C++学习笔记 (三)
文章目录
- 第一章 什么是C++
-
- 1.1 C++之父
- 1.2 历史背景
- 1.3 应 “运” 而生,运为何
- 1.4 发展计事
-
- 1.4.1 现代 C++
- 1.5 语言地位
- 1.6 应用领域
-
- 1.6.1 系统层软件开发
- 1.6.2 服务器程序开发
- 1.6.3 游戏网络分布式云计算
- 1.6.4 丰富的库类
- 1.7 开发环境
-
- 1.7.1 QT/VS
- 第二章 C++类型增强
-
- 2.1 Type enhance 类型增强
-
- 2.1.1 更严格的类型检查
- 2.1.2 bool类型
- 2.1.3 真正的枚举
- 2.1.4 可被赋值的表达式
- 2.1.5 nullptr (C++11)
- 2.2 Input/Output 标准输入与输出
-
- 2.2.1 cout的格式化输出:
- 2.2.2 cout的预宽,左右对齐
- 2.2.3 设置浮点数精度
- 2.3 函数重载
- 2.3.1 重载底层实现
- 2.3.2 extern "C"
- 2.4 Op Overload 运算符重载
- 2.5 默认参数(Default Arg)
-
- 2.5.1 规则冲突
- 2.6 & 引用(Reference)
-
- 2.6.1 定义
- 2.6.2 引用的应用
- 2.6.3 引用的提高
-
- 2.6.3.1指针的引用-有, 引用的指针-无
- 2.6.3.2 指针的指针-有,引用的引用-无
- 2.6.3.3 指针的数组-有,引用的数组-无
- 2.6.3.4 数组的引用
- 2.7 常引用
- 2.7.1 Const Semantic
-
- 2.7.1.2 常引用的特性
- 2.7.1.3 临时对象的常引用
- 2.8 引用的本质
- 2.9 new/delete 堆内存操作
-
- 2.9.1 new/new[]
-
- 2.9.1.1 单变量
- 2.9.1.2 申请一或多维数组
- 2.9.1.3 指针数组的申请
- 2.9.2 delete
- 2.9.3 返值判断
-
- 2.9.3.1 失败退出
- 2.9.3.2 异常机制trycatch
- 2.9.3.3 设置回调 set_new_handler
- 2.9.4 使用规则
- 2.10 内联函数(inline function)
- 2.11 Cast类型强转
-
- 2.11.1 C -> C++Style
- 2.11.2 static_cast
-
- 2.11.2.1 语法
- 2.11.3 reinterpret_cast
-
- 2.11.3.1 语法
- 2.11.3 const_cast(去const化)
-
- 2.11.3.1 语法
- 2.12 String字符串类
-
- 2.12.1 定义
-
- 2.12.1.1 大小
- 2.12.1.2 初始化 / 输入与输出
- 2.12.1.3 长度 - size()
- 2.12.1.4 拼接
- 2.12.1.5 比较
- 2.12.1.6 拷贝
- 2.12.1.7 to_string
- 2.12.1.7 stoi
- 2.13 总结
- 2.14 namespace 命名空间
-
- 2.14.1 why namespace?
- 2.14.2 C语言的命名空间
- 2.14.3 C++的命名空间
-
- 2.14.3.1 全局无名命名空间( :: )
- 2.14.3.2 命名空间的使用
- 2.14.3.3 命名空间的嵌套
- 2.14.3.4 命名空间的协同开发
- 第三章 封装 (Encapsulation)
-
- 3.1 C struct数据封装
- 3.2 从 struct 到 class
- 第四章 类(Class)
- 4.1 init 到 自动化
- 4.2 自动初始化
-
- 4.2.1 构造器(Constructor):
- 4.2.2 重载
- 4.2.3 默认参数
- 4.2.4 初始化参数列表(initialize list)
-
- 4.2.4.1 初始化列表
- 4.2.4.2 列表的初始化顺序
- 4.3 析构器(Destructor)
-
- 4.3.1 析构器
- 4.3.2 语法
- 4.3.3 特性
- 4.4 层次内存管理
-
- 4.5.1 引例
- 4.5.2 层次管理
- 4.6 拷贝构造器 (Copy Constructor)
-
- 4.6.1 发生时机
- 4.6.2 语法定义
- 4.6.3 浅(shallow)/深(deep)拷贝
- 4.7 this指针
-
- 4.7.1 指向调用对象的指针
- 4.7.2 特性
- 4.7.3 作用
- 4.8 赋值运算符重载(operator =)
-
- 4.8.1 发生时机
- 4.8.2 语法
- 4.8.3 特性
- 4.8.4 问题的解决
- 4.9 自实现string类
- 4.10 栈对象返回问题
-
- 4.10.1 C++返回栈对象
-
- 4.10.1.1 传值
- 4.10.1.2 传引用
- 4.10.1.3 RVO/NRCO
- 4.10.1.4 栈对象接受
- 4.10.1.5 返回栈引用
- 4.11 对象数组
-
- 4.11.1 二段式初始化
- 4.12 实现钟表类 class Clock
- 4.13 实现汽车类 class MyCar
- 第五章 类的扩展(Class' Extension)
-
- 5.1 类成员储存(class memeber storage)
-
- 5.1.1 类大小 sizeof(class)
- 5.1.2 类成员函数可能的储存方式
- 5.1.3 类成员函数的实际储存方式
- 5.1.4 this 至关重要的存在
- 5.1.5 注意事项
- 5.2 const in class
-
- 5.2.1 const data member
- 5.2.2 const 修饰函数成员
-
- 5.2.2.1 const修饰函数的位置
- 5.2.2.2 const成员函数的意义
- 5.2.2.3 小结
- 5.2.2.4 const 修饰对象
- 5.2.3 static 修饰类
-
- 5.2.3.1 static data member
-
- 5.2.4.1.1 语法规则
- 5.2.4.2 使用
-
- 5.2.4.1.1 统计函数调用次数
- 5.2.4.1.2 案例:一塔湖图
- 5.2.4.2 static修饰成员函数
- 5.2.4.2.1 案例:取号服务
- 5.3.1 单例模式
- 5.3.1 渲染树 (Render Tree)
- 5.4 ststic const in class
- 5.5 指向类成员的指针
-
- 5.5.1 语法
- 5.5.1 应用
- 5.5.1.1 更加统一的接口
- 5.5.1.2 更加隐蔽的接口
- 5.5.6 指针 or 偏移量
- 5.5.7 指向类静态成员的指针
- 第六章 友元
-
- 6.1 为什么需要友元
-
- 6.1.1 get / set method
- 6.1.2 实现
- 6.1.3 效率是项目中的重中之重
- 6.1.4 why friend
- 6.2 关系辨别 (relationship)
-
- 6.2.1 同类间无私处 mstring
- 6.2.2 异类间有友元 struct -> class
- 6.2.3 友元不是成员
- 友元函数 Freind Function
-
- 6.3.1 全局函数作友元
- 6.3.2 成员函数作友元
- 6.6.3 前向声明ForwardDeclaration
- 6.4 友元类 Friend class
-
- 6.4.1 原由
- 6.4.2 声明
- 6.4.3 应用
- 6.5 总结
-
- 6.5.1 声明位置
- 6.5.2 友元利弊
- 6.5.3 注意
- 第七章 运算符重载Operator Overload
-
- 7.1重载引入
-
- 7.1.1 语法格式
- 7.1.2 友元重载
- 7.1.3 成员重载
- 7.1.4 const作返值修饰符
- 7.2 重载规则
-
- 7.2.1 可被重载的操作符
- 7.2.2 不能新增运算符
- 7.2.3 不能改变操作数的个数
- 7.2.4 不改变语义
- 7.2.5 至少有一个操作数是自定义类
- 7.2.6 其他
- 7.3 重载范例
-
- 7.3.1 双目例举
-
- 7.3.1.1. 格式
- 7.3.1.2 operator+=
- 7.3.2 单目例举
-
- 7.3.2.1 格式
- 7.3.2.2 operator- (minus)
- 7.3.2.3 operator++ ()
- 7.3.2.4 operator++ (int)
- 7.3.2.5. 匿名对象的知多少
- 7.4 实战
-
- 7.4.1 成员函数作谁的-成员?友元?
-
- 7.4.4.1 引例
- 7.3.4 非全局莫属 operator << / >>
- 7.5 自定义类型转化 User-DefinedTypeCast
-
- 7.5.1 标准类型转换
-
- 7.5.1.1 隐式转化
- 7.5.1.2 强制转化
- 7.5.2 自定义类型-转化构造函数
-
- 7.5.2.1 语法
- 7.5.2.2 特性
- 7.5.2.3 实现
- 7.5.2.4 explicit 关键字
- 7.5.3 自定义类型-操作符函数转化
-
- 7.5.3.1 语法
- 7.5.3.2 特性
- 7.5.3.3 实现
- 7.6 高级主题扩展
-
- 7.6.1 仿函数 (Functor)
-
- 7.6.1.1 语法格式
- 7.6.1.2 示例
- 7.6.1.3 sort中的回调
- 7.6.1.4 functor 的优势
- 7.7.2 对象模拟指针(Smart Point)
-
- 7.7.2.1 什么是RAII
- 7.7.2.2 auto_ptr
- 7.7.2.3 auto_ptr 自实现
- 7.7.3 operator new/delete预定义的内存
-
- 7.2.3.1 operator new/delete语法格式
- 7.2.3.2 全局重载
- 7.2.3.3 实现
第一章 什么是C++
1.1 C++之父
1979 年,美国 AT&T 公司贝尔实验室的 Bjarne Stroustrup 博士在 C语言的基础上引 入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与C语言的渊源 关系,它被命名为C++。而Bjarne Stroustrup(本贾尼·斯特劳斯特卢普)博士被尊称为C++ 语言之父。

1.2 历史背景
C语言作为结构化和模块化的语言,在处理较小规模的程序时,比较得心应手。但是 当问题比较复杂,程序的规模较大的时,需要高度的抽象和建模时,C语言显得力不从心。
1.3 应 “运” 而生,运为何
说这个之前,什么是面向过程编程,什么是面向对象编程,这两个东西呢。只是一种思想而已,就像二级指针和一级指针,只是对格式化内存空间不同逻辑思想而已,简单概括以下就是如下区别:
- 面向过程:编写函数
- 面向对象:编写类
为了解决软件危机,20 世纪 80 年代,计算机界提出了 OOP(Object Oriented Programming)思想,这需要设计出支持面向对象的程序设计语言。Smalltalk 就是当时问 世的一种面向对象的语言。而在实践中,人们发现C语言是如此深入人心,使用如此之广 泛,以至于最好的办法,不是发明一种新的语言去取代它,而是在原有的基础上发展它。 在这种情况下 C++应运而生,在C的基础之上添加面向对象的功能,最初这门语言并 不叫 C++而是 Cwith class (带类的C)。
1.4 发展计事
1.4.1 现代 C++
- 1979 April :Work on C withClasses began
- 1979 October:First C with Classes(Cpre)running
- 1984: C++ named
- 1985 October: Cfront Release 1.0 (firstcommercialrelease) The C++ Programming Language
- 1987 December: First GNU C++ release(1.13)
- 1989:The Annotated C++ Reference Manual; ANSI C++ committee (J16) founded (Washington,DC)
- 1994 string:(templatized by character type) (San Diego, California); the STL accepted(SanDiego,CAandWaterloo,Canada)
- 1998:ISO C++ standard ratified
- 2003:Technical Corrigendum; workon C++0x started
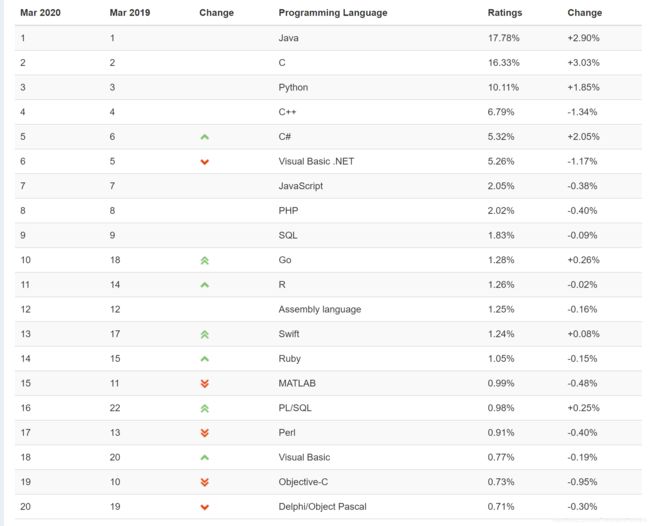
1.5 语言地位
1.6 应用领域
效率重要,且同时需要好的抽象机制的领域。几乎涵盖了,底层的操作系统层,主流 服务器层和主流开发框架层。
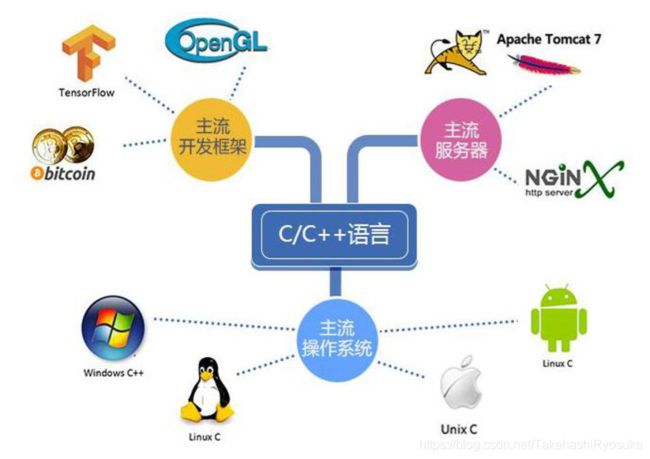
1.6.1 系统层软件开发
C++的语言本身的高效和面向对象,使其成为系统层开发的不二之选。比如我们现在用 的window 桌面,GNOME 桌面系统,KDE 桌面系统。
1.6.2 服务器程序开发
面向对像,具有较强的抽像和建模能力。使其在电信,金融,电商,通信,媒体,交 换路由等方面中不可或缺。
1.6.3 游戏网络分布式云计算

