Flink 1.12.0学习与分享(pyflink)
Flink 1.12.0学习与分享
1. 大数据实时计算引擎历史
- 第一代, 以Storm为代表, 高吞吐,低延迟,但精确一次消费以及开发维护便捷性,生态完善度等相对欠缺一些.
- 第二代,以Spark 为代表, 高吞吐, 牺牲了一些延迟(微批次理念), 结合第三方框架, 可以很好实现精确一次消费. 开发维护便捷性, 生态完善度都非常好.
- 第三代, 以Flink为代表, 设计时就以实时计算为出发点, 高吞吐,低延迟,精确一次消费语义支持, 开发维护便捷性, 生态完善度都非常好
生态完善度:
各类编程语言支持, SQL支持, 和其他大数据框架集成如Hadoop, 消息队列如Kafka, Hive, Hbase, Mysql, 监控体系等等
2. Flink是什么
- 在无界和有界数据流上进行状态计算的框架和分布式处理引擎。 Flink 已经可以在所有常见的集群环境中运行,并以 in-memory 的速度和任意的规模进行计算.
注意, 在大数据计算引擎,最典型是mapreduce(计算中间结果会大量落地磁盘, 性能较慢, 但很稳定)
后续的Spark, 除了shuffle时会落地磁盘,其他场景不会, 这样尽可能将中间结果放在内存, 计算会快很多,因为减少了和磁盘IO的性能消耗
再后续的Flink, 以及OLAP领域的内存计算引擎如Impala, Presto等都尽可能在计算时不做磁盘IO(并不是没有磁盘IO). 这样就很好利用了内存的高速存储特性, 极大提升了数据计算性能.–同样的, 不稳定性以及对硬件高配置要求也自然而然发生, 这是需要实际开发时特别注意的.
- API层级设计
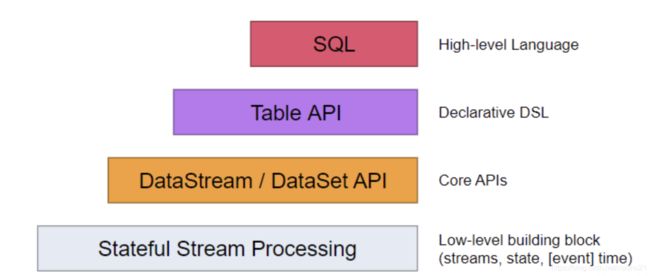
注意, 因为Flink本身基于Java和Scala开发, 所以目前各个层级API对这2个语言支持最好也是最快, Python目前最新的1.12支持SQL, Table以及DataStream, 但更底层的Process Function级别还不支持
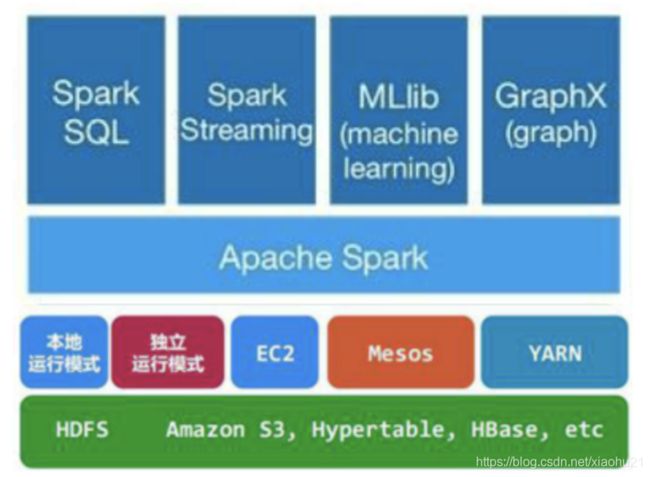
Spark的API 层级设计也类似, 最底层是RDD(更底层就是各类Function), 再之上有DataSet, DataStream, 基于此之上,有SQL层, Structed Streaming层. 图计算,机器学习,Streaming则是基于RDD进行封装.
- Flink 模块和架构层级设计

