nvidia 显卡深度学习
Any deep learning model has two phases — training and inference. Both the phases are as important as the other. The training phase is an iterative process — we iterate to find optimal hyper-parameters, optimal neural network architecture, model refresh and the list goes one. This iterative process is compute intensive and time consuming.
任何深度学习模型都有两个阶段-训练和推理。 这两个阶段都同等重要。 训练阶段是一个反复的过程-我们反复寻找最佳的超参数,最佳的神经网络架构,模型刷新,然后列表一一列出。 该迭代过程需要大量的计算和时间。
On the other hand, the deployed model should serve millions of requests with low latency. Also, in real world scenario it’s a bunch of models, not one single model, act up on the user requests to produce the desired response. For instance, in case of a voice assistant the speech recognition, the natural language processing and the speech synthesis models work one after the other in sequence. Hence, it is very important that our deep learning pipeline optimally utilizes all the available compute resources to make both the phases efficient by all means.
另一方面,部署的模型应以低延迟为数百万个请求提供服务。 同样,在现实世界中,它是一堆模型,而不是一个模型,它会根据用户请求产生所需的响应。 例如,在语音助手的情况下,语音识别,自然语言处理和语音合成模型依次工作。 因此,至关重要的是,我们的深度学习管道必须以最佳方式利用所有可用的计算资源,以确保所有阶段都高效。
Graphic Processing Units (GPU) are the most efficient compute resources for parallel processing. They are massively parallel with their thousands of CUDA cores and hundreds of Tensor cores. It is up to the user to best utilize the available GPU resource to make the pipeline efficient. This article discusses four tools from NVIDIA toolkit that can seamlessly integrate in to your deep learning pipeline making it more efficient.
图形处理单元(GPU)是用于并行处理的最有效的计算资源。 它们与数千个CUDA内核和数百个Tensor内核大规模并行。 用户可以最佳地利用可用的GPU资源来提高管道效率。 本文讨论了NVIDIA工具包中的四个工具,它们可以无缝集成到您的深度学习管道中,从而使其效率更高。
- DAta loading LIbrary — DALI 数据加载库— DALI
- Purpose built pre-trained models 专门构建的预训练模型
- TensorRT TensorRT
- Triton Inference Server Triton推理服务器
数据加载库— DALI (DAta loading LIbrary — DALI)
As discussed earlier the GPU is a huge compute engine but data has to be fed to the processing cores at the same rate as they are processed. Only then the GPUs are optimally utilized, else the GPU cores have to wait for data thereby making the it under utilized.
如前所述,GPU是一个巨大的计算引擎,但是数据必须以与处理核心相同的速率馈送到处理核心。 只有这样,GPU才能得到最佳利用,否则GPU内核必须等待数据,从而使其无法充分利用。
The figure below depicts a typical deep learning pipeline.
下图描绘了典型的深度学习管道。
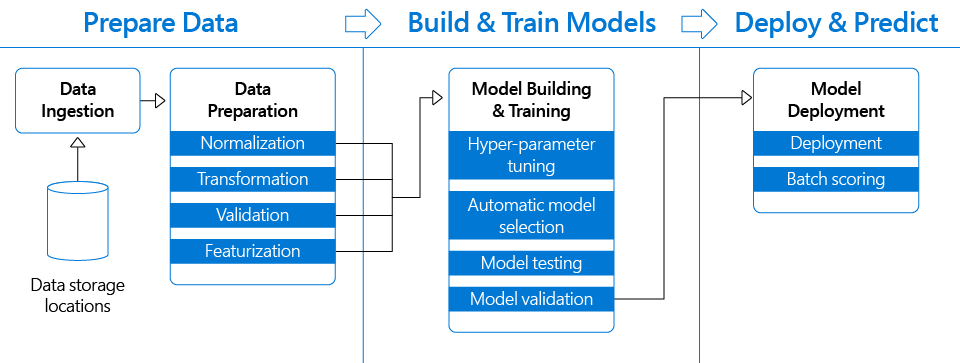
Conventionally, the data loading and pre-processing is done by the CPU and the pre-processed data is fed into the GPU for training. With the CPU core to GPU ratio increasing by the day, the CPUs are not able to keep up the pace to pre-process the data and feed the GPUs for training thereby creating a bottleneck.
