grpc通信原理_容器原理架构详解(全)
目录
1 容器原理架构:容器与虚拟化、容器应用/引擎架构、Namespace与Cgroups、镜像原理
2 K8S原理架构:K8S主要功能、K8S 系统架构、Pod原理与调度
3 K8S存储方案:容器存储类型、PVC与PV、PV创建与挂载
4 K8S网络方案:CNI与网络方案、网络配置与通信
5 应用编排管理:工作负载workload、服务与负载均衡、应用监控日志
6 容器安全方案:API 访问控制、Pod安全策略PSP、安全容器Kata
-----------------
1. 容器原理架构
1.1 容器与虚拟化
如图1,虚拟化技术通过Hypervisor实现VM与底层硬件的解耦。而容器(container)技术是一种更加轻量级的操作系统虚拟化技术,将应用程序及其运行依赖环境打包封装到标准化、强移植的镜像中,通过容器引擎提供进程隔离、资源可限制的运行环境,实现应用与OS平台及底层硬件的解耦,一次打包,随处运行。容器基于镜像运行,可部署在物理机或虚拟机上,通过容器引擎与容器编排调度平台实现容器化应用的生命周期管理。
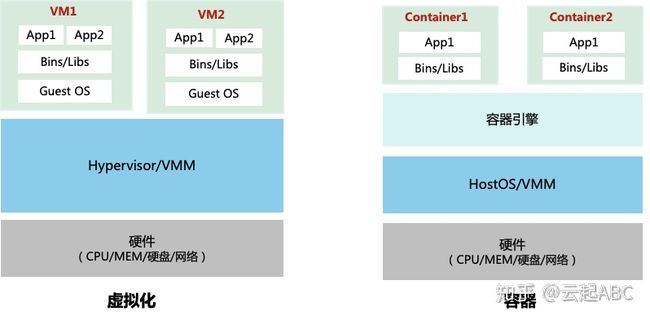
图1:虚拟化与容器架构
VM中包含GuestOS,调度与资源占用都比较重。而容器仅包含应用运行所需的文件,管理容器就是管理应用本身。如表1,容器具有极其轻量、秒级部署、易于移植、敏捷弹性伸缩等优势;但VM是OS系统级隔离,而容器是进程级隔离,容器的安全性相对更弱一些,需要一些额外的安全技术或安全容器方案来弥补。作为云原生的核心技术,容器、微服务与DevOps/ CICD)等技术已成为应用架构转型或实现技术中台不可或缺组件。
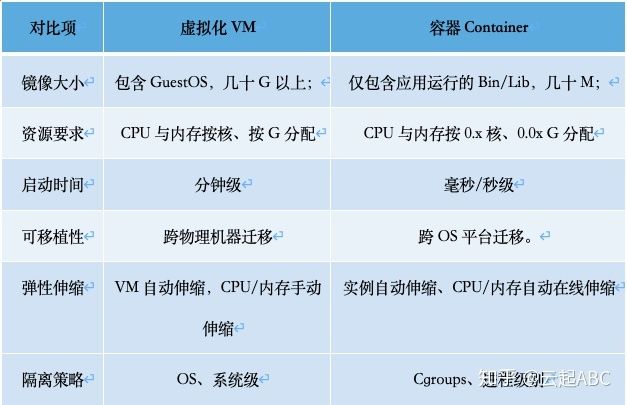
表1:容器与虚拟化对比
1.2 容器应用架构
容器概念始于1979年提出的UNIX chroot,而2008年推出功能比较完善的Linux容器LXC,但标准化与可移植性面临较大挑战。2013 推出的Docker突破性的解决了容器标准化与可移植性问题,成为当前最流行的开源容器容器引擎。2016年OCI组织推出了开放容器标准,包括容器运行时标准(runtime spec)和容器镜像标准(image spec),推动了容器技术的广泛应用。如图2,docker应用是一种C/S架构,包括3个部分
1) Docker Client:Docker的应用/管理员,通过相应的docker 命令通过HTTP或REST API等方式与docker daemon实现docker服务使用与管理。
2) Docker Host:运行各种组件docker组件提供容器服务。其中Docker Daemon负责监听client的请求并管理docker对象(容器、镜像、网络、磁盘等);Docker Image提供容器运行所需的所有文件;Linux 内核中的namespace负责容器的资源隔离,而Cgroup负责容器资源使用限制。
3) Docker Registry:容器镜像仓库,负责docker镜像存储管理。 可以用镜像仓库如DockerHub或者自建私有镜像仓库。可以通过docker push/pull 往镜像仓库上传/下载镜像。
