一、报告背景:
2018年8月7日,境外[旅游]服务商KLOOK客路旅行已获D轮融资,成为全球旅游活动领域融资金额最高的公司。在高速发展状况下,KLOOK客路旅行境外活动是否始终保持高速发展、高评价、高服务?
二、报告目的:
(1)、分析KLOOK客路旅行最火爆活动之一《台北101观景台门票》,通过该活动侧面分析KLOOK客路旅行的经营状况及面临的风险。
(2)、通过案例数据完成一份Python的数据分析报告。
三、分析方法:
六西格玛DMAIC分析方法(DMAIC是六西格玛管理中流程改善的重要工具。DMAIC是指定义Define、测量Measure、分析Analyze、改进Improve、控制Control五阶段构成。)
四、分析过程:
(1)、定义Define:
范围:台北101观景台门票
风险:爬虫导致KLOOK客路旅行服务器崩溃
解决:空闲时间爬取数据
收益:分析现状、预测未来、发现风险、提高服务
工具:Python、SPSS、MYSQL、SQL、Excel
(2)、测量Measure:
收集时间:2019-02-28
收集方法:详见《原创|实战爬虫|客路旅行》(https://www.jianshu.com/p/0d44a72e6269)
(3)、分析Analyze:
数据:链接:https://pan.baidu.com/s/13T13o-7_SAAifsyj2zaLAQ 提取码:qv4c
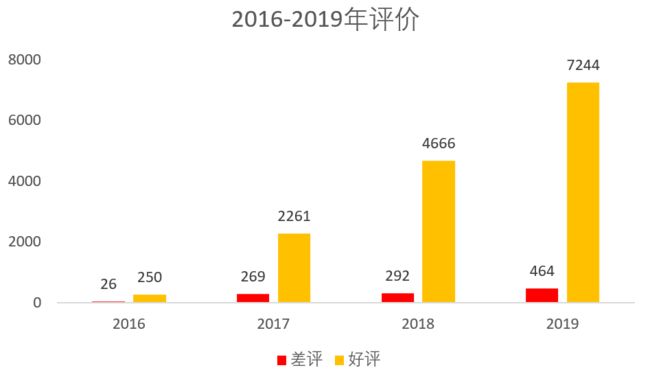
好评:评分>=80
差评:评分<=60
①、现状分析
#导入库
# -*- UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
#用户、评价、时间、年份、价格、频率
columns=['author','rating','time','year','amount','frequency']
df=pd.read_table(r'C:\Users\41174\Desktop\kelu.csv',names=columns,sep=',',skiprows=1)
print(df.head())

如图,数据来源:客路旅行[台北101观景台门票]的用户评价及基本信息。数据时间范围:2016年到2019年2月28日,活动价格110元。
print(df.rating.describe())

样本数:8757,评价92.42分,满分100分,与客路网4.6分,满分5分,公布的数据与实际一致。
df['time']=pd.to_datetime(df.time,format='%Y/%m/%d')
df['month']=df.time.values.astype('datetime64[M]')
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
ax=df.groupby('time').rating.count().plot(figsize=(12,4))
df_max=df.groupby('time').max().rating.count()
ax.set_xlabel('时间')
ax.set_ylabel('数量')
ax.set_title('2016-2019年每天销售数量')
plt.xticks(rotation=0)
plt.show()
#2016年到2019年销量排名前10的日期
df_max=df.groupby('time').rating.count().sort_values(ascending=False)
df_min=df.groupby('time').rating.count().sort_values(ascending=True)
print(df_max.head(10).sort_index(ascending=False))
print(df_min.head(60).sort_index(ascending=False))



如上两图,最高日销售量33份,最高日销售量集中在2018年12月和2019年1月份。最差日销售量集中在2018年1月和3月,最低日销售量1份。但整体最差销售月份集中在2018年4月份,从2018年1月到4月份销售情况很不乐观,猜想是由于价格因素导致此波动,从侧面验证了此波动60%的可能性是由价格引发。
ax=df.groupby('month').rating.count().plot(figsize=(12,4))
ax.set_xlabel('月份')
ax.set_ylabel('数量')
ax.set_title('2016-2019年每月销售数量')
plt.show()