注意, Gelly, FlinkML, CEP等模块并没有包括在Flink内部,开发时, 需要在pom文件中引入, 框架本身集成也需要做处理. 这一点和Spark框架是一致的, 提供出来的包是最小化功能, 需要其他功能再进一步扩展集成即可.
对照一下Spark的模块划分
- Flink 发布渠道
- Apache Bahir 官网
- Ververica 官网
- Flink 官网 官网
- Maven
- SBT
- 等等
注意, Flink是一个开源产品, 为了降低Flink开发中项目规模, Flink将很多模块拆分出来,也利用了开源社区很多现有模块如Zookeeper, Calcite等
3. Flink如何安装
环境要求:
- Java 8
- Flink发布包 官网下载
- 尽可能是Linux, Mac os等操作系统环境
- local模式安装
- 下载Flink 的安装包, 解压缩到自己的安装目录下
- 在Flink安装目录的bin目录下,调用
# 启动
bin/start-cluster.sh
# 关闭
bin/stop-cluster.sh
- 集群部署
- 3种模式(https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/)
- Application Mode,
- Per-Job Mode,
- Session Mode.
- 参考博客
- https://blog.csdn.net/qq_38058332/article/details/108227900
- https://www.jianshu.com/p/1b05202c4fb6
- 容器化集群部署
同样的模式,但需要使用K8s和docker技术,这也是被阿里巴巴验证实际可行并且支撑业务发展的方式
- 安装目录简介
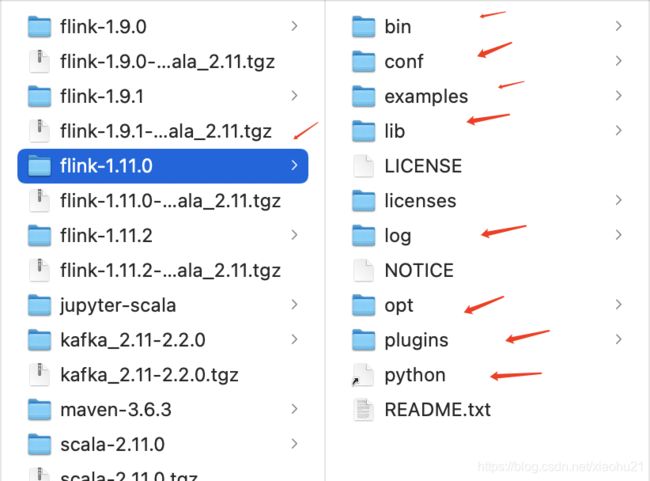
经典的文件目录命名
bin, 可执行文件目录

conf, 配置文件所在
examples, 演示案例(入门是足够的,但对比实际开发还是需要去github上寻找更多案例代码学习)
lib, 第三方依赖
log, 日志所在
opt, 第三方可选依赖所在
plugins, 第三方插件支持, 如对GPU, FPGA等的支持
另, 因为Flink本身属于美国Apache基金会旗下开源项目,是受到美国出口管制的, 从法律上来说, 美国政府可以要求禁止Apache向中国出口Flink,虽然是开源的,免费的.