所以,Docker运行过程就是Client发送Docker run命令到Dockerd,Dockerd从本地或镜像仓库获取Docker镜像,然后通过镜像启动运行容器实例。
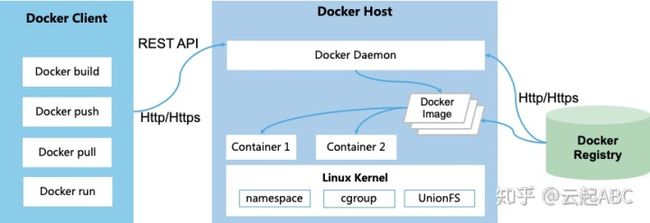
图2:Docker容器应用架构
1.3 容器引擎架构
容器引擎负责容器的生命周期管理与资源管理,2017年4月docker公司将docker项目改名为Moby。Moby容器引擎的内部架构如图3:
1) Moby daemon:通过HTTP/S或Restful API对外提供容器、镜像、网络与存储的管。
2) Containerd:容器运行时管理引擎,向上提供gRPC调用,镜像与容器的基本管理。通过containerd shim插件模块实现对不同容器运行时模块的动态接管,保障Moby daemon或containerd动态升级时对业务不产生影响。
3) 容器运行时RunC:基于OCI标准实现,负责容器的配置文件、运行环境与生命周期管理。另外应对Docker容器安全性不足,新推出Kata、gVisor等安全容器技术。

图3: Moby容器引擎架构
1.4 Namespace与Cgroups
Linux namespace
Linux namespace负责容器的工作空间与资源隔离。容器中namespace通过unshare系统调用来创建,Linux内核提供了7中namespace:
1) PID namespace:保障进程隔离,每个容器都以PID=1的init进程来启动。
2) MNT namespace: 保障每个容器都有独立的目录挂载路径。
3) UTS namespace:保障每个容器都有独立的主机名或域名。
4) NET namespace:保障每个容器都有独立的网络栈、socket和网卡设备。
5) IPC namespace:只有在相同IPC命名空间的容器才可以利用共享内存、信号量和消息队列通信。
6) User namespace:用于隔离容器中UID、GID以及根目录等。可配置映射宿主机和容器中的UID、GID。
7) Cgroup namespace:保障容器容器中看到的 cgroup 视图像宿主机一样以根形式来呈现,同时让容器内使用 cgroup 会变得更安全。
Linux Cgroups
Cgroups对容器进程进行层次化分组,并按组实现资源限制和策略控制。
1) Cgroupfs驱动:需要限制CPU或内存使用时,直接把容器进程的PID写入相应的CPU或内存的cgroup。
2) systemd cgroup驱动:提供cgroup管理,所有的cgroup写操作需要通过systemd的接口来完成,不能手动修改。
Linux内核提供了很多Cgroup控制器,容器中常用的是
1)cpu/cpuset/cpuacct group:设置CPU share、cpuacct控制CPU使用率
2)memory group:控制内存使用量;
3)device group:控制在容器中看到的device设备,保障安全。
4)freezer group:容器停止时Freezer当前容器进程都写入cgroup,进程冻结。
5)blkio group:限制容器到磁盘的IOS、BPS;
6)pid group:限制容器里面可用到的最大进程数量。
1.5 容器镜像原理