如图,2018年2、3、4月份总销量明显不佳,但4月份尤其明显,估计活动涨价,导致销量异常。
grouped_count_author = df.groupby('author').frequency.count().reset_index()
grouped_sum_amount=df.groupby('author').amount.sum().reset_index()
user_purchase_retention = pd.merge(left = grouped_count_author, right = grouped_sum_amount, how = 'inner', on ='author', suffixes=('', '_min'))
ax=user_purchase_retention.plot.scatter('frequency','amount')
ax.set_xlabel('数量')
ax.set_ylabel('金额(元)')
ax.set_title('每个用户购买数量和金额')
plt.show()

如图,销售数量和销售金额成线性关系。
bin = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
ax=df.groupby('author').frequency.count().plot.hist(bins=bin)
ax.set_xlim(1,17)
ax.set_xlabel('购买数量')
ax.set_ylabel('人数')
ax.set_title('用户购买门票直方图')
plt.show()

如图,80%顾客只购买1次,约6900名,占总体份额80%以上,符合二八定律。
df_frequency_2=df.groupby('author').count().reset_index()
bin = [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
ax=df_frequency_2[df_frequency_2.rating>=2].groupby('author').frequency.sum().plot.hist(bins=bin)
ax.set_xlim(2,17)
ax.set_xlabel('购买数量')
ax.set_ylabel('人数')
ax.set_title('用户购买门票2次及以上直方图')
plt.show()

df_frequency_2[df_frequency_2.frequency>=2].groupby('frequency').frequency.count()
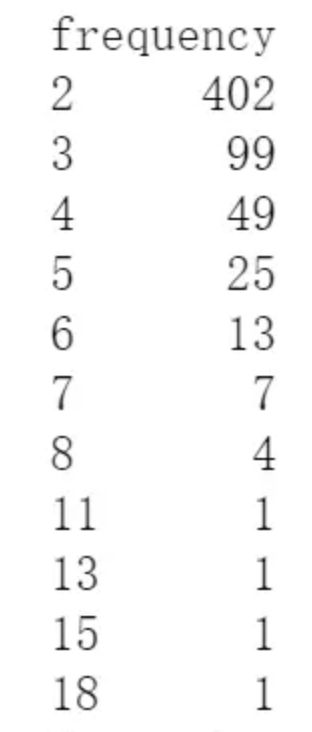
如图,除去购买1次顾客,看其余购买次数的数量情况,购买2次顾客402名,3次99名,4次49名,5次25名,6次13名,7次7名,8次4名,11、13、15、18次顾客各1名。
#筛选出购买次数1~5间数量,其余购买频次数量少,忽略不计。
df_frequency_1=df.groupby('author').frequency.count().reset_index()
df_frequency_1_2_5=df_frequency_1[df_frequency_1.frequency>=1].reset_index()
labels=[u'1次',u'2次',u'3次',u'4次',u'5次']
sizes=list(df_frequency_1_2_5[df_frequency_1_2_5.frequency<=5].groupby('frequency').frequency.sum())
plt.pie(sizes,labels=labels,autopct='%3.1f%%')
plt.title('购买次数1~5次的饼状图')
plt.show()

如图,购买1次顾客占比83.4%,2次9.4%,3次3.5%,4次2.3%,5次1.5%,其余,忽略不计。
df_frequency_2_2_5=df_frequency_2[df_frequency_2.frequency>=2].reset_index()
df_frequency_2_2_5=df_frequency_2_2_5[df_frequency_2_2_5.frequency<=5].groupby('frequency').frequency.sum()
sizes=list(df_frequency_2_2_5)
labels=[u'2次',u'3次',u'4次',u'5次']
plt.pie(sizes,labels=labels,autopct='%3.1f%%')
plt.title(('购买次数2~5次的饼状图'))
plt.show()

如图,去除购买1次顾客,购买2次顾客占比56.5%,3次顾客占比20.9%,4次顾客占比13.8%,5次顾客8.8%。
#当月复购率
pivot_count=df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_count=pivot_count.applymap(lambda x: 1 if x>1 else np.NAN if x==0 else 0 )
ax=(pivot_count.sum()/pivot_count.count()).plot()
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分比(%)')
ax.set_title('2016-2019年每月复购率')
plt.show()