4. Flink如何使用
4.1 Table&SQL API
- wordcount
# coding=utf-8
import os
import shutil
from pyflink.table import BatchTableEnvironment, EnvironmentSettings
from pyflink.table import DataTypes
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
# 批处理模式, 因为blink palnner更加强大,批流都支持sql,特性也更加丰富,官方也推荐使用blink planner
env_set = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
env = BatchTableEnvironment.create(environment_settings = env_set)
# 设置python执行环境为python3
env.get_config().set_python_executable("python3")
source_word= '/Users/hulc/PycharmProjects/pyflink_1/com/hajk/wordcount/word.csv'
# os.path.join(os.path.abspath(os.path.dirname(__file__)), 'word.csv')
env.execute_sql("""
CREATE TABLE source(
id BIGINT,
word STRING
) with (
'connector' = 'filesystem',
'path' = '/Users/hulc/PycharmProjects/pyflink_1/com/hajk/wordcount/word.csv',
'format' = 'csv'
)""")
sink_word = '/Users/hulc/PycharmProjects/pyflink_1/com/hajk/wordcount/result.csv'
# os.path.join(os.path.abspath(os.path.dirname(__file__)), 'result.csv')
if os.path.exists(sink_word):
if os.path.isfile(sink_word):
os.remove(sink_word)
else:
shutil.rmtree(sink_word, True)
env.execute_sql("""
CREATE TABLE sink (
word STRING,
cnt BIGINT
) WITH (
'connector' = 'filesystem',
'path' = '/Users/hulc/PycharmProjects/pyflink_1/com/hajk/wordcount/result.csv',
'format' = 'csv'
)
""")
env.execute_sql("""
INSERT INTO sink
SELECT
word,
count(1) as cnt
FROM
source
GROUP BY word
""")
数据
0,flink
1,pyflink
2,flink
3,pyflink
4,flink
- UDF
# coding=utf-8
from pyflink.table import EnvironmentSettings, StreamTableEnvironment, udf
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import TableFunction
from pyflink.table.types import DataTypes
from pyflink.table.udf import udtf
env_stream = StreamExecutionEnvironment.get_execution_environment()
env_table = StreamTableEnvironment.create(env_stream)
class Split(TableFunction):
def eval(self, string):
for s in string.split(" "):
yield s, len(s)
table_src = env_table\
.from_elements([('sad asd erf wer', 2), ('ert tyu uiyer ert', 3)], schema=DataTypes.ROW([DataTypes.FIELD('a', DataTypes.STRING()), DataTypes.FIELD('b', DataTypes.INT())]))
split = udtf(Split(), result_types = [DataTypes.STRING(), DataTypes.INT()])
result1 = table_src.join_lateral(split(table_src.a).alias("word", "length"))
# print(result1.to_pandas())
result2 = table_src.left_outer_join_lateral(split(table_src.a).alias("word", "length"))
# print(result2.to_pandas())
# sql 中使用
env_table.create_temporary_function('split', udtf(Split(), result_types=[DataTypes.STRING(), DataTypes.INT()]))
env_table.create_temporary_view('view_src', table_src)
result3 = env_table.sql_query("""
SELECT
a,
word,
length
FROM
view_src,
LATERAL TABLE(split(a)) as T(word, length)
""")
# print(result3.to_pandas())
result4 = env_table.sql_query("""
SELECT
a,
word,
length
FROM
view_src
LEFT JOIN
LATERAL Table(split(a)) as T(word, length)
ON TRUE
""")
print(result4.to_pandas())
备注(多种UDF定义和使用方式)
# coding=utf-8
import functools
from pyflink.table.types import DataTypes
from pyflink.table.udf import udf
from pyflink.table.udf import ScalarFunction
from pyflink.table import BatchTableEnvironment, EnvironmentSettings
# 继承基类ScalarFunction
class Add(ScalarFunction):
def eval(self, i, j):
return i + j
add = udf(Add(), result_type=DataTypes.BIGINT())
# 普通python函数,但是加udf注解
@udf(result_type=DataTypes.BIGINT())
def add2(i, j):
return i + j
# lambda函数
add3 = udf(lambda i, j: i + j, result_type=DataTypes.BIGINT())
# callable函数
class CallabelAdd(object):
def __call__(self, i, j):
return i + j
add4 = udf(CallabelAdd(), result_type=DataTypes.BIGINT())
# partial 函数
def partial_add(i, j, k):
return i + j + k
add5 = udf(functools.partial(partial_add, k=1), result_type=DataTypes.BIGINT())
# 定义后,还需要注册
env = BatchTableEnvironment.create(
environment_settings=EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build())
env.create_temporary_function('add', add)
# 如果是table api--dsl风格,则可以直接使用python自定义函数,不需要提前注册
- Kafka source 和Kafka sink
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
def log_processing():
env = StreamExecutionEnvironment.get_execution_environment()
env_settings = EnvironmentSettings.Builder().use_blink_planner().build()
t_env = StreamTableEnvironment.create(stream_execution_environment=env, environment_settings=env_settings)
# specify connector and format jars
t_env.get_config().get_configuration().set_string("pipeline.jars",
"file:///my/jar/path/connector.jar;file:///my/jar/path/json.jar")
source_ddl = """
CREATE TABLE source_table(
a VARCHAR,
b INT
) WITH (
'connector' = 'kafka',
'topic' = 'source_topic',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'test_3',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
)
"""
sink_ddl = """
CREATE TABLE sink_table(
a VARCHAR
) WITH (
'connector' = 'kafka',
'topic' = 'sink_topic',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json'
)
"""
t_env.execute_sql(source_ddl)
t_env.execute_sql(sink_ddl)
t_env.sql_query("SELECT a FROM source_table") \
.execute_insert("sink_table").wait()
if __name__ == '__main__':
log_processing()
- 多种创建environment方法
# coding=utf-8
from pyflink.table import StreamTableEnvironment, BatchTableEnvironment, EnvironmentSettings
# 注意,mode和对应Environment都是对应的,混合会报错
# 流,blink
env_setting1 = EnvironmentSettings.new_instance().use_blink_planner().in_streaming_mode().build()
env1 = StreamTableEnvironment.create(environment_settings = env_setting1)
# 流 flink
env_setting2 = EnvironmentSettings.new_instance().use_old_planner().in_streaming_mode().build()
env2 = StreamTableEnvironment.create(environment_settings = env_setting2)
# 批 blink
env_setting3 = EnvironmentSettings.new_instance().use_blink_planner().in_batch_mode().build()
env3 = BatchTableEnvironment.create(environment_settings=env_setting3)
# 批 flink
env_setting4 = EnvironmentSettings.new_instance().in_batch_mode().use_old_planner().build()
env4 = BatchTableEnvironment.create(env_setting4)
4.2 DataStream
- 简单sink
# coding=utf-8
from pyflink.common.serialization import SimpleStringEncoder
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import StreamingFileSink
import os
import shutil
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds = env.from_collection(
collection=[(1, 'jack'), (2, 'rose'), (3, 'laowang'), (4, 'laoli')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
result_path = '/Users/hulc/PycharmProjects/pyflink_1/com/hajk/datastream/result'
if os.path.exists(result_path):
if os.path.isfile(result_path):
os.remove(result_path)
else:
shutil.rmtree(result_path, True)
ds.add_sink(StreamingFileSink.for_row_format(result_path, SimpleStringEncoder()).build())
env.execute('datastream test1')
# 执行脚本
# /Users/hulc/Library/Python/3.8/lib/python/site-packages/pyflink/bin/flink run -m localhost:8081 -py /Users/hulc/PycharmProjects/pyflink_1/com/hajk/datastream/Test_blink_stream_table.py
4.3 DataSet

