今天我们讲GAN,GAN是什么?GAN就是Generative Adversarial Networks,也就是生成对抗网络。这是近两年特别火的一个学术方向,发出了大量优秀的论文,简直是百花齐放。效果都挺好,但是其原理却又很简单,所以我们今天就不用一个公式,来介绍一下GAN。内容大致分为:
- GAN是什么?
- cycleGAN是什么?
- GAN的其他变体
首先说GAN是什么,开头说了,GAN就是生成对抗网络,那什么是生成对抗网络?我们平时在训练深度学习模型的时候,往往需要给训练出的网络模型做一个评价,并由此判断模型效果,那如果我们模型的输出结果是一张图片,应该如何让机器给结果打分呢?毕竟图像的质量是一个主观性的东西,图像是否表现出你要的内容,是否细致清晰,需要你主管判断。GAN选择的做法是:同时再训练一个网络来给生成的图片结果打分(评价)。
我们看一个最简单的GAN结构图:
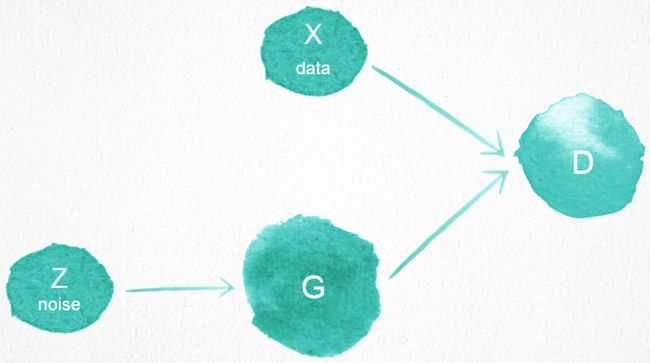
图中最左边的Z就是我们的输入,它是一个随机噪声,目的在于生成一张符合我们要求的随机图片,比如一张随机特征的人脸、猫等。G就是一个生成器(Generator),它是一个需要训练的神经网络,输入的随机噪声,通过G来转化成一张图片。随着训练,我们希望生成的图片效果越来越好。D是一个鉴别器(Discriminator),它就是上文说的要训练的另一个网络,用来评价G生成的图片效果好不好,怎么评价呢?我们从数据集X中,随机取出一张图片让D判断它和G生成的图片哪一张才是真实的图片,哪一张又是生成的假图片。
X中就是我们希望训练出的模型能够生成的目标类型图片集,比如都是各种人脸图片,那么训练过程中D就会不断判断G生成的图片和真实人脸图片谁才是真的,刚开始G生成的图片比较不知所云,所以可以判断,慢慢地G会随着D的反馈越来越优秀,生成的图片越来越像人脸,从而能以假乱真,影响D的判断,而D也在不断地成长,越来越火眼金睛,从而能识别出G的图片是假的,由于做对比的是各种人脸图片呢,所以G为了骗过D,也会生成类似的人脸,掌握人脸的特征,在这种不断的互相较量、训练中,G就会变得越来越能生成真实的人脸图像了。
因为在训练过程中G和D一直在互相较量、对抗,而我们的目的又是得到一个图片生成器,因此整个结构就称为:生成对抗网络。
步骤简单描述如下,每个batch轮流训练G和D:
- 从X中拿出一张真图片
- 令G根据随机噪声Z生成一张假图片
- 让D判断上述两张照片谁真谁假
- 回馈G令其生成更逼真图片
上面我们用的输入是随机噪声,目的是为了生成随机的一张图片,但如果完全随机,是不负责任的,因为结果不可控,你不知道生成的图像有什么特征,只能保证是要训练出的图片类型。那能不能将输入改成一张图片,来达到一种图片风格转换的目的呢?
什么叫做图片风格转换呢?比如我现在想要一个工具,可以把所以的风景照片转换成素描画,这就是一种风格转换。如果输入是噪声,那就是单纯的图像生成,而不是转换,但更常见的应用可能是转换风格,所以我们能不能把输入改成图片呢?肯定可以。
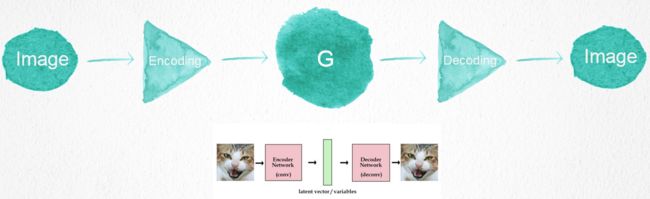
我们只需要在原有的结构上做一点点修改。首先是输入的图片,在输入到G之前,加一个编码器,把图片编码成一种向量,再输入到生成器G,生成器在高维空间进行转换之后,再解码成图片,送给鉴别器D去做判断。比如我们要把猫图片输入,这里例子中的猫没有变,我们可以将其转换成另一种猫,或者是一只狗,在转换的过程中你既可以转换出狗的特征,又可以保持原本猫的一些特点,比如毛色不变等等。
这里就要引出我们的cycleGAN——循环生成对抗网络。我们先看一些图片风格转换的例子:
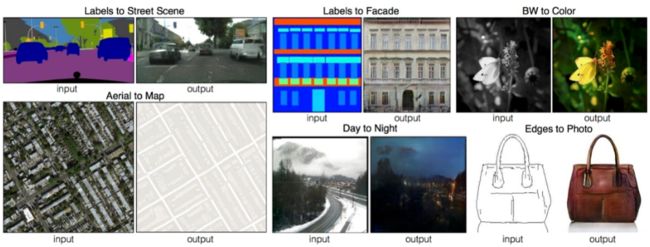
这些图中,有的是将画转化为真实街景图;将真实卫星图转换为地图App中的街道;将白天的风景转换为晚上。将黑白色转换为彩色;将简笔画转换成实物等等。这些都可以做到,是一篇论文的结果,叫做pix2pix,也比较有名。