1.6.4 丰富的库类
MFC/QT/ACE/Boost/Cocos/CrossApp/Unreal
1.7 开发环境
1.7.1 QT/VS
VS更为强大,QT更为小清新
第二章 C++类型增强
曾有人戏谑的说,C++作为一种面向对象的语言,名字起的不好,为什么呢?用 c 的 语法来看,++ 操作符是 post++,即后++。 post++,即意味着,对C语言的扩展和兼容。扩展即面向对象的扩充,兼容能否作到 百分之百呢?
2.1 Type enhance 类型增强
2.1.1 更严格的类型检查
C语言中 const * ->non-const* / void* ->sometype * / type *-> type * 均是可以的, ->的方向代表转化方向。
最直接的证明就是,c++ 里的const就是一个名副其实的const了。
2.1.2 bool类型
C 语言中没有逻辑类型,C中的逻辑的真假,用 0 表示逻辑真,而非 0 来表示逻辑的假。
而 C++中有了具体的类型,即 bool 类型,有两个值可供选择,true 和 false。但其本 质,仍是一个 char类型的变量,可被 0和非 0的数据赋值。
bool类型的值,除了true 和false以后,还可以被其它类型赋值的。当用sizeof来求 bool类型的大小的时候,发现其大小是1,即一个字节,也就是 char类型的大小。
2.1.3 真正的枚举
C语言中枚举元素类型本质就是整型,枚举变量可以用任意整型赋值。而C++中枚举 变量,只能用被枚举出来的元素赋值。
2.1.4 可被赋值的表达式
C语言中表达式通常不能作为左值的,即不可被赋值, C++中某些表达式是可以赋值的。
2.1.5 nullptr (C++11)
为了避免引起调用或语义上的混淆,C++11,此入了nullptr 用于区分,NULL 和0
2.2 Input/Output 标准输入与输出
cin 和 cout 是 C++的标准输入和输出流对象。他们在头文件 iostream 中定义,其意 义作用类似于 C语言中的 scanf和printf。

scanf和printf 的本质是函数, 而cin和cout是类对象。
#include 但是cin与scanf一样,都是不安全的:
int main(int argc, char** argv)
{
char buf[10];
cin >> buf;
cout << buf << endl;
system("pause");
return 0;
}
虽然是buf[10], 但是输入大于10个字符的时候,还是大概率行得通。
我们可以使用getline来弥补这一行为:
int main(int argc, char** argv)
{
char buf[10];
cin.getline(buf, 10);
cout << buf << endl;
system("pause");
return 0;
}
输出如下:

但是,最保险的,还是使用string类型,只是c++比起c新添加的类型,在c++中会取代字符数组:
int main(int argc, char** argv)
{
string buf;
cin >> buf;
cout << buf << endl;
system("pause");
return 0;
}
但是,有时候也是不能取代的。这个string到底有多大呢?不妨看一下:
int main(int argc, char** argv)
{
string buf;
cin >> buf;
cout << buf.max_size() << endl;
system("pause");
return 0;
}
输出是2147483647,也就是有符号int的最大值,超过这个值就是不安全的。所以,别超过这个值。
2.2.1 cout的格式化输出:
既然cout是为了取代printf的,那么总得拿出点实力来说服我们他确实比printf方便。就拿格式化输出来说,用法如下:
int main(int argc, char** argv)
{
int a = 30;
cout << a << endl;
cout << hex << a << endl; //16进制
cout << oct << a << endl;//8进制
cout << a << endl; //在上一句中已经将默认输出设置为8进制了
cout << dec << a << endl; //十进制输出
system("pause");
return 0;
}
2.2.2 cout的预宽,左右对齐
设置预宽,需要包含头文件 iomanip,然后使用set()来设置。
int main(int argc, char** argv)
{
float ft = 1.234;
cout << setw(10) << ft << setw(10) << endl;
system("pause");
return 0;
}
左右对齐则需要用到setiosflags()来设置:
int main(int argc, char** argv)
{
float ft = 1.234;
cout << setw(10) << setiosflags(ios::left) << ft << endl;
cout << setw(10) << setiosflags(ios::right) << ft << endl;
system("pause");
return 0;
}
还有一个问题就是填充,现在默认是填充空格。我们能不能用其他字符来填充呢?可以使用setfill()来设置填充比如我们要输出时间12:03:01呢?可以通过以下来设置格式:
int main(int argc, char** argv)
{
int a = 12, b = 3, c = 1;
cout << setfill('0') << setw(2) << a << ":" << setw(2) << b << ":" << setw(2) << c << endl;
system("pause");
return 0;
}
以下是一个练习刷频时间的小练习:
void ShowTime()
{
system("cls");
time_t lt = time(nullptr);
time(<);
struct tm time_now;
localtime_s(&time_now, <);
int hour, min, sec;
hour = (&time_now)->tm_hour;
min = (&time_now)->tm_min;
sec = (&time_now)->tm_sec;
cout << setfill('0') << setw(2) << hour << ":" << setw(2) << min << ":"
<< setw(2) << sec << endl;
}
int main(int argc, char** argv)
{
while (1)
{
ShowTime();
Sleep(1000);
}
system("pause");
return 0;
}
2.2.3 设置浮点数精度
还有一个点需要讲,就是设置浮点数精度。我们可以使用setprecision()来设置。
int main(int argc, char** argv)
{
float ft = 1.23456;
cout << setprecision(2) << ft << endl;
system("pause");
return 0;
}
这个时候,setprecision(2)代表有效数字为2;
cout << setprecision(2) << setiosflags(ios::fixed) << ft << endl;
这个时候,则表示小数位数为2位。
2.3 函数重载
函数重载会出现重名的函数,重名的函数会根据语境来决定声明。
运算符重载也是函数重载
重载的特点:
- 函数的函数名相同
- 函数的参数,类型,个数不同,皆可以构成重载。
- 函数返回值的类型不能作为函数重载的标志。
int AbsNum(int a)
{
return a > 0 ? a : -a;
}
float AbsNum(float a)
{
return a > 0 ? a : -a;
}
int main(int argc, char** argv)
{
int a = -5;
float b = -5.12;
cout << AbsNum(a) << endl;
cout << AbsNum(b) << endl;
system("pause");
return 0;
}
注意:C++允许 int 到 long 和 double, double 到 int 和 float, int 到 short 和 char 等隐式转换,遇到这种情形,则会引起二义性。
2.3.1 重载底层实现
C++利用Name Mangling(命名倾轴)技术,来改变函数名,区分参数不同的函数名。实现原理:vcifld 表示void int float long double 及其引用。在底层实现时,函数名在编译器层面上已经不一样了。
void Foo(double a) // Foo_d
{
cout << "double" << endl;
}
void Foo(long a) //Foo_l
{
cout << "long" << endl;
}
2.3.2 extern “C”
C/C++的编译都是以文件为单位进行编译的。 Name Mangling(命名倾轧) 依据函数声明来进行倾轧的。若声明被倾轧,则调用为倾轧版本,若声明为非倾轧版本,则调用也为非倾轧版本。 C++ 默认所有函数倾轧。若有特殊函数不参与倾轧,则需要使用 extercn “C” 来进行 声明。
2.4 Op Overload 运算符重载
前面用到的运算符<<,本身在C语言中,是位操作中的左移运算符。现在又用作流插入运算符,这种一个运算符多种用处的现像叫作运算符重载。在C语言中本身就有重载的现像,比如 & 既表示取地址,又表示位操作中的与运算。 *既表示;解引用,又表示乘法运算符。只不过此类功能,C语言并没有对开发者开放这类功能。 C++提供了运算符重载机制。可以为自定义数据类型重载运算符。实现构造数据类型也可以像基本数据类型一样的运算特性。比如,我们可以轻松的实现基本数据类型 3+5的运算,确实不能实现两个结构体类型变量相加的运算。
记得之前写的·贪吃蛇游戏的时候,我们需要补比较蛇头与食物的位置是否一样时,我们不能直接在比较 snakeHead.pos == food.pos, 而是分别比较了 x 与 y 的值,这就很不方便:
int IfEatFood(Snake* sh, Food* fd)
{
if (sh->pos_.x_ == fd->pos_.x_ && sh->pos_.y_ == fd->pos_.y_)
return 1;
return 0;
}
这样就很繁琐,C++ 对用户开放了这一系列功能:
typedef struct _pos {
int x_;
int y_;
}Pos;
bool operator ==(Pos one, Pos another)
{
if (one.x_ == another.x_ && one.y_ == another.y_)
{
return true;
}
return false;
}
//运算符重载
int main(int argc, char** argv)
{
Pos ps = {
1,2 };
Pos fdPs = {
1,2 };
if (ps == fdPs) //本质就是operator ==(ps, fdPs)
cout << "equl" << endl;
else
cout << "not equl" << endl;
system("pause");
return 0;
}
2.5 默认参数(Default Arg)
通常情况下,函数在调用时,形参从实参那里取得值。C++给出了可以不用从实参取 值的方法,给形参设置默认值,称为默认参数。默认值,则是一种最为常见的情况,是对真实生活的模似,生活中很难找出没有默认 的东西。(例如,**杀人偿命,欠债还钱 **)故,C++引入默认参数,也是为了方便编程。
默认规则:
- 从右往左,不能跳跃
void Foo(int a=1, int b, int c = 5)
{
cout << "a = " << a << ", b = " << b << ", c = " << c << endl;
}
这样设计坚决不行的,设置默认值必须从右往左且不能跳跃
- 实参个数 + 默认个数 >= 形参个数
void Foo(int a, int b = 0, int c = 0)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main(int argc, char** argv)
{
Foo(5,4); // 2 + 2 = 4
Foo(1); // 1 + 2 = 3
Foo(); // 0 + 2 = 2 < 3 编译不通过
}
- 声明和实现不在一起的时候,默认参数出现在声明中(可能由于编译器不同而不同)
- 默认参数可以是一个常量,全局变量,亦或是一个函数。
2.5.1 规则冲突
重载与默认参数的冲突。这是一个无解的冲突。
- 当实现同一个功能的时候,既可以使用默认参数,也可以使用重载,但是推荐使用默认参数。
void Foo(int a, int b = 0, int c = 0)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
void Foo()
{
cout << " NULL " << endl;
}
2.6 & 引用(Reference)
2.6.1 定义
变量名,本身是一段内存的引用,即别名(alias)此处引入的引用,是为已知变量起的一个别名。
声明如下:
int main(int argc, char** argv)
{
int a = 0;
int& ra = a;
return 0;
}
此处的 ra 与 a 是的等价关系。此处 ra 是一种声明关系,不开辟额外的空空间。且必须初始化,不能单独存在。与被别名的变量拥有相同的数据类型。
引用关系一旦确定,便不可变更:
int main(int argc, char** argv)
{
int a = 0;
int b = 1;
int& ra = a;
cout << ra << endl;
ra = b;
cout << ra << endl;
return 0;
}
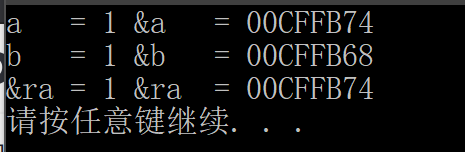
输出如下:

可能会误以为引用已经变更到 b 身上了,其实并没有,这里等价于:
int a = 0, b = 1;
int & ra = a;
ra = b // a = b;
cout << ra << endl; // cout << a << endl;
所以是直接更改了a的值,可以通过取地址来证明:
我们可以对一个变量建立多个引用,此时所有的引用都是一种平行关系。如下:
int main(int argc, char** argv)
{
int a = 0;
int& ra_1 = a;
int& ra_2 = a;
int& ra_3 = ra_2;
return 0;
}
2.6.2 引用的应用
C++很少使用独立变量的引用,如果使用某一个变量,就直接使用它的原名,没有必要使用他的别名。
引用的真正目的,就是取代指针传参。C++引入引用后,可以用引用解决的问题。避免用指针来解决。
还记得怎么交换两个int吗?
void MySwape(int* pa, int* pb)
{
int t = *pa;
*pa = *pb;
*pb = t;
}
//引用的应用
int main(int argc, char** argv)
{
int a = 0, b = 5;
cout << a << " " << endl;
cout << b << " " << endl;
MySwape(&a, &b);
cout << a << " " << endl;
cout << b << " " << endl;
return 0;
}
但是在这里,引用可以完全取代指针,这也正是他的作用所在:
void MySwape(int& ra, int& rb)
{
int t = ra;
ra = rb;
rb = t;
}
//引用的应用
int main(int argc, char** argv)
{
int a = 0, b = 5;
cout << a << " " << endl;
cout << b << " " << endl;
MySwape(a, b);
cout << a << " " << endl;
cout << b << " " << endl;
return 0;
}
效果一模一样。传引用等价于传作用域。把一个变量以引用的方式传到另外一个作用域。等价于扩展了该变量的作用域。
2.6.3 引用的提高
2.6.3.1指针的引用-有, 引用的指针-无
引用的本质是指针,C++对裸露的内存地址(指针)作了一次包装。又取得了指针的优良特性,避免使用裸露的地址。所以再对引用取地址,建立引用的指针没有意义
指针的引用如下:
void MySwape(const char*& p, const char* & q)
{
const char* t = p;
p = q;
q = t;
}
//指针的引用
int main(int argc, char ** argv)
{
const char* p = "China";
const char* q = "Canada";
MySwape(p, q);
cout << "p = " << p << endl;
cout << "q = " << q << endl;
system("pause");
return 0;
}
这告诉我们,原来需要用二级指针解决的事情,现在只需要在平级内解决。这是很棒的东西,不用再指来指去。
对于引用的指针类型,C++避免了对引用再次开放。
const char*& rp = p;
const char&* prp = &re;
这样是编译不过去的。
2.6.3.2 指针的指针-有,引用的引用-无
指针的指针,即二级指针。C++为了避免C语言设计指针的"失误",避免了引用的引用这种情况。由此,也避免了引用的引用的引用的…的引用的情况,这种可穷递归的设计本身就是有问题的。
指针的指针如下:
int main(int argc, char** argv)
{
int a = 5;
int* p = &a;
int** pp = &p;
int*** ppp = &pp;
system("pause");
return 0;
}
这里所讨论的引用的引用,并非之前讨论的对引用再次引用,如下:
int a = 5;
int& ra = a;
int& raa = ra;
int& raaa = raa;
这种情况是完全允许的,因为ra,raa,raaa都是a的别名,他们是平级关系。我所说的是下面这个情况:
int a = 5;
int& ra = a;
int&& raa = ra;
这样就叫作对引用再次引用,也就是二级引用,和二级指针的思想一样。但是这种是编译不过的,在C++里不存在这种逻辑。如果放开这个逻辑的话,接下来就会出现三级引用, 四级引用, 五级引用。。。这样就刹不住车了,不也就成为了另外的一个指针吗?平级就能解决的问题,为什么又要去跨层解决?
2.6.3.3 指针的数组-有,引用的数组-无
看下面的几个情况:
int a, b, c;
int *p[] = {
&a, &b, &c};//指针数组
int & q[] = {
a, b, c};//引用数组
其中,第二个是铁定编译不过去的。
可以通过反证法来证明。
第一个例子,指针数组的首元素是 int * 型,所以首元素的地址就是 int ** ·型的。
第二个例子, 引用数组的首元素是 int &型,所以首元素的地址就应该是 int & * 的,我们知道,引用的指针是不存在的,所以第二个是编译不过去的。
2.6.3.4 数组的引用
数组是一种构造类型,那么数组可以被引用吗?
答案是可以的。
数组名,本质是一个常量指针,对于指针是可以取引用的,所以数组的引用是存在的, 如下示例。
数组名代表了首元素地址,也是整个数组的唯一标识符。那么就从这个地方出发去研究, 先研究当数组名代表首元素地址时的情况:
int main(int argc, char** argv)
{
int arr[5] = {
0,1,2,3,4 };
int* const& parr = arr;
for (int i = 0; i < 5; i++)
{
cout << parr[i] << endl;
}
system("pause");
return 0;
}
其次是数组名当作一个整体,代表整个数组的情况。int arr[5] 实际上是 int[5] 类型的,可得:
- int[5] &parr = arr, 换写成 int &arr[5],由于我们知道,引用的数组是不存在的,那么又可得:
- int (&arr)[10] = arr
2.7 常引用
2.7.1 Const Semantic
C++中 const 定义的变量称为常变量。const 修饰的变量,有着变量的形式,常量的作用,用作常量,常用于取代#define 定义的宏常量。
2.7.1.2 常引用的特性
const的本意,即不可修改。所以,const对象,只能声明为const 引用,使其语义保持一致性。 non-const 对象,既可以声明为 const 引用,也可以声明为 no-const 引用。 声明为const引用,则不可以通过const 引用修改数据。
int main(int argc, char** argv)
{
const int a = 100;
const int & ra = a;
int b = 200;
const int& rb = b;// 只具备读的功能。
int c = rb + ra;
system("pause");
return 0;
}
2.7.1.3 临时对象的常引用
临时对象,通常理解为不可以取地址的对象,比如函数的返回值,即Cpu中计算产生的中间变量通常称为右值。常见临时值有常量,表达式等。
以下办法是行不通的:
int& a = 55;
但是,我们可以用常引用来引用它:
const int& a = 55;
也可以对表达式进行引用:
int b = 5, c = 3;
const int& e = b + c;
再来研究函数的返回值:
int ReturnA()
{
int a = 100;
return a;
}
int main(int argc, char** argv)
{
int f = ReturnA();
return 0;
}
我们吧ReturnA的值返回给一个整型 f 当然是可以的,但是返回给一个整型引用就会出问题,正确的做法依旧是通过const来解决:
int ReturnA()
{
int a = 100;
return a;
}
int main(int argc, char** argv)
{
const int& f = ReturnA();
return 0;
}
可以理解为,ReturnA在返回时产生了一个中间变量,这个中间变量时在CPU里面的,所以这时候的引用是引用了在CPU中的一个临时变量。
还有一种情况,当引用类型与被引用类型不同的时候,也可以用const来解决:
double p = 3.14;
const int& rp = p;
cout << rp << endl;
此时输出为 3
造成这个的原理是什么呢?其实原理还是中间变量。可以来看一下:
double a = 3.14;
const int& ra = a;
cout << "a = " << a << endl;
cout << "ra = " << ra << endl;
a = 4.14;
cout << "a = " << a << endl;
cout << "ra = " << ra << endl;
输出如下:

发现,ra尽管是对a的引用,但是当a发生改变时,ra的值并没有改变。其实本质就是发生了如下的变化:
int & t = a;
const int & ra = t;
常引用申请了新内存以存放初始化的值,并以const修饰,这样就可以实现对引用对象的类型转换,不过这样也等于引用了新的对象,跟最初的引用对象就没关系了。
2.8 引用的本质
之前稍微提到过一点,引用的本质就是指针。但是我们要如何其去验证这一观点呢,原来那套直接 sizeof 的办法肯定行不通的了。可以如下去严重:
struct TypeC {
char c;
};
struct TypeP {
char* pc;
};
struct TypeR {
char& rc;
};
int main(int argc, char** argv)
{
cout << "sizeof(TypeC) = " << sizeof(TypeC) << endl;
cout << "sizeof(TypeP) = " << sizeof(TypeP) << endl;
cout << "sizeof(TypeR) = " << sizeof(TypeR) << endl;
return 0;
}
输出如下:

这里可以大致推敲出来,引用实际上就是一个指针。但是,引用他必须初始化,什么样的数据类型需要初始化呢?常量就必须初始化。所以,引用就是一个常指针,且一经声明则不可以更改。它的结构形式就应该如下:
int * const p
我们在使用引用的时候,会发现引用和指针使用起来不一样。但是我可以很负责的讲,引用脱去面上的包装,在底层实现上和指针的实现是一模一样的。可以写两个Swape,一个用指针实现,一个用引用实现,在编译器里调试,汇编层面会暴露的一览无余。
2.9 new/delete 堆内存操作
C语言中提供了 malloc 和 free 两个系统函数,完成堆内存的申请和释放。而C++则提供了两个关键字 new 和 delete。此两个关键字是为类对象而设计的。
2.9.1 new/new[]
2.9.1.1 单变量
int* pt = (int*)malloc(sizeof(int));
int* p = new int;
以上是C与C++申请堆内存的操作。在C++中可以如下对申请的内存进行初始化:
int* p = new int(10);
cout << *p << endl;
此时输出就为10,但是一般不这样初始化,还是老老实实用平常的办法:
int* pt = (int*)malloc(sizeof(int));
int* p = new int;
*p = 10;
那我们要 new 一个指针的话,就得用二级指针咯:
int** pp = new int*;
*pp = p;
结构体一样可以new:
Stu* ps = new Stu;
以上就是单变量,接下来看看申请一堆空间。
2.9.1.2 申请一或多维数组
new 关键字,后面跟上类型和维度,比如申请一个 10个int类型大小的数组,即 new int[10], 后面也可以跟初始化数据。
float* p = new float[10]{
1.2,1.4,1.6 };
不过我们通常也不会在这里直接初始化。
接下来是指针数组的申请:
char** pp = new char* [11];
for (int i = 0; i < 10; i++)
{
pp[i] = (char*)"China";
}
pp[10] = nullptr;
while (*pp!=nullptr)
{
cout << *pp++<< endl;
}
多维数组的申请:
//二维空间-数组指针
int(*ptr)[5] = new int[3][5];
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 5; j++)
{
ptr[i][j] = i + j;
}
}
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 5; j++)
{
cout << ptr[i][j]<<" " ;
}
putchar('\n');
}
2.9.1.3 指针数组的申请
char** pp = new char* [11];
for (int i = 0; i < 10; i++)
{
pp[i] = (char*)"China";
}
pp[10] = nullptr;
while (*pp != nullptr)
{
cout << *pp++ << endl;
}
2.9.2 delete
delete 总共只分为两种情况。单变量或者多变量。
单变量的 delete 的方法如下:
int* p_int = new int;
delete p_int;
多变量的 delete 的方法如下:
int** p_arry = new int*[3];
delete []p_arry;
int(*p_arryPointer)[5] = new int[3][5];
delete[] p_arryPointer;
内存终究是线性的,所以不论你是几维数组,都一次性给你搞定。
2.9.3 返值判断
对于 malloc 申请出的空间,类型是 void*型,如果申请失败,则返回 NULL,可以通过返值对申请成功与否作过判断。 new 关键字申请的空间是不是也可以采用这样的方式来作申请成功与否的判断呢?答 案是否定的。 new 申请空间失败不是返回NULL,而是抛出异常(这个我们后面会讲到,在这里先提一 下),应当采用try catch结构对其处理。当然也我们可以采用不抛出异常的方式,此时用法 同malloc。
2.9.3.1 失败退出
为了测试申请失败的情况,我们申请了一个大内存,你可以在你的电脑上,申请可能 更大的内存,这个视你的电脑内存容量而定。
int main()
{
double* pd[50];
for (int i = 0; i < 50; i++)
{
pd[i] = new double[50000000];
cout << i << endl;
}
}
此时系统会抛出一个异常,而不是空指针。
2.9.3.2 异常机制trycatch
上述案例,直到内存申请失败为止,那么就到了,下面我们采用try catch的方案来解 决申请失败的情况。 将可能会申请失败的代码段放置到try块中,然后在紧随其后的 catch块中捕获失败。 (对于此案例,当下,采用了解的方式来操作,即可)。
int main()
{
double* pd[50];
try
{
for (int i = 0; i < 50; i++)
{
pd[i] = new double[50000000];
cout << i << endl;
}
} catch (std::bad_alloc & e)
{
cout << e.what() << endl;
}
}
这样写其实很别扭,trycatch 占了一大截,看着很不舒服。如果觉得看着不符合自己审美,那么可以使用 set_new_handler
2.9.3.3 设置回调 set_new_handler
除了采用上述方式以后,还可以设置,申请失败回调的方法。设置回调的函数为 set_new_handler。
//此处设置推出函数
void NewError()
{
cout << "new error" << endl;
exit(-1);
}
int main(int argc, char** argv)
{
double* pd[50];
set_new_handler(NewError);//设置回调
for (int i = 0; i < 50; i++)
{
pd[i] = new double[50000000];
cout << i << endl;
}
system("pause");
return 0;
}
2.9.4 使用规则
- new/delete 是关键字,效率高于 malloc 和 free。
- 配对使用,避免内存泄漏和多重释放。
- 避免交叉使用。比如 malloc 申请的空间去 delete,new 出的空间被 free。
2.10 内联函数(inline function)
C 语言中有宏函数的概念。宏函数的特点是内嵌到调用代码中去,避免了函数调用的 开销。但是由于宏函数的处理发生在预处理阶段,缺失了语法检测和有可能带来的语意差错。
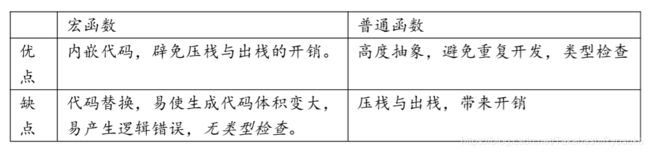
内联函数就有函数的优点,又避免了宏函数的缺陷。
内联函数:
- 有类型检查
- 内嵌
具体怎么办呢,非常简单,就在自定义函数前加上 inline 关键字就好了。
inline int MySqr(int x){
return x*x;
}
并不是说有函数都去inline,只有短小且频繁的函数才有可能被编译器真正的 inline。

2.11 Cast类型强转
2.11.1 C -> C++Style
使用 C风格的强制转换可以把想要的任何东西转换成合乎心意的类型。那为什么还需 要一个新的C++类型的强制转换呢? 新类型的强制转换可以提供更好的控制强制转换过程,允许控制各种不同种类的强制 转换。C++提供了四种转化 static_cast,reinterpret_cast,dynamic_cast 和 const_cast 以满足不同需求,C++风格的强制转换好处是,它们能更清晰的表明它们要 干什么。
但是,C语言转换风格在C++中依然适用。

2.11.2 static_cast
2.11.2.1 语法

double d;
d = static_cast<double>(10) / 3;
int i;
i = static_cast<int>(d);
此时 d 则会输出3.33333。i 则是3.这种情况称之为 双隐。
下面来看看单隐的情况。
int* p; void* q;
q = p;
p = q;
这时候 p = q 编译就会不通过:
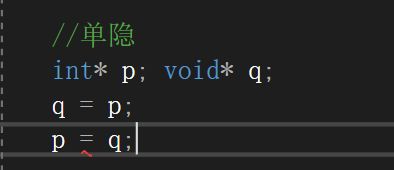
这时候这样就可以了:
p = static_cast<int*>(q);
两边都不能隐式转换,就是双不隐:
//双不隐
int m; int* n;
m = n;
n = m;
此时编译器一个也通不过:
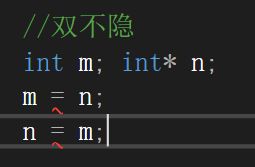
这个时候就没法使用static_cast了。这时候就需要引入reinterpret_cast了。
2.11.3 reinterpret_cast
2.11.3.1 语法

什么意思呢,也就是忽略类型,都相互理解为一个二进制去从更加底层的方面去重新解释。
//双不隐
int m; int* n;
m = reinterpret_cast<int>(n);
n = reinterpret_cast<int*>(m);
有一道C语言的面试题,如下:
int arr[5] = {
1,2,3,4,5 };
cout << hex << *((int*)((int)arr + 1)) << endl;
cout << *(reinterpret_cast<int*>((reinterpret_cast<int>(arr) + 1))) << endl;
换成C++风格就是下面那种写法。
2.11.3 const_cast(去const化)
2.11.3.1 语法

这里的 const 并不是转成 const,而是对指针和引用进行去const化。
//引用
int a = 5;
const int& ra = a;
const_cast<int&>(ra) = 100;
//指针
const int* pa = &a;
*const_cast<int*>(pa) = 1000;
那么,这些到底有什么用呢?我们常说,在写函数时,传参是能加 const 的就加 const。但是有时候我们传递的东西它就不是 const,这个时候就有用了。
void Fooo(const int &ra)
{
const_cast<int&>(ra) = 10000;
}
int main(int argc, char** argv)
{
int a = 5;
Fooo(a);
cout << a << endl;
system("pause");
return 0;
}
注意!:
- const_cast is only safe if you are adding const to an originally non-const variable. Trying to remove the const status from an originally-const object, and then perform the write operation on itwillresult inundefinedbehavior.
- 原生数据是非 const 的,可以去除其引用的 const 的属性,若原生数据是 const 的, 去除其引用的 const属性,执行任何写入操作都是未定义的。
2.12 String字符串类
2.12.1 定义
string 是 C++中处理字符串的类,是对 C 语言中字符串的数据和行为的包装。使对字符串的处理,更简单易用。
在C++中,我们可以将string初步理解为一种新类型。地位与 int 是一模一样的。那我们研究它就需要搬出研究其他基本类型的那一套方法了。
2.12.1.1 大小
string s;
cout << "sizeof(s) = " << sizeof(s) << endl;
输出如下:

这一结果并不是唯一的。因为它与不同的平台,32或64位机都有关。这里最准确的做法,应是把这个数值理解成 4。
2.12.1.2 初始化 / 输入与输出
有以下几种初始化方式:
string s_0("China");
string s_1 = "China";
输入与输出:
string s;
cin >> s;
cout << s << endl;
这么写的话,如果在输入过程中输入空格,那么空格之后的所有字符串将会丢失。这时候只需要使用 getline 就行了:
string s;
cout << "输入您的姓名:";
getline(cin, s);
cout << s << endl;
此时输出如下:

2.12.1.3 长度 - size()
string s = "Great Wall";
cout << s.size() << endl;
size() 可以求得字符串的长度。此处输出为10。
2.12.1.4 拼接
C++ 中,拼接相对简单,直接使用 加等 运算符即可:
string s = "Great Wall";
//拼接
string s_1 = " in China";
s += s_1;
2.12.1.5 比较
与拼接相似,直接使用 比较运算符就可以了。
string s_2 = "China";
string s_3 = "china";
if (s_2 == s_3)
cout << "相等" << endl;
else
cout << "不相等" << endl;
cout << ((s_1) == (s_2) ? 1 : 0) << endl;
以上两种方式皆可。
2.12.1.6 拷贝
拷贝更加简单:
string s_4 = "Damon";
string s_5;
s_5 = s_4;
2.12.1.7 to_string
string也有很多成员函数。但是现在在没有封装的概念,所以暂且不讨论。只讲几个有意思的。
to_string可以将整型数据转为字符类型。
int a = 12345678;
string sa = to_string(a);
2.12.1.7 stoi
字符串必须已数字开头,否则会抛出异常。
try{
string s = "aaaaa19961218";
int birth = stoi(s);
cout << birth << endl;
}
catch(std::invalid_argument&){
cout << "invalid argument" << __FILE__ << __func__ << __LINE__ << endl;
}
2.13 总结
- (一)在C++中几乎不需要用宏,用 const 或 enum 定义显式的常量,用inline避免函数调用的额外开销,用模板去刻画一族函数或类型,用namespace 去避免命名冲突。
- (二)不要在你需要变量之前去声明,以保证你能立即对它进行初始化。
- (三)不要用malloc,new运算会做的更好。
- (四)避免使用void*、指针算术、联合和强制,大多数情况下,强制都是设计错误的指示器。
- (五)尽量少用数组和C风格的字符串,标准库中的 string 和vector可以简化程序。
- (六)更加重要的是,试着将程序考虑为一组由类和对象表示的相互作用的概念,而不是一堆数据结构和一些可以拨弄的二进制。
2.14 namespace 命名空间
2.14.1 why namespace?
命名空间为了大型项目开发,而引入的一种避免命名冲突的一种机制。比如,在一个 大型项目中,要用到多家软件开发商提供的类库。在事先没有约定的情况下,两套类库可能存在同名的函数或是全局变量而产生冲突。项目越大,用到的类库越多,开发人员越多, 这种冲突就会越明显。 鉴于这类大型项目的开发需要,C++引入的了命名空间的概念。其实这种命名空间的概念在 C语言中也有,只是没有被概念化。
2.14.2 C语言的命名空间
C 语言将工程的命名空间划分为,全局无名命名空间和函数命名空间。全局命名空间中,不可以有重名的全局变量和函数(除非被static修饰),函数命名空间,不可以用重名的局部变量。
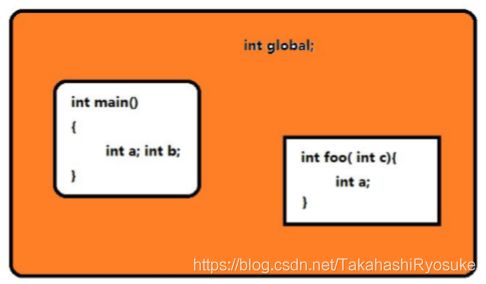
2.14.3 C++的命名空间
2.14.3.1 全局无名命名空间( :: )
C++在 C 语言的基础之上,C++首次以语法的行式,确立了全局无名命空间的的存在和使用方法。看以下例子:
int mm = 200;
int main(int argc, char** argv)
{
int mm = 100;
cout << mm << endl;
system("pause");
return 0;
}
在C语言中我们想先访问全局mm, 除非在局部mm之前先输出,不然基本不可能取地全局mm。但是在C++中,我们就可以:
int mm = 200;
int main(int argc, char** argv)
{
int mm = 100;
cout << mm << endl;
cout << ::mm << endl;
system("pause");
return 0;
}
C++中的命名空间就,就是将无名全局命名空间再次划分的结果。
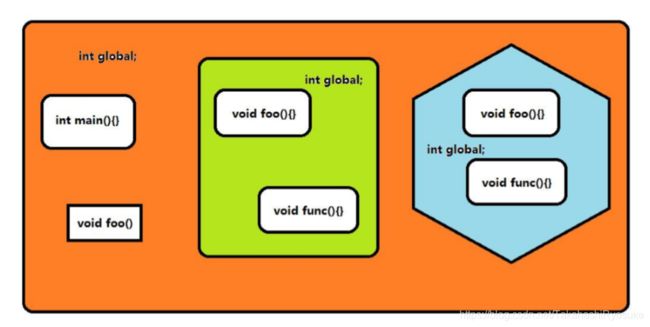
声明如下:

2.14.3.2 命名空间的使用
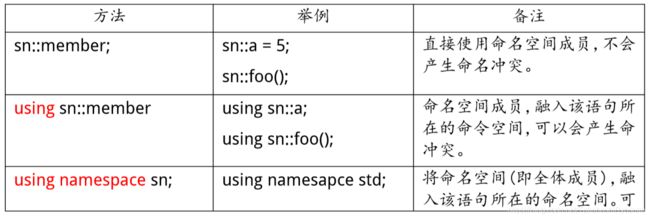

- 第一种情况:
namespace ONE {
int a = 5;
}
namespace ANOTHER {
int a = 10;
}
int main(int argc, char** argv)
{
int a = 100;
cout << ONE::a << endl;
cout << ANOTHER::a << endl;
cout << a << endl;
return 0;
}
这样相当于带着壳使用,不会发生命名冲突。
- 第二种:
int a = 1000;
using ONE::a;
cout << a << endl;
命名空间相当于是一个打包的过程,而using则像是解包的过程。他将打包好的内容释放到解包处的作用域,此时便会产生命名冲突。
- 第三种:
第三种相当于直接打开所有命名空间,以便使用里面的所有内容,命名冲突的几率就更大了。
2.14.3.3 命名空间的嵌套
上面的命名空间声明图已经列出来了,命名空间里还能嵌套其他的命名空间:
namespace ONE {
int a = 5;
namespace ANOTHER {
int a = 10;
}
}
//命名空间的嵌套
int main(int argc, char** argv)
{
cout << ONE::ANOTHER::a << endl;
system("pause");
return 0;
}
2.14.3.4 命名空间的协同开发
当项目组中有多个人共同开发的时候,每个人可能负责几个模块或是几个文件,但是 要求是相同的命名空间,该如何实现呢? 同名命名空间自动合并,是协同开发的基础,示例如下:
namespace namea {
int a = 1996;
}
namespace namea {
int b = 1218;
}
int main(int argc, char** argv)
{
using namespace namea;
cout << a << b << endl;
system("pause");
return 0;
}
第三章 封装 (Encapsulation)
3.1 C struct数据封装
当单一变量无法完成描述类型需求的时候,结构体类型解决了这一问题,关键字 struct 可以将多个类型打包成一体,形成新的类型,这是 C 语言中封装的概念。 但是,新类型并不包含对数据的操作。所有的操作都是通过函数传参的方式,去进行封装。 例子如下:
struct Data {
int year;
int month;
int day;
};
void InitData(Data& rb)
{
cout << "年份: ";
cin >> rb.year;
cout << "月份: ";
cin >> rb.month;
cout << "日期: ";
cin >> rb.day;
}
void DisData(Data& rb)
{
cout << "您出生在 " << rb.year << " 年 "
<< rb.month << " 月 " << rb.day << " 日。" << endl;
}
bool IfLeapYear(Data& rb)
{
if ((!(rb.year % 4) && (rb.year % 100!=0)) || (!(rb.year % 400)))
return true;
return false;
}
int main(int argc, char** argv)
{
Data birth;
InitData(birth);
DisData(birth);
if (IfLeapYear(birth))
cout<<"Leap Year"<<endl;
else
cout<<"Not Leap Year"<<endl;
system("pause");
return 0;
}
我们关于Data的所有行为,都是通过传参到函数里去进行操作的。无论是初始化,输出日期,判断是否闰年,无一例外。
但是在C++中,我们可以将方法整合到结构体当中去,此时定义的结构体内不需要再传参,关于传参的所有相关操作都去除,如下:
struct Data {
void InitData()
{
cout << "年份: ";
cin >> year;
cout << "月份: ";
cin >> month;
cout << "日期: ";
cin >> day;
}
void DisData()
{
cout << "您出生在 " << year << " 年 "
<< month << " 月 " << day
<< " 日。" << endl;
}
bool IfLeapYear()
{
if ((!(year % 4) && (year % 100 != 0))
|| (!(year % 400)))
return true;
return false;
}
int year;
int month;
int day;
};
int main(int argc, char** argv)
{
Data birth;
birth.InitData();
birth.DisData();
if (birth.IfLeapYear())
cout<<"Leap Year"<<endl;
else
cout<<"Not Leap Year"<<endl;
system("pause");
return 0;
}
另外一个例子,就是之前用 C 语言写过的栈:
struct Stack {
//初始化栈
void InitStack()
{
top = 0;
memset(space, 0, 1024);
}
//是否到达栈顶
bool IfFull()
{
return top == 1024;
}
//是否到达栈底
bool IfEmpty()
{
return top == 0;
}
//压栈
void Push(char ch)
{
space[top++] = ch;
}
//出栈
char Pop()
{
space[--top];
return space[top];
}
int top;
char space[1024];
};
int main(int argc, char** argv)
{
Stack s;
s.InitStack();
for (char i = 'a';!(s.IfFull())&&(i <= 'z'); i++)
{
s.Push(i);
}
while (!s.IfEmpty())
{
cout << s.Pop() << endl;
}
system("pause");
return 0;
}
封装包含两部分:
- 数据
- 行为(接口)
这样的好处就在于权限控制:对外提供接口,隐藏数据。对内开放数据(如银行的提款机)。如果我们在数据部加上 private:
private:
int top;
char space[1024];
这样我们在外部就无法访问 top 和 space 了:
Stack s;
s.InitStack();
for (char i = 'a';!(s.IfFull())&&(i <= 'z'); i++)
{
s.Push(i);
}
s.top = 0;//在这一步将会报错
while (!s.IfEmpty())
{
cout << s.Pop() << endl;
}
3.2 从 struct 到 class
上节说到,封装,可以达到对外界提供接口,隐藏数据,对内开放数据的作用。
在 C++ 中,我们不再使用struct,而使用 class。可以这么理解,除了权限不一样以外,class 和 struct 是一样的。
- struct 默认全部都是 public。
- class 默认全部都是 private
还是拿上面的 Stack 举例:
class Stack {
public: //此处加上public
//初始化栈
void InitStack()
{
top = 0;
memset(space, 0, 1024);
}
//是否到达栈顶
bool IfFull()
{
return top == 1024;
}
//是否到达栈底
bool IfEmpty()
{
return top == 0;
}
//压栈
void Push(char ch)
{
space[top++] = ch;
}
//出栈
char Pop()
{
space[--top];
return space[top];
}
//数据
int top;
char space[1024];
};
在开头加上 public,就会把权限一路开放到底,所以需要在加上权限的地方加上权限:
class Stack {
public:
//初始化栈
void InitStack()
{
top = 0;
memset(space, 0, 1024);
}
//是否到达栈顶
bool IfFull()
{
return top == 1024;
}
//是否到达栈底
bool IfEmpty()
{
return top == 0;
}
//压栈
void Push(char ch)
{
space[top++] = ch;
}
//出栈
char Pop()
{
space[--top];
return space[top];
}
private:
int top;
char space[1024];
};
struct 中所有行为和属性都是public的(默认),此举也是为了C++兼容C语言,因为C 语言中没有权限的概念。 C++中的class可以指定行为和属性的访问方式,默认为private,此举要求你必须指定权限,不然就没有办法外部访问。