容器镜像就是容器运行时所需要的二进制文件与依赖包的集合,存储在只读的Dockerfile中。镜像基于分层的联合文件系统UnionFS来实现,Ubuntu里基于AUFS实现,新推出OverlayFS比AUFS性能更好,部署更简单,两者核心原理是类似的。图5为容器镜像基于OverlayFS(推荐更高效稳定的Overlay2)的分层架构,其文件处理如表2。
1) lowerdir:镜像层,保存只读的容器镜像文件,多个容器共享;
2) upperdir:容器层,可读可写,采用写时复制COW,每个容器独有。
3) merged:统一视图层,整合各层内容,挂载的容器rootfs下,统一呈现。

图5:基于OverlayFS容器镜像分层(图片来源:Docker官网)
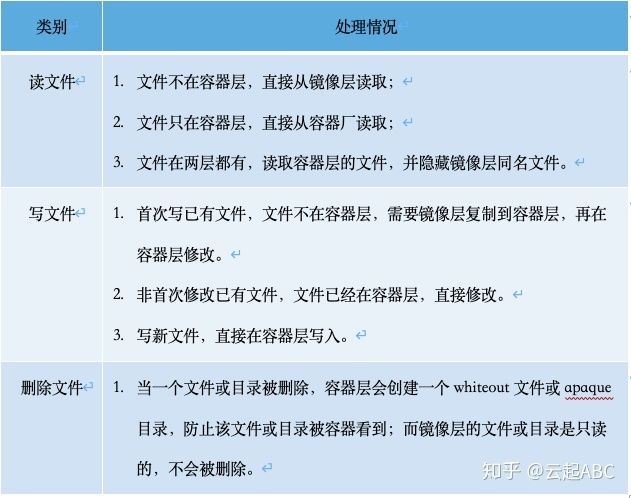
表2:基于overlay2的容器文件的读写处理
2. K8S原理架构
2.1 K8S主要功能
Kubernetes简称K8S 是 Google于2014年开源容器编排调度管理平台。相比与Swarm、Mesos,K8S引入Pod、Replica、Label、Service等机制简化了容器调度与管理,提供可靠性,增加了功能特性,目前成为最流行的容器编排平台,K8S主要功能如下:
1)容器调度管理:基于调度算法与策略将容器调度到对应的节点上运行。
2)服务发现与负载均衡:通过域名、VIP对外提供容器服务,提供访问流量负载均衡。
3)弹性扩展:定义期待的容器状态与资源,K8S自动检测、创建、删除实例和配置以满足要求。
4)自动恢复与回滚:提供健康检查,自动重启、迁移、替换或回滚运行失败或没响应的容器,保障服务可用性。
5)K8S对象管理:涉及应用编排与管理、配置、秘钥等、监控与日志等。
6)资源管理:对容器使用的网络、存储、GPU等资源进行管理。
2.2 K8S 系统架构
如图5,K8S是二层C/S架构Master作为管控节点,负责集群调度,监控管控与元数据存储;Node是业务节点,负责容器运行、资源分配与管理。用户通过UI或API与Master通信交付,然后把相关请求转发到Node上进行处理。

图5:K8S系统架构
Master的主要组件功能如下:
1)API Server:K8S资源对象的唯一操作入口,接收、校验并处理 API 请求;Master中所有组件互不相连,都通过API Server 进行消息传送与任务处理;
2)Controller Manager:集群管理控制中心,负责集群状态检测与故障恢复等工作。管理多个控制器:Node Controller、Endpoint Controller、Service Account & Token Controller等。
3)Scheduler:集群调度器,负责容器调度操作,基于资源与策略等将Pod调度到合适的Node上运行。
4)ETCD:负责集群元数据与状态保存。是一个基于RAFT协议的高可用的分布式Key-Value存储系统。
5)Cloud Controller Manager:负责与云厂商组件相关的控制器交互,如 Node Controller、Route Controller、Service Controller、Volume Controller。K8S控制器由“声明式”的API驱动,提前定义K8S资源对象的期待状态,控制器自主运行,异步地控制系统想最终状态趋近。