考虑到Flink未来Api规划–批流一体, 所以按照官方建议, 直接基于DataStream,但是使用batch mode模式就是批处理了
实际上, Spark也开始做这种尝试, 这个可以从其Dataframe的广泛应用以及structed stream的开发就可以看出.
5. Flink内部机制和原理
5.1 内部架构
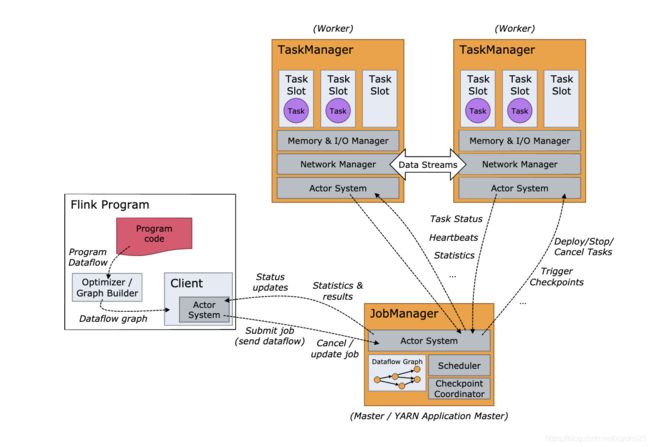
经典的主从结构, 和Spark非常相似,同样也是需要配置HA模式
- JobManager作用
it decides when to schedule the next task (or set of tasks),
reacts to finished tasks or execution failures,
coordinates checkpoints,
coordinates recovery on failures, among others

- TaskManager
execute the tasks of a dataflow,
buffer and exchange the data streams
The smallest unit of resource scheduling in a TaskManager is a task slot.
The number of task slots in a TaskManager indicates the number of concurrent processing tasks
5.2 内部机制
5.2.1. checkpoint和savepoint机制
- checkpoint

其实checkpoint, 顾名思义,就是对数据做检查点保存
注意,只有基于rocksdb,才能做增量数据保存
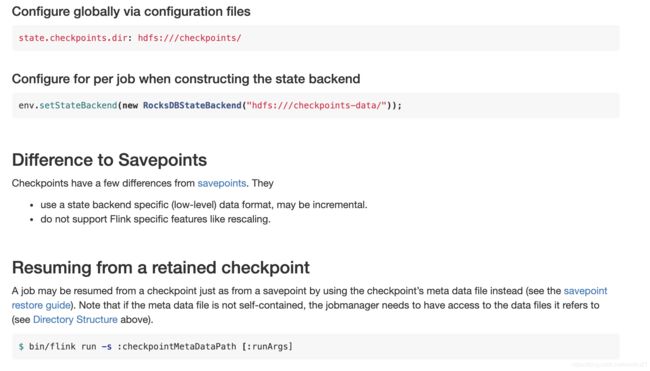

