Python模块和包
文章目录
- 什么是模块,Python模块化编程
- import用法
-
- import 模块名 as 别名
- from 模块名 import 成员名 as 别名
-
-
- 不推荐使用 from import 导入模块所有成员
-
- 自定义模块
-
- 自定义模块编写说明文档
- Python ```__name__```=='```__main__```'作用详解
- 导入模块的3种方式
-
- 导入模块方式一:临时添加模块完整路径
- 导入模块方式二:将模块保存到指定位置
- 导入模块方式三:设置环境变量
-
-
- 在 Windows 平台上设置环境变量
- 在 Linux 上设置环境变量
- 在Mac OS X 上设置环境变量
-
- ```__all__```变量用法
-
- Python模块```__all__```变量
- Python包及其定义和引用详解
-
- 什么是包
- 定义包
- 导入包内成员
- Python包(存放多个模块的文件夹)
- 创建包,导入包
-
- Python包的导入
-
-
- 1) import 包名[.模块名 [as 别名]]
- 2) from 包名 import 模块名 [as 别名]
- 3) from 包名.模块名 import 成员名 [as 别名]
-
- __init__.py作用
- 查看模块(变量、函数、类)方法
-
- 查看模块成员:dir()函数
- 查看模块成员:```__all__```变量
- ```__doc__```属性:查看文档
- ```__file__```属性:查看模块的源文件路径
- 第三方库(模块)下载和安装(使用pip命令)
前面章节中,我们已经使用了很多模块(如 string、sys、os 等),通过向程序中导入这些模块,我们可以使用很多“现成”的函数实现想要的功能。
那么,模块到底是什么,模块内部到底是什么样子的,模块可以自定义吗?本章将带领读者详细了解 Python 中的模块,诸如此类疑问,本章都会一一给大家解惑。
除此之外,本章还会讲解 Python 中的包,它本质上也是模块,是有效管理模块的工具。
什么是模块,Python模块化编程
Python 提供了强大的模块支持,主要体现在,不仅 Python 标准库中包含了大量的模块(称为标准模块),还有大量的第三方模块,开发者自己也可以开发自定义模块。通过这些强大的模块可以极大地提高开发者的开发效率。
那么,模块到底指的是什么呢?模块,英文为 Modules,至于模块到底是什么,可以用一句话总结:模块就是 Python 程序。换句话说,任何 Python 程序都可以作为模块,包括在前面章节中写的所有 Python 程序,都可以作为模块。
模块可以比作一盒积木,通过它可以拼出多种主题的玩具,这与前面介绍的函数不同,一个函数仅相当于一块积木,而一个模块(.py 文件)中可以包含多个函数,也就是很多积木。模块和函数的关系如图 1 所示。

图 1 模块和函数的关系
经过前面的学习,读者已经能够将 Python 代码写到一个文件中,但随着程序功能的复杂,程序体积会不断变大,为了便于维护,通常会将其分为多个文件(模块),这样不仅可以提高代码的可维护性,还可以提高代码的可重用性。
代码的可重用性体现在,当编写好一个模块后,只要编程过程中需要用到该模块中的某个功能(由变量、函数、类实现),无需做重复性的编写工作,直接在程序中导入该模块即可使用该功能。
前面讲了封装,并且还介绍了很多具有封装特性的结构,比如说:
- 诸多容器,例如列表、元组、字符串、字典等,它们都是对数据的封装;
- 函数是对 Python 代码的封装;
- 类是对方法和属性的封装,也可以说是对函数和数据的封装。
本节所介绍的模块,可以理解为是对代码更高级的封装,即把能够实现某一特定功能的代码编写在同一个 .py 文件中,并将其作为一个独立的模块,这样既可以方便其它程序或脚本导入并使用,同时还能有效避免函数名和变量名发生冲突。
举个简单的例子,在某一目录下(桌面也可以)创建一个名为 hello.py 文件,其包含的代码如下:
def say ():
print("Hello,World!")
在同一目录下,再创建一个 say.py 文件,其包含的代码如下:
#通过 import 关键字,将 hello.py 模块引入此文件
import hello
hello.say()
运行 say.py 文件,其输出结果为:
Hello,World!
读者可能注意到,say.py 文件中使用了原本在 hello.py 文件中才有的 say() 函数,相对于 day.py 来说,hello.py 就是一个自定义的模块(有关自定义模块,后续章节会做详细讲解),我们只需要将 hellp.py 模块导入到 say.py 文件中,就可以直接在 say.py 文件中使用模块中的资源。
与此同时,当调用模块中的 say() 函数时,使用的语法格式为“模块名.函数”,这是因为,相对于 say.py 文件,hello.py 文件中的代码自成一个命名空间,因此在调用其他模块中的函数时,需要明确指明函数的出处,否则 Python 解释器将会报错。
import用法
使用 Python 进行编程时,有些功能没必须自己实现,可以借助 Python 现有的标准库或者其他人提供的第三方库。比如说,在前面章节中,我们使用了一些数学函数,例如余弦函数 cos()、绝对值函数 fabs() 等,它们位于 Python 标准库中的 math(或 cmath)模块中,只需要将此模块导入到当前程序,就可以直接拿来用。
前面章节中,已经看到使用 import 导入模块的语法,但实际上 import 还有更多详细的用法,主要有以下两种:
import 模块名1 [as 别名1], 模块名2 [as 别名2],…:使用这种语法格式的 import 语句,会导入指定模块中的所有成员(包括变量、函数、类等)。不仅如此,当需要使用模块中的成员时,需用该模块名(或别名)作为前缀,否则 Python 解释器会报错。from 模块名 import 成员名1 [as 别名1],成员名2 [as 别名2],…: 使用这种语法格式的 import 语句,只会导入模块中指定的成员,而不是全部成员。同时,当程序中使用该成员时,无需附加任何前缀,直接使用成员名(或别名)即可。
注意,用 [] 括起来的部分,可以使用,也可以省略。
其中,第二种 import 语句也可以导入指定模块中的所有成员,即使用 form 模块名 import *,但此方式不推荐使用,具体原因本节后续会做详细说明。
import 模块名 as 别名
下面程序使用导入整个模块的最简单语法来导入指定模块:
# 导入sys整个模块
import sys
# 使用sys模块名作为前缀来访问模块中的成员
print(sys.argv[0])
上面第 2 行代码使用最简单的方式导入了 sys 模块,因此在程序中使用 sys 模块内的成员时,必须添加模块名作为前缀。
运行上面程序,可以看到如下输出结果(sys 模块下的 argv 变量用于获取运行 Python 程序的命令行参数,其中 argv[0] 用于获取当前 Python 程序的存储路径):
C:\Users\mengma\Desktop\hello.py
导入整个模块时,也可以为模块指定别名。例如如下程序:
# 导入sys整个模块,并指定别名为s
import sys as s
# 使用s模块别名作为前缀来访问模块中的成员
print(s.argv[0])
第 2 行代码在导入 sys 模块时才指定了别名 s,因此在程序中使用 sys 模块内的成员时,必须添加模块别名 s 作为前缀。运行该程序,可以看到如下输出结果:
C:\Users\mengma\Desktop\hello.py
也可以一次导入多个模块,多个模块之间用逗号隔开。例如如下程序:
# 导入sys、os两个模块
import sys,os
# 使用模块名作为前缀来访问模块中的成员
print(sys.argv[0])
