定义
Hashmap是map接口的常用实现类。
Hashmap中put方法的源码如下:
public V put(K key, V value)
{
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 与需要放入的 key 相等(hash 值相同
// 通过 equals 比较放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引处的 Entry 为 null,表明此处还没有 Entry
modCount++;
// 将 key、value 添加到 i 索引处
addEntry(hash, key, value, i);
return null;
}
上面程序中用到了一个重要的内部接口:Map.Entry,每个 Map.Entry 其实就是一个 key-value 对。从上面程序中可以看出:当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置。这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
所以,若Hashmap在插入key时,
HashMap会先用key的hash值来检查是否发生了hash碰撞,也就是对应的位置是否为空。如果原本已经存在对应的key,则直接改变对应的value,并返回旧的value,而在判断key是否存在的时候是先比较key的hashCode,再比较相等或equals的。
Hashmap的构造
HashMap 包含如下几个构造器:
* HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
* HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
* HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
对于 HashMap 及其子类而言,它们采用 Hash 算法来决定集合中元素的存储位置。当系统开始初始化 HashMap 时,系统会创建一个长度为 capacity 的 Entry 数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket 都有其指定索引,系统可以根据其索引快速访问该 bucket 里存储的元素。
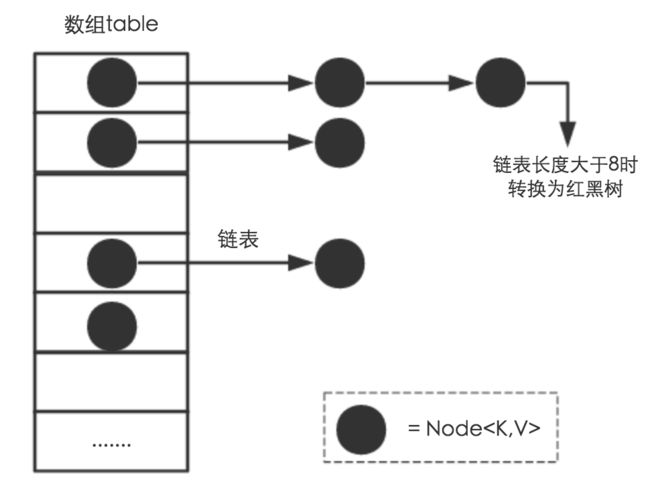
无论何时,HashMap 的每个“桶”只存储一个元素(也就是一个 Entry),由于 Entry 对象可以包含一个引用变量(就是 Entry 构造器的的最后一个参数)用于指向下一个 Entry,因此可能出现的情况是:HashMap 的 bucket 中只有一个 Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。如图 1 所示:
Hashmap的读取
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时,此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。看 HashMap 类的 get(K key) 方法代码:
public V get(Object key)
{
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry e = table[indexFor(hash, table.length)];
e != null;
// 搜索该 Entry 链的下一个 Entr
e = e.next) // ①
{
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}
从上面代码中可以看出,如果 HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
由此,我们可以在创建 HashMap 时根据实际需要适当地调整 load factor 的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子。
Hashmap的遍历
public class HashMapDemo {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
hashMap.put("cn", "中国");
hashMap.put("jp", "日本");
hashMap.put("fr", "法国");
System.out.println(hashMap);
System.out.println("cn:" + hashMap.get("cn"));
System.out.println(hashMap.containsKey("cn"));
System.out.println(hashMap.keySet());
System.out.println(hashMap.isEmpty());
hashMap.remove("cn");
System.out.println(hashMap.containsKey("cn"));
//采用Iterator遍历HashMap
Iterator it = hashMap.keySet().iterator();
while(it.hasNext()) {
String key = (String)it.next();
System.out.println("key:" + key);
System.out.println("value:" + hashMap.get(key));
}
//遍历HashMap的另一个方法
Set> sets = hashMap.entrySet();
for(Entry entry : sets) {
System.out.print(entry.getKey() + ", ");
System.out.println(entry.getValue());
}
}
}
Maphash中的一些方法
Maphash.keySet获得map的键集合
Maphash中的红黑树(待)
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。
练习
leetcode no.599
使用哈希索引找最小索引
public class no599 {
public static String[] findRestaurant(String[] list1, String[] list2) {
List buffer = null;
Map map1 = new HashMap<>();
Map map2 = new HashMap<>();
int min = Integer.MAX_VALUE;
for(int i = 0; i < list1.length; i++){
map1.put(list1[i], i);
}
for (int i = 0; i < list2.length; i++){
map2.put(list2[i], i);
}
for (int i = 0; i < list1.length; i++){
if(map2.containsKey(list1[i])){
int sum = map1.get(list1[i]) + map2.get(list1[i]);
if(sum < min){
min = sum;
buffer = new ArrayList();
buffer.add(list1[i]);
}
else if(sum == min)
buffer.add(list1[i]);
}
}
return buffer.toArray(new String[buffer.size()]);
}
public static void main(String[] args){
String[] a = {"Shogun", "Tapioca Express", "Burger King", "KFC"};
String[] b = {"KFC", "Shogun", "Burger King"};
System.out.println(Arrays.toString(findRestaurant(a, b)));
}
}
no.594
public class no594 {
public static int findLHS(int[] nums) {
Map map = new HashMap<>();
for (int i = 0; i < nums.length; i++){
// if(!map.containsKey(nums[i]))
// map.put(nums[i], 1);
// else {
int value = map.getOrDefault(nums[i], 0);
value++;
map.put(nums[i], value);
}
int length = 0;
for (int num: map.keySet()){
if(map.containsKey(num + 1))
length = Math.max(length, map.get(num) + map.get(num + 1));
}
return length;
}
public static void main(String[] args){
int[] nums = {1,3,2,2,5,2,3,7};
System.out.println(findLHS(nums));
}
}
http://www.cnblogs.com/chenssy/p/3521565.html
HashSet和HashMap的区别
- HashMap实现了Map接口 HashSet实现了Set接口
- HashMap储存键值对 HashSet仅仅存储对象
- 使用put()方法将元素放入map中 使用add()方法将元素放入set中
- HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false
- HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