Hadoop学习笔记(二):从map到reduce的数据流
一个MapReduce作业是一个用户希望被执行的工作单元:它包括输入数据,MapReduce程序和配置信息。Hadoop通过把作业分成任务(tasks,分为map tasks 和reduce tasks两种)的形式来运行该作业。
有两种节点用来控制每个作业的执行: jobtracker通过把tasks分发到各个tasktrackers来运行,并协调系统上运行的所有作业。tasktrackers运行任务,并向jobtracker报告进度信息,jobtracker保持了每个作业的全局进度。如果一个任务失败了,jobtracker会把这个任务重新分发到另一个tasktracker上(也就是说,jobtracker不仅负责全局的作业调度,还要负责所有作业的所有task的维护,负担比较大,所以因为这个问题而产生了MapReduce2--YARN,这个后面会做详细介绍)。
Hadoop把一个MapReduce作业的输入分成固定大小的分片,叫做input splits,也叫splits。Hadoop为每个split创建一个map任务。这样可以很好地利用Hadoop的并发处理特性,如果一个节点的处理速度比较快,我们可以给它分配更多的splits。但split并不是越多越好,因为如果splits太小的话,管理splits和创建map task的额外开销会在作业的执行时间中占很大比例,对于大多数作业来说,一个好的splits大小默认为HDFS的block大小,也就是64MB(这个值可以在集群层面上改变,这样会影响到以后所有新创建的文件;也可以为以后每个新创建的文件设置一个特定的重载的值)。
如果map task运行的节点上刚好有输入数据的冗余备份(replica),此时Hadoop可以发挥出它的最大性能(因为不需要额外的数据传输从而节省了时间),这叫做data locality optimization(数据本地最优化)。然而有时情况并不是如此理想,因为有可能存放replica的节点此时都在满负荷运行着其他tasks,那么这个task就要被分发到其他节点上运行了,然后再从存放replica的最近的节点上取replica。总的来说,有以下三种情况:
Data-local (a), rack-local (b), and off-rack (c) map tasks
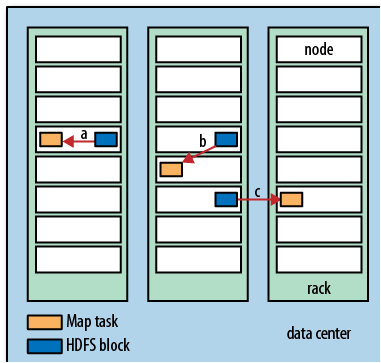
这是我们应该很清楚为什么splits的大小应刚好等于block的大小了吧,因为这是HDFS能保证的存放在一个节点上的最大数据量,如果splits的大小超过了block的大小,他就会占用两个block,这两个block又同时保存在一个节点上的概率是很小的,这样就不可避免的要进行网络传输了,从而增加了执行时间。
Map tasks把他们的输出数据写到本地文件系统,而不是HDFS上,这么做的原因是大多数Map任务的输出都是中间数据:它接着会被reduce任务处理以产生最终输出,而且一旦作业成功完成,这些中间数据就被删除了,如果把他们存放到HDFS上的话会造成很大的额外开销。如果运行map task的节点在reduce task取走map任务输出的中间数据之前当机了(相应的,中间数据也就丢失了),Hadoop会在另一个节点上自动的重启这个map task以重新生成这些中间数据。
Reduce masks并没有数据本地化的优势,因为单个reduce task的输入数据通常是来自所有mapper的输出的。因此,经排序的map输出必须经由网络传送给reducer。reduce的输出为了可靠性一般会存放到HDFS上去(第一个replica存放在本地节点上,其他两个存放到与本地节点不同的机架上去)。
只有一个reduce task 的数据流如下所示(虚线箭头表示本地数据流向,实线箭头表示集群间数据流向):
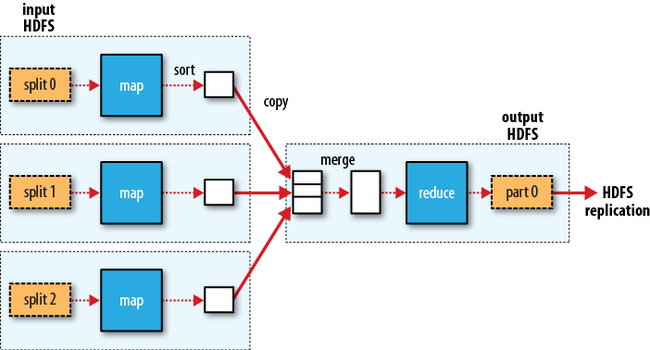
reduce task是的个数并不是由输入数据的大小决定的,而是由用户独立设定的。当有很多reducer时,map tasks会把他们的输出数据分区(partition),为每一个reducer创建一个分区(partition)。一个分区内可能有多个keys(以及与他们相连的values),但是每个给定的key所对应的的记录(records)都保存在一个分区中。分区时使用的分区方法可以由用户指定,但通常情况下,会使用一个默认的分区器(partitionor),它使用hash函数来对记录进行分区。拥有多个reduce 的数据流表示如下:
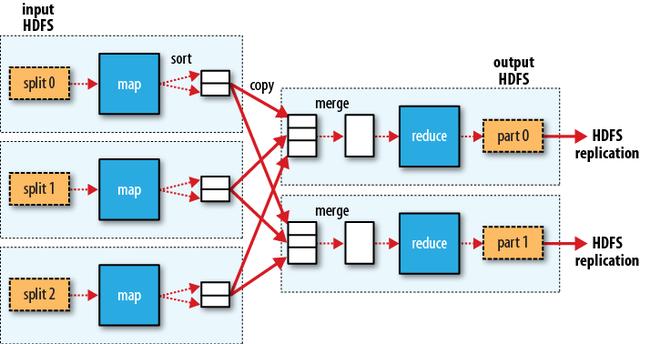
从上图中我们也可以看出,为什么从map到reduce的数据流会被称为shuffle(有“洗牌,混乱”的意思),因为每个reduce的输入都是由很多map的输出。shuffle阶段远比上图演示的要复杂,此阶段如果调优做的好的话,会对作业的执行时间有很大影响,具体细节以后再做讨论。
转载请注明出处:http://www.cnblogs.com/beanmoon/archive/2012/12/06/2805636.html