蒙特卡洛树搜索(Monte Carlo tree search;简称:MCTS)是一种用于某些决策过程的启发式搜索算法,最引人注目的是在游戏中的使用。一个主要例子是计算机围棋程序,它也用于其他棋盘游戏、即时电子游戏以及不确定性游戏。
决策函数
比如围棋,棋手需要针对盘面的情况,选择下一步走哪个位置。这个决策过程可以认为是一个决策函数
a = f(s),即面对可能的状态s,决策函数f 会提供一个行动a(落子位置)。当然,我们希望 f 尽可能优秀,其决策a能够尽可能赢棋。
决策树
我们也可以将f构造为一颗决策树。从盘面初始状态开始(没有棋子),令初始状态为根节点,第一手棋有19*19=361个位置,因此根节点下面有361个子节点,第二手棋有360个可能的位置,即361个节点下,每个节点又有360个子节点......随着双方的落子,树的分枝越来越多,每个分支最终会进入叶子状态(对局结束,黑胜或白胜)。理论上可以列举所有可能的情况,做一棵完整的决策树,但实际上这个数据量大到不可能实现。因此,我们必须在有限的时间和空间之内,高效的构建一个子树,这是一个不完整但尽量好的决策树。
启发
即便只是尽量好的决策,也是很困难的。因为一步棋的好坏通常不能立即判断出来,最终的评判要到下完的时候才能决定谁赢,况且即便赢了棋,也不代表其中每一步都是好的。
但是,无论怎样,必须提供某种方法让AI知道一步棋好不好,也就是要提供一些 启发,于是我们可以采用蒙特卡洛树搜索方法。
蒙特卡洛方法
刚才我们说到下一盘棋不能判定其中走法的好坏,但如果下很多次呢?比如在某个特定盘面s1情况下,进行n次对局(接着s1盘面往后走),如果统计下来黑棋赢得多,说明s1情况对黑棋比较有利。这就是蒙特卡洛方法的思想,用大量随机事件逼近真实情况。
蒙特卡洛树搜索
虽然通过蒙特卡罗方法可以近似估计一个状态的好坏,但我们依然无法对太多状态进行估算。因此,我们需要有选择的集中力量对决策树中的可能更有价值的那些节点进行估算。这就需要使用蒙特卡洛树搜索,它提供了一种选择机制,使我们能够尽量选择决策树中比较有潜力的节点进行蒙特卡洛模拟,从而使得树可以尽量集中在“较好”的策略上进行“生长”。
蒙特卡洛树搜索有四个主要步骤:
1)选择(Selection)
从根节点R开始,选择连续的子节点向下至叶子节点L。让决策树向最优的方向扩展,这是蒙特卡洛树搜索的精要所在。也就是要选择一个尽量”有潜力“的树节点,那么怎样的节点是有潜力呢?一个是胜率高,另一个是被考察的次数少。
胜率高的节点(状态)意味着最后赢棋的概率较大,当然应该多花些精力分析其后续走法。被考察次数少的节点意味着该节点(状态)尚未经过充分研究,有成为黑马的可能。
| . | 胜率高 | 胜率低 |
|---|---|---|
| 考察多 | 次优先 | 希望不大 |
| 考察少 | 优先 | 次优先 |
具体来说,通常用UCB1(Upper Confidence Bound,上置信区间)公式来计算一个节点的”潜力“:
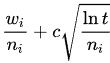
wi:第 i 次移动后取胜的次数
ni:第 i 次移动后仿真的次数
c:探索参数/权衡参数,理论上等于 根号2,在实际中通常可凭经验选择
t:仿真总次数,等于所有 ni 的和
看一个例子(参考 28 天自制你的 AlphaGo(五))

上图中每个节点代表一个局面。而 A/B 代表这个节点被访问 B 次,黑棋胜利了 A 次。例如一开始的根节点是 12/21,代表总共模拟了 21 次,黑棋胜利了 12 次。
图中展示了蒙特卡洛树搜索的四个步骤,我们先看左边第一个树(Selection)。假设根节点是轮到黑棋走。那么我们首先需要在 7/10、5/8、0/3 之间选择,采用上面的UCB1公式:

假设 C 比较小(比如C=1),上述3个分数为 1.25 1.245 1,于是我们选择 7/10 节点(它得分1.25是最高的)。然后接下来 7/10 下面的 2/4 和 5/6 之间选择。注意,由于现在是白棋走,需要把胜率估计倒过来。即图上黑棋胜率是 2/4 和 5/6,则白棋胜率是 (1 - 2/4) 和 (1 - 5/6):

那么白棋应该选 2/4 节点。(图中扩展的是 5/6 节点,这不是很合理)。
2. 扩展(Expansion)
在所选的叶子节点L,如果已经能判定输赢,则该轮游戏结束,否则创建一个或多个子节点并选取其中一个节点C。
看上图第2个树(Expansion),假设黑棋选择了(当前的)叶子节点 3/3,然后创建了一个子节点,初始状态 0/0。
3. 仿真(Simulation)
从节点C开始,用随机策略进行游戏,直到分出输赢(获得一次准确的回报)。这一步骤又称为playout或者rollout。
虽然原则上蒙特卡洛方法是采用随机策略,不过实际中也可以采用一些“有经验”的策略,或者两者的结合。所谓有经验的策略就像一个有一定水平的棋手,ta 可以下出一些比较好的走法。我们可以在仿真的某个阶段