# os模块的sep变量代表平台上的路径分隔符
print(os.sep)
上面第 2 行代码一次导入了 sys 和 os 两个模块,因此程序要使用 sys、os 两个模块内的成员,只要分别使用 sys、os 模块名作为前缀即可。在 Windows 平台上运行该程序,可以看到如下输出结果(os 模块的 sep 变量代表平台上的路径分隔符):
C:\Users\mengma\Desktop\hello.py
\
在导入多个模块的同时,也可以为模块指定别名,例如如下程序:
# 导入sys、os两个模块,并为sys指定别名s,为os指定别名o
import sys as s,os as o
# 使用模块别名作为前缀来访问模块中的成员
print(s.argv[0])
print(o.sep)
上面第 2 行代码一次导入了sys 和 os 两个模块,并分别为它们指定别名为 s、o,因此程序可以通过 s、o 两个前缀来使用 sys、os 两个模块内的成员。在 Windows 平台上运行该程序,可以看到如下输出结果:
C:\Users\mengma\Desktop\hello.py
\
from 模块名 import 成员名 as 别名
下面程序使用了 from…import 最简单的语法来导入指定成员:
# 导入sys模块的argv成员
from sys import argv
# 使用导入成员的语法,直接使用成员名访问
print(argv[0])
第 2 行代码导入了 sys 模块中的 argv 成员,这样即可在程序中直接使用 argv 成员,无须使用任何前缀。运行该程序,可以看到如下输出结果:
C:\Users\mengma\Desktop\hello.py
导入模块成员时,也可以为成员指定别名,例如如下程序:
# 导入sys模块的argv成员,并为其指定别名v
from sys import argv as v
# 使用导入成员(并指定别名)的语法,直接使用成员的别名访问
print(v[0])
第 2 行代码导入了 sys 模块中的 argv 成员,并为该成员指定别名 v,这样即可在程序中通过别名 v 使用 argv 成员,无须使用任何前缀。运行该程序,可以看到如下输出结果:
C:\Users\mengma\Desktop\hello.py
form…import 导入模块成员时,支持一次导入多个成员,例如如下程序:
# 导入sys模块的argv,winver成员from sys import argv, winver# 使用导入成员的语法,直接使用成员名访问print(argv[0])print(winver)
上面第 2 行代码导入了 sys 模块中的 argv、 winver 成员,这样即可在程序中直接使用 argv、winver 两个成员,无须使用任何前缀。运行该程序,可以看到如下输出结果(sys 的 winver 成员记录了该 Python 的版本号):
C:\Users\mengma\Desktop\hello.py
3.6
一次导入多个模块成员时,也可指定别名,同样使用 as 关键字为成员指定别名,例如如下程序:
# 导入sys模块的argv,winver成员
from sys import argv, winver
# 使用导入成员的语法,直接使用成员名访问
print(argv[0])
print(winver)
上面第 2 行代码导入了 sys 模块中的 argv、winver 成员,并分别为它们指定了别名 v、wv,这样即可在程序中通过 v 和 wv 两个别名使用 argv、winver 成员,无须使用任何前缀。运行该程序,可以看到如下输出结果:
C:\Users\mengma\Desktop\hello.py
3.6
不推荐使用 from import 导入模块所有成员
在使用 from…import 语法时,可以一次导入指定模块内的所有成员(此方式不推荐),例如如下程序:
#导入sys 棋块内的所有成员
from sys import *
#使用导入成员的语法,直接使用成员的别名访问
print(argv[0])
print(winver)
上面代码一次导入了 sys 模块中的所有成员,这样程序即可通过成员名来使用该模块内的所有成员。该程序的输出结果和前面程序的输出结果完全相同。
需要说明的是,一般不推荐使用“from 模块 import”这种语法导入指定模块内的所有成员,因为它存在潜在的风险。比如同时导入 module1 和 module2 内的所有成员,假如这两个模块内都有一个 foo() 函数,那么当在程序中执行如下代码时:
foo()
上面调用的这个 foo() 函数到底是 module1 模块中的还是 module2 模块中的?因此,这种导入指定模块内所有成员的用法是有风险的。
但如果换成如下两种导入方式:
import module1
import module2 as m2
接下来要分别调用这两个模块中的 foo() 函数就非常清晰。程序可使用如下代码:
#使用模块module1 的模块名作为前缀调用foo()函数
module1.foo()
#使用module2 的模块别名作为前缀调用foo()函数
m2.foo()
或者使用 from…import 语句也是可以的:
#导入module1 中的foo 成员,并指定其别名为foo1
from module1 import foo as fool
#导入module2 中的foo 成员,并指定其别名为foo2
from module2 import foo as foo2
此时通过别名将 module1 和 module2 两个模块中的 foo 函数很好地进行了区分,接下来分别调用两个模块中 foo() 函数就很清晰:
foo1() #调用module1 中的foo()函数
foo2() #调用module2 中的foo()函数
自定义模块
到目前为止,读者已经掌握了导入 Python 标准库并使用其成员(主要是函数)的方法,接下来要解决的问题是,怎样自定义一个模块呢?
前面章节中讲过,Python 模块就是 Python 程序,换句话说,只要是 Python 程序,都可以作为模块导入。例如,下面定义了一个简单的模块(编写在 demo.py 文件中):
name = "Python教程"
add = "http://c.biancheng.net/python"
print(name,add)
def say():
print("人生苦短,我学Python!")
class CLanguage:
def __init__(self,name,add):
self.name = name
self.add = add
def say(self):
print(self.name,self.add)
可以看到,我们在 demo.py 文件中放置了变量(name 和 add)、函数( say() )以及一个 Clanguage 类,该文件就可以作为一个模板。
但通常情况下,为了检验模板中代码的正确性,我们往往需要为其设计一段测试代码,例如:
say()
clangs = CLanguage("C语言中文网","http://c.biancheng.net")
clangs.say()
运行 demo.py 文件,其执行结果为:
Python教程 http://c.biancheng.net/python
人生苦短,我学Python!
C语言中文 http://c.biancheng.net
通过观察模板中程序的执行结果可以断定,模板文件中包含的函数以及类,是可以正常工作的。
在此基础上,我们可以新建一个 test.py 文件,并在该文件中使用 demo.py 模板文件,即使用 import 语句导入 demo.py:
import demo
注意,虽然 demo 模板文件的全称为 demo.py,但在使用 import 语句导入时,只需要使用该模板文件的名称即可。
此时,如果直接运行 test.py 文件,其执行结果为:
Python教程 http://c.biancheng.net/python
人生苦短,我学Python!