使用pix2pix,只要你能提供成对的简笔画和实物的训练集,就可以训练处能将任意简笔画转换成实物的模型。当然,也可能得到一些奇奇怪怪的结果:

pix2pix要求有成对的训练集,什么叫成对的训练集呢?它要训练简笔画到实物的模型,在一开始就必须要提供一些成对的简笔画到实物的对应关系以供参考,如下左边所示:
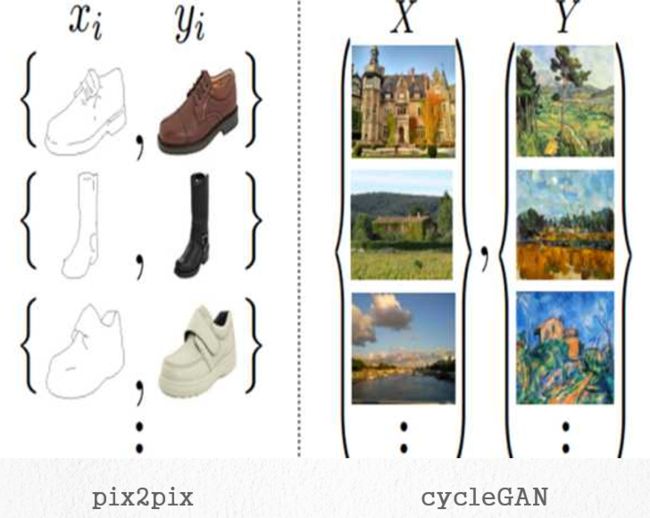
这是pix2pix的一个缺点,因为很多时候,我们没办法找到那么多对应的,比如你想要训练冬天风景到夏天风景的转换,那你很难到各个地方的冬夏两种一致的风景来做训练集,如果能够单独的找一组冬天的照片和找一组夏天的照片,它们可能来自于不同的地方,但是我想要的结果就是把冬天的风景转换成夏天的风景。就好比上左图,想把照片转换成油画,我无法找到每张油画原本的风景,尤其是莫奈、梵高等人的画,我只能提供一组画,和一组风景。而这就是cycleGAN的一个改进,它和pix2pix其实是同一个作者做的东西。
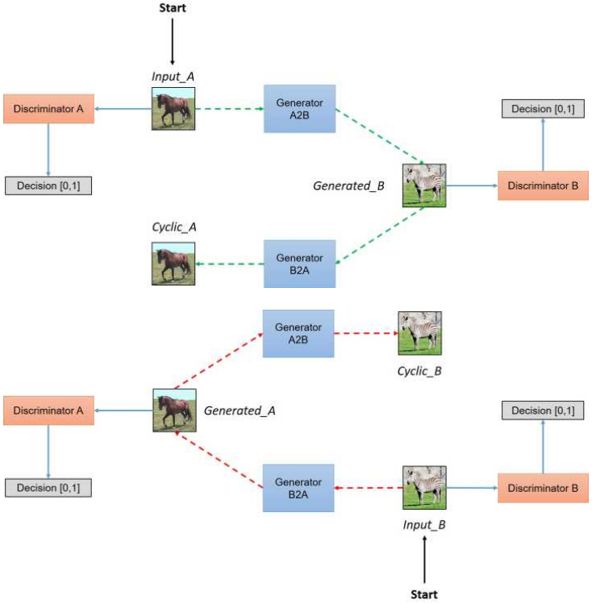
现在本文最绕的部分来了,上图就是cycleGAN的结构,还记不记得GAN的结构,有生成器G、鉴别器D、训练集X和输入噪声Z。cycleGAN也是基于GAN的,说白了就是两个GAN结构串联起来。
前面说了我们的输入可以改成图片,这里我们的目的是把一匹马转换成一批斑马,现在输入一张马的图片到生成器,结果给到鉴别器,鉴别器从真实的斑马数据集中取照片,和生成的斑马做比较判断,这是第一个GAN结构。
另一个GAN结构,输入一个斑马图片到另一个生成器(这个生成器的训练目的是把斑马转化成马),生成的结果马图片输入到另一个鉴别器,该鉴别器从真实的马数据集中取照片,和生成的马做比较判断。
同时,为了防止模型坍塌,也就是防止生成器为了骗过鉴别器,将所有输入的图片都生成同一张最以假乱真的图片,这就失去了意义,因为没有保持原图片的特征。为了防止这种现象,cycleGAN要求从一匹马转化为一匹斑马后,该生成出的斑马通过“斑马到马”的生成器,还能转换回原本的马,有这种限制后,就能强制生成器保留原图的一些特征。这也是cycleGAN中,cycle(循环)一词的真正意义所在。
下面我们看一些使用cycleGAN做转换的例子,开发脑洞:







等等。。。
cycleGAN最好的一点在于,只要你有两种数据集,他们有类似的地方,比如都是人,就可以直接丢到网络中去,不需要数据集之间是成对匹配的,比如你不需要有同一个人的男妆和女妆照片,就可以做到男女互换,还保持他原本的脸部特征。
下面再看看一些GAN的其他变种的应用。
比如CGAN,也就是条件性GAN,你可以要求生成的图像中某个物体在哪个位置:
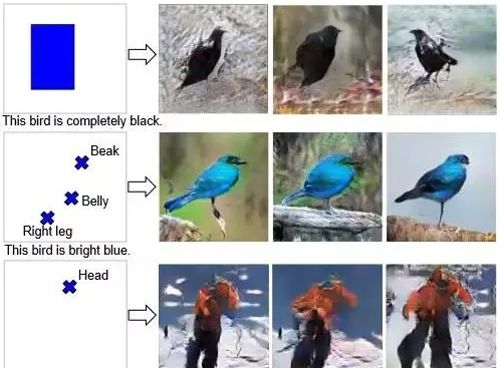
也可以要求生成某个年龄的人脸:

GAN也可以用来给漫画上色,比如基于CGAN的DeepColor:

还可以用来要求生成具有某些特征的动漫造型,日本一个小哥哥就做了一个AnimeGAN,基于DCGAN(深度卷积GAN),你可以要求发色、发型、眼镜等等条件,模型能够“创造”出各种动漫造型:
GAN也不是只能用于图像,还可以做到文字和图像之间的转换:

甚至能用来提升图片质量(SRGAN):

不过要训练GAN,最好有强大的显卡,毕竟NVIDIA这样的显卡公司为了训练出一个高清人脸生成器都训练了15天之久:

总之,GAN的用途千变万化,原理简单,却极为有效,但其实也存在着训练过程无法直接判断结束的缺点,毕竟训练中两个网络一直在对抗升级,但没有指标来衡量结果的好坏,你可能还是得自己看生成效果如何,这也是一个挺遗憾的点了。
查看作者首页