复购率:复购率的定义是在某时间窗口内消费两次及以上的用户在总消费用户中占比。这里的时间窗口是月,如果一个用户在同一天下了两笔订单,也算作复购用户。
如图,2016年8月份复购率最高约7.5%,然后陡降到2%,接着保持稳定状态。
fig,ax=plt.subplots(figsize=(12,6))
ax=pivot_count.sum().plot()
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月复购用户人数')
plt.show()
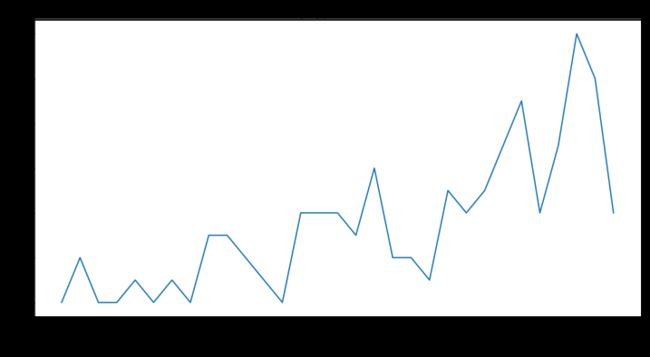
如图,2018年4月份复购人数明显下降,可能是活动价格调整,导致人数降低。2018年10月份和2019年2月份,单月整体销量比往年翻倍,复购人数却下降,存在明显异常。
#回购率
pivot_purchase=df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_purchase.applymap(lambda x:1 if x>0 else 0)
#定义函数,每个月都要跟后面一个月对比下,本月有消费且下月也有消费,则本月记为1,下月没有消费则为0,本月没有消费则为NaN,由于最后个月没有下月数据,规定全为NaN
def purchase_return(data):
status = []
for i in range(30):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
pivot_purchase_return=pivot_purchase.apply(purchase_return,axis=1)
fig,ax=plt.subplots(figsize=(12,6))
columns=df.month.sort_values().unique()
ax.plot(columns,list(pivot_purchase_return.sum()/pivot_purchase_return.count()))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分比(%)')
ax.set_title('2016-2019年每月回购率')
plt.show()

回购率:回购率是某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。例如:前一月消费用户1000,后一个月仍有200个消费,回购率是20%。由于牵扯两个时间窗口的计算,所以较之复购率稍稍复杂点。
如图,2016年6月份达最高峰回购率4.5%,2016年到2018年6月份回购率呈上升趋势,往后开始略微下降到1%,结合下图回购人数,2019年回购率人数0,回购的趋势速度明显放缓。
fig,ax=plt.subplots(figsize=(12,6))
ax.plot(columns,list(pivot_purchase_return.sum()))
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月回购人数')
legends=['每月回购人数']
ax.legend(legends,loc = 2)
plt.show()

def active_status(data):
status = []
for i in range(31):
#若本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月有消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status)
pivot_purchase_status = pivot_purchase.apply(active_status, axis =1)
pivot_purchase_status.columns = columns
pivot_purchase_status.head()
pivot_status_counts =pivot_purchase_status.replace('unreg', np.NaN).apply(pd.value_counts)
ax=pivot_status_counts.fillna(0).T.plot.area(figsize=(12,6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月各类用户类型占比面积图')
plt.show()

根据用户的消费行为,划分成几个维度:活跃用户、新用户、回流用户、不活跃用户。
活跃用户(active):即连续两个时间窗口都消费过的用户。
新用户(new):新用户的定义是第一次消费的用户。
回流用户(return):回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。
不活跃用户(unactive):不活跃用户则是时间窗口内没有消费过的活跃用户,即一二月份都消费过,三月份没消费过。
如图,活动的主要动力是新用户,2018年4月份,明显没有新用户,存在异常危机,2018年4月份到2019年2月份,新用户明显趋于稳定,但2019年2月份,有略微下降。
return_rate = pivot_status_counts.apply(lambda x: x/x.sum())
ax = return_rate.loc['return'].plot(figsize = (12,6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分数(%)')
ax.set_title('每月回流用户占比')
plt.show()

回流用户(return):回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。
如图,回流用户保持在1%±0.2%上下波动,整体回流用户比较稳定,但2019年2月份明显下降,预估是春节活动影响。
ax = return_rate.loc['active'].plot(figsize = (12,6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分数(%)')
ax.set_title('每月活跃用户占比')
plt.show()