我们在提供给别人服务的时候,提供头文件和库就够了。所以我们最好不要在类里提供方法,只在类里进行声明,将实现放在类外,但是需要使用类域运算符:: ,如下:
class Stack {
public:
void InitStack();
bool IfFull();
bool IfEmpty();
void Push(char ch);
char Pop();
private:
int top;
char space[1024];
};
void Stack::InitStack()
{
top = 0;
memset(space, 0, 1024);
}
//是否到达栈顶
bool Stack::IfFull()
{
return top == 1024;
}
//是否到达栈底
bool Stack::IfEmpty()
{
return top == 0;
}
//压栈
void Stack::Push(char ch)
{
space[top++] = ch;
}
//出栈
char Stack::Pop()
{
space[--top];
return space[top];
}
加上类域运算符以后,即使在全局里有重名的函数,也能编译通过,因为他们隶属于不同的作用域。类名本质也是一个命名空间。
第四章 类(Class)
4.1 init 到 自动化
前面我们封装 Date/Stack,虽然表达的意义各不相同,但是均会涉及到从类型到 对象的初始化,即 init()初始化函数。 init()函数给予了对象的一个初始状态。这样一个初始状态对于后序的操作意义是重大的。
因此,初始化成为了类到对象必要的一个行为。
4.2 自动初始化
将上例中,init函数,注释掉。换为了与类名相同的函数,该函数无返回,称为构造函数,会在对象生成的时候自动调用。
class Stack {
public:
Stack()
{
top = 0;
memset(space, 0, 1024);
cout << "初始化完成。。。" << endl;
}
private:
int top;
char space[1024];
};
//自动初始化,构造器
int main(int argc, char** argv)
{
Stack s;
system("pause");
return 0;
}
4.2.1 构造器(Constructor):
- 与类名相同,在对象生成时自动调用。
- 无返回值,可以有参数。
- 当没有构造器时,系统会提供一个默认的系统无参空体构造器,一经自实现,系统提供的默认将不复存在
- 依然可以传参,那么就意味着可以有默认参数,可以被重载。
- 无论重载,还是默认参数,应该把无参空题构造器包含。
4.2.2 重载
MyStack::MyStack()
{
top = 0;
space = new char[1024];
memset(space, 0, 1024);
spaceSize = 1024;
cout << "初始化完成。。。" << endl;
}
MyStack::MyStack(int size)
{
top = 0;
space = new char[size];
memset(space, 0, size);
spaceSize = size;
cout << "初始化完成。。。" << endl;
}
4.2.3 默认参数
MyStack::MyStack(int size = 1024)
{
top = 0;
space = new char[size];
memset(space, 0, size);
spaceSize = size;
cout << "初始化完成。。。" << endl;
}
在这种情况下,显然默认参数更好。它包含了上面无参和有参的两个情况。
4.2.4 初始化参数列表(initialize list)
4.2.4.1 初始化列表
C++提供了一种,不在构造体内初始化的方法,称为:初始化参数列表。一方面,提升了效率,另外一方面是功能的扩展。 初始化参数列表,位于构造器声明与实现之间,“ :”开始,各初始化成员用“ ,” 分开,其后的初始化成员置于“()”以内。
实现如下:
MyStack::MyStack(int size = 1024): spaceSize(size),top(0), space(new char[spaceSize])
{
memset(space, 0, size);
cout << "初始化完成。。。" << endl;
}
这种写法不仅可以装酷,效率还非常的高。为什么效率高?留着以后再说。
4.2.4.2 列表的初始化顺序
初始化列表里的初始化顺序,与列表中的顺序无关,与下面的变量声明有关。
class MyStack {
public:
MyStack();
MyStack(int size);
void InitStack();
bool IfFull();
bool IfEmpty();
void Push(char ch);
char Pop();
private:
int top;
char* space;
int spaceSize;
};
与 private 里的声明先后顺序有关。所以在日常中,我们最好不要拿被初始化成员去初始化其他成员。如spaceSize 和 space。
4.3 析构器(Destructor)
4.3.1 析构器
以"~"开头与类名相同,无参无返回的函数,在类对象销毁时(栈/堆对象),自动调用,完成对象的销毁。尤其是类中己申请的堆内存的释放。
4.3.2 语法

4.3.3 特性
- 与类名相同, 无参, 无返回, 前面将上一个 ~ 符号
- 在对象被销毁前,自动调用,被调用用于处理清理工作 (堆对象)
- 两种对象:栈上对象,堆上对象
- 不自实现的时候,系统会提供一个空体默认析构器。
MyStack::~MyStack()
{
delete[] space;
cout << "deleted" << endl;
}
在没有堆空间的对象当中,使用默认析构器就足够了。在有堆空间的情形下,就必须使用析构器。
4.4 层次内存管理
4.5.1 引例
看以下 C 语言示例:
struct Stu {
char* name;
int age;
};
上例中,虽然我们给 Student 申请了大小,但是其结构内部的 name仍然指向一段未初始 化的内存,是一种野指针的存在,此时冒然向其内拷贝数据,会引发段错误。 要想不发生段错误,就要为 name 指针申请空间,并且表在释放的时候,注意先申请 的后释放,后申请的先释放。
4.5.2 层次管理
C++ 的析构器和构造器很好的解决了这一问题:
class Stu
{
public:
Stu()
{
cout << "初始化中..." << endl;
name = new char[1024];
age = 18;
}
~Stu()
{
delete[] name;
cout << "释放完成..." << endl;
}
private:
char* name;
int age;
};
int main(int argc, char** arhv)
{
Stu s;
Stu* ps = new Stu;
delete ps;
//system("pause");
return 0;
}
我们在main里只关心我们 new 出来的对象,至于类里面的 new ,我们在析构器里自行释放。比如我们在Stu里再内嵌一个类:
class BirthDay {
public:
BirthDay()
{
cout << "初始化BirthDay..." << endl;
year = new int(1996);
month = new int(12);
day = new int(18);
}
~BirthDay()
{
delete year;
delete month;
delete day;
cout << "释放BirthDay完成..." << endl;
}
private:
int *year;
int *month;
int *day;
};
class Stu
{
public:
Stu()
{
cout << "初始化中..." << endl;
name = new char[1024];
age = 18;
}
~Stu()
{
delete[] name;
cout << "释放完成..." << endl;
}
private:
char* name;
int age;
BirthDay birth;
};
int main(int argc, char** arhv)
{
Stu* ps = new Stu;
delete ps;
//system("pause");
return 0;
}
我们不需要在BirthDay以外关心它的释放问题。我们只需要对本层的内存负责。C++ 较 C语言,解决了从外而内的申请,从内而外的释放。而是只对本层级负责,内部的层级由内部本层级来负责。
4.6 拷贝构造器 (Copy Constructor)
4.6.1 发生时机
由己存在的对象,创建新对象。也就是说新对象,不由构造器来构造,而是由拷贝构造器来完成。拷贝构造器的格式是固定的:
- 由普通数值做参数完成构造 - Constructor
- 由同类对象作参数完成构造- Copy Constructor
4.6.2 语法定义
系统提供了默认的拷贝构造器,且不是空构造器,提供了一种等位拷贝机制。格式固定,一经实现,默认拷贝构造器将不复存在。
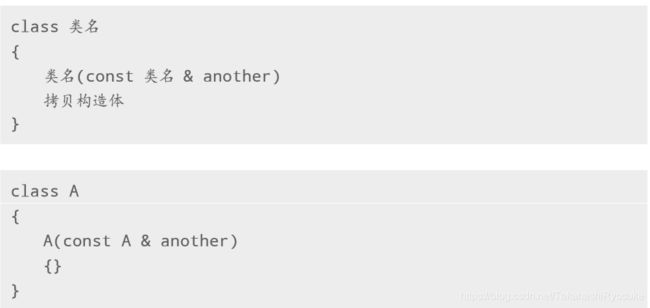
系统提供的默认拷贝构造器是一种浅拷贝 ( Shallow Copy)。对应的,我们就会有深拷贝 ( Deep Copy)。
4.6.3 浅(shallow)/深(deep)拷贝
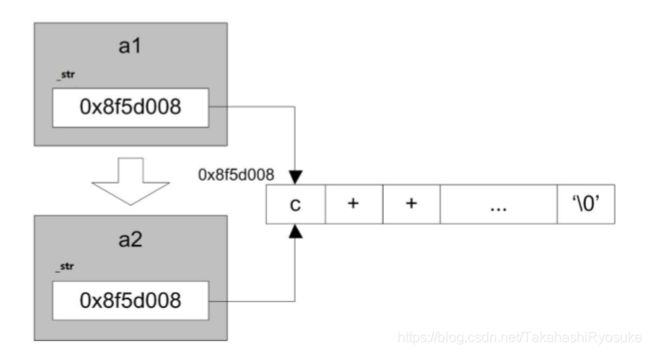
系统提供默认的拷贝构造器,一经定义不再提供。但系统提供的默认拷贝构造器是等 位拷贝,也就是通常意义上的浅(shallow)拷贝。 如果类中包含的数据元素全部在栈上,浅拷贝也可以满足需求的,此时i就没必要去自实现。但如果含有堆上的数据, 则会发生多次析构行为,此时就需要自实现。
- 浅拷贝相当于将地址拷贝过去。此时就会发生Double Free。
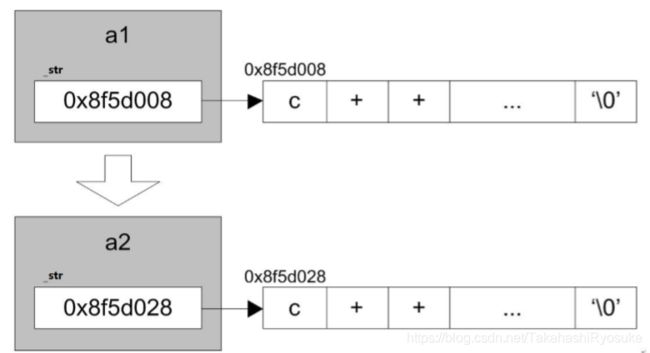
- 深拷贝相当于我不需要你的地址,不需要和你指向同一空间。但我需要一份和你的内容一模一样的空间。相当于深拷贝才是真正意义上的拷贝。
4.7 this指针
4.7.1 指向调用对象的指针
系统在创建对象时,默认生成的指向当前对象的指针。这样作的目的,就是为了带来使用上的方便。
4.7.2 特性
- 指向当前对象,可用于所有的成员函数,但不能应用于初始化列表。
- this 是以隐含参数的形式传入,而非成员的一部分,所以不会影响 sizeof(obj) 的大小。
- this 指针本身是不能更改指向的,即,是 const 类型修饰的。
4.7.3 作用
- 避免了形参与数据成员的重名
- 形成了链式表达。
4.8 赋值运算符重载(operator =)
4.8.1 发生时机
用一个已有对象,给另一个已有对象赋值。两个对象均已创建结束后,发生的赋值行为,就会涉及到赋值运算符重载的问题。注意,与拷贝构造器不同的是,拷贝构造器是用一个已有对象去创建一个新的对象。
4.8.2 语法

4.8.3 特性
- 系统提供默认的赋值运算符,一经自实现,不复存在
- 系统提供的也是等位拷贝,也就是浅拷贝,会在成内存泄漏,重析构
- 如果对象中不存在由*构成的堆空间,此时默认默认也是可以满足需求的。
- 要实现“深深”的赋值,必须自定义
- 返回引用,通常不能用 const 修饰
- 要实现自定义,必须解决三个问题:重析构,内存泄漏,自赋值。
4.8.4 问题的解决
myString& operator=(const myString& another)
{
cout << "operator= ..." << endl;
//解决自赋值问题,判断,若为自赋值,则直接返回。
if (this == &another)
return *this;
//解决内存泄漏问题,先释放自己
delete[] this->_str;
//深拷贝
int len = strlen(another._str);
_str = new char[len + 1];
strcpy_s(_str, len + 1, another._str);
return *this;//解决链式表达
}
4.9 自实现string类
class myString
{
public:
myString(const char* s = nullptr)//默认值作标志位;
{
cout << this << "初始化构造中..." << endl;
if (s)
{
int len = strlen(s);
_str = new char[len + 1];
strcpy_s(_str, len + 1, s);
} else
{
_str = new char[1];//为了析构器的统一性;
*_str = '\0';
}
}
myString(const myString& another)
{
cout << "拷贝构造中..." << endl;
int len = strlen(another._str);
_str = new char[len + 1];
strcpy_s(_str, len + 1, another._str);
}
myString& operator=(const myString& another)
{
cout << "operator= ..." << endl;
//解决自赋值问题,判断,若为自赋值,则直接返回。
if (this == &another)
return *this;
//解决内存泄漏问题,先释放自己
delete[] this->_str;
//深拷贝
int len = strlen(another._str);
_str = new char[len + 1];
strcpy_s(_str, len + 1, another._str);
return *this;//解决链式表达
}
bool operator==(const myString& another)
{
return strcmp(this->_str, another._str) == 0;
}
bool operator>(const myString& another)
{
return strcmp(this->_str, another._str) > 0;
}
bool operator<(const myString& another)
{
return strcmp(this->_str, another._str) < 0;
}
myString operator+(const myString& another)
{
int len = strlen(this->_str) + strlen(another._str) + 1;
myString ms; // 这里会触发一个构造器,默认值是nullptr
delete[] ms._str; // 先delete 这个构造器
ms._str = new char[len];
memset(ms._str, 0, len);
strcat_s(ms._str, len, this->_str);
strcat_s(ms._str, len, another._str);
return ms;
}
myString & operator+=(const myString& another)
{
//int len = strlen(this->_str) + strlen(another._str) + 1;
//myString ms; // 这里会触发一个构造器,默认值是nullptr
//delete[] ms._str; // 先delete 这个构造器
//ms._str = new char[len];
//memset(ms._str, 0, len);
//strcat_s(ms._str, len, this->_str);
//strcat_s(ms._str, len, another._str);
//delete[] this->_str;// 释放原_str,去报避免内存泄漏
//this->_str = new char[len];
//strcpy_s(this->_str, len, ms._str);
int len = strlen(this->_str) + strlen(another._str) + 1;
this->_str = static_cast<char*>(realloc(this->_str, len));//避免realloc返回新地址
memset(this->_str + strlen(this->_str), 0, strlen(another._str));
strcat_s(this->_str, len, another._str);
return *this;
}
char operator[](int n){
if (n > strlen(this->_str))
cout << "OUT_OF_INDEX" << endl;
else
return this->_str[n];
}
char at(int n)
{
if (n > strlen(this->_str))
cout << "OUT_OF_INDEX" << endl;
else
return this->_str[n];
}
char* c_str()
{
return this->_str;
}
void DisStr()
{
cout << _str << endl;
}
~myString()
{
cout << this << " Deleting..." << endl;
delete[] _str;
}
private:
char* _str;
};
4.10 栈对象返回问题
栈上的对象是可以返回的,不可以返回栈对象的引用。
4.10.1 C++返回栈对象
假设我们有如下这么一个类:
class A
{
public:
A()
{
cout << this << "constructor" << endl;
}
A(const A& another)
{
cout << this << "copy consturctor" << endl;
}
A& operator=(const A& another)
{
cout << this << "operator =" << endl;
}
~A()
{
cout << this << "desructor" << endl;
}
};
4.10.1.1 传值
我们试试在Func中传值会发生什么:
void Func(A a)
{
}
int main(int argc, char** argv)
{
A a;
Func(a);
//system("pause");
return 0;

会触发一次构造一次拷贝构造和两次析构器。
4.10.1.2 传引用
void Func(A &a)
{
}
int main(int argc, char** argv)
{
A a;
Func(a);
//system("pause");
return 0;
}