按照惯例,数据加载和预处理是由CPU完成的,并且预处理后的数据会馈送到GPU中进行训练。 随着CPU核心与GPU的比例一天一天地增加,CPU无法跟上步伐来预处理数据并馈送GPU进行训练,从而造成瓶颈。
This is where DALI comes to the rescue. Only the data loading part is done by the CPU whereas the pre-processing and augmentation of data are done by the GPU.
这就是DALI进行救援的地方。 仅数据加载部分由CPU完成,而数据的预处理和扩充由GPU完成。

class GPUPipeline(Pipeline):def __init__(self, batch_size, num_threads, device_id):
super(RandomRotatedGPUPipeline, self).__init__(batch_size, num_threads, device_id, seed = 12)
self.input = ops.FileReader(file_root = image_dir, random_shuffle = True, initial_fill = 21)
self.decode = ops.ImageDecoder(device = 'cpu', output_type = types.RGB)
self.rotate = ops.Rotate(device = "gpu")
self.rng = ops.Uniform(range = (-10.0, 10.0))def define_graph(self):
jpegs, labels = self.input()
images = self.decode(jpegs)
angle = self.rng()
rotated_images = self.rotate(images.gpu(), angle = angle)return (rotated_images, labels)In the above code snippet, data load and decode is done by the CPU whereas data augmentation (Rotate in this example) is done by GPU.
在以上代码段中,数据加载和解码由CPU完成,而数据增强(在此示例中为Rotate)由GPU完成。
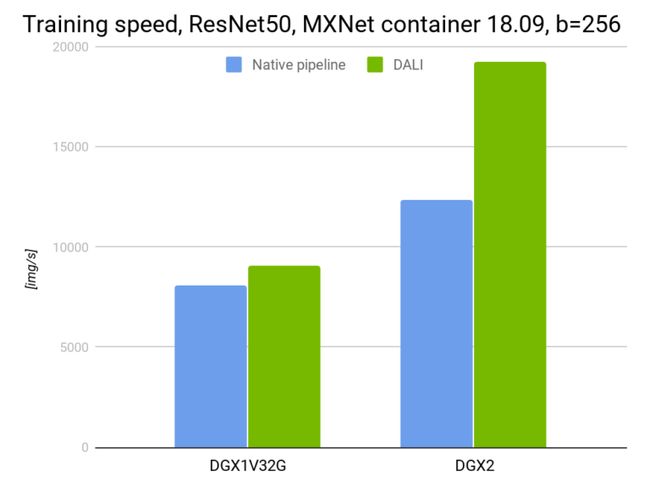
As expected, the above benchmark proves that DALI can bring in a huge performance boost as the CPU to GPU ratio increases. In DGX-1 there are 5 CPU cores per GPU where as it’s only 3 CPU cores per GPU in DGX-2.
不出所料,上述基准证明DALI可以随着CPU与GPU比率的增加而带来巨大的性能提升。 在DGX-1中,每个GPU有5个CPU内核,而在DGX-2中,每个GPU只有3个CPU内核。
专门构建的预训练模型 (Purpose built pre-trained models)
Transfer learning is a technique in which a deep learning model trained on a huge data set like ImageNet can be used for other applications with minimal data set and minimal training. Models like YOLO and BERT are trained on a huge data set using huge compute clusters. With transfer learning, these pre-trained models can be easily adopted for our application with minimal architectural changes.
