再谈KMP算法
KMP算法的三种匹配方法
文章目录
- KMP算法的三种匹配方法
-
-
-
- KMP算法方法一:前缀表匹配查找
- 方法二:next[]数组法
- 方法三:改进的next[]数组,即nextval[]数组法
-
-
声明:
这三种匹配方式分别为:真前缀表、next[]数组、nextval[]数组匹配,其中真前缀表与next[]数组平级,复杂度相同,而nextval[]为next[]的升级版,时间复杂度相比前两者有显著降低。
…
对于真前缀表,仅给出一种格式,即无论待匹配长串、还是待匹配短串,其数组下标均是从0开始
对于next[]数组和nextval[]数组给出两种格式,一种待匹配长串、还是待匹配短串,其数组下标均是从0开始,另一种待匹配长串、还是待匹配短串,其数组下标均是从1开始。
…
其实我个人认为字符数组下标从0开始看起来更舒服,也更符合逻辑,但是有的人认为下标从1开始方便,可以巧妙避免很多问题的出现…所以我勉为其难地把字符数组下标为1的格式列了出来,这波也算是致敬著有《大话数据结构》的程杰老师。
KMP算法方法一:前缀表匹配查找
小目录:
1. 求出前缀表继而得到真前缀表
2. 根据前缀表进行匹配查找
1. 求出前缀表继而得到真前缀表
*以下所讲的子串均不包含其自身*
//简介前缀表:前缀表即待匹配短串的子串的前缀,这句话中说,举例如下
待匹配短串:ababax
其全部子串为:a、ab、aba、abab、ababa,这5子串对一一应一个前缀值
前缀值就是该子串的最大前后公共子串的长度,举例介绍一下前缀值:
以上面 5个子串中其一abab为例:
因为子串不包括自身,所以前、后子串最长为3,前子串应该是aba(1-3),后子串应该是bab(2-4)
因为前子串不等于后子串,所以不能称之为“公共子串”,所以abab的前缀值不等于3
我们减少该前后子串长度,变为2,这时前子串是ab(1-2),后子串是ab(3-4),前子串等于后子串
所以对于abab来说公共子串是ab,长度为2,故abab的前缀值为2,由此可得对应前缀表:
(待匹配短串的)子串 前缀值 对应公共子串
a 0 无
ab 0 无
aba 1 a
abab 2 ab
ababa 3 aba
ababax 0 无
注:该项为了观感,(串自身)其实不应该出现
得到前缀表(prefixtable)数组: prefix[] = {0, 0, 1, 2, 3, 0}
接下来对前缀表进行加工,使其变为真前缀表,规则如下:
前缀表所有前缀值后移一位,最后一位数据(即上述ababax的前缀值)被覆盖
将前缀表首位赋值为-1,得到真前缀表,显示如下:
prefix[] = {-1, 0, 0, 1, 2, 3}
2. 根据真前缀表进行匹配查找:见如下代码
#include 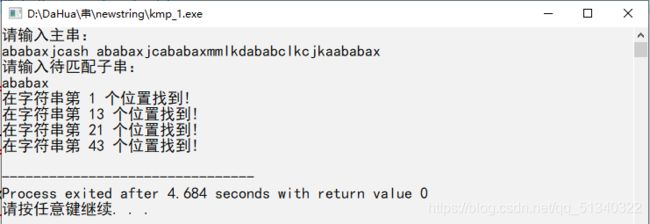
注:为了让字符串下标从1开始,为了方便,我们在输入时多输入一个空格,该空格起占位作用,但是在查找时,不算有效字符,以该空格后一个字符作为第一个字符位置
方法二:next[]数组法
关于next数组法,我简单介绍一下,借用《大话数据结构》的公式进行说明
{ 0 , j = 1;
next[j] = { Max{k|1- 两字符串下标从1开始的,next[]数组法
#include 
- 两字符串下标从0开始的,next[]数组法
#include 
小结:下标从字符串1开始确实方便很多的操作,如上所示,无论是在求next[]数组,还是利用next[]数组进行匹配查找的过程中,下标从0开始会遇到一些小问题,你可以看一下,下标从0开始算next[]数组,其实是利用另一种思路求得“伪next[]”,再加工(next[i] = next[i] + 1)这一步得到的,在匹配过程中就更显麻烦了。