会发现,这里只出发了一次构造器,与析构器,效率大大提高。原理就是传引用的本质就是扩大了Func的作用域。
4.10.1.3 RVO/NRCO
(具名)返回值优化((Name)ReturnValue Optimization,简称(N)RVO),是这么一种优化 机制:当函数需要返回一个对象的时候,如果自己创建一个临时对象用户返回,那么这个 临时对象会消耗一个构造函数(Constructor)的调用、一个复制构造函数的调用(Copy Constructor)以及一个析构函数(Destructor)的调用的代价。 通过优化的方式,可以减少这些开销。
如下:
A Func()
{
return A();
}
int main(int argc, char** argv)
{
Func();
system("pause");
return 0;
}
此时A() 就是一个不具名对象,A()就相当于是在main中直接生成与销毁的。
4.10.1.4 栈对象接受
接收栈对象的方式不同,会影响优化的,可自行测之。
4.10.1.5 返回栈引用
A & Func()
{
A a;
return a;
//A a;
//cout <<"Func"<< &a << endl;
//return a;
}
int main(int argc, char** argv)
{
A r = Func();
system("pause");
return 0;
}
输出如下:
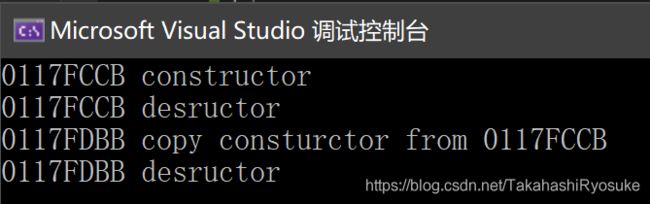
这里可以看到,当返回引用时,Func 里直接先构造随机立马就解析了。所以后面再main里的拷贝构造实际在拷贝已经解析过后的地址里的东西,所以此时返回的引用实际是无效的。
注意:上面的运行结果只是基于VS平台的运行结果。由于C++只提供了语法规则,背后的优化各个平台公司都不一样,所以其他平台的运行结果很有可能不一样,一定要注意。
4.11 对象数组
class Student {
public:
Student(string n =""):_name(n){
}//最好包含默认值
void Dis()
{
cout << _name << endl;
}
private:
string _name;
};
int main(int argc, char** argv)
{
Student students[100] = {
Student("Shaojie"),Student("WangLan")};
Student* s = new Student;
Student* ps = new Student[10];
return 0;
}
这样我们就有了一个对象数组,并且都有了一个默认值。但是,我们终究需要去使用数组,例如输入班级里所有的学生姓名。这时候我们就需要用到二段式初始化。
4.11.1 二段式初始化
在对象数组中,要求对象必须包含默认无参构造器的情况,但有时,默认无参构造器 并不能完全满足我们的需求,可能要再次初始化。 二段初始化,常将默认无参构造器置为空。然后再次调用初始化函数,比如 cocos中 对象生成就是这样的。 其中,对象数组,就是二段初始化的原因之一。
class Student {
public:
Student()
{
};
void init(string s)
{
_name = s;
}
void Dis()
{
cout << _name << endl;
}
private:
string _name;
};
int main(int argc, char** argv)
{
Student students[100] = {
};
if (students)
{
for (int i = 0; i < 100; i++)
{
if (students)
{
students[i].init("damon");
}
}
} else
{
delete[] students;
}
return 0;
}
4.12 实现钟表类 class Clock
#include 4.13 实现汽车类 class MyCar
#include 第五章 类的扩展(Class’ Extension)
C++引入的面向对象的概念之后,C语言中的一些比如 static/const 等原有语意,作一 些升级处理,此时既要保持兼容,还要保持不冲突。
5.1 类成员储存(class memeber storage)
5.1.1 类大小 sizeof(class)
一个对象所占的空间大小,只取决于对象中数据成员所占空间的大小,与成员函数无关。
class MyTime {
public:
MyTime(int hour = 0,int min = 0, int sec = 0):
_hour(hour),_min(min),_sec(sec)
{
};
void Dis()
{
cout << _hour << " " << _min << " " << _sec << endl;
}
private:
int _hour;
int _min;
int _sec;
};
int main(int argc, char** argv)
{
MyTime t1;
cout << sizeof(t1) << endl; // 12
system("pause");
return 0;
}
以上代码的输出结果为 12 。
5.1.2 类成员函数可能的储存方式
那么,类函数又储存在哪里呢?储存了几份呢?
按理说,应该为每一个类对象的类数据与类函数都分配一段储存空间,如下:
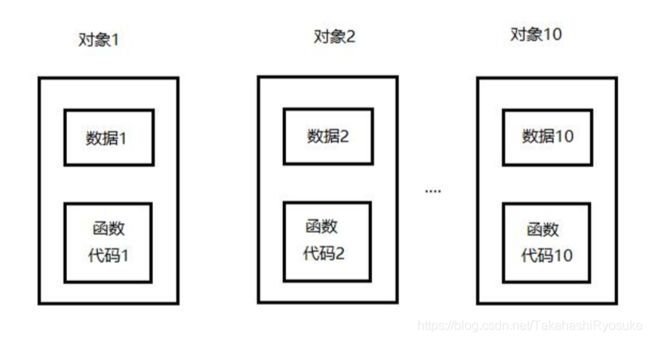
但是,实际的储存方式并不像上图所示那样。
5.1.3 类成员函数的实际储存方式
实际上,是有一段空间储存共同的函数代码段,在调用各个对象的函数时,都去调用这个公共函数代码段。如下:

这样做大大节省了节约了内存空间。问题接着又来饿了,当对象调用公共函数时,C++是如何确定访问的成员是调用的成员呢?
5.1.4 this 至关重要的存在
所有的对象都调用共用的函数代码段,如何保证访问的是调用对象的成员呢?为此, C++设置了 this 指针,对象在调用公用函数时,并将对象的指针作为隐含参数传入其内, 从而保证了访问的成员,属于调用者。
5.1.5 注意事项
- 不论成员函数在类内定义还是在类外定义,成员函数的代码段都用同一种方式存储。
- 应当说明,常说的 “某某对象的成员函数”,是从逻辑的角度而言的,而成员函 数 的存储方式,是从物理的角度而言的,二者是不矛盾的。类似于二维数组是逻辑概念,而物理存储是线性概念一样。
5.2 const in class
5.2.1 const data member
const 修饰数据成员,称为常数据成员,可以被普通成员函数和常成员函数来使用, 不可以更改。
常数据成员必须初始化,可以在类中(不推荐),或初始化参数列表中(这是在类对象生成之前唯一 一次改变const成员值的机会了)。
class A{
public:
A(int x = 0):_x(x){
}
void Dis()
{
cout << _x << endl;
}
private:
const int _x;
};
int main(int argc, char** argv)
{
A a(100);
a.Dis();
system("pause");
return 0;
}
5.2.2 const 修饰函数成员
5.2.2.1 const修饰函数的位置
const 修饰函数放在,声明之后,实现体之前,大概也没有别的地方可以放了。const 可以修饰全局函数吗?答案是不可以。
5.2.2.2 const成员函数的意义
const 构成的函数成员可以构成重载。const 修饰函数以后,承诺在本函数内不会发生改变数据成员的行为,也不能调用其他的非const的成员函数。
const构成的重载函数,非const对象优先调用非const版本。而const对象只能调用const版本。
5.2.2.3 小结
- const 修饰函数,在声明之后,实现体之前。
- const 函数只能调用 const 函数。非 const 函数可以调用 const 函数。
- 如果 const 构成函数重载,const 对象只能调用 const 函数,非 const 对象优先调 用非 const 函数。
- 类体外定义的 const 成员函数,在定义和声明处都需要 const 修饰符(有些关键字 是定义型的,有些是声明型的)。
5.2.2.4 const 修饰对象
const 修饰对象,其内可以有非const数据成员,但是保证在对象层面,不会修改数据成员。所以const 对象,只能调用 const 成员函数。不同编译器,可能会要求必须自实现构造器,因为若采用默认的话, const 对象中的成员,再无初始化的机会。
5.2.3 static 修饰类
C++扩展了 static 在类中的语意,用于实现在同一个类,多个对象间数据共享,协调行为的目的。 静态变量有全局变量的优势,又不会像全变量一样被滥用。而这一类变量,即可以通过类来管理,也可以通过类的静态函数来管理。 类的静态成员,属于类,也属于对象,但终归属于类。
5.2.3.1 static data member
5.2.4.1.1 语法规则

- 初始化:static 修饰数据成员,需要先初始化,并且不可以内类初始化,并且必需要在内外结合命名空间初始化。
当类的声明与实现分开的时候,初始化应发生在.cpp中 - 类大小:被static声明的数据成员,也不占用类对象的大小,储存在data的rw段
- 访问:命名空间(类名)是维持基础成员数据与static数据成员的基础,所以可以通过类名来访问,也可以通过对象来访问。
class S {
public:
static int _share;
S(int m = 12, int n = 18) :
_m(m), _n(n)
{
}
void Dis()
{
cout << _m << _n << _share << endl;
}
private:
int _m, _n;
};
int S::_share = 1996;
int main(int argc, char** argv)
{
S s1;
s1.Dis();
S s2;
s2.Dis();
cout << S::_share << endl;
system("pause");
return 0;
}
5.2.4.2 使用
5.2.4.1.1 统计函数调用次数
class S {
public:
static int _share_count_Dis;
S(int m = 12, int n = 18) :
_m(m), _n(n)
{
}
void Dis()
{
cout << _m << _n << endl;
_share_count_Dis++;//使用一次,统计数就自加一次
}
private:
int _m, _n;
};
//此处对类静态数据初始化
int S::_share_count_Dis = 0;
int main(int argc, char** argv)
{
S s1, s2, s3, s4;
s1.Dis();
s2.Dis();
s3.Dis();
s4.Dis();
cout << S::_share_count_Dis << endl;
system("pause");
return 0;
}
这么写,可行,但是就失去了类封装的意义,这时候就需要借助static修饰函数,来管理静态变量了:
class S {
public:
S(int m = 12, int n = 18) :
_m(m), _n(n)
{
}
void Dis()
{
cout << _m << _n << endl;
_share_count_Dis++;
}
//通过static修饰函数:
static int InvokeCountDis()
{
return _share_count_Dis;
}
private:
int _m, _n;
static int _share_count_Dis;
};
int S::_share_count_Dis = 0;
int main(int argc, char** argv)
{
S s1, s2, s3, s4;
s1.Dis();
s2.Dis();
s3.Dis();
s4.Dis();
cout << S::InvokeCountDis() << endl;
system("pause");
return 0;
}
5.2.4.1.2 案例:一塔湖图
·这个案例就是为了更直观的去感受类成员之间共享数据的好处,记录每个学校赞助图书馆的书本:
class University {
public:
University(string t, string l)
{
_tower = t;
_lake = l;
}
static string& Getlib()
{
return _lib;
}
void Dis()
{
cout << "塔:" << _tower << " 湖:" << _lake << " 图:" << _lib
<< endl;
}
private:
string _tower;
string _lake;
static string _lib;
};
string University::_lib = "";
int main(int argc, char** argv)
{
University pk("博雅塔","未名湖");
University sc("钟楼", "墨池");
University cq("雷峰塔", "西湖");
University::Getlib() += "钢铁是怎样炼成的,";
University::Getlib() += "海底两万里,";
University::Getlib() += "格林童话,";
pk.Dis();
sc.Dis();
cq.Dis();
system("pause");
return 0;
}
其中,有一个很有意思的地方。
static string& Getlib()
{
return _lib;
}
仔细看这么一个函数。_lib明明是私有变量,可是我们却可以通过这种接口的方式去返回它的引用,并修改他的值。算是一个 C++ 的后门小bug吧。
5.2.4.2 static修饰成员函数
为了管理静态成员,C++提供了静态函数,以对外提供接口。并且静态函数只能访问静态成员。
- 静态成员函数的意义,不在于信息共享,数据沟通,而在于管理静态数据成员,完成对静态数据成员的封装。
- staitc 修饰成员函数,仅出现在声明处,不可在定义处。
- 静态成员函数只能访问静态数据成员。原因:非静态成员函数,在调用时 this指针时被当作参数传进。而静态成员函数属于类,而不属于对象,没有 this 指针。
5.2.4.2.1 案例:取号服务
class Server {
public:
Server(char name):_serverName(name)
{
}
static int & GetCusCount()
{
return _cusCount;
}
void ServerOne()
{
//若服务号小于客户数,则开始服务,随后自加,为下一个窗口的服务号做准备
if (_openFlag && _curCus++ < _cusCount)
{
cout << _serverName << " 服务:" << _curCus << endl;
}
}
static bool& StillOpen()
{
//若服务号等于客户数,说明没有客户了,则关闭窗口
if (_curCus >= _cusCount)
{
cout << "没有多余客户,窗口即将关闭。。。" << endl;
_openFlag = !_openFlag;
}
return _openFlag;
}
private:
char _serverName;
static int _cusCount;//票号
static bool _openFlag;//标志位,窗口是否继续开启
static int _curCus;
};
int Server::_cusCount = 0;
bool Server::_openFlag = true;
int Server::_curCus = 0;
int main(int argc, char** argv)
{
Server a('A'), b('B'), c('C'), d('D');
int num = 0;
do
{
//询问还有多少人排队
cout << "how many people in your line: ";
cin >> num;
for (int i = 0; i < num; i++)
{
cout << "idx: " << ++Server::GetCusCount() << endl;
}
a.ServerOne();
b.ServerOne();
c.ServerOne();
d.ServerOne();
} while (Server::StillOpen());
cout << "窗口关闭" << endl;
system("pause");
return 0;
}
5.3.1 单例模式
一个类仅有一个实例的现像,称为单例模式,此处并不讲单例存在和使用的意义, 只讲实现一个实例的技术手段。
//单例模式主要用于实现共享。
class Singleton {
public:
static Singleton* getInstaance()
{
if (_ins == nullptr)
{
_ins = new Singleton;
}
return _ins;
}
static void releaseIns()
{
if (_ins != nullptr)
{
delete _ins;
_ins = nullptr;
}
}
private :
Singleton()
{
}//此时不能通过常规手段生成对象他。
Singleton(const Singleton&)
{
}
Singleton& operator=(const Singleton&)
{
}
~Singleton()
{
}
static Singleton* _ins;
};
Singleton* Singleton::_ins = nullptr;
int main(int cargc, char** argv)
{
Singleton* ps = Singleton::getInstaance();
Singleton::releaseIns();
cout << ps << endl;
system("pause");
return 0;
}
5.3.1 渲染树 (Render Tree)
一套成熟的类库,通常都会引入内存管理,从使用的角度来说,只见 new不见delete, 或是自始至终见不到new 和delete。
class CCSprite {
public:
CCSprite()
{
};
static CCSprite* Create()
{
CCSprite* pRet = new CCSprite;
if (pRet && pRet->Init())
{
pRet->AutoRealease();
return pRet;
}
else
{
delete pRet;
pRet = nullptr;
exit(-1);
}
}
bool Init()
{
cout << "Initial" << endl;
this->ch = (rand() % (127 - 33)) + 33;
return true;
}
static void RenderTree()
{
CCSprite* t = head;
while (t)
{
cout << t->ch << endl;
t = t->next;
}
}
void AutoRealease()
{
this->next = head;
head = this;
}
private:
static CCSprite* head;
CCSprite* next;
char ch;
};
CCSprite* CCSprite::head = nullptr;
int main(int argc, char** argv)
{
srand(time(0));
CCSprite* ps = CCSprite::Create();
CCSprite* ps2 = CCSprite::Create();
CCSprite* ps3 = CCSprite::Create();
CCSprite* ps4 = CCSprite::Create();
CCSprite* ps5 = CCSprite::Create();
CCSprite::RenderTree();
system("pause");
return 0;
}
5.4 ststic const in class
如果一个类的成员,既要实现共享,又要实现不可改变,那就用 static const组合模式来修饰。 修饰成员函数,格式并无二异,修饰数据成员,必须要类内部初始化。初始化和使用 方法,见如下示例。
class SC {
public:
SC()
{
};
static const int _a = 100;
};
int main(int argc, char** argv)
{
SC sc;
cout << sc._a << endl;
system("pause");
return 0;
}
5.5 指向类成员的指针
C++扩展了指针在类中的使用,使其可以指向类成员(数据成员和函数成员),这种行为是类层面的,而不是对象层面的。
5.5.1 语法
指向非静态数据成员的指针在定义时必须和类相关联,在使用时必须和具体的对象关
联。
由于类不是运行时存在的对象。因此,在使用这类指针时,需要首先指定类的一个对象,然后,通过对象来引用指针所指向的成员。