活跃用户(active):即连续两个时间窗口都消费过的用户。
如图,开始最高峰活跃用户0.55%,然后下降到0.2%,在此范围内波动,2019年2月有异常波动,估计是春节活动影响。
#用户生命周期
user_purchase = df[['author','rating','time','year','amount','frequency','month']]
time_min=user_purchase.groupby('author').time.min()
time_max=user_purchase.groupby('author').time.max()
life_time = (time_max-time_min).reset_index()
print(life_time.describe())

如图,原样本数:8757,用户存在多次购买,所以样本数量缩减到7722,到平均二次间隔消费时间23天,最大间隔时间864天。
life_time['life_time'] = life_time.time/np.timedelta64(1,'D')
ax=life_time.life_time.plot.hist(bins =100,figsize = (12,6))
ax.set_xlabel('天数(天)')
ax.set_ylabel('人数(人)')
ax.set_title('二次消费以上用户的生命周期直方图')
plt.show()

如图,单次消费用户达到7130,生命周期0天,其余592用户属于优质忠诚用户。
life_time['life_time'] = life_time.time/np.timedelta64(1,'D')
ax=life_time[life_time.life_time>0].life_time.plot.hist(bins =100,figsize = (12,6))
ax.set_xlim(0,900)
ax.set_xlabel('天数(天)')
ax.set_ylabel('人数(人)')
ax.set_title('二次消费以上用户的生命周期直方图')
plt.show()
life_time_gm0=life_time[life_time.life_time>0].life_time.reset_index()
print(life_time_gm0.mean())
print(len(life_time_gm0))
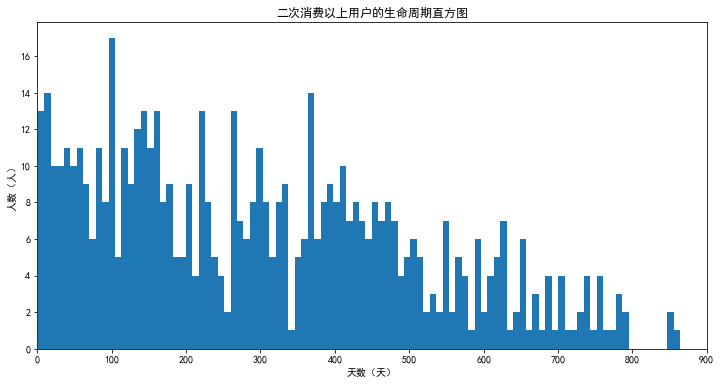

如图,去掉单次购买顾客,看其余顾客的生命周期,平均生命周期300天,0~100天内达到最高峰,100~370天缓慢下降,370~870天快速下降。
user_purchase_retention =pd.merge(left=user_purchase,right=time_min.reset_index(),how='inner',on='author',suffixes=('','_min'))
user_purchase_retention['time_diff'] = user_purchase_retention.time-user_purchase_retention.time_min
user_purchase_retention['time_diff'] = user_purchase_retention.time_diff.apply(lambda x: x/np.timedelta64(1,'D'))
bin = [0,90,180,270,360,450,540,630,720,810,900]
user_purchase_retention['time_diff_bin'] = pd.cut(user_purchase_retention.time_diff, bins = bin)
pivot_retention= user_purchase_retention.groupby(['author','time_diff_bin']).frequency.sum().unstack()
pivot_retention_trans = pivot_retention.fillna(0).applymap(lambda x: 1 if x >0 else 0)
ax = (pivot_retention_trans.sum()/pivot_retention_trans.count()).plot.bar()
ax.set_xlabel('时间跨度(天)')
ax.set_ylabel('百分数(%)')
ax.set_title('各时间段的用户留存率')
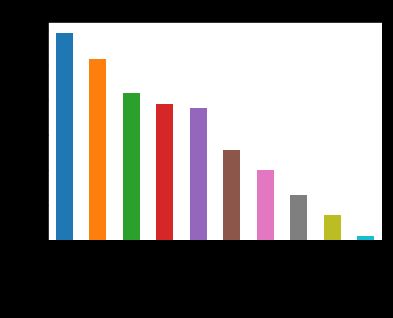
如图,每个周期是3个月,第一个周期留存率30%,连续2个周期,每次递减5%,到达20%,然后保持20%稳定2个周期,最后每月递减约5%,直到0%。根据观察,保持稳定最重要的是第4个周期,也就是跨度1年,必须开始召回用户,若不召回用户,就会产生大量用户流失。
#创建函数,返回时间差
def diff(group):
d= abs(group.time_diff - group.time_diff.shift(-1))
return d
last_diff = user_purchase_retention.groupby('author').apply(diff)
ax = last_diff.hist(bins = 20)
ax.set_xlabel('时间跨度(天)')
ax.set_ylabel('人数(人)')
ax.set_title('用户平均购买周期直方图')
plt.show()
print(life_time_gm0.mean())
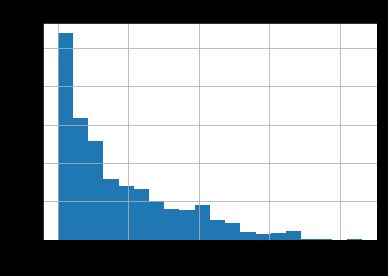