C语言中文 http://c.biancheng.net
可以看到,当执行 test.py 文件时,它同样会执行 demo.py 中用来测试的程序,这显然不是我们想要的效果。正常的效果应该是,只有直接运行模板文件时,测试代码才会被执行;反之,如果是其它程序以引入的方式执行模板文件,则测试代码不应该被执行。
要实现这个效果,可以借助 Python 内置的 name 变量。当直接运行一个模块时,name 变量的值为 main;而将模块被导入其他程序中并运行该程序时,处于模块中的 name 变量的值就变成了模块名。因此,如果希望测试函数只有在直接运行模块文件时才执行,则可在调用测试函数时增加判断,即只有当 name ==‘main’ 时才调用测试函数。
因此,我们可以修改 demo.py 模板文件中的测试代码为:
if __name__ == '__main__':
say()
clangs = CLanguage("C语言中文网","http://c.biancheng.net")
clangs.say()
这样,当我们直接运行 demo.py 模板文件时,其执行结果不变;而运行 test.py 文件时,其执行结果为:
Python教程 http://c.biancheng.net/python
显然,这里执行的仅是模板文件中的输出语句,测试代码并未执行。
自定义模块编写说明文档
我们知道,在定义函数或者类时,可以为其添加说明文档,以方便用户清楚的知道该函数或者类的功能。自定义模块也不例外。
为自定义模块添加说明文档,和函数或类的添加方法相同,即只需在模块开头的位置定义一个字符串即可。例如,为 demo.py 模板文件添加一个说明文档:
'''
demo 模块中包含以下内容:
name 字符串变量:初始值为“Python教程”
add 字符串变量:初始值为“http://c.biancheng.net/python”
say() 函数
CLanguage类:包含 name 和 add 属性和 say() 方法。
'''
在此基础上,我们可以通过模板的 doc 属性,来访问模板的说明文档。例如,在 test.py 文件中添加如下代码:
import demo
print(demo.__doc__)
程序运行结果为:
Python教程 http://c.biancheng.net/python
demo 模块中包含以下内容:
name 字符串变量:初始值为“Python教程”
add 字符串变量:初始值为“http://c.biancheng.net/python”
say() 函数
CLanguage类:包含 name 和 add 属性和 say() 方法。
Python __name__==’__main__'作用详解
前面章节已经对模块及其用法做了详解的介绍,相信有很多读者已经开始去尝试阅读别人的代码了(通常阅读比自己牛的人写的代码,会让自己的技术水平飞速提高)。不过,在阅读别人写的自定义模块时,经常会看到有如下这行判断语句:
if __name__ == '__main__':
这行代码的作用是什么呢?本节就详解讲解以下它的作用。
一般情况下,当我们写完自定义的模块之后,都会写一个测试代码,检验一些模块中各个功能是否能够成功运行。例如,创建一个 candf.py 文件,并编写如下代码:
'''
摄氏度和华氏度的相互转换模块
'''
def c2f(cel):
fah = cel * 1.8 + 32
return fah
def f2c(fah):
cel = (fah - 32) / 1.8
return cel
def test():
print("测试数据:0 摄氏度 = %.2f 华氏度" % c2f(0))
print("测试数据:0 华氏度 = %.2f 摄氏度" % f2c(0))
test()
单独运行此模块文件,可以看到如下运行结果:
测试数据:0 摄氏度 = 32.00 华氏度
测试数据:0 华氏度 = -17.78 摄氏度
在 candf.py 模块文件的基础上,在同目录下再创建一个 demo.py 文件,并编写如下代码:
import candf
print("32 摄氏度 = %.2f 华氏度" % candf.c2f(32))
print("99 华氏度 = %.2f 摄氏度" % candf.f2c(99))
运行 demo.py 文件,其运行结果如下所示:
测试数据:0 摄氏度 = 32.00 华氏度
测试数据:0 华氏度 = -17.78 摄氏度
32 摄氏度 = 89.60 华氏度
99 华氏度 = 37.22 摄氏度
可以看到,Python解释器将模块(candf.py)中的测试代码也一块儿运行了,这并不是我们想要的结果。想要避免这种情况的关键在于,要让 Python 解释器知道,当前要运行的程度代码,是模块文件本身,还是导入模块的其它程序。
为了实现这一点,就需要使用 Python 内置的系统变量 name,它用于标识所在模块的模块名。例如,在 demo.py 程序文件中,添加如下代码:
print(__name__)
print(candf.__name__)
其运行结果为:
__main__
candf
可以看到,当前运行的程序,其 name 的值为 main,而导入到当前程序中的模块,其 name 值为自己的模块名。
因此,if __name__ == '__main__': 的作用是确保只有单独运行该模块时,此表达式才成立,才可以进入此判断语法,执行其中的测试代码;反之,如果只是作为模块导入到其他程序文件中,则此表达式将不成立,运行其它程序时,也就不会执行该判断语句中的测试代码。
导入模块的3种方式
很多初学者经常遇到这样的问题,即自定义 Python 模板后,在其它文件中用 import(或 from…import) 语句引入该文件时,Python 解释器同时如下错误:
ModuleNotFoundError: No module named ‘模块名’
意思是 Python 找不到这个模块名,这是什么原因导致的呢?要想解决这个问题,读者要先搞清楚 Python 解释器查找模块文件的过程。
通常情况下,当使用 import 语句导入模块后,Python 会按照以下顺序查找指定的模块文件:
- 在当前目录,即当前执行的程序文件所在目录下查找;
- 到 PYTHONPATH(环境变量)下的每个目录中查找;
- 到 Python 默认的安装目录下查找。
以上所有涉及到的目录,都保存在标准模块 sys 的 sys.path 变量中,通过此变量我们可以看到指定程序文件支持查找的所有目录。换句话说,如果要导入的模块没有存储在 sys.path 显示的目录中,那么导入该模块并运行程序时,Python 解释器就会抛出 ModuleNotFoundError(未找到模块)异常。
解决“Python找不到指定模块”的方法有 3 种,分别是:
- 向 sys.path 中临时添加模块文件存储位置的完整路径;
- 将模块放在 sys.path 变量中已包含的模块加载路径中;
- 设置 path 系统环境变量。
不过,在详细介绍这 3 种方式之前,为了能更方便地讲解,本节使用前面章节已建立好的 hello.py 自定义模块文件(D:\python_module\hello.py)和 say.py 程序文件(C:\Users\mengma\Desktop\say.py,位于桌面上),它们各自包含的代码如下:
#hello.py
def say ():
print("Hello,World!")
#say.py
import hello
hello.say()
显然,hello.py 文件和 say.py 文件并不在同一目录,此时运行 say.py 文件,其运行结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\say.py", line 1, in <module>
import hello
ModuleNotFoundError: No module named 'hello'
可以看到,Python 解释器抛出了 ModuleNotFoundError 异常。接下来,分别用以上 3 种方法解决这个问题。
导入模块方式一:临时添加模块完整路径
模块文件的存储位置,可以临时添加到 sys.path 变量中,即向 sys.path 中添加 D:\python_module(hello.py 所在目录),在 say.py 中的开头位置添加如下代码:
import sys
sys.path.append('D:\\python_module')
注意:在添加完整路径中,路径中的 ‘’ 需要使用 \ 进行转义,否则会导致语法错误。再次运行 say.py 文件,运行结果如下:
Hello,World!
可以看到,程序成功运行。在此基础上,我们在 say.py 文件中输出 sys.path 变量的值,会得到以下结果:
['C:\\Users\\mengma\\Desktop', 'D:\\python3.6\\Lib\\idlelib', 'D:\\python3.6\\python36.zip', 'D:\\python3.6\\DLLs', 'D:\\python3.6\\lib', 'D:\\python3.6', 'C:\\Users\\mengma\\AppData\\Roaming\\Python\\Python36\\site-packages', 'D:\\python3.6\\lib\\site-packages', 'D:\\python3.6\\lib\\site-packages\\win32', 'D:\\python3.6\\lib\\site-packages\\win32\\lib', 'D:\\python3.6\\lib\\site-packages\\Pythonwin', 'D:\\python_module']
该输出信息中,红色部分就是临时添加进去的存储路径。需要注意的是,通过该方法添加的目录,只能在执行当前文件的窗口中有效,窗口关闭后即失效。
导入模块方式二:将模块保存到指定位置
如果要安装某些通用性模块,比如复数功能支持的模块、矩阵计算支持的模块、图形界面支持的模块等,这些都属于对 Python 本身进行扩展的模块,这种模块应该直接安装在 Python 内部,以便被所有程序共享,此时就可借助于 Python 默认的模块加载路径。
Python 程序默认的模块加载路径保存在 sys.path 变量中,因此,我们可以在 say.py 程序文件中先看看 sys.path 中保存的默认加载路径,向 say.py 文件中输出 sys.path 的值,如下所示:
['C:\\Users\\mengma\\Desktop', 'D:\\python3.6\\Lib\\idlelib', 'D:\\python3.6\\python36.zip', 'D:\\python3.6\\DLLs', 'D:\\python3.6\\lib', 'D:\\python3.6', 'C:\\Users\\mengma\\AppData\\Roaming\\Python\\Python36\\site-packages', 'D:\\python3.6\\lib\\site-packages', 'D:\\python3.6\\lib\\site-packages\\win32', 'D:\\python3.6\\lib\\site-packages\\win32\\lib', 'D:\\python3.6\\lib\\site-packages\\Pythonwin']
上面的运行结果中,列出的所有路径都是 Python 默认的模块加载路径,但通常来说,我们默认将 Python 的扩展模块添加在 lib\site-packages 路径下,它专门用于存放 Python 的扩展模块和包。
所以,我们可以直接将我们已编写好的 hello.py 文件添加到 lib\site-packages 路径下,就相当于为 Python 扩展了一个 hello 模块,这样任何 Python 程序都可使用该模块。
移动工作完成之后,再次运行 say.py 文件,可以看到成功运行的结果:
Hello,World!