- savepoint

最大作用就是集群迁移, 版本升级等时, 保存集群中运行的Flink任务状态信息(数据以及操作)
需要主动触发,属于运维类型指令
5.2.2. event time, processtime和watermark机制
- processing time

处理时间,顾名思义, 就是流计算中, 事件时间以时间被处理的时间为准.
对于一些业务场景,希望以最低延迟,但对于数据精度要求不那么高时, 就可以采用以处理时间为基准做事件处理
但注意, 以处理时间为基准,其实会导致数据无法做回放. 这一点和基于事件时间处理相差较大
- event time
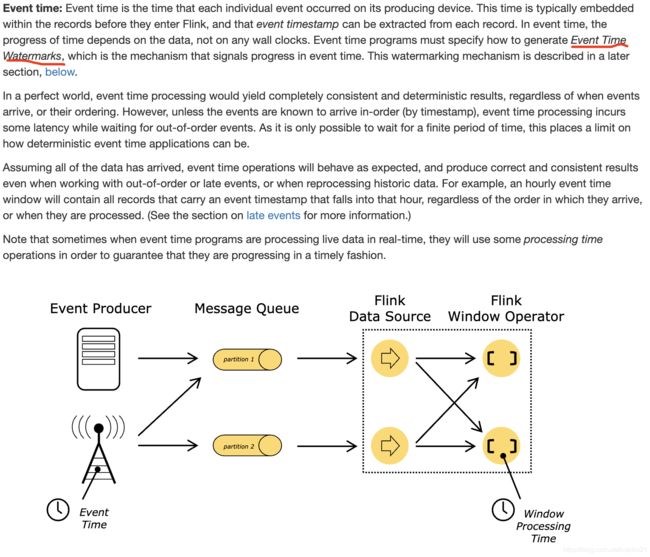
事件时间, 就是事件中带着发生时间这个信息. 基于此做处理,则可以做数据回放.
精确一次消费语义也是基于事件时间实现的
- watermark
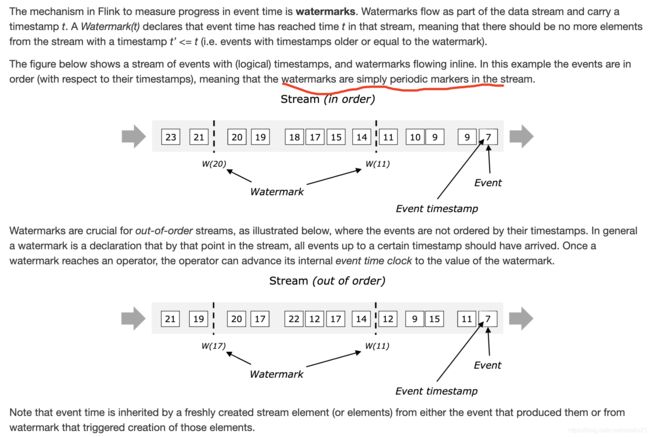
水印, 这是为了衡量基于事件时间处理的一个机制, 本质可以看做是带着时间戳的一个特殊信息单元, 会被放入数据流中.
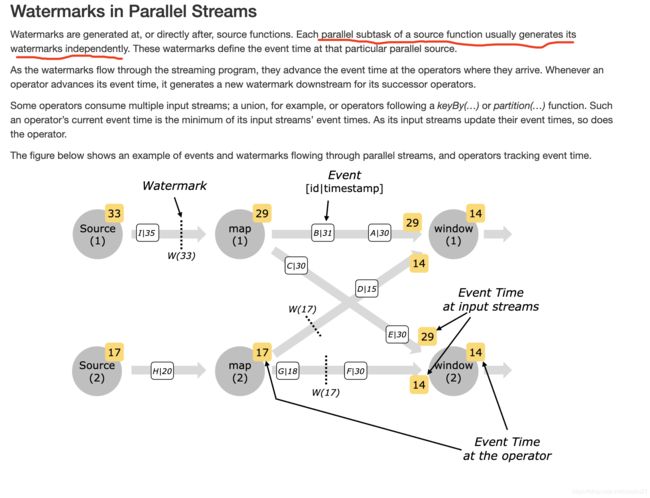
并行处理多个流或者任务时, 水印是独立产生的
- 延迟到达数据