方法三:改进的next[]数组,即nextval[]数组法
关于nextval[]数组的求法,这里简单介绍一下,这里的next[]数组与上面的next[]数组均出自程杰的《大话数据结构》
next[]转 -- nextval[]规则:字符串下标从1开始
{ 0; j = 1
nextval[j]= { next[j]; str[next[j]] = str[j] && j > 1
{ nextval[next[j]]; 其他情况
举例说明如下:
j = 1 2 3 4 5 6 7 8 9
str: a b a b a a a b a
next[j]: 0 1 1 2 3 4 2 2 3
nextval[j]: 0 1 0 1 0 4 2 1 0
/* str为待匹配短串 */
当 j = 1 时, nextval[1] = 0;
当 j = 2 时, 因为第二位字符"b"的next值为1,而第一位就是“a”,它们不相等,
故nextval[2] = next[2] = 1, nextval[2]继承next[2]原值
当 j = 3时, 因为第三位字符“a”的next值为1,而第一位就是"a",它们相等,
故nextval[3] = nextval[1] = 0;
...
以此类推,可得nextval[]数组的所有值
- 两字符串下标从1开始的,nextval[]数组法
#include 
2.两字符串下标从0开始的,nextval[]数组法
#include 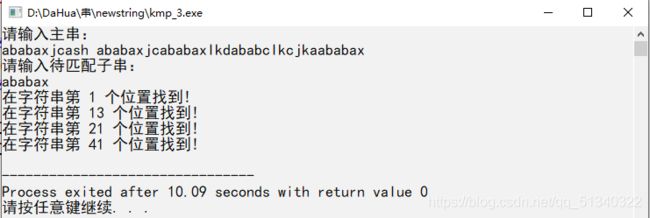
总结: 真前缀表的方法可以直接套用,没有什么好说的。重点在于next[]数组、nextval[]数组的方法,尽管求next[]数组、nextval[]数组的方法是多样的,但其模式可归纳为两部分:求next/nextval数组、依照求得数组回溯规则匹配字符串
因为求next[]/nextval[]数组方法很多,这里不在赘述
next[]数组/nextval[]数组 + 匹配模板
- 字符串下标从0开始
//求出next[]数组后,可套匹配模板,当然要根据
//你的实际情况进行改动这里仅作为一个参照
j = 0, i = 0;
while (i < m)//m为主字符串长度, n为短串长度
{
if (j == n - 1 && text[i] == str[j])
{
printf("在字符串第 %d 个位置找到!\n", i - j + 1);
++i, j = 0;
}
if (text[i] == str[j]) ++ i, ++ j;//text为主字符串,str为短串
else
{
if (j == 0) ++ i;
else j = next[j-1];
}
}
- 字符串下标从1开始
//这里注释与上面一样
j = 1, i = 1;
while (i < m)
{
if (j == n - 1 && text[i] == str[j])
{
printf("在字符串第 %d 个位置找到!\n", i - j + 1);
j = 0;
}
if (j == 0 || text[i] == str[j]) ++ i, ++ j;
else j = next[j];
}
由此可见,同模式(即字符串起点相同)只要next[],可以运行,那么只需在匹配模板中将next[]改为nextval[]即可
所以,next[]数组方法 —> nextval[]数组法,仅仅需要在原来next[]数组法的基础上,加一步next[]转化nextval[],并将查找匹配模块中的next[]改为nextval[]即可
最后,如果您对于next[]、nextval[]数组的多种求法感兴趣,不妨移步至我之前的一篇博客,里面具体介绍了该数组的计算方法。点击可至