如图,典型的长尾分布,大部分用户的消费间隔0天,只有单次消费。为了召回用户,不妨将时间召回点设为消费后立即赠送优惠券,消费后7天内询问重要用户的体验感,消费后30天提醒优惠券到期,消费后300天短信推送活动资讯,吸引关注。


如图,新老用户好评主因是便宜和方便,80%可能性是便宜,从此角度侧面验证了2018年4月份销量异常的原因:价格因素。新老用户差评主因:天气和排队。
②、预测
(a)、预测销量
数据来源:
2016~2019年1月数据来源于客路旅行数据
2019年2-12月数据来源于SPSS预测结果




(b)、预测评价




③、用户
(a)、潜在风险用户

(b)、重点活跃用户

(c)、优质建议用户

(4):提高Improve:
改善监控:
(a)、建立活动销量监控、复购率、回购率、留存率、用户消费行为分层、用户生命周期等监控,及时发现异常并处理,避免事态扩散或销量大幅降低。
改善评价:
(a)、将“天气与排队”对评分影响较大,却是不可控因素提前告知用户,需提前提醒用户活动当天的天气,降低用户的主观因素对评分的影响。
(b)、监控《潜在风险用户》、收集《优质建议用户》建议、关注《重点活跃用户》动向。
改善网络:
(a)、网站无反爬虫措施,容易导致服务器崩溃,造成重大影响。
(5)、控制:Control:
标准化方向:
(a)、可视化活动销量情况、评价体系。
(b)、复购率、回购率、活跃率、留存率。
(c)、用户消费行为分层、用户生命周期。
(d)、监控潜在风险用户及收集优质建议体系。
(e)、建立反爬虫系统。
五、结论
现状方面:
1、2018年2~4月份,销售量明显异常,4月份特别明显,2019年2月份销量有略微下降约100份。
2、活动复购率从7.5%下降到2%,回购率4.5%下降到1%,回流用户从1.2%下降到0.6%。
3、活动销量主要依赖新用户。包含单次购买用户,生命周期平均23天。去除单次购买用户,生命周期平均300天。
4、好评主因:便宜|方便,差评主因:天气|排队。
5、潜在风险用户:8名,重点活跃用户:10名,优质建议用户:4名。
预测方面:
1、2019年预测销量:置信区间95%,置信范围[8533,6884]。
2、2019年预测差评数:置信区间95%,置信范围[719,208]。
改善建议:
1、增加网站的知名度、曝光度,增加与新用户的接触,促进订单量。
2、召回|活跃:消费后立即赠送优惠券,消费后7天内询问重要用户的体验感,消费后30天提醒优惠券到期,消费后300天短信推送活动资讯。
3、重大潜在风险:网站无反爬虫措施。
4、增加复购率、回购率、活跃率、存留率、用户消费行为分层、用户生命周期等监控。
5、增加活动销量和评价的数据监控。
六、完整代码
# -*- UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
columns = ['author', 'rating', 'time', 'year', 'amount', 'frequency']
df = pd.read_table(r'C:\Users\41174\Desktop\kelu.csv', names=columns, sep=',', skiprows=1)
print(df.head())
print(df.rating.describe())
df['time'] = pd.to_datetime(df.time, format='%Y/%m/%d')
df['month'] = df.time.values.astype('datetime64[M]')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
ax = df.groupby('time').rating.count().plot(figsize=(12, 4))
df_max = df.groupby('time').max().rating.count()
ax.set_xlabel('时间')
ax.set_ylabel('数量')
plt.xticks(rotation=0)
ax.set_title('2016-2019年每天销售数量')
plt.show()
df_max=df.groupby('time').rating.count().sort_values(ascending=False)
df_min=df.groupby('time').rating.count().sort_values(ascending=True)
print(df_max.head(10).sort_index(ascending=False))
print(df_min.head(60).sort_index(ascending=False))
ax = df.groupby('month').rating.count().plot(figsize=(12, 4))
ax.set_xlabel('月份')
ax.set_ylabel('数量')
ax.set_title('2016-2019年每月销售数量')
plt.show()
grouped_count_author = df.groupby('author').frequency.count().reset_index()
grouped_sum_amount = df.groupby('author').amount.sum().reset_index()
user_purchase_retention = pd.merge(left=grouped_count_author, right=grouped_sum_amount, how='inner', on='author',
suffixes=('', '_min'))
ax = user_purchase_retention.plot.scatter('frequency', 'amount')
ax.set_xlabel('数量')
ax.set_ylabel('金额(元)')
ax.set_title('每个用户购买数量和金额')
plt.show()
bin = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
ax = df.groupby('author').frequency.count().plot.hist(bins=bin)
ax.set_xlim(1, 17)
ax.set_xlabel('购买数量')
ax.set_ylabel('人数')
ax.set_title('用户购买门票直方图')
plt.show()
df_frequency_2 = df.groupby('author').count().reset_index()