转移学习是一种技术,其中在像ImageNet这样的庞大数据集上训练的深度学习模型可以用于具有最少数据集和最少训练的其他应用程序。 YOLO和BERT等模型使用庞大的计算集群在庞大的数据集上进行训练。 通过迁移学习,这些经过预训练的模型可以在我们的应用中轻松采用,而只需进行最小的体系结构更改。
NVIDIA has taken this concept of transfer learning to the next level with purpose built pre-trained models available in NVIDIA GPU Cloud (NGC). Few such models are,
NVIDIA通过NVIDIA GPU Cloud(NGC)中提供的专门构建的预训练模型,将这种转移学习的概念提升到了一个新的水平。 很少有这样的模型,
Smart city models
智慧城市模型
- DashCamNet DashCamNet
- FaceDetect FaceDetect
- PeopleNet 人民网
- TrafficCamNet TrafficCamNet
- VehicleTypeNet VehicleTypeNet
Health sciences models
健康科学模型
- Brain Tumor Segmentation 脑肿瘤分割
- Liver and Tumor Segmentation 肝肿瘤分割
- Spleen Segmentation 脾脏分割
- Chest X-ray classification 胸部X线分类
TensorRT (TensorRT)
Deep Learning has a wide range of applications such as Self Driving cars, Aerial Surveillance, Real Time Face Recognition solutions, Real Time Language Processing solutions to name a few. But there is only one similarity among these applications. REAL TIME. Considering the need for real time performance (throughput) of these models, we need to optimize the trained model so that it is lite but provides close to training accuracy.
深度学习具有广泛的应用,例如自动驾驶汽车,空中监视,实时人脸识别解决方案,实时语言处理解决方案等。 但是这些应用程序之间只有一个相似之处。 实时性 。 考虑到这些模型的实时性能(吞吐量)的需求,我们需要优化训练后的模型,使其精简但提供接近训练的准确性。
TensorRT is a Deep Learning Inference platform from NVIDIA. It is built on NVIDIA CUDA programming model which helps us leverage the massive parallel performance offered by NVIDIA GPUs. Deep Learning models from almost all popular frameworks can be parsed and optimized for low latency and high throughput inference on NVIDIA GPUs using TensorRT.
TensorRT是NVIDIA的深度学习推理平台。 它基于NVIDIA CUDA编程模型构建,可帮助我们利用NVIDIA GPU提供的大量并行性能。 可以使用TensorRT解析和优化来自几乎所有流行框架的深度学习模型,以实现低延迟和高吞吐量推断。
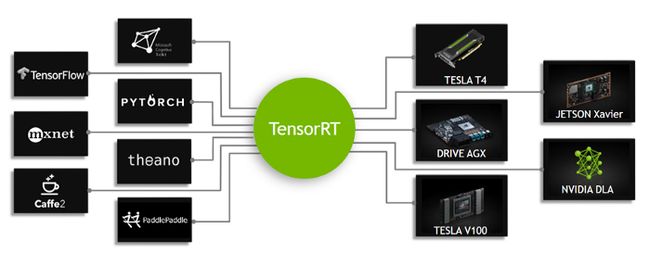
With TensorRT, we can do various optimizations effortlessly. The following are few important optimizations that can be done using TensorRT.
借助TensorRT,我们可以轻松进行各种优化。 以下是一些使用TensorRT可以完成的重要优化。
1. Mixed Precision Inference
1.混合精度推断
2. Layer Fusion
2.层融合
3. Batching
3.批处理
My observations using TensorRT engine in FP16 precision
我在FP16精度中使用TensorRT引擎的观察
1. There wasn’t much of a performance gain when my model was very shallow. For instance, with just 6 convolution layers followed by respective ReLU activation layers and a couple of fully connected layers I couldn’t see any considerable throughput gain.
1.当我的模型很浅时,性能没有太大提高。 例如,只有6个卷积层,后面分别是ReLU激活层和几个完全连接的层,我看不到任何可观的吞吐量增长。
2. When I increased the depth of the model to 20 convolution layers followed by respective ReLU layers and a couple of fully connected layers, I was able to see solid performance gains. I noticed a 3x gain in throughput.
2.当我将模型的深度增加到20个卷积层,再加上相应的ReLU层和几个完全连接的层时,我看到了可观的性能提升。 我注意到吞吐量提高了3倍。
3. The TensorRT engine was approximately half the size of the native PyTorch model as expected.
3. TensorRT引擎大约是预期的本地PyTorch模型大小的一半。
Triton推理服务器 (Triton Inference Server)
Now that we have a whole bunch of trained models, we need to deploy these models in such a way that they serve millions of user requests with low latency possible. Adding to the complexity, the models may not come from the same framework.