5.5.1 应用
指向类对象成员数据
class Student {
public:
Student(string n, int nu) :_name(n), _num(nu)
{
}
string _name;
int _num;
};
int main(int argc, char** argv)
{
Student s("Damon", 23);
Student z("Zhao", 22);
Student* pd = &s;
Student* pz = &z;
string Student:: *psn = &Student::_name;
cout << s.*psn << endl;
cout << pd->*psn << endl;
cout << z.*psn << endl;
cout << pz->*psn << endl;
system("pause");
return 0;
}
指向类成员函数:
定义一个指向非静态成员函数的指针必须在三个方面与其指向的成员函数保持一致: 参数列表要相同、返回类型要相同、所属的类型(类名)要相同。 由于类不是运行时存在的对象。因此,在使用这类指针时,需要首先指定类的一个对 象,然后,通过对象来引用指针所指向的成员。
//类成员指针
class Student {
public:
Student(string n, int nu) :_name(n), _num(nu)
{
}
void Dis(int idx)
{
cout << idx << " " << _name << " " << _num << endl;
}
private:
string _name;
int _num;
};
int main(int argc, char** argv)
{
Student s("Damon", 23);
Student z("Zhao", 22);
Student* pd = &s;
Student* pz = &z;
void (Student::*pdis)(int idx) = &Student::Dis;
(s.*pdis)(1);
(z.*pdis)(2);
(pd->*pdis)(3);
(pz->*pdis)(4);
system("pause");
return 0;
}
5.5.1.1 更加统一的接口
//更加统一的接口
class Point {
public:
int Add(int x, int y)
{
return x + y;
}
int Minus(int x, int y)
{
return x - y;
}
int Mult(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
};
int Oper(Point& p, int (Point::* pf)(int x,int y), int x, int y)
{
return (p.*pf)(x, y);
}
typedef int (Point::* PF)(int x, int y);
int main(int argc, char** argv)
{
Point p;
PF pf = &Point::Add;
cout << Oper(p, pf, 3, 2) << endl;
system("pause");
return 0;
}
5.5.1.2 更加隐蔽的接口
//更加隐蔽的接口
class Player {
public:
Player()
{
pf[0] =&Player::f;
pf[1] =&Player::g;
pf[2] =&Player::h;
pf[3] =&Player::l;
pf[4] =&Player::k;
}
void Select(int i)
{
if (i >= 0 && i <= 4)
{
(this->*pf[i])(i);
}
}
private:
void f(int idx){
cout<< "void f(int idx)"<<endl;}
void g(int idx){
cout<< "void g(int idx)"<<endl;}
void h(int idx){
cout<< "void h(int idx)"<<endl;}
void l(int idx){
cout<< "void l(int idx)"<<endl;}
void k(int idx){
cout<< "void k(int idx)"<<endl;}
enum {
nc = 5
};
void (Player::* pf[nc])(int idx);
};
int main(int argc, char** argv)
{
Player p;
p.Select(0);
p.Select(1);
p.Select(2);
p.Select(3);
p.Select(4);
system("pause");
return 0;
}
5.5.6 指针 or 偏移量
指向类成员的指针,具有指针的形而不具体指针的实质,或者,确切意义上说,不是指针。
5.5.7 指向类静态成员的指针
指向静态成员的指针的定义和使用与普通指针相同,在定义时无须和类相关联,在使用时也无须和具体的对象相关联。在初始化时,要加上类名限定。
第六章 友元
6.1 为什么需要友元
6.1.1 get / set method
get方法和set方法,是常见的获取和设置数据成员的方式。比如精灵遭到对方攻击后 血量减少,就需要用到 set方法,而要实时的显示就需要set方法。
6.1.2 实现
class Sprite
{
public:
Sprite(int lb = 100) :_lifeBlood(lb)
{
}
int GetLifeBlood()
{
return _lifeBlood;
}
void SetLifeBlood(int lb)
{
_lifeBlood = lb;
}
private:
int _lifeBlood;
};
void Attack(Sprite & sp)
{
sp.SetLifeBlood((sp.GetLifeBlood() - 20));
cout << sp.GetLifeBlood() << endl;
}
int main(int argc, char** argv)
{
Sprite sp;
Attack(sp);
system("pause");
return 0;
}
6.1.3 效率是项目中的重中之重
Attack 全局接口,通过战斗来参加或是减少血量,对于这种频繁的操作,是否可以每次不通过对象,而直接操作呢? 方法很简单,将函数fight设置为类Sprite的友元,通过友元这层关系,就可以直接访问类的私有数据成员,从面大大提高的访问的效率。
class Sprite
{
//此处声明为友元
friend void Attack(Sprite& sp);
public:
Sprite(int lb = 100) :_lifeBlood(lb)
{
}
int GetLifeBlood()
{
return _lifeBlood;
}
void SetLifeBlood(int lb)
{
_lifeBlood = lb;
}
private:
int _lifeBlood;
};
void Attack(Sprite & sp)
{
/*sp.SetLifeBlood((sp.GetLifeBlood() - 20));
cout << sp.GetLifeBlood() << endl;*/
sp._lifeBlood = sp._lifeBlood - 20;
cout << sp._lifeBlood << endl;
}
int main(int argc, char** argv)
{
Sprite sp;
Attack(sp);
return 0;
}
get 和 set 方法是标准封装的产物。
friend 破坏了这样的封装,但是带来了效率上的的提高。
6.1.4 why friend
采用类的机制后实现了数据的隐藏与封装,类的数据成员一般定义为私有成员,成员函数一般定义为公有的,依此提供类与外界间的通信接口。 但是,有时需要定义一些函数,这些函数不是类的一部分,但又需要频繁地访问类的数据成员,这时可以将这些函数定义为该类的友元函数。除了友元函数外,还有友元类, 两者统称为友元。 友元的作用是提高了程序的运行效率(即减少了类型和安全性检查及调用的时间开销), 但它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。 友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类。
6.2 关系辨别 (relationship)
6.2.1 同类间无私处 mstring
一个类可以访问本类所有对象的私有成员
mystring::mystring(const mystring & other) {
int len = strlen(other._str);
this->_str = new char[len+1];
strcpy(this->_str,other._str);
}
6.2.2 异类间有友元 struct -> class
但是,如果上层关系,不是发生在同一类之间,就麻烦了。private属性会限制类对象 私有成员的访问。 struct 对象其成员默认是public的,所以operator+函数中是可以成立的,但是 struct 换为 class后,其成员默认是 private 的,就会编译出错。 若不想通过get/set方法来获取私有成员,怎么办呢,答案是友元。
class Complex {
friend Complex operator+(Complex& c1, Complex& c2);
public:
Complex(double r = 0 , double i = 0) :_real(r), _image(i)
{
}
void DumpFormat()
{
cout << "(" << _real << "," << _image << ")" << endl;
}
private:
double _real;
double _image;
};
Complex operator+(Complex& c1, Complex& c2)
{
Complex cReturn;
cReturn._image = c1._image + c2._image;
cReturn._real = c1._real + c2._real;
return cReturn;
}
int main(int argc, char** argv)
{
Complex c1(1, 2), c2(3,4);
Complex sum;
sum = c1 + c2;
sum.DumpFormat();
return 0;
}
6.2.3 友元不是成员
友元函数终究不是成员函数,成员中有隐参this指针,可以直接访问成员,而友元中 则没有,必须得通过对象来访问。 友元仅是打破了,外部访问中的 private 权限。声明为谁的友元,就可以通过谁的对象, 访问谁的私有成员。
友元函数 Freind Function
6.3.1 全局函数作友元
全局函数作友元,只需要在相应的类内作友元函数声明即可。一个函数可以是多个类的友元函数,只需要在各个类中分别声明。 友元的声明位置,可以是类中任意位置,且其声明不受访问权限关键字 (public/protected/private)的影响。
class Point {
friend float GetPointsDistance(const Point& p1, const Point& p2);
public:
//计算两点的距离
Point(int x = 0, int y = 0) :_x(x), _y(y)
{
}
void DumpFormat()
{
cout << "(" << _x << "," << _y << ")" << endl;
}
private:
float _x;
float _y;
};
float GetPointsDistance(const Point & p1, const Point & p2)
{
Point pReturn;
pReturn._x = p1._x - p2._x;
pReturn._y = p1._y - p2._y;
return sqrt(pReturn._x * pReturn._x + pReturn._y * pReturn._y);
}
int main(int argc, char** argv)
{
Point p1(3, 4), p2(7, 8);
p1.DumpFormat();
p2.DumpFormat();
cout << GetPointsDistance(p1, p2) << endl;
return 0;
}
6.3.2 成员函数作友元
一个类的成员函数作友员,在声明为另一个类的友员时,要将原类的作用域加上,其它属性同全局函数。
6.6.3 前向声明ForwardDeclaration
前向声明,是一种不完全型(incompletetype)声明,不能定义对象,可以定义指针和引用,用在函数声明,做参数和返回值,仅用在函数声明中。即只需提供类名(无需提供类实现) 即可。正因为是类型不完成,功能也很有限:
class Point;
class ManagePoint {
public:
float GetPointsDistance(const Point& p1, const Point& p2);
private:
};
class Point {
friend float ManagePoint::GetPointsDistance(const Point& p1, const Point& p2);
public:
//计算两点的距离
Point(int x = 0, int y = 0) :_x(x), _y(y)
{
}
void DumpFormat()
{
cout << "(" << _x << "," << _y << ")" << endl;
}
private:
float _x;
float _y;
};
float ManagePoint:: GetPointsDistance(const Point& p1, const Point& p2)
{
Point pReturn;
pReturn._x = p1._x - p2._x;
pReturn._y = p1._y - p2._y;
return sqrt(pReturn._x * pReturn._x + pReturn._y * pReturn._y);
}
int main(int argc, char** argv)
{
Point p1(3, 4), p2(7, 8);
p1.DumpFormat();
p2.DumpFormat();
ManagePoint mp;
cout << mp.GetPointsDistance(p1, p2) << endl;
system("pause");
return 0;
}
指针和引用的大小均是 4,对于编译器来说是可以确定的,但是对于一个不完类型编译器是无法确定其大小的。 所以上例中的distance(Point &a, Point &b)中的引用改为distance(Point a, Point b)是不可行的。若改为指针类型,distance(Point a, Pointb)则是可行的。 前向声明常见于头文件中,而在其头文件所在的cpp 文件中被包含。
6.4 友元类 Friend class
6.4.1 原由
当希望一个类中所有成员函数,均可存取另一个类的私有成员时,可以将该类声明为 另一类的友元类。 友元类,导致封装破坏的面积扩大化,但由于其简易操作的特性,而常常在实战开发中被使用。
6.4.2 声明

6.4.3 应用
假设在 ManagerPoint 中再加一个函数成员,求三点的面积。doubel area(Point &a, Point&b, Point &c);是否一个友元类就可以搞定了呢?
//友元类
class Point {
friend class ManagePoint;
public:
//计算两点的距离
Point(int x = 0, int y = 0) :_x(x), _y(y)
{
}
void DumpFormat()
{
cout << "(" << _x << "," << _y << ")" << endl;
}
private:
float _x;
float _y;
};
class ManagePoint {
public:
//求两点距离
float GetPointsDistance(const Point& p1, const Point& p2)
{
Point pReturn;
pReturn._x = p1._x - p2._x;
pReturn._y = p1._y - p2._y;
return sqrt(pReturn._x * pReturn._x + pReturn._y * pReturn._y);
};
//求三点面积
float GetAre(const Point& p1, const Point& p2, const Point& p3)
{
float a = abs(GetPointsDistance(p1, p2));
float b = abs(GetPointsDistance(p1, p3));
float c = abs(GetPointsDistance(p2, p3));
float p = (a + b + c) / 2;
return sqrt(p * (p - a) * (p - b) * (p - c));//海伦公式
}
private:
};
int main(int argc, char** argv)
{
Point p1(0, 0), p2(3, 0), p3(3, 4);
ManagePoint mp;
cout << mp.GetPointsDistance(p2, p3) << endl;
cout << mp.GetAre(p1, p2, p3) << endl;
system("pause");
return 0;
}
6.5 总结
6.5.1 声明位置
友元声明以关键字friend 开始,它只能出现在类定义中。因为友元不是类授权的成员, 所以它不受其所在类的声明区域 public private 和 protected 的影响。通常我们选择把所有友元声明组织在一起并放在类头之后。具体放的位置,要看团队的一致风格
6.5.2 友元利弊
友元不是类成员,但是它可以通过对象访问类中的私有成员。友元的作用在于提高程序的运行效率,但是,它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。不过,类的访问权限确实在某些应用场合显得有些呆板,从而容忍了友元这一特别 语法现象。
6.5.3 注意
- 友元关系不能被继承。
- 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
- 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是 类A的友元,同样要看类中是否有相应的声明。
第七章 运算符重载Operator Overload
对于基本数据类型,比如 int 类型,我们对其进行加、减、乘、除运算,是语言层面己经设置好的。 但是对于结构类型,比如structComplex类型的对象是否也可以直接进行加、减、乘、 除运算呢,答案是否定的。要想实现自定义类型加、减、乘、除运算,怎么操作呢,对加、减、乘、除运算符进 行重载,也就是本章要讲解的内容,运算符重载的本质是函数重载。
7.1重载引入
7.1.1 语法格式
重载函数的一般格式如下,operator是关键字,后面跟的是运算符,operator+运算符构成了新的函数名,此时我们说该运算符被重载了。

