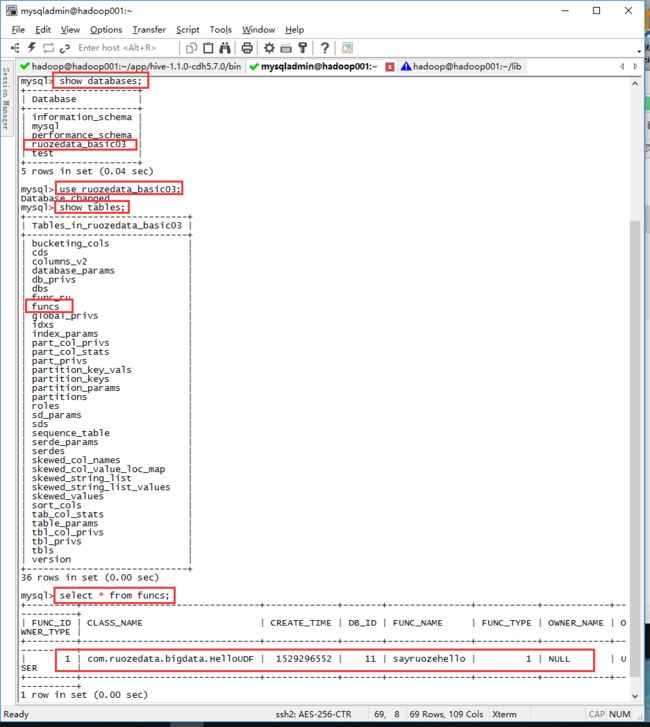
验证一下mysql里有没有这个函数
mysql> show databases;
mysql> use ruozedata_basic03;
mysql> show tables;
mysql> select * from funcs;
Q:
输入

要求输出:userid,movie,rate,time(时间戳格式), year,month,day,hour,minute,ts(格式:'%Y-%m-%d %H:%i:%s')
A:
hive> create table rating_json(json string);
hive> load data local inpath '/home/hadoop/data/rating.json' into table rating_json;
hive> select a.userid,a.movie,a.rate,a.time,year(b.ts) year,month(b.ts) month,day(b.ts) day,hour(b.ts) hour,minute(b.ts) minute,b.ts from
> (select from_unixtime(cast(time as int)) ts from
> (select json_tuple(json,"userid","movie","rate","time") as (userid,movie,rate,time) from rating_json limit 10) a
> ) b;