既然我们拥有一整套训练有素的模型,我们就需要以这样的方式部署这些模型,即它们以可能的低延迟为数百万个用户请求提供服务。 更复杂的是,这些模型可能不是来自同一框架。
Triton Inference Server provides inference service via HTTP/REST or GRPC endpoint with the following advantages,
Triton Inference Server通过HTTP / REST或GRPC端点提供推理服务,具有以下优点:
- Multiple framework support 多框架支持
- Concurrent model execution 并发模型执行
- Model ensemble support 模型合奏支持
- Multi GPU support 多GPU支持
- Batch processing of inputs 批处理输入
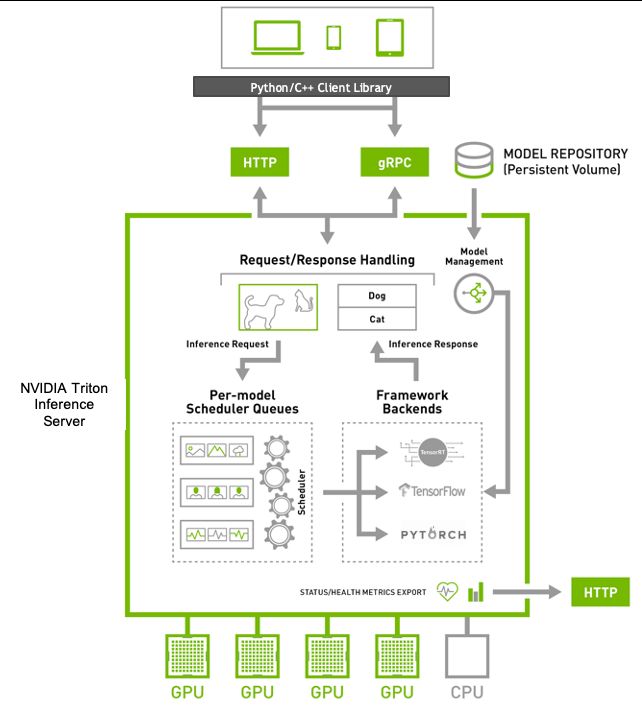
The trained models should be placed in the model repository. When an inference request arrives for a model, an execution instance is created for the model and Triton Inference Server schedules them to be processed by the underlying hardware. If multiple inference requests arrive for the same model either they can be serviced serially or multiple execution instances of the same model will be created and serviced in parallel.
受过训练的模型应放在模型库中。 当对模型的推理请求到达时,将为该模型创建一个执行实例,并且Triton Inference Server安排它们由基础硬件处理。 如果有多个推理请求到达同一模型,则可以对它们进行串行服务,或者将创建并并行服务同一模型的多个执行实例。
Multiple models or multiple instance of the same model can be serviced in parallel by a single GPU with hardware scheduling. Also, multi GPU support of Triton helps scaling out of compute resource thereby helping the user meet the latency and throughput demands during deployment.
单个GPU可以通过硬件调度并行服务多个模型或同一模型的多个实例。 此外,Triton的多GPU支持有助于扩展计算资源,从而帮助用户满足部署期间的延迟和吞吐量需求。
In the past decade deep learning has evolved a lot because of more data, powerful compute and intelligent model architectures. In this journey NVIDIA has played a major role through their GPU compute and intelligent tools and libraries. Data preparation, training and inference — all the three blocks of the deep learning pipeline are accelerated with these four tools from NVIDIA.
在过去的十年中,由于更多的数据,强大的计算和智能模型架构,深度学习取得了长足的发展。 在此过程中,NVIDIA通过其GPU计算以及智能工具和库发挥了重要作用。 数据准备,训练和推理-借助NVIDIA的这四个工具,可以加速深度学习管道的所有三个部分。
https://docs.nvidia.com/deeplearning/dali/user-guide/docs/index.html
https://docs.nvidia.com/deeplearning/dali/user-guide/docs/index.html
https://developer.nvidia.com/transfer-learning-toolkit
https://developer.nvidia.com/transfer-learning-toolkit
https://developer.nvidia.com/tensorrt
https://developer.nvidia.com/tensorrt
https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/
https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/
翻译自: https://medium.com/analytics-vidhya/accelerate-your-deep-learning-pipeline-with-nvidia-toolkit-48155939db38
nvidia 显卡深度学习