可以看出, 水印相当于在数据流中放了一些时间标记信息, 这时候就会产生一个问题, 原本是2021-01-03 19:47:00产生的数据, 结果推迟了10小时才到达. 这时候已经超过水印标记范围了, 因为程序不可能无限等待延迟到达的数据, 所以这些数据其实就需要有一个处理策略
- 抛弃
- 侧流输出,再更新以往结果
- 开窗时允许一定延迟时间, 这样晚到一小会的数据也可以被处理
具体可以参考:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/windows.html#allowed-lateness
实际参考新浪的Flink实践时, 有一个场景就是用户行为日志有可能延迟到达半天到一天, 他们就是使用Hbase做外部缓存,等到了之后再抽出来做批处理来解决延迟到达问题.
5.2.3. side output 侧流输出

适合场景就是一个流拷贝切分为多个流(单纯拷贝为多个流, 每个流处理各自逻辑. 例如这样就不需要从kafka中设置多个消费者组进行消费处理了)
也可以用来处理延迟到达事件(主流处理, 侧流做延迟到达数据处理–更新或者删除等操作)
也可以用来做流事件处理的监控(主流做处理, 侧流做采样和处理结果对比监控)
5.2.4. 容错机制
- Flink的容错是基于状态快照机制, 顾名思义, 就是需要以快照方式对整个Flink中状态(数据, 操作等)做快照处理
- 状态后端 state backend
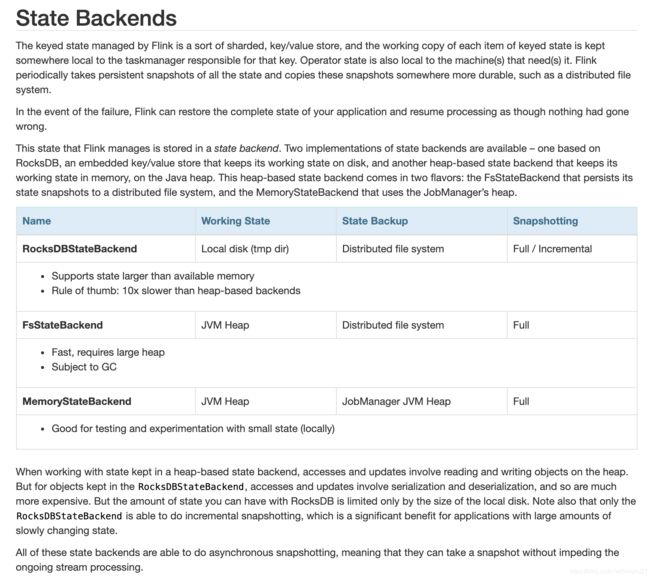
三大类, 基于rocksdb, 文件系统以及内存
- state 快照

快照如何实现:

- 精确一次消费语义

5.2.5 pipeline
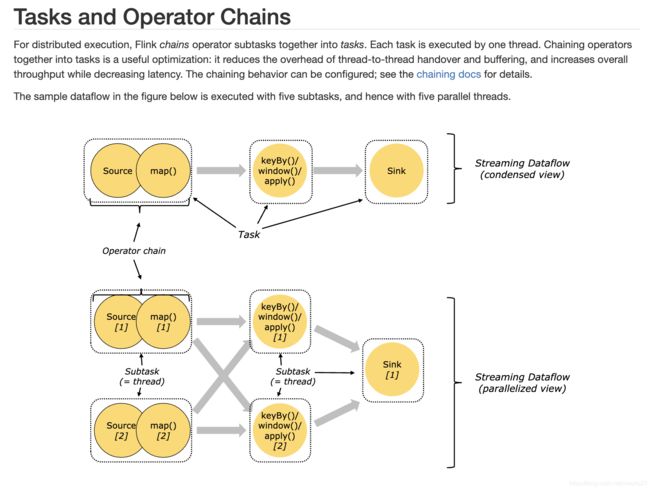
和Spark一样, 会把窄依赖操作合并为流水线, 这样一个流水线用一个线程执行
流水线可以降低线程间切换和通信的消耗
5.2.6 任务槽和资源划分
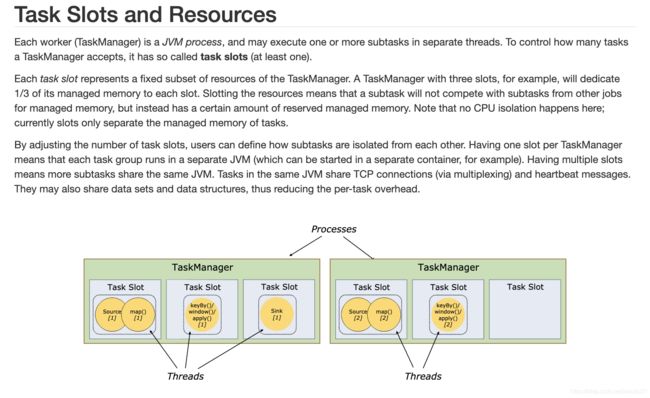
和Spark类似, Flink是一个TaskManager一个JVM, 但是为了更细粒度利用资源, 将这些资源以Slot插槽方式划分
一个插槽可以理解为一个类似做了线程切割而没有做进程切割. 所以只是内存级别切割,但是CPU级别没有切割, 都还是在一个JVM虚拟机中
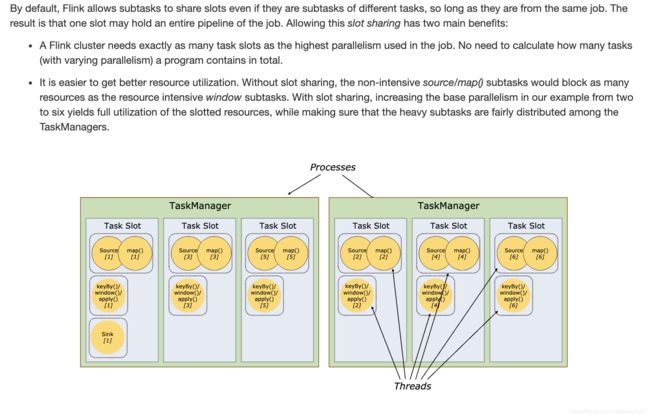
5.2.7 window
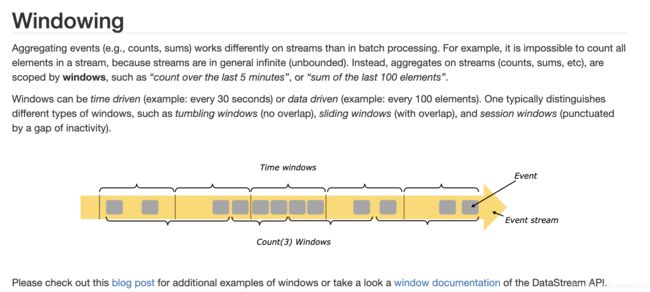
开窗, 顾名思义,就是对数据流上数据已一定条件做提取, 无界流改为有界流. 计算时,以一定条件和规则触发计算以及窗口中数据清空处理
6. Flink实际生产部署上线
- 集群监控(包括数据上游如Kafka, 数据下游如Mysql, Kafka, MongoDB, Flink集群本身). 因为Flink实时计算是一个长时间不停的计算作业, 就算容错和高可用配置好了,但为了防止出问题以及出问题后可以及时发现,监控也是必须提前做好计划和设计的.
- JobManager HA设置, 类似HDFS的namenode的高可用, 因为都是主从结构,所以主节点必须要设置高可用防止单点问题
- 合理设置checkpoint 相关参数, 包括给每个操作算子一个唯一id, 选择合适的checkpoint 后端等.
- 设置合理的并行度(环境级别, 算子级别等等)
- 部署测试和生产环境, 如果可以,还可以部署开发环境, 按照开发->测试->生产流程进行验证, 降低出错概率.
- 任务调度, 因为本身可以支持脚本和Rest API方式(https://ci.apache.org/projects/flink/flink-docs-release-1.12/ops/rest_api.html). 所以可以用如Azkaban, Airflow或者自研任务提交Web Console平台等.
- 需要注意, 流式计算和离线计算不一样在于数据到来时差问题, 俗称late data, 特别是多个流join,或者一个流依赖另外一个数据源如Hive表做查询操作时,特别需要注意数据时差以及数据量问题
- checkpoint机制很强大,但因为需要使用内部或者外部缓存,所以合理地设置对应参数,通过TTL或者RLU等思路来进行数据淘汰,防止checkpoint中数据过大,影响性能.
- 部署模式