导入模块方式三:设置环境变量
PYTHONPATH 环境变量(简称 path 变量)的值是很多路径组成的集合,Python 解释器会按照 path 包含的路径进行一次搜索,直到找到指定要加载的模块。当然,如果最终依旧没有找到,则 Python 就报 ModuleNotFoundError 异常。
由于不同平台,设置 path 环境变量的设置流程不尽相同,因此接下来就使用最多的 Windows、Linux、Mac OS X 这 3 个平台,给读者介绍如何设置 path 环境变量。
在 Windows 平台上设置环境变量
首先,找到桌面上的“计算机”(或者我的电脑),并点击鼠标右键,单击“属性”。此时会显示“控制面板\所有控制面板项\系统”窗口,单击该窗口左边栏中的“高级系统设置”菜单,出现“系统属性”对话框,如图 1 所示。
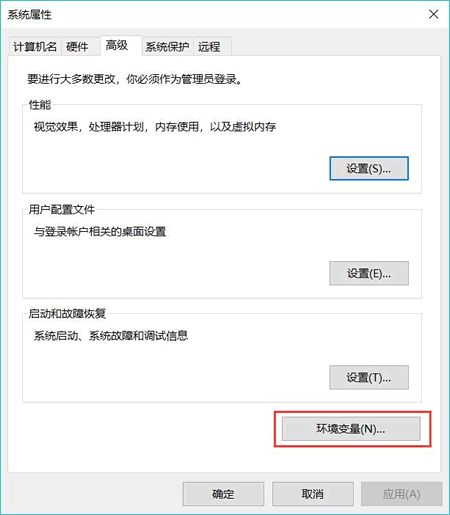
图 1 系统属性对话框
如图 1 所示,点击“环境变量”按钮,此时将弹出图 2 所示的对话框:
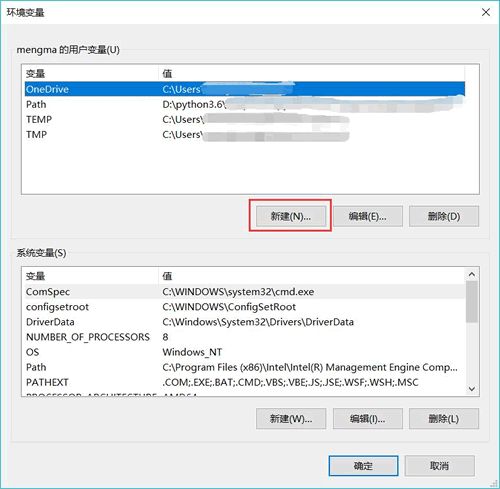
图 2 环境变量对话框
如图 2 所示,通过该对话框,就可以完成 path 环境变量的设置。需要注意的是,该对话框分为上下 2 部分,其中上面的“用户变量”部分用于设置当前用户的环境变量,下面的“系统变量”部分用于设置整个系统的环境变量。
通常情况下,建议大家设置设置用户的 path 变量即可,因为此设置仅对当前登陆系统的用户有效,而如果修改系统的 path 变量,则对所有用户有效。
对于普通用户来说,设置用户 path 变量和系统 path 变量的效果是相同的,但 Python 在使用 path 变量时,会先按照系统 path 变量的路径去查找,然后再按照用户 path 变量的路径去查找。
这里我们选择设置当前用户的 path 变量。单击用户变量中的“新建”按钮, 系统会弹出如图 3 所示的对话框。
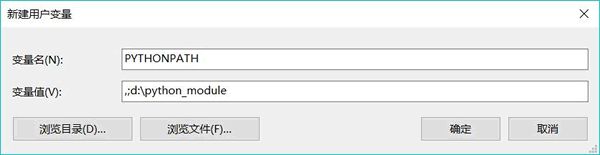
图 3 新建PYTHONPATH环境变量
其中,在“变量名”文本框内输入 PYTHONPATH,表明将要建立名为 PYTHONPATH 的环境变量;在“变量值”文本框内输入 .;d:\python_ module。注意,这里其实包含了两条路径(以分号 ;作为分隔符):
- 第一条路径为一个点(.),表示当前路径,当运行 Python 程序时,Python 将可以从当前路径加载模块;
- 第二条路径为
d:\python_ module,当运行 Python 程序时,Python 将可以从d:\python_ module中加载模块。
然后点击“确定”,即成功设置 path 环境变量。此时,我们只需要将模块文件移动到和引入该模块的文件相同的目录,或者移动到 d:\python_ module 路径下,该模块就能被成功加载。
在 Linux 上设置环境变量
启动 Linux 的终端窗口,进入当前用户的 home 路径下,然后在 home 路径下输入如下命令:
ls - a
该命令将列出当前路径下所有的文件,包括隐藏文件。Linux 平台的环境变量是通过 .bash_profile 文件来设置的,使用无格式编辑器打开该文件,在该文件中添加 PYTHONPATH 环境变量。也就是为该文件增加如下一行:
#设置PYTHON PATH 环境变量
PYTHONPATH=.:/home/mengma/python_module
Linux 与 Windows 平台不一样,多个路径之间以冒号(:)作为分隔符,因此上面一行同样设置了两条路径,点(.)代表当前路径,还有一条路径是 /home/mengma/python_module(mengma 是在 Linux 系统的登录名)。
在完成了 PYTHONPATH 变量值的设置后,在 .bash_profile 文件的最后添加导出 PYTHONPATH 变量的语句。
#导出PYTHONPATH 环境变量
export PYTHONPATH
重新登录 Linux 平台,或者执行如下命令:
source.bash_profile
这两种方式都是为了运行该文件,使在文件中设置的 PYTHONPATH 变量值生效。
在成功设置了上面的环境变量之后,接下来只要把前面定义的模块(Python 程序)放在与当前所运行 Python 程序相同的路径中(或放在 /home/mengma/python_module 路径下),该模块就能被成功加载了。
在Mac OS X 上设置环境变量
在 Mac OS X 上设置环境变量与 Linux 大致相同(因为 Mac OS X 本身也是类 UNIX 系统)。启动 Mac OS X 的终端窗口(命令行界面),进入当前用户的 home 路径下,然后在 home 路径下输入如下命令:
ls -a
该命令将列出当前路径下所有的文件,包括隐藏文件。Mac OS X 平台的环境变量也可通过,bash_profile 文件来设置,使用无格式编辑器打开该文件,在该文件中添加 PYTHONPATH 环境变量。也就是为该文件增加如下一行:
#设置PYTHON PATH 环境变盘
PYTHONPATH=.:/Users/mengma/python_module
Mac OS X 的多个路径之间同样以冒号(:)作为分隔符,因此上面一行同样设置了两条路径:点(.)代表当前路径,还有一条路径是 /Users/mengma/python_module(memgma 是作者在 Mac OS X 系统的登录名)。
在完成了 PYTHONPATH 变量值的设置后,在 .bash_profile 文件的最后添加导出 PYTHONPATH 变量的语句。
#导出PYTHON PATH 环境变量
export PYTHONPATH
重新登录 Mac OS X 系统,或者执行如下命令:
source.bash_profile
这两种方式都是为了运行该文件,使在文件中设置的 PYTHONPATH 变量值生效。
在成功设置了上面的环境变量之后,接下来只要把前面定义的模块(Python 程序)放在与当前所运行 Python 程序相同的路径中(或放在 Users/mengma/python_module 路径下),该模块就能被成功加载了。
__all__变量用法
事实上,当我们向文件导入某个模块时,导入的是该模块中那些名称不以下划线(单下划线“_”或者双下划线“__”)开头的变量、函数和类。因此,如果我们不想模块文件中的某个成员被引入到其它文件中使用,可以在其名称前添加下划线。
以前面章节中创建的 demo.py 模块文件和 test.py 文件为例(它们位于同一目录),各自包含的内容如下所示:
#demo.py
def say():
print("人生苦短,我学Python!")