7.1.2 友元重载
友元重载的本质是全局函数重载。
class Complex {
friend Complex operator+(Complex& c1, Complex& c2);//友元重载
public:
Complex(double r = 0, double i = 0) :_real(r), _image(i)
{
}
void DumpFormat()
{
cout << "(" << _real << "," << _image << ")" << endl;
}
private:
double _real;
double _image;
};
//通过此处访问Complex的私有成员
Complex operator+(Complex& c1, Complex& c2)
{
Complex cReturn;
cReturn._image = c1._image + c2._image;
cReturn._real = c1._real + c2._real;
return cReturn;
}
int main(int argc, char** argv)
{
Complex c1(1, 2), c2(3, 4);
Complex sum;
sum = c1 + c2;
sum.DumpFormat();
return 0;
}
7.1.3 成员重载
友元重载到成员重载,少了一个参数。少的参数,即左操作数,也就是成员函数中的 this指针。
class Complex {
public:
Complex(double r = 0, double i = 0) :_real(r), _image(i)
{
}
void DumpFormat()
{
cout << "(" << _real << "," << _image << ")" << endl;
}
const Complex operator+(Complex& another)
{
Complex cReturn;
cReturn._image = this->_image + another._image;
cReturn._real = this->_real + another._real;
return cReturn;
}
private:
double _real;
double _image;
};
int main(int argc, char** argv)
{
Complex c1(1, 2), c2(3, 4);
Complex sum;
sum = c1 + c2;
sum.DumpFormat();
system("pause");
return 0;
}
7.1.4 const作返值修饰符
C++引入引用的概念后,表达式可以被赋值的现象就出现了,有的表达式可以被赋值, 有的表达式则不可以。
比如,inta;intb;intc; (a=b)= c; 是可以的。而,(a+b)=c;则是不允许的。重载的运算符是否会导致表达式可以被赋值应该以基础类型为准。返回类型通过加 const加以限定来实现。 并不是所有的表达式均可被赋值。
7.2 重载规则
7.2.1 可被重载的操作符

7.2.2 不能新增运算符
只能对已有的C++运算符进行重载。例如,有人觉得 BASIC中用"**“作为幂运算符很方便,也想在 C++中将”* "定义为幂运算符,用"3 *5"表示 35,这是不行的。
7.2.3 不能改变操作数的个数
关系运算符">“和”<“等是双目运算符,重载后仍为双目运算符,需要两个参数。运算符 “+”,”-","*","&"等既可以作为单目运算符,也可以作为双目运算符,可以分别将它们重载为单目运算符或双目运算符。
7.2.4 不改变语义
应当使重载运算符的功能类似于该运算符作用于标准类型数据时候时所实现的功能。 例如,我们会去重载"+“以实现对象的相加,而不会去重载”+“以实现对象相减的功能,因为这样不符合我们对”+"原来的认知。
7.2.5 至少有一个操作数是自定义类
重载的运算符必须和用户定义的自定义类型的对象一起使用,其参数至少应有一个是类对象(或类对象的引用)。 也就是说,参数不能全部是 C++的标准类型,以防止用户修改用于标准类型数据成员 的运算符的性质,如下面这样是不对的:
int operator+(int a,int b) {
return(a-b);
}
原来运算符+的作用是对两个数相加,现在企图通过重载使它的作用改为两个数相减。 如果允许这样重载的话,如果有表达式 4+3,它的结果是 7 还是 1呢?显然,这是绝对要禁止的。
7.2.6 其他
- 不能改变运算符的优先级 例如"*“和”/“优先级高于”+“和”-",不论怎样进行重载,各运算符之间的优先级 不会改变。有时在程序中希望改变某运算符的优先级,也只能使用加括号的方法强 制改变重载运算符的运算顺序。
- 重载不能改变运算符的结合性。 如,复制运算符"="是右结合性(自右至左),重载后仍为右结合性。
- 重载运算符的函数不能有默认的参数 否则就改变了运算符参数的个数,否则,就会跟7.2.3相矛盾。
- 某些运算定律未必支持 比如,加法交换律。
7.3 重载范例
7.3.1 双目例举
7.3.1.1. 格式

7.3.1.2 operator+=

Complex & operator+=(const Complex& another)
{
this->_real += another._real;
this->_image += another._image;
return *this;
}
7.3.2 单目例举
7.3.2.1 格式

7.3.2.2 operator- (minus)

const 对象不能调用非const成员函数
const Complex operator-() const
{
return Complex (-this->_real,-this->_image);
}
private:
double _real;
double _image;
};
7.3.2.3 operator++ ()
Complex & operator++()
{
this->_image++;
this->_real++;
return *this;
}
7.3.2.4 operator++ (int)
为了区别前加加和后加加,引入了哑元的概念,引入哑元(增加了入参的方式,在调用 时并不要传任何的参数),仅仅为了区分,并无其它意义。

const Complex operator++(int a)
{
Complex r = *this;
this->_image++;
this->_real++;
return r;
}
7.3.2.5. 匿名对象的知多少
匿名对象,可以被赋值 ,可以调用成员函数,可赋给const同类的引用。
7.4 实战
7.4.1 成员函数作谁的-成员?友元?
7.4.4.1 引例
假设,我们有类Sender类和 Mail类,实现发送邮件的功能。
Sender sender;
Mail mail;
sender << mail;
sender左操作数,决定了operator<<为Sender的成员函数,而mail决定了operator<< 要作 Mail类的友员。
class Email {
friend class Sender;
public:
Email(string t = 0, string c = 0) :_title(t), _contents(c)
{
}
private:
string _title;
string _contents;
};
class Sender {
public:
Sender(string a = 0) :_address(a)
{
}
Sender& operator<<(const Email & mail)
{
cout << mail._title << endl;
cout << mail._contents << endl;
return *this;
}
private:
string _address;
};
int main(int argc, char** argv)
{
Sender damon("[email protected]");
Email email("开会", "关于本月绩效总结");
Email email2("通知", "关于撤销本次会议");
damon << email << email2;
return 0;
}
7.3.4 非全局莫属 operator << / >>
不可能通过增加 istream 或ostream 成员的方式重载>>/<<,此时只能通过在自定义的类中增加友元函数的方式重载>>/<<。
7.3.3 中讲的成员函数的问题,本节作为补充讲的是全局函数的问题。
//operator>>(cin,c);
friend istream& operator>>(istream& ci,Complex & c)
{
ci >> c._real;
ci >> c._image;
return ci;
}
//operator(cout,c);
friend ostream& operator<<(ostream& co,Complex & c)
{
co <<"("<<c._real<<","<<c._image<<")"<<endl;
return co;
}
7.5 自定义类型转化 User-DefinedTypeCast
类型转化对于语言实现层面来讲,是最复杂的。同样,不同类对象间进行转化,也是比较复杂的。
7.5.1 标准类型转换
7.5.1.1 隐式转化
参见 C语言,标准类型隐式转化
7.5.1.2 强制转化
参见 C语言,标准类型强制转化
7.5.2 自定义类型-转化构造函数
7.5.2.1 语法
class 目标类{
目标类(const 源类型 & 源类对象引用)
{
根据需求完成从源类型到目标类型的转换
}
}
7.5.2.2 特性
- 目标 实现其它类型到本类类型的转化。
- 原理 转换构造函数,本质是一个构造函数。是只有一个参数的构造函数。如有多 个参数,只能称为构造函数,而不是转换函数。转换构造,强调的是一转一。
- 应用 用于传参或是作返回。
7.5.2.3 实现
class Point2D {
friend class Point3D;
public:
Point2D(int x = 0, int y = 0) :_x(x), _y(y)
{
}
private:
int _x;
int _y;
};
class Point3D {
public:
Point3D(int x = 0, int y = 0, int z = 0) :_x(x), _y(y), _z(z)
{
}
Point3D(const Point2D& d2)
{
this->_x = d2._x;
this->_y = d2._y;
this->_z = rand() % 100;
}
void DumpFormat()
{
cout << _x << " " << _y << " " << _z << endl;
}
private:
int _x;
int _y;
int _z;
};
Point3D Convert3to2(Point2D& d2)
{
return Point3D(d2);
}
int main(int argc, char** argv)
{
srand(time(0));
Point2D d2(10, 100);
Point3D d3 = d2;
d3.DumpFormat();
return 0;
}
7.5.2.4 explicit 关键字
关键字 explicit 可以禁止"单参数构造函数"被用于自动类型转换。即 explicit 仅用于单参构造(默认参数构成的单参亦算)。 转化多是刻意而为之,以隐式的形式发生,为了示意同正常构造的不同,常用explicti 关键字修饰,要求在转化时显示的调用其构造器完成转化。
在以上例子中,我们给转化构造函数加上这个关键字,main里的隐式转化将不可实现,所以我们必须使用显示的转化:
Point3D d3 = (Point3D)d2;
或者:
Point3D = static_cast<Point3D>(d2);
7.5.3 自定义类型-操作符函数转化
7.5.3.1 语法
class 源类{
operator 目标类(void) {
return 目标类构造器(源类实参);
}
}
7.5.3.2 特性
转换函数必须是类方法,转换函数无参数,无返回。
7.5.3.3 实现
class Point2D{
operator Point3D()
{
return Point3D(this->_x, this->_y, rand() % 100);
}
}
7.6 高级主题扩展
7.6.1 仿函数 (Functor)
把类对象,像函数名一样使用,所认称为仿函数,本质是类对象。 仿函数(functor),就是使一个类的使用看上去像一个函数。其实现就是类中实现一个 operator(),这个类就有了类似函数的行为,就是一个仿函数类了。
7.6.1.1 语法格式
class 类名
{
返值类型 operator()(参数类型)
函数体
}
7.6.1.2 示例
class Pow
{
public:
int operator()(int a,int b)
{
if (!b)
return 1;
int t = a;
for (int i = 0; i < b-1; i++)
t *= a;
return t;
}
private:
};
//仿函数
int main(int argc, char** argv)
{
int a = 5;
cout << pow(a, 2) << endl;;
cout << a << endl;
Pow myPow;
cout << myPow(a, 2) << endl;
cout << a << endl;
return 0;
}
7.6.1.3 sort中的回调
class Compare {
public:
Compare(bool f = true) :flag(f)
{
}
bool operator()(int a, int b)
{
if (flag)
return a < b;
else
return a > b;
}
private:
bool flag;
};
int main(int argc, char** argv)
{
int arr[6] = {
1,3,5,8,6,4 };
vector<int> vi(arr, arr + 6);
sort(vi.begin(), vi.end(), Compare(false));
for (auto itr = vi.begin(); itr != vi.end(); ++itr)
cout << *itr << endl;
system("pause");
return 0;
}
7.6.1.4 functor 的优势
functor的优势在于,是对象形式,可以携带更多的的信息,用于作出判断。比如,我 们可以在对象初始化的时候,传入参数来决定状态,而不用去修改原代码。如,7.6.1.3 中的 Compare。
7.7.2 对象模拟指针(Smart Point)
一套成熟的类库,通常都会引用内存管理机制。 C++作为语言层面也提供了,相应的解决方案,即智能指针,auto_ptr。虽然 auto_ptr 己经被 deserted 了(引自 GoogleC++ 编程规范),它的后继者,诸如share_ptr,weak_ptr 灵 感均取自于此。
7.7.2.1 什么是RAII
RAII(Resource Acquisition IsInitialization),也称为"资源获取即初始化",是 C++语言的 一种管理资源、避免泄漏的惯用法。
C++标准保证任何情况下,已构造的对象最终会销毁,即它的析构函数最终会被调用。 简单的说,RAII 的做法是使用一个对象,在其构造时获取资源,在对象生命期控制对资源的访问使之始终保持有效,最后在对象析构的时候释放资源。
即 new 获取资源,constructor 构造资源 初始化。
7.7.2.2 auto_ptr
auto_ptr<RAII> p(new RAII);
p->XXXX();
这样的使用不同于直接声明该对象的指针,普通指针不会释放,它等价于:
RAII r;
r.XXXX();
他们会自动调用析构器并且进行释放。
7.7.2.3 auto_ptr 自实现
我们需要重载 * 符号,这里不重载 . 和-> 的原因是他们不能被重载。
class RAII {
public:
RAII()
{
cout << "RAII()" << endl;
}
void XXXX()
{
cout << "XXXX()" << endl;
}
~RAII()
{
cout << "~RAII()" << endl;
}
private:
};
class SmartPtr {
public:
SmartPtr(RAII * pr)
{
_pr = pr;
}
RAII & operator*()
{
return *_pr;
}
~SmartPtr()
{
delete _pr;
}
private:
RAII* _pr;
};
void FOO2()
{
SmartPtr ps(new RAII);
(*ps).XXXX();
}
7.7.3 operator new/delete预定义的内存
适用于极个别情况需要定制的时候才用的到。一般很少用,比如定制内存。
7.2.3.1 operator new/delete语法格式
void *operator new(size_t);
void operator delete(void *);
void *operator new[](size_t);
void operator delete[](void *);
7.2.3.2 全局重载
最好不要在全局重载,这样会把对基础数据的 new / delete 一起重载。
7.2.3.3 实现
class T {
public:
T()
{
//_x = 100;
//_y = 200;
cout << "T()" << endl;
putchar(10);
}
void XXX()
{
cout << "XXX(): " << _x << _y << endl;
putchar(10);
}
void* operator new(size_t size)
{
cout << size << endl;
cout << "void* operator new(size_t)" << endl;
void* p = malloc(size);
cout << p << endl;
((T*)p)->_x = 100;
((T*)p)->_y = 200;
putchar(10);
return p;
}
void *operator new[](size_t size) {
cout << size << endl;
cout << "void* operator new[](size_t)" << endl;
void* p = malloc(size);
cout << p << endl;
return p;
}
void operator delete(void *p)
{
free(p);
cout << p << endl;
}
void operator delete[](void* p)
{
cout << "delete[]" << endl;
free(p);
cout << p << endl;
}
~T()
{
cout << "~T()" << endl;
putchar(10);
}
private:
int _x;
int _y;
};