Node的主要组件功能如下:
1)Kube-let:与API Server交互获取容器Pod创建请求,转到对应的Container Runtime处理。监控并上报Pod运行情况、镜像与资源状态等。
2)kube-proxy:Node上的网络代理,维护集群服务的网络规则与网络通信。
3)Container Runtime:接收Kube-let请求在OS创建容器的运行时环境。
4)Storage Plugin/Network Plugin, 负责与外部组件通信,容器存储或网络的配置使用。
2.3 Pod原理与调度
Pod 是K8S的最小调度以及资源分配单元,包含容器运行环境与资源。Pod之间相互隔离。通常一个Pod运行一个容器。当某些容器间关系非常紧密Tightly coupled(如文件交换、频繁的RPC调用、共享网络或存储等),需要在一个Pod运行多个容器方便调度管理。
Pod中可以通过Infra Container共享网络。Infra container,大小100-200KB,最先启动,并绑定了Pod的唯一IP地址与各种网络资源,Pod内其他容器通过加入infra container的Network namespace来实现网络共享。Pod中的多个容器也可以通过挂载相同的共享路径实现存储共享。
Pod 中可定义Init Container在应用启动前先启动来执行一次性的辅助任务,比如执行脚本、拷贝文件到共享目录、日志收集、应用监控等。将辅助功能与主业务容器解耦,实现独立发布和能力重用。
一个Pod就是一个应用运行实例,可以运行多个Pod实现应用横向扩展。当调度失败或运行失败时,Pod本身没有自恢复能力,需要借助上层的controller来通过采用提前定义好的Pod模板创建Pod,提供Pod重启、重建或迁移能力。
K8S调度主要涉及资源调度和关系的调度,采用两种机制过滤(Filtering)和打分(Scoring)。通过过滤机制选择备用节点,过滤因素包括CPU/内存/存储、Pod与Nod匹配、Pod与Pod匹配等;然后将Pod调度到分数最高的节点,打分依据包含亲和性/反亲和性、资源水位等等。完整的调度流程如下:
1) 用户通过UI或CLI提交Pod部署请求时,会首先提交给API Server,然后信息存储到ETCD;
2) Scheduler通过Watch或通知机制获得Pod需要调度的请求,通过过滤和打分机制做出调度决策,并通知API Server调度结果;
3) API Server收到调度结果写入ETCD,并通知响应Node上的Kube-let。
4) Kube-let调用Container Runtime配置其他运行环境,并调用对应的插件去分片存储和网络资源。
3 K8S存储方案
3.1 容器存储类型
容器数据存储与共享需要提供存储卷,有几种方式:
1) 本地存储:将容器所在宿主机的目录挂载到容器中,可以是指定路径的Hostpath或系统分配的零时路径Emptydir。
2) 网络存储:通过in-tree 方式实现(代码包含在K8S中)维护和扩展相对麻烦,目前推荐采用 out-of-tree方式实现,通过CSI插件将网络存储diver实现与K8S解耦。
3) Projected Volume:将配置数据(如Secret、ConfigMap等)以卷形式挂载到容器中,让应用可以通过POSIX接口来访问。