def CLanguage():
print("C语言中文网:http://c.biancheng.net")
def disPython():
print("Python教程:http://c.biancheng.net/python")
#test.py
from demo import *
say()
CLanguage()
disPython()
执行 test.py 文件,输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
在此基础上,如果 demo.py 模块中的 disPython() 函数不想让其它文件引入,则只需将其名称改为 _disPython() 或者 __disPython()。修改之后,再次执行 test.py,其输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Traceback (most recent call last):
File "C:/Users/mengma/Desktop/2.py", line 4, in <module>
disPython()
NameError: name 'disPython' is not defined
显然,test.py 文件中无法使用未引入的 disPython() 函数。
Python模块__all__变量
除此之外,还可以借助模块提供的 all 变量,该变量的值是一个列表,存储的是当前模块中一些成员(变量、函数或者类)的名称。通过在模块文件中设置 all 变量,当其它文件以“from 模块名 import *”的形式导入该模块时,该文件中只能使用 all 列表中指定的成员。
也就是说,只有以“from 模块名 import *”形式导入的模块,当该模块设有 all 变量时,只能导入该变量指定的成员,未指定的成员是无法导入的。
举个例子,修改 demo.py 模块文件中的代码:
def say():
print("人生苦短,我学Python!")
def CLanguage():
print("C语言中文网:http://c.biancheng.net")
def disPython():
print("Python教程:http://c.biancheng.net/python")
__all__ = ["say","CLanguage"]
可见,all 变量只包含 say() 和 CLanguage() 的函数名,不包含 disPython() 函数的名称。此时直接执行 test.py 文件,其执行结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Traceback (most recent call last):
File "C:/Users/mengma/Desktop/2.py", line 4, in <module>
disPython()
NameError: name 'disPython' is not defined
显然,对于 test.py 文件来说,demo.py 模块中的 disPython() 函数是未引入,这样调用是非法的。
再次声明,all 变量仅限于在其它文件中以“from 模块名 import *”的方式引入。也就是说,如果使用以下 2 种方式引入模块,则 all 变量的设置是无效的。
- 以“import 模块名”的形式导入模块。通过该方式导入模块后,总可以通过模块名前缀(如果为模块指定了别名,则可以使用模快的别名作为前缀)来调用模块内的所有成员(除了以下划线开头命名的成员)。
仍以 demo.py 模块文件和 test.py 文件为例,修改它们的代码如下所示:
#demo.py
def say():
print("人生苦短,我学Python!")
def CLanguage():
print("C语言中文网:http://c.biancheng.net")
def disPython():
print("Python教程:http://c.biancheng.net/python")
__all__ = ["say"]
#test.py
import demo
demo.say()
demo.CLanguage()
demo.disPython()
运行 test.py 文件,其输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
可以看到,虽然 demo.py 模块文件中设置有 all 变量,但是当以“import demo”的方式引入后,all 变量将不起作用。
- 以“from 模块名 import 成员”的形式直接导入指定成员。使用此方式导入的模块,all 变量即便设置,也形同虚设。
仍以 demo.py 和 test.py 为例,修改 test.py 文件中的代码,如下所示:
from demo import say
from demo import CLanguage
from demo import disPython
say()
CLanguage()
disPython()
运行 test.py,输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
Python包及其定义和引用详解
对于一个需要实际应用的模块而言,往往会具有很多程序单元,包括变量、函数和类等,如果将整个模块的所有内容都定义在同一个 Python 源文件中,这个文件将会变得非常庞大,显然并不利于模块化开发。
什么是包
为了更好地管理多个模块源文件,Python 提供了包的概念。那么问题来了,什么是包呢?
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 init.py 文件,该文件夹可用于包含多个模块源文件;从逻辑上看,包的本质依然是模块。
根据上面介绍可以得到一个推论,包的作用是包含多个模块,但包的本质依然是模块,因此包也可用于包含包。典型地,当我们为 Python 安装了 numpy 模块之后,可以在 Python 安装目录的 Lib\site-packages 目录下找到一个 numpy 文件夹,它就是前面安装的 numpy 模块(其实是一个包)。该文件夹的内容如图 1 所示:

图 1 numpy 模块(包)的文件结构
从图 1 可以看出,在 numpy 包(也是模块)下既包含了 matlib.py 等模块源文件,也包含了 core 等子包(也是模块)。这正对应了我们刚刚介绍的:包的本质依然是模块,因此包又可以包含包。
定义包
掌握了包是什么之后,接下来学习如何定义包。定义包更简单,主要有两步:
- 创建一个文件夹,该文件夹的名字就是该包的包名。
- 在该文件夹内添加一个 init.py 文件即可。
下面定义一个非常简单的包。先新建一个 first_package 文件夹,然后在该文件夹中添加一个 init.py 文件,该文件内容如下:
'''这是学习包的第一个示例'''
print('this is first_package')
上面的 Python 源文件非常简单,该文件开始部分的字符串是该包的说明文档,接下来是一条简单的输出语句。
下面通过如下程序来使用该包:
# 导入first_package包(模块)
import first_package
print('==========')
print(first_package.__doc__)
print(type(first_package))
print(first_package)
再次强调,包的本质就是模块,因此导入包和导入模块的语法完全相同。因此,上面程序中第 2 行代码导入了 first_package 包。程序最后三行代码输出了包的说明文档、包的类型和包本身。
运行该程序,可以看到如下输出结果:
this is first package
==========
这是学习包的第一个示例
<class 'module'>
<module 'first_package' from 'G:\\publish\\codes\\09\\9.3\\first_package\\__init__.py'>
从上面的输出结果可以看出,在导入 first_package 包时,程序执行了该包所对应的文件夹下的 init.py;从倒数第二行输出可以看到,包的本质就是模块;从最后一行输出可以看到,使用 import
first_package 导入包的本质就是加载井执行该包下的 init.py 文件,然后将整个文件内容赋值给与包同名的变量,该变量的类型是 module。
与模块类似的是,包被导入之后,会在包目录下生成一个 pycache 文件夹,并在该文件夹内为包生成一个 init.cpython-36.pyc 文件。
由于导入包就相当于导入该包下的 init.py 文件,因此我们完全可以在 init.py 文件中定义变量、函数、类等程序单元,但实际上往往并不会这么做。想一想原因是什么?包的主要作用是包含多个模块,因此 init.py 文件的主要作用就是导入该包内的其他模块。
下面再定义一个更加复杂的包,在该包下将会包含多个模块,并使用 init.py 文件来加载这些模块。
