1. 集群规划:
192.168.1.11 wkh11 Namenode+Datanode
192.168.1.12 wkh12 YarnManager+Datanode+SecondaryNameNode
192.168.1.13 wkh13 Datanode
2. 设定固定IP地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
UUID=7ac09286-c35b-4f15-a9ba-701c093832bf
DEVICE=eth0
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_PRIVACY=no
ONBOOT=yes
DNS1=192.168.1.1
IPADDR=192.168.1.11 #三台机器都要分别设置
PREFIX=24
GATEWAY=192.168.1.1
3. 修改主机名:
192.168.1.11
hostnamectl set-hostname wkh11
hostnamectl --static set-hostname wkh11
192.168.1.12
hostnamectl set-hostname wkh12
hostnamectl --static set-hostname wkh12
192.168.1.13
hostnamectl set-hostname wkh13
hostnamectl --static set-hostname wkh13
注意:hostnamectl 在 redhat6.5还不存在,需要用如下方式修改主机名
vi /etc/sysconfig/network
#修改HOSTNAME项
HOSTNAME=XXX
#重启network服务:
service network restart
#或者执行命令
hostname XXX
4. 修改hosts文件
vi /etc/hosts
127.0.0.1 localhost
192.168.1.11 wkh11
192.168.1.12 wkh12
192.168.1.13 wkh13
5. 安装JDK(所有节点)
具体到oracle官网下载
6. SSH免密登录
A) 每台机器生成访问秘钥,复制到192.168.1.11:/home/workspace目录下
192.168.1.11:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
cp ~/.ssh/authorized_keys /home/workspace/authorized_keys11
rm -rf ~/.ssh/authorized_keys #删除公钥文件
192.168.1.12:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys 192.168.1.11:/home/workspace/authorized_keys12
rm -rf ~/.ssh/authorized_keys #删除公钥文件
192.168.1.13:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys 192.168.1.11:/home/workspace/authorized_keys13
rm -rf ~/.ssh/authorized_keys #删除公钥文件
B) 在192.168.1.11上将所有的公钥合并成一个公钥文件
cat /home/workspace/authorized_keys11 >> /home/workspace/authorized_keys
cat /home/workspace/authorized_keys12 >> /home/workspace/authorized_keys
cat /home/workspace/authorized_keys13 >> /home/workspace/authorized_keys
C) 将合并后的公钥文件复制到集群中的各个主机中
scp /home/workspace/authorized_keys 192.168.1.12:~/.ssh/
scp /home/workspace/authorized_keys 192.168.1.13:~/.ssh/
cp /home/workspace/authorized_keys ~/.ssh/ #因为目前在11主机中,所以使用的命令为cp而不是scp
注:也可以借助 ssh-copy-id -i ~/.ssh/id_rsa.pub {ip or hostname}来往远程机器复制公钥
以本集群的配置为例,以上ABC三步的操作亦可以通过下面的操作来完成,操作方法如下:
192.168.1.11,192.168.1.12,192168.1.13 均做以下操作,就完成了私钥的生成,公钥的分发
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #生成本机公钥和私钥
ssh-copy-id -i ~/.ssh/id_rsa.pub wkh11 #复制本机的公钥到wkh11机器上,默认会存储在远程机器的~/.ssh/authorized_keys文件中,如果此文件不存在,会创建该文件
ssh-copy-id -i ~/.ssh/id_rsa.pub wkh12 #复制本机的公钥到wkh11机器上,默认会存储在远程机器的~/.ssh/authorized_keys文件中,如果此文件不存在,会创建该文件
ssh-copy-id -i ~/.ssh/id_rsa.pub wkh13 #复制本机的公钥到wkh11机器上,默认会存储在远程机器的~/.ssh/authorized_keys文件中,如果此文件不存在,会创建该文件
D) 每台机器:
chmod 755 ~ #当前用户根目录访问权限
chmod 700 ~/.ssh/ #.ssh目录权限
chmod 600 ~/.ssh/id_rsa #id_rsa的访问权限
chmod 644 ~/.ssh/id_rsa.pub #id_rsa.pub的访问权限
chmod 644 ~/.ssh/authorized_keys #authorized_keys的访问权限
说明:
如果ssh 登录的时候失败或者需要密码才能登陆,可以查看sshd的日志信息。日志信息目录为,/var/log/secure
你会发现如下字样的日志信息。
Jul 22 14:20:33 v138020.go sshd[4917]: Authentication refused: bad ownership or modes for directory /home/edw
则需要设置权限:sshd为了安全,对属主的目录和文件权限有所要求。如果权限不对,则ssh的免密码登陆不生效。
用户目录权限为 755 或者 700,就是不能是77x。
.ssh目录权限一般为755或者700。
rsa_id.pub 及authorized_keys权限一般为644
rsa_id权限必须为600
可通过来查看ssh过程中的日志.