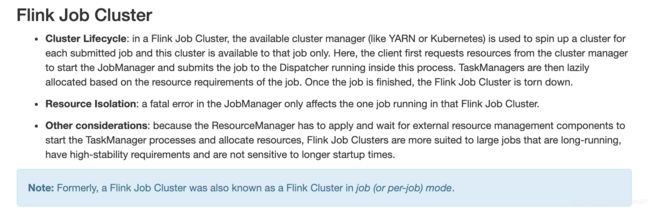
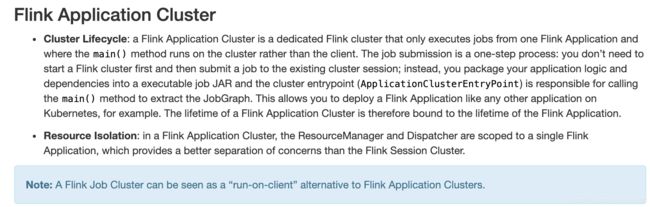
7. 选择Flink注意点
- 对比Spark来说, Flink目前在功能稳定和完善度上还相对薄弱一些,从社区频繁发版和迭代,以及邮件讨论列表中可以知道. 意味着Flink在快速追赶,但同时也意味着生产上线以及问题解决需要的技术研发力量要求会更高一些.
- Flink不是灵丹妙药, 如果现有Spark技术体系可以解决业务中问题(SQL, 批处理, 机器学习, 图计算),并且预期未来0.5到1年都不会遇到Flink这种强实时性要求(亚秒级别数据吞吐性能要求),则可以先技术预研, 不着急做生产切换.
- 如果是以Python语言开发技术体系, 则Flink对比Spark还有一些路要求, 因为Flink是从2019年8月的1.9.0版本开始支持Python, 现在Flink最新版本1.12.0对于一些功能还是无法使用Python开发如自定义的connector, sink等等.就是还需要混编, 另外, 最开始Flink只支持在Table, SQL的API这一层级支持Python,后面逐步完善到更低一层的DataStream API, 但更低的Process Function目前还不支持Python
- 从框架应用范围来说, 目前Flink的应用范围相比Spark还是窄一些, 所以一些开发, 运维资料和经验要少很多. 实际生产时, 一些技术问题就需要更多时间和精力去攻关. 如果公司大数据团队技术力量相对薄弱, 业务也不是很着急, 建议可以先缓0.5到1年再让Flink上生产环境. 预计2021年Flink在企业应用会有一个爆发性提升
- 如果是在云服务上搭建的生产环境, 建议直接使用云服务厂商的Flink套件, 相对支持和完善度更好一些. 如阿里云上就有Flink套件Flink 官网描述
- 如果需要部署, 建议暂时先不着急上Docker等容器化技术, 目前相对稳定并且被验证规模化可用的还是主流的基于节点方式部署, 也就是基于Yarn, Mesos等方式而不是容器化方式. 从生产和运维难度来说,这是最稳定方式, 不过作为技术人员, 还是需要多多关注容器化部署技术.
- 框架学习使用门槛, 从文档以及案例代码完善度来说,对比Spark, Flink的文档以及案例代码还有很多需要提升的地方. 最直接一点, Flink的一些案例代码是无法拷贝后直接运行的,Spark的基本都可以. 另外, 由于Flink版本更新较快, 网上很多博客和书籍资料, 都是基于比较老一些版本如1.7, 1.9等版本, 但2020年最新已经是1.12版本, 1.13据说也快要出来了.
- Flink是属于第三代实时计算框架, 同时也可以降级到离线计算(批处理).可以真正做到批流一体, 从框架设计角度就解决了很多第二代计算引擎的问题.从行业趋势来看, 不管从运维角度(批流一体化, 整个数仓架构可以更简化), 框架性能和功能设计角度,还有生态完善度, 成功案例都可以看出, Flink为代表的第三代计算引擎是未来大势.