新建一个 fk_package 包,并在该包下包含三个模块文件:
- print_shape.py
- billing.py
- arithmetic_chart.py
fk_package 的文件结构如下:
fk_package
┠──arithmetic_chart.py
┠──billing.py
┠──print_shape.py
┗━━__init__.py
其中,arithmetic_chart.py 模块文件的内容如下:
def print_multiple_chart(n):
'打印乘法口角表的函数'
for i in range(n):
for j in range(i + 1):
print('%d * %d = %2d' % ((j + 1) , (i + 1) , (j + 1)* (i + 1)), end=' ')
print('')
上面模块文件中定义了一个打印乘法口诀表的函数。
billing.py 模块文件的内容如下:
class Item:
'定义代表商品的Item类'
def __init__(self, price):
self.price = price
def __repr__(self):
return 'Item[price=%g]' % self.price
print_shape.py 模块文件的内容如下:
def print_blank_triangle(n):
'使用星号打印一个空心的三角形'
if n <= 0:
raise ValueError('n必须大于0')
for i in range(n):
print(' ' * (n - i - 1), end='')
print('*', end='')
if i != n - 1:
print(' ' * (2 * i - 1), end='')
else:
print('*' * (2 * i - 1), end='')
if i != 0:
print('*')
else:
print('')
tk_package 包下的 init.py 文件暂时为空,不用编写任何内容。
上面三个模块文件都位于 fk_package 包下,总共提供了两个函数和一个类。这意味着 fk_package 包(也是模块)总共包含 arithmetic_chart、 billing 和 print_shape 三个模块。在这种情况下,这三个模块就相当于 fk_package 包的成员。
导入包内成员
如果需要使用 arithmetic_chart、 billing 和 print_shape 这三个模块,则可以在程序中执行如下导入代码:
# 导入fk_package包,实际上就是导入包下__init__.py文件
import fk_package
# 导入fk_package包下的print_shape模块,
# 实际上就是导入fk_package目录下的print_shape.py
import fk_package.print_shape
# 实际上就是导入fk_package包(模块)导入print_shape模块
from fk_package import billing
# 导入fk_package包下的arithmetic_chart模块,
# 实际上就是导入fk_package目录下的arithmetic_chart.py
import fk_package.arithmetic_chart
fk_package.print_shape.print_blank_triangle(5)
im = billing.Item(4.5)
print(im)
fk_package.arithmetic_chart.print_multiple_chart(5)
上面程序中第 2 行代码是“import fk_package”,由于导入包的本质只是加载并执行包里的 init.py 文件,因此执行这条导入语句之后,程序只能使用 fk_package 目录下的 init.py 文件中定义的程序单元。对于本例而言,由于 fk_package_init_.py 文件内容为空,因此这条导入语句没有任何作用。
第 5 行导入语句的本质就是加载并执行 fk_package 包下的 print_shape.py 文件,并将其赋值给 fk_package.print_shape 变量。因此执行这条导入语句之后,程序可访问 fk_package\print_shape.py 文件所定义的程序单元,但需要添加 fk_package.print_shape 前缀。
第 8 行导入语句的本质是导入 fk_package 包(也是模块)下的 billing 成员(其实是模块)。因此执行这条导入语句之后,程序可使用 fk_package\billing.py 文件定义的程序单元,而且只需要添加 billing 前缀。
第 11 行代码与第 5 行代码的导入效果相同。
该程序后面分别测试了 fk_package 包下的 print_shape、billing、arithmetic_chart 这三个模块的功能。运行上面程序,可以看到三个模块的功能完全可以正常显示。
上面程序虽然可以正常运行,但此时存在两个问题:
- 为了调用包内模块中的程序单元,需要使用很长的前缀,这实在是太麻烦了。
- 包内 init.py 文件的功能完全被忽略了。
想一想就知道,包内的 init.py 文件并不是用来定义程序单元的,而是用于导入该包内模块的成员,这样即可把模块中的成员导入变成包内成员,以后使用起来会更加方便。
将 fk_package 包下的 init.py 文件编辑成如下形式:
# 从当前包导入print_shape模块
from . import print_shape
# 从.print_shape导入所有程序单元到fk_package中
from .print_shape import *
# 从当前包导入billing模块
from . import billing
# 从.billing导入所有程序单元到fk_package中
from .billing import *
# 从当前包导入arithmetic_chart模块
from . import arithmetic_chart
# 从.arithmetic_chart导入所有程序单元到fk_package中
from .arithmetic_chart import *
该程序的代码基本上差不多,都是通过如下两行代码来处理导入的:
# 从当前包导入print_shape模块
from . import print_shape
# 从.print_shape导入所有程序单元到fk_package中
from .print_shape import *
上面第一行 from…import 用于导入当前包(模块)中的 print_shape(模块),这样即可在 tk_package 中使用 print_shape 模块。但这种导入方式是将 print_shape 模块导入了 fk_package 包中,因此当其他程序使用 print_shape 内的成员时,依然需要通过 fk_package.print_shape 前缀进行调用。
第二行导入语句用于将 print_shape 模块内的所有程序单元导入 fk_package 模块中,这样以后只要使用 fk_package.前缀就可以使用三个模块内的程序单元。例如如下程序:
# 导入fk_package包,实际上就是导入包下__init__.py文件
import fk_package
# 直接使用fk_package前缀即可调用它所包含的模块内的程序单元。
fk_package.print_blank_triangle(5)
im = fk_package.Item(4.5)
print(im)
fk_package.print_multiple_chart(5)
上面第 2 行代码是导入 tk_package 包,导入该包的本质就是导入该包下的 init.py 文件。而 init.py 文件又执行了导入,它们会把三个模块内的程序单元导入 tk_package 包中,因此程序的下面代码可使用 tk_package.前缀来访问三个模块内的程序单元。
运行上面程序,同样可以看到正常的运行结果。
Python包(存放多个模块的文件夹)
实际开发中,一个大型的项目往往需要使用成百上千的 Python 模块,如果将这些模块都堆放在一起,势必不好管理。而且,使用模块可以有效避免变量名或函数名重名引发的冲突,但是如果模块名重复怎么办呢?因此,Python提出了包(Package)的概念。
什么是包呢?简单理解,包就是文件夹,只不过在该文件夹下必须存在一个名为“init.py” 的文件。
注意,这是 Python 2.x 的规定,而在 Python 3.x 中,init.py 对包来说,并不是必须的。
每个包的目录下都必须建立一个 init.py 的模块,可以是一个空模块,可以写一些初始化代码,其作用就是告诉 Python 要将该目录当成包来处理。
注意,init.py 不同于其他模块文件,此模块的模块名不是 init,而是它所在的包名。例如,在 settings 包中的 init.py 文件,其模块名就是 settings。