cat /var/log/secure
7. 配置hadoop
7-1) 解压
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
tar xzvf hadoop-2.7.3.tar.gz -C /opt/
7-2) 创建存放数据的目录(必须事先创建好,否则会报错)
mkdir -p /opt/hadoop-2.7.3/data/full/tmp/
mkdir -p /opt/hadoop-2.7.3/data/full/tmp/dfs/name
mkdir -p /opt/hadoop-2.7.3/data/full/tmp/dfs/data
7-3) 配置/opt/hadoop-2.7.3/etc/hadoop下面的配置文件
cd opt/hadoop-2.7.3/etc/hadoop #定位到配置文件目录
7-3-1) core-site.xml
fs.defaultFS
hdfs://wkh11:9000
The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
hadoop.tmp.dir
file:/opt/hadoop-2.7.3/data/full/tmp
是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中
dfs.webhdfs.enabled
true
启用 webhdfs
7-3-2) yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
wkh12
yarn.resourcemanager.address
wkh12:8032
yarn.resourcemanager.scheduler.address
wkh12:8030
yarn.resourcemanager.resource-tracker.address
wkh12:8031
yarn.nodemanager.resource.memory-mb
10240
yarn.scheduler.minimum-allocation-mb
1024
yarn.nodemanager.vmem-pmem-ratio
2.1
7-3-3) slaves
wkh11
wkh12
wkh13
7-3-4) mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
wkh11:10020
mapreduce.jobhistory.webapp.address
wkh11:19888
7-3-5) hdfs-site.xml
dfs.replication
1
不能大于datanode的数量,默认为3
dfs.namenode.secondary.http-address
wkh12:50090
dfs.data.dir
file:/opt/hadoop-2.7.3/data/full/tmp/dfs/data
用于确定将HDFS文件系统的数据保存在什么目录下,可以将这个参数设置为多个分区上目录,即可将HDFS建立在不同分区上。
dfs.name.dir
file:/opt/hadoop-2.7.3/data/full/tmp/dfs/name
这个参数用于确定将HDFS文件系统的元信息保存在什么目录下,如果这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份.
hadoop.proxyuser.hadoop.hosts
*
配置成*的意义,表示任意节点使用 hadoop 集群的代理用户hadoop 都能访问 hdfs 集群
hadoop.proxyuser.hadoop.groups
*
代理用户所属的组
7-3-6) hadoop-env.sh
配置JAVA_HOME
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
8. 配置环境变量(每台机器都必须做)
vi /etc/profile
在文件尾部添加:
#####set jdk enviroment
export JAVA_HOME=/usr/java/jdk1.8.0_172-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
##### set hadoop_home enviroment
export HADOOP_HOME=/opt/hadoop-2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
###enable hadoop native library
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
命令行终端执行 source /etc/profile,让配置的环境变量生效
source /etc/profile ####make the env variable to take effect right now.
9. 启动:
9-1) 启动hdfs: namenode节点(11)
格式化namenode
hdfs namenode -format
启动hdfs
start-dfs.sh # (master 11)
9-2) 启动Yarn: yarn节点(12)
#注意:Namenode和ResourceManger如果不是同一台机器,
#不能在NameNode上启动 yarn,
#应该在ResouceManager所在的机器上启动yarn。
start-yarn.sh
#验证启动情况:
jps #查看java进程
[root@wkh11 hadoop]# jps
21458 DataNode
21110 QuorumPeerMain
16809 NameNode
24765 Jps
[root@wkh12 ~]# jps
30261 SecondaryNameNode
31941 DataNode
30616 ResourceManager
2056 Jps
20973 QuorumPeerMain
[root@wkh13 ~]# jps
9525 NodeManager
20981 QuorumPeerMain
9414 DataNode
13575 Jps
http://ResourceManager:8088/
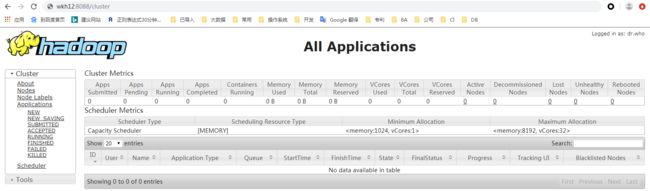
http://NameNode:50070/
//TODO 暂时访问失败
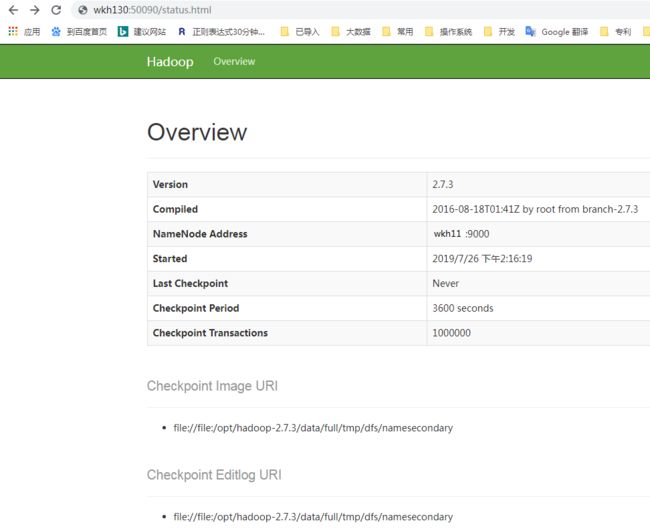
http://SecondaryNameNode:50090/
10 Hadoop启动停止方式
1)各个服务组件逐一启动
分别启动hdfs组件: hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
启动yarn: yarn-daemon.sh start|stop resourcemanager|nodemanager
2)各个模块分开启动(配置ssh是前提)常用
start|stop-dfs.sh start|stop-yarn.sh
3)全部启动(不建议使用)
start|stop-all.sh