4) PVC与PV:通过PV(Persistent Volume)将Pod与Volume生命周期解耦,同时通过PVC(Persistent Volume Claim)实现职责分离,简化K8S用户对存储的使用与调度分配。
3.2 PVC与PV
PVC定义业务侧的存储需求,如存储容量、访问模式(独占还是共享、只读还是读写)等;PV是存储的具体实现,分配存储空间。如图7,PV支持静态分配与动态分配。
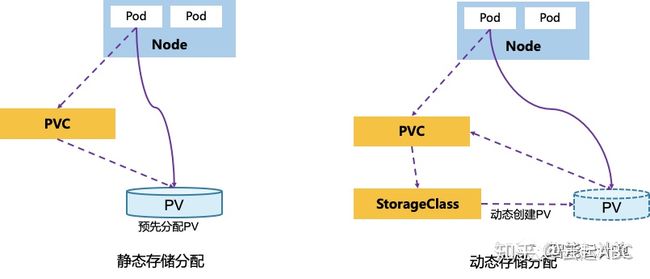
图6:PV存储分配方式
1) 静态分配:管理员预先创建分配一些PV,用户端提交Pod与PVC存储需求时,管控组件将PVC与合适的PV绑定到一起,然后提供给Pod使用。这里预先分配的PV很难精确匹配存储需求,可能造成资源浪费。
2) 动态分配:管理员不预先分配PV,只是定义了PV模板StorageClass,说明存储类型,存储插件,回收策略及相关参数,用户端提交Pod与PVC存储需求时,管控组件会根据StorageClass动态创建符合需求的PV,然后绑定到PVC,提供给Pod使用。这里实现了存储按需分配,管理运维也更加简单。
3.3 PV 创建与挂载
如图8,K8S中引入了存储插件CSI(Container Storage Interface),其一部分是K8S驱动中实现的通用部分如图中的CSI-Provisioner-Controller和CSI-Attacher-Controller,实现存储控制功能;另一部分是云存储厂商实现的CSI-Controller-Server与CSI-Node-Server,实现Vol创建/删除、挂载/卸载等存储操作。PV和PVC的处理有3个阶段:
1) PV创建与绑定(1-5):Kube-API-Server接收到用户提交Pod和PVC请求。CSI-Provisioner-Controller监听到PVC对象生成,结合PVC中声明StorageClass,通过gRPC调用CSI-Controller-Server,然后调用云存储组件创建PV资源。PV-Controller将PVC与PV绑定,PV使用就绪。
2) Pod调度与PV Attach(6-8):用户提交Pod后,调度器选择合适的Node。AD-Controller监听到被选Node并生成VolumeAttachment对象,触发CSI-Attacher-Controller调用CSI-Controller-Server去将存储关联(Attach)到被选Node上(路径/dev)。
3) Pod创建与PV Mouth(9-10):Kube-let创建Pod时先通过CSI-Node-Server将PVC绑定的PV挂载(Mount)到Pod可以使用的路径,然后启动Pod中的所有容器。
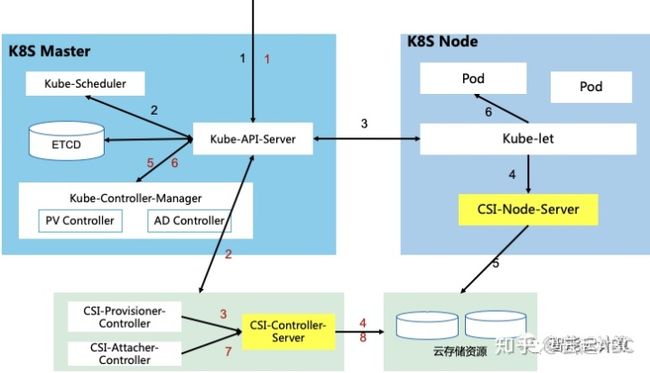
图7:Pod与PV创建与挂载流程
4 K8S网络方案
4.1 CNI与网络方案
K8S网络通过CNI(Container Network Interface)网络插件实现。如图6,基于不同的实现模式(Overlay、Underlay或路由),对底层网络依赖程度也不同。主流网络实现方案如表3所示,可以基于网络环境限制、功能需求与性能要求进行对比选择。