包是一个包含多个模块的文件夹,它的本质依然是模块,因此包中也可以包含包。例如,在前面章节中,我们安装了 numpy 模块之后可以在 Lib\site-packages 安装目录下找到名为 numpy 的文件夹,它就是安装的 numpy 模块(其实就是一个包),它所包含的内容如图 1 所示。
图 1 numpy包(模块)
从图 1 可以看出,在 numpy 包(模块)中,有必须包含的 init.py 文件,还有 matlib.py 等模块源文件以及 core 等子包(也是模块)。这正印证了我们刚刚讲过的,包的本质依然是模块,包可以包含包。
Python 库:相比模块和包,库是一个更大的概念,例如在 Python 标准库中的每个库都有好多个包,而每个包中都有若干个模块。
创建包,导入包
《Python包》一节中已经提到,包其实就是文件夹,更确切的说,是一个包含“init.py”文件的文件夹。因此,如果我们想手动创建一个包,只需进行以下 2 步操作:
- 新建一个文件夹,文件夹的名称就是新建包的包名;
- 在该文件夹中,创建一个 init.py 文件(前后各有 2 个下划线‘_’),该文件中可以不编写任何代码。当然,也可以编写一些 Python 初始化代码,则当有其它程序文件导入包时,会自动执行该文件中的代码(本节后续会有实例)。
例如,现在我们创建一个非常简单的包,该包的名称为 my_package,可以仿照以上 2 步进行:
-
创建一个文件夹,其名称设置为 my_package;
-
在该文件夹中添加一个 init.py 文件,此文件中可以不编写任何代码。不过,这里向该文件编写如下代码:
''' http://c.biancheng.net/ 创建第一个 Python 包 ''' print('http://c.biancheng.net/python/')可以看到,init.py 文件中,包含了 2 部分信息,分别是此包的说明信息和一条 print 输出语句。
由此,我们就成功创建好了一个 Python 包。
创建好包之后,我们就可以向包中添加模块(也可以添加包)。这里给 my_package 包添加 2 个模块,分别是 module1.py、module2.py,各自包含的代码分别如下所示(读者可直接复制下来):
#module1.py模块文件
def display(arc):
print(arc)
#module2.py 模块文件
class CLanguage:
def display(self):
print("http://c.biancheng.net/python/")
现在,我们就创建好了一个具有如下文件结构的包:
my_package
┠── __init__.py
┠── module1.py
┗━━ module2.py
当然,包中还有容纳其它的包,不过这里不再演示,有兴趣的读者可以自行调整包的结构。
Python包的导入
通过前面的学习我们知道,包其实本质上还是模块,因此导入模块的语法同样也适用于导入包。无论导入我们自定义的包,还是导入从他处下载的第三方包,导入方法可归结为以下 3 种:
import 包名[.模块名 [as 别名]]from 包名 import 模块名 [as 别名]from 包名.模块名 import 成员名 [as 别名]
用 [] 括起来的部分,是可选部分,即可以使用,也可以直接忽略。
注意,导入包的同时,会在包目录下生成一个含有 init.cpython-36.pyc 文件的 pycache 文件夹。
1) import 包名[.模块名 [as 别名]]
以前面创建好的 my_package 包为例,导入 module1 模块并使用该模块中成员可以使用如下代码:
import my_package.module1
my_package.module1.display("http://c.biancheng.net/java/")
运行结果为:
http://c.biancheng.net/java/
可以看到,通过此语法格式导入包中的指定模块后,在使用该模块中的成员(变量、函数、类)时,需添加“包名.模块名”为前缀。当然,如果使用 as 给包名.模块名”起一个别名的话,就使用直接使用这个别名作为前缀使用该模块中的方法了,例如:
import my_package.module1 as module
module.display("http://c.biancheng.net/python/")
程序执行结果为:
http://c.biancheng.net/python/
另外,当直接导入指定包时,程序会自动执行该包所对应文件夹下的 init.py 文件中的代码。例如:
import my_package
my_package.module1.display("http://c.biancheng.net/linux_tutorial/")
直接导入包名,并不会将包中所有模块全部导入到程序中,它的作用仅仅是导入并执行包下的 init.py 文件,因此,运行该程序,在执行 init.py 文件中代码的同时,还会抛出 AttributeError 异常(访问的对象不存在):
http://c.biancheng.net/python/
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 2, in <module>
my_package.module1.display("http://c.biancheng.net/linux_tutorial/")
AttributeError: module 'my_package' has no attribute 'module1'
我们知道,包的本质就是模块,导入模块时,当前程序中会包含一个和模块名同名且类型为 module 的变量,导入包也是如此:
import my_package
print(my_package)
print(my_package.__doc__)
print(type(my_package))
运行结果为:
http://c.biancheng.net/python/
<module 'my_package' from 'C:\\Users\\mengma\\Desktop\\my_package\\__init__.py'>
http://c.biancheng.net/
创建第一个 Python 包
<class 'module'>
2) from 包名 import 模块名 [as 别名]
仍以导入 my_package 包中的 module1 模块为例,使用此语法格式的实现代码如下:
from my_package import module1
module1.display("http://c.biancheng.net/golang/")
运行结果为:
http://c.biancheng.net/python/
http://c.biancheng.net/golang/
可以看到,使用此语法格式导入包中模块后,在使用其成员时不需要带包名前缀,但需要带模块名前缀。
当然,我们也可以使用 as 为导入的指定模块定义别名,例如:
from my_package import module1 as module
module.display("http://c.biancheng.net/golang/")
此程序的输出结果和上面程序完全相同。
同样,既然包也是模块,那么这种语法格式自然也支持 from 包名 import * 这种写法,它和 import 包名 的作用一样,都只是将该包的 init.py 文件导入并执行。
3) from 包名.模块名 import 成员名 [as 别名]
此语法格式用于向程序中导入“包.模块”中的指定成员(变量、函数或类)。通过该方式导入的变量(函数、类),在使用时可以直接使用变量名(函数名、类名)调用,例如:
from my_package.module1 import display
display("http://c.biancheng.net/shell/")
运行结果为:
http://c.biancheng.net/python/
http://c.biancheng.net/shell/
当然,也可以使用 as 为导入的成员起一个别名,例如:
from my_package.module1 import display as dis
dis("http://c.biancheng.net/shell/")
该程序的运行结果和上面相同。
另外,在使用此种语法格式加载指定包的指定模块时,可以使用 * 代替成员名,表示加载该模块下的所有成员。例如:
from my_package.module1 import *
display("http://c.biancheng.net/python")
init.py作用
查看模块(变量、函数、类)方法
前面章节中,详细介绍了模块和包的创建和使用(严格来说,包本质上也是模块),有些读者可能有这样的疑问,即正确导入模块或者包之后,怎么知道该模块中具体包含哪些成员(变量、函数或者类)呢?