bin = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
ax = df_frequency_2[df_frequency_2.rating >= 2].groupby('author').frequency.sum().plot.hist(bins=bin)
ax.set_xlim(2, 17)
ax.set_xlabel('购买数量')
ax.set_ylabel('人数')
ax.set_title('用户购买门票2次及以上直方图')
plt.show()
df_frequency_2[df_frequency_2.frequency >= 2].groupby('frequency').frequency.count()
# 筛选出购买次数1~5间数量,其余购买频次数量少,忽略。
df_frequency_1 = df.groupby('author').frequency.count().reset_index()
df_frequency_1_2_5 = df_frequency_1[df_frequency_1.frequency >= 1].reset_index()
labels = [u'1次', u'2次', u'3次', u'4次', u'5次']
sizes = list(df_frequency_1_2_5[df_frequency_1_2_5.frequency <= 5].groupby('frequency').frequency.sum())
plt.pie(sizes, labels=labels, autopct='%3.1f%%')
plt.title('购买次数1~5次的饼状图')
plt.show()
df_frequency_2_2_5 = df_frequency_2[df_frequency_2.frequency >= 2].reset_index()
df_frequency_2_2_5 = df_frequency_2_2_5[df_frequency_2_2_5.frequency <= 5].groupby('frequency').frequency.sum()
sizes = list(df_frequency_2_2_5)
labels = [u'2次', u'3次', u'4次', u'5次']
plt.pie(sizes, labels=labels, autopct='%3.1f%%')
plt.title(('购买次数2~5次的饼状图'))
plt.show()
# 当月复购率
pivot_count = df.pivot_table(index='author', columns='month', values='frequency', aggfunc='count').fillna(0)
pivot_count = pivot_count.applymap(lambda x: 1 if x > 1 else np.NAN if x == 0 else 0)
ax = (pivot_count.sum() / pivot_count.count()).plot()
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分比(%)')
ax.set_title('2016-2019年每月复购率')
plt.show()
fig, ax = plt.subplots(figsize=(12, 6))
ax = pivot_count.sum().plot()
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月二次消费用户人数')
plt.show()
# 回购率
pivot_purchase = df.pivot_table(index='author', columns='month', values='frequency', aggfunc='count').fillna(0)
pivot_purchase.applymap(lambda x: 1 if x > 0 else 0)
# 定义函数,每个月都要跟后面一个月对比下,本月有消费且下月也有消费,则本月记为1,下月没有消费则为0,本月没有消费则为NaN,由于最后个月没有下月数据,规定全为NaN
def purchase_return(data):
status = []
for i in range(30):
if data[i] == 1:
if data[i + 1] == 1:
status.append(1)
if data[i + 1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
pivot_purchase_return = pivot_purchase.apply(purchase_return, axis=1)
fig, ax = plt.subplots(figsize=(12, 6))
columns = df.month.sort_values().unique()
ax.plot(columns, list(pivot_purchase_return.sum() / pivot_purchase_return.count()))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分比(%)')
ax.set_title('2016-2019年每月回购率')
plt.show()
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(columns, list(pivot_purchase_return.sum()))
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月回购人数')
legends = ['每月回购人数']
ax.legend(legends, loc=2)
plt.show()
def active_status(data):
status = []
for i in range(31):
# 若本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i - 1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月有消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i - 1] == 'unactive':
status.append('return')