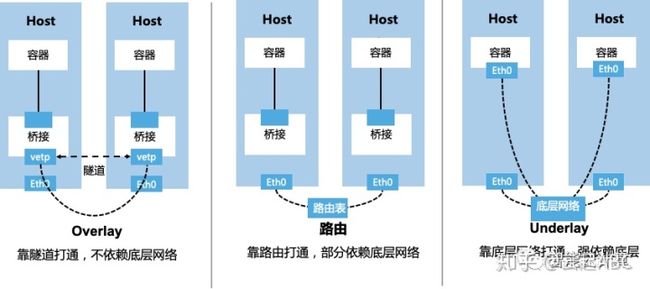
图9:K8S网络插件实现模式

表3:K8S网络实现方案
4.2 网络配置与通信
K8S中每个Pod有独立网络空间,通过独立的IP对外通信。Pod之间、Pod与Node之间可直接通信,无需地址转换,可通过Network Policy设置访问策略。通过CNI网络插件实现网络配置步骤如下:
1) 配置CNI配置文(/etc/cni/net.d/xxnet.conf);
2) 安装二进制CNI插件(/opt/cni/bin/xxnet);
3) 在节点上创建Pod时,Kube-let根据CNI配置文件执行CNI插件来配置Pod网络。
如图7在云厂商容器服务中,容器服务可以部署在VM上。容器网络采用基于VPC私有网络实现,其中涉及底层主机的物理网络,Node集群的虚拟网络,以及上层容器网络。容器与外部网络通信基于Overlay隧道、虚拟网关、VPC路由表、物理网络路由等技术实现。
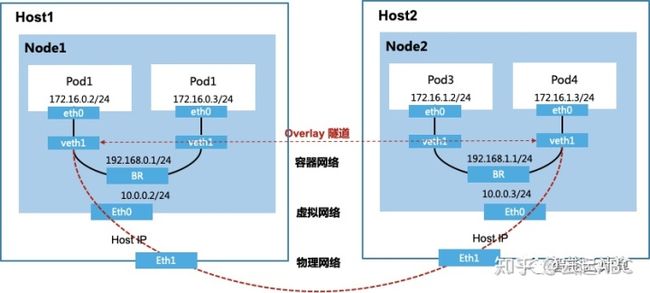
图10:基于Overlay隧道的容器网络
5 应用编排管理
5.1 工作负载Workload
K8S中通过工作负载Workload来管理应用部署与发布。需要基于不同的工作负载类型(Deployment、StatefulSet、DaemonSet、Job、CronJob),配置存储卷,配置容器实例与镜像,实例的数量与弹性伸缩,服务访问方式等。不同负载类型与说明如表4。另外容器中还可以通过ConfigMap、Secret来保持容器中的可变配置与敏感信息。
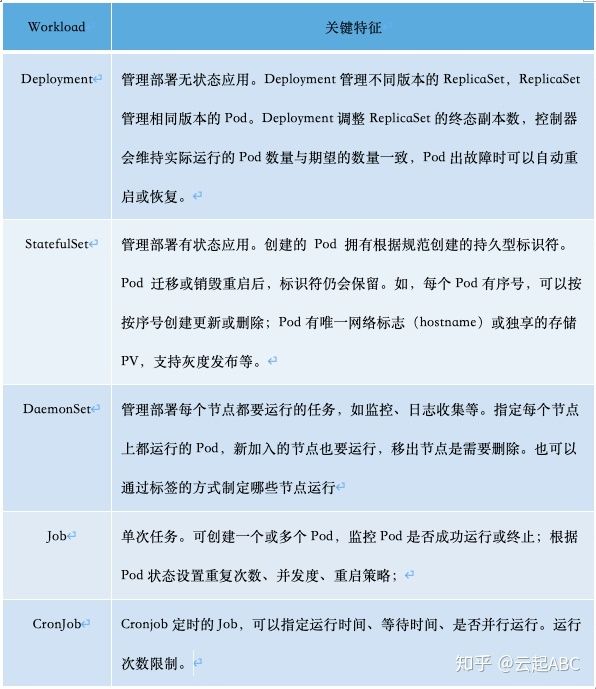
表4:容器工作负载类型与说明

表5:容器配置ConfigMap与Secret
5.2 服务与负载均衡
K8S服务Service提供了功能相同的一组Pod统一抽象入口,定义了服务访问方式与负载均衡,实现前端Client的服务访问与后端Pod上的服务部署解耦。另外可以通过Ingress实现基于HTTP/HTTPS的7层负载均衡,配置转发规则,实现不同URL访问不同的service,支持配置SSL证书。如表6,容器服务支持基于负载均衡、ClusterIP或NodePort方式实现不同场景下的服务访问。

表6:容器服务访问方式
容器服务的配置与访问路径如图11,Master中Kube-API-Server负责监听服务状态与变化;Cloud-Controller-Manager负责配置负载均衡提供外网访问;CoreDNS负责配置服务域名到ClusterIP的DNS解析。如图,当客户端Pod4想要访问容器服务时,先通过CoreDNS解析服务名到服务的ClusterIP,然后Pod4向ClusterIP发起服务请求;请求到达Node节点后会被Kube-Proxy配置的Iptables或IPVS的规则拦截,然后内部负载均衡到后端的服务Pod1、Pod2、Pod3。如果是集群外访问,请求发送到外部LB然后转发到NodePort,然后经过Kube-Proxy配置的Iptables或IPS转换成访问ClusterIP,然后转换成访问后端Pod具体IP。
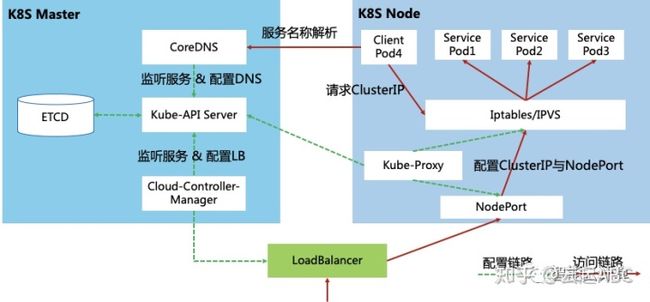
图11:K8S服务发现与访问路径
5.3 应用监控管理
就绪探针与存活探针
要保障容器应用的健康稳定运行,需要提供应用的运行状态、资源使用的可观测性与恢复能力。系统通过就绪探针Readiness Probe探测Pod是否处于就绪状态,如果不就绪就切断上层流量,Pod不对外提供服务。通过存活探针Liveness Probe探测Pod是否存活,如果不存活,根据重启策略判断是否需要重新拉起pod。两种探针支持3种探测方式:
1) httpGet:发送 http Get 请求来判断,当返回码是 200-399 之间时,应用正常。
2) Exec:通过执行容器中的一个命令来判断,如果返回结果 0,容器服务正常。
3) tcpSocket:通过容器 IP 和 Port 建立TCP 连接,如果连接成功,容器正常。
监控告警与日志
K8S监控分为几种类型,如资源监控(CPU、内存、网络)、性能监控(APM应用性能指标)、安全监控(安全策略、越权管理、安全漏洞)、事件监控(正常Normal事件或异常warning事件)。目前K8S采用主流的开源监控标准Prometheus,应用侧只需要只需要实现 Prometheus Client就是可以实现数据采集,支持3种数据采集策略:
1) Pull 模式:通过拉模式去对应的数据的任务上面去拉取数据;一旦你的数据声明周期短于数据采集周期可能漏采。
2) Push模式:通过 pushgateway 进行数据采集,然后 Prometheus 再通过 pull 的方式去 pushgateway 去拉数据。
3) Prometheus on Prometheus:通过一个 Prometheus同步数据到另一个Prometheus。
K8S日志也分为几种类型:主机内核日志、运行时Runtime日志、K8S组件日志、业务应用日志。日志通过宿主机文件、容器日志文件或日志标准或错误输出进行采集。目前主流的日志采集呈现方案是ELK,通过 Fluentd采集日志,将数据汇集到 Elasticsearch(或InfluxDB)分析处理,然后再通过 Kibana(或Grafana)做日志展现。
6 容器安全方案
6.1 API访问控制
容器安全4C
如图12,容器环境的安全涉及4个层级4C(Code、Container、Cluster,Cloud),每个层级都需要有相对独立又相互关联的安全机制与方案。本文重点讲Cluster与Container层级的安全机制。

图12:容器环境的安全层级
API 访问控制
如图13,K8S API访问控制,普通用户UserAccount或集群对象Service Account发起API请求,API Server会接收请求,并进行访问控制检测,通过后才将API请求转发到对应的K8S对象进行处理。其中,可以通过证书、密码、秘钥和Token进行用户认证;通过基于节点Node,基于角色的RBAC、基于属性的ABAC或自定义HTTP回调方法Webhook的方式进行授权校验;最后再基于准入控制插件在对象创建/删除/更新或连接时进行准入控制检测,读操作时不做。

图13:K8SAPI请求访问控制
6.2 Pod 安全策略PSP
K8S中可以设置Security Context,限制容器行为,保证系统和其他容器的安全。用户配置Security Context后,传到系统内核,然后通过内核机制让SecurityContext生效。SecurityContext分为三个级别:容器级别仅对容器生效;Pod 级别对 Pod 里所有容器生效;集群级别,就是 PSP,对集群内所有 pod 生效。可支持如下配置:
1)Users and groups:通过指定UID、GID的范围控制访问权限。
2)SELinux:对用户或进程文件配置基于Linux内核的强制访问控制;
3)Privileged:指定Pod内那些容器客户运行在特权模式;
4)Capabilities:提供与Superuser关联权限细分,可用于容器权限升级。
5)AppArmor:通过配置文件来控制可执行文件的一个访问控制权限,
6)Systemctl:对系统调用的控制;
7)Volumes and file systems:指定运行访问的存储卷类型。
PSP对象是集群级别的资源,定义了一组条件,指示 Pod 必须按系统所能接受的顺序运行、能够控制 Pod 运行行为与访问能力。允许管理员控制如下内容:
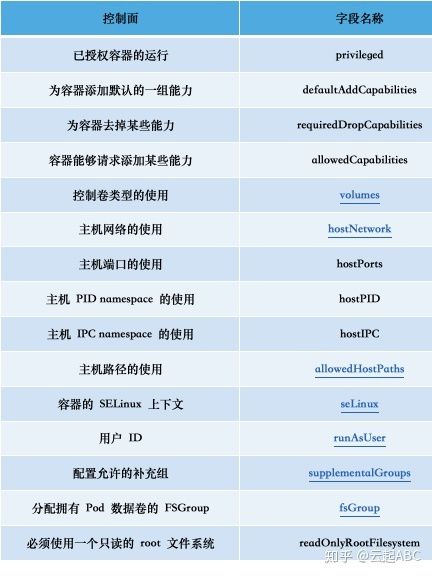
表7:Pod安全策略说明
K8S保障容器安全,除了以上安全机制,还可过RBAC、Namespace机制 加强隔离;使用ResourceQuota & Limit Range限制资源使用;通过加密实现敏感信息保护;通过NetworkPolicy控制网络流量,采用日志、监控与告警机制等。
6.3 安全容器Kata
应用部署在Docker容器中调度管理方便,运行性能高,但安全隔离较差; 而应用部署VM上,安全隔离更好,但调度管理与性能上又受到限制,所以,安全容器整合容器和VM的优势。如图14,传统容器中,不同Pod共享内核,通过namespace隔离。而安全容器在每个Pod外增加了保护层Pod Sandbox,容器之间达到内核级隔离,提升了安全性,调度管理与运行性能也不受影响。Pod Sandbox基于VM面向云原生的虚拟化,有kernel但没有完整OS,只读系统,仅运行容器,动态调整资源。
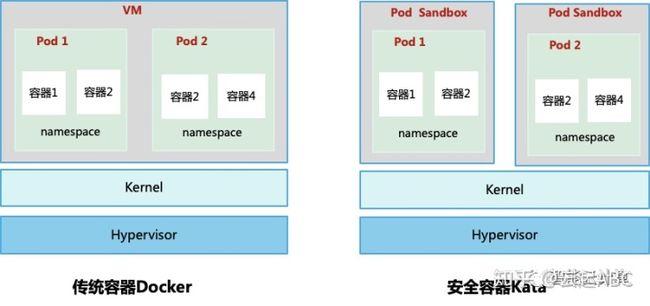
图14:传统容器与安全容器对比
Kata 容器可以与K8S进行集成,Kata 1.5 版本之后集成架构如图15。客户端Kube-let通过CRI接口向Containerd发起请求;Containerd为每个Pod创建一个Containerd-shim-kata-v2,然后启动Pod Sandbox,运行轻量的Guest Kernel;然后把容器的声明Spec与Rootfs提交给Pod Sandbox,启动容器运行。其他外置存储、网络等可以无缝的接入Pod sandbox使用。Kata容器通过优化现有VM隔离机制实现安全容器,Google开源的gVisor不创建Pod Sandbox,采用新的更加轻量技术实现安全容器。

图15:Kata容器与K8S集成
相关阅读:
云起ABC:KVM 虚拟化详解zhuanlan.zhihu.com
--------
参考资料:
1. Docker官网:
https://docs.docker.com/
2. K8S官网:
https://kubernetes.io/docs/home/
3. 从零开始入门 K8S系列:
https://developer.aliyun.com/article/718433