查看已导入模块(包)中包含的成员,本节给大家介绍 2 种方法。
查看模块成员:dir()函数
事实上,在前面章节的学习中,曾多次使用 dir() 函数。通过 dir() 函数,我们可以查看某指定模块包含的全部成员(包括变量、函数和类)。注意这里所指的全部成员,不仅包含可供我们调用的模块成员,还包含所有名称以双下划线“__”开头和结尾的成员,而这些“特殊”命名的成员,是为了在本模块中使用的,并不希望被其它文件调用。
这里以导入 string 模块为例,string 模块包含操作字符串相关的大量方法,下面通过 dir() 函数查看该模块中包含哪些成员:
import string
print(dir(string))
程序执行结果为:
['Formatter', 'Template', '_ChainMap', '_TemplateMetaclass', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_re', '_string', 'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace']
可以看到,通过 dir() 函数获取到的模块成员,不仅包含供外部文件使用的成员,还包含很多“特殊”(名称以 2 个下划线开头和结束)的成员,列出这些成员,对我们并没有实际意义。
因此,这里给读者推荐一种可以忽略显示 dir() 函数输出的特殊成员的方法。仍以 string 模块为例:
import string
print([e for e in dir(string) if not e.startswith('_')])
程序执行结果为:
['Formatter', 'Template', 'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace']
显然通过列表推导式,可在 dir() 函数输出结果的基础上,筛选出对我们有用的成员并显示出来。
查看模块成员:__all__变量
除了使用 dir() 函数之外,还可以使用 __all__变量,借助该变量也可以查看模块(包)内包含的所有成员。
仍以 string 模块为例,举个例子:
import string
print(string.__all__)
程序执行结果为:
['ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace', 'Formatter', 'Template']
显然,和 dir() 函数相比,__all__变量在查看指定模块成员时,它不会显示模块中的特殊成员,同时还会根据成员的名称进行排序显示。
不过需要注意的是,并非所有的模块都支持使用 __all__变量,因此对于获取有些模块的成员,就只能使用 dir() 函数。
__doc__属性:查看文档
在使用 dir() 函数和 all 变量的基础上,虽然我们能知晓指定模块(或包)中所有可用的成员(变量、函数和类),比如:
import string
print(string.__all__)
程序执行结果为:
['ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace', 'Formatter', 'Template']
但对于以上的输出结果,对于不熟悉 string 模块的用户,还是不清楚这些名称分别表示的是什么意思,更不清楚各个成员有什么功能。
针对这种情况,我们可以使用 help() 函数来获取指定成员(甚至是该模块)的帮助信息。以前面章节创建的 my_package 包为例,该包中包含 init.py 、module1.py 和 module2.py 这 3 个模块,它们各自包含的内容分别如下所示:
#***__init__.py 文件中的内容***
from my_package.module1 import *
from my_package.module2 import *
#***module1.py 中的内容***
#module1.py模块文件
def display(arc):
'''
直接输出指定的参数
'''
print(arc)
#***module2.py中的内容***
#module2.py 模块文件
class CLanguage:
'''
CLanguage是一个类,其包含:
display() 方法
'''
def display(self):
print("http://c.biancheng.net/python/")
现在,我们先借助 dir() 函数,查看 my_package 包中有多少可供我们调用的成员:
import my_package
print([e for e in dir(my_package) if not e.startswith('_')])
程序输出结果为:
['CLanguage', 'display', 'module1', 'module2']
通过此输出结果可以得知,在 my_package 包中,有以上 4 个成员可供我们使用。接下来,我们使用 help() 函数来查看这些成员的具体含义(以 module1 为例):
import my_package
help(my_package.module1)
输出结果为:
Help on module my_package.module1 in my_package:
NAME
my_package.module1 - #module1.py模块文件
FUNCTIONS
display(arc)
直接输出指定的参数
FILE
c:\users\mengma\desktop\my_package\module1.py
通过输出结果可以得知,module1 实际上是一个模块文件,其包含 display() 函数,该函数的功能是直接输出指定的 arc 参数。同时,还显示出了该模块具体的存储位置。
当然,有兴趣的读者还可以尝试运行如下几段代码:
#输出 module2 成员的具体信息
help(my_package.module2)
#输出 display 成员的具体信息
help(my_package.module1.display)
#输出 CLanguage 成员的具体信息
help(my_package.module2.CLanguage)
值得一提的是,之所以我们可以使用 help() 函数查看具体成员的信息,是因为该成员本身就包含表示自身身份的说明文档(本质是字符串,位于该成员内部开头的位置)。前面讲过,无论是函数还是类,都可以使用 doc 属性获取它们的说明文档,模块也不例外。
以 my_package 包 module1 模块中的 display() 函数为例,我们尝试用 doc 变量获取其说明文档:
import my_package
print(my_package.module1.display.__doc__)
程序执行结果为:
直接输出指定的参数
其实,help() 函数底层也是借助 doc 属性实现的。
那么,如果使用 help() 函数或者 doc 属性,仍然无法满足我们的需求,还可以使用以下 2 种方法:
- 调用 file 属性,查看该模块或者包文件的具体存储位置,直接查看其源代码(后续章节或详细介绍);
- 对于非自定义的模块或者包,可以查阅 Python 库的参考文档 https://docs.python.org/3/library/index.html。
__file__属性:查看模块的源文件路径
前面章节提到,当指定模块(或包)没有说明文档时,仅通过 help() 函数或者 doc 属性,无法有效帮助我们理解该模块(包)的具体功能。在这种情况下,我们可以通过 file 属性查找该模块(或包)文件所在的具体存储位置,直接查看其源代码。
仍以前面章节创建的 my_package 包为例,下面代码尝试使用 file 属性获取该包的存储路径:
import my_package
print(my_package.__file__)
程序输出结果为:
C:\Users\mengma\Desktop\my_package\__init__.py
注意,因为当引入 my_package 包时,其实际上执行的是 init.py 文件,因此这里查看 my_package 包的存储路径,输出的 init.py 文件的存储路径。
再以 string 模块为例:
import string
print(string.__file__)
程序输出结果为:
D:\python3.6\lib\string.py
由此,通过调用 file 属性输出的绝对路径,我们可以很轻易地找到该模块(或包)的源文件。
注意,并不是所有模块都提供 file 属性,因为并不是所有模块的实现都采用 Python 语言,有些模块采用的是其它编程语言(如 C 语言)。
第三方库(模块)下载和安装(使用pip命令)
进行 Python 程序开发时,除了使用 Python 内置的标准模块以及我们自定义的模块之外,还有很多第三方模块可以使用,这些第三方模块可以借助 Python官方提供的查找包页面(https://pypi.org/)找到。
使用第三方模块之前,需要先下载并安装该模块,然后就能像使用标准模块和自定义模块那样导入并使用了。因此,本节主要讲解如何下载并安装第三方模块。
下载和安装第三方模块,可以使用 Python 提供的 pip 命令实现。pip 命令的语法格式如下:
pip install|uninstall|list 模块名
其中,install、uninstall、list 是常用的命令参数,各自的含义为:
- install:用于安装第三方模块,当 pip 使用 install 作为参数时,后面的模块名不能省略。
- uninstall:用于卸载已经安装的第三方模块,选择 uninstall 作为参数时,后面的模块名也不能省略。
- list:用于显示已经安装的第三方模块。
以安装 numpy 模块为例(该模块用于进行科学计算),可以在命令行窗口中输入以下代码:
pip install numpy
执行此代码,它会在线自动安装 numpy 模块。安装完成后,将显示图 1 所示的结果:
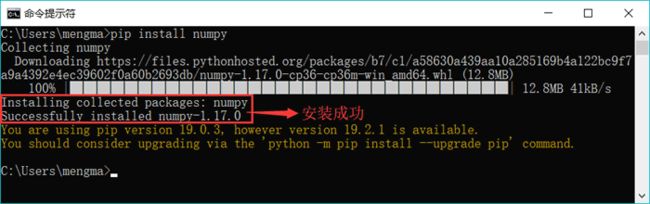
图 1 numpy 模块安装成功示意图
pip 命令会将下载完成的第三方模块,默认安装到 Python 安装目录中的 \Lib\site-packages 目录下。打开此目录,你就会发现 numpy 包,也就是 numpy 文件夹,如图 2 所示。

图 2 numpy 包内容示意图
前面讲过,对于向程序中导入模块,\Lib\site-packages 目录是 Python 肯定会搜索的目录,因此位于此目录的模块,可以直接使用 import 语句引入,例如:
#直接导入 numpy 模块即可import numpy as nu#用 numpy 模块中的开发函数print(nu.sqrt(16))
运行结果为:
4.0
通过 pip 命令,我们可以下载并安装很多第三方模块,如果想要查看 Python 中目前有哪些模块(包括标准模块和第三方模块),可以在 IDLE 中输入以下命令:
help(‘modules’)
在此基础上,如果只是想要查看已经安装的第三方模块,可以在使用如下命令:
pip list
提示:在大型程序中,往往需要导入很多模块,建议初学者在导入模块时,优先导入 Python 提供的标准模块,然后再导入第三方模块,最后导入自定义模块。