elif status[i - 1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status)
pivot_purchase_status = pivot_purchase.apply(active_status, axis=1)
pivot_purchase_status.columns = columns
pivot_purchase_status.head()
pivot_status_counts = pivot_purchase_status.replace('unreg', np.NaN).apply(pd.value_counts)
print(pivot_status_counts.head())
ax = pivot_status_counts.fillna(0).T.plot.area(figsize=(12, 6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('用户数(人)')
ax.set_title('每月各类用户类型占比面积图')
return_rate = pivot_status_counts.apply(lambda x: x / x.sum())
ax = return_rate.loc['return'].plot(figsize=(12, 6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分数(%)')
ax.set_title('每月回流用户占比')
plt.show()
ax = return_rate.loc['active'].plot(figsize=(12, 6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('百分数(%)')
ax.set_title('每月活跃用户占比')
plt.show()
# 用户生命周期
user_purchase = df[['author', 'rating', 'time', 'year', 'amount', 'frequency', 'month']]
time_min = user_purchase.groupby('author').time.min()
time_max = user_purchase.groupby('author').time.max()
life_time = (time_max - time_min).reset_index()
print(life_time.describe())
life_time['life_time'] = life_time.time / np.timedelta64(1, 'D')
ax = life_time.life_time.plot.hist(bins=100, figsize=(12, 6))
ax.set_xlabel('天数(天)')
ax.set_ylabel('人数(人)')
ax.set_title('二次消费以上用户的生命周期直方图')
plt.show()
life_time['life_time'] = life_time.time / np.timedelta64(1, 'D')
ax = life_time[life_time.life_time > 0].life_time.plot.hist(bins=100, figsize=(12, 6))
ax.set_xlim(0, 900)
ax.set_xlabel('天数(天)')
ax.set_ylabel('人数(人)')
ax.set_title('二次消费以上用户的生命周期直方图')
plt.show()
life_time_gm0 = life_time[life_time.life_time > 0].life_time.reset_index()
print(life_time_gm0.mean())
print(len(life_time_gm0))
user_purchase_retention = pd.merge(left=user_purchase, right=time_min.reset_index(), how='inner', on='author',
suffixes=('', '_min'))
user_purchase_retention['time_diff'] = user_purchase_retention.time - user_purchase_retention.time_min
user_purchase_retention['time_diff'] = user_purchase_retention.time_diff.apply(lambda x: x / np.timedelta64(1, 'D'))
bin = [0, 90, 180, 270, 360, 450, 540, 630, 720, 810, 900]
user_purchase_retention['time_diff_bin'] = pd.cut(user_purchase_retention.time_diff, bins=bin)
pivot_retention = user_purchase_retention.groupby(['author', 'time_diff_bin']).frequency.sum().unstack()
pivot_retention_trans = pivot_retention.fillna(0).applymap(lambda x: 1 if x > 0 else 0)
print(pivot_retention_trans.head())
ax = (pivot_retention_trans.sum() / pivot_retention_trans.count()).plot.bar()
ax.set_xlabel('时间跨度(天)')
ax.set_ylabel('百分数(%)')
ax.set_title('各时间段的用户留存率')
plt.show()
# 创建函数,返回时间差
def diff(group):
d = abs(group.time_diff - group.time_diff.shift(-1))
return d
last_diff = user_purchase_retention.groupby('author').apply(diff)
ax = last_diff.hist(bins=20)
ax.set_xlabel('时间跨度(天)')
ax.set_ylabel('人数(人)')
ax.set_title('用户平均购买周期直方图')
plt.show()
七、备注
若有错误,还望指出,我会及时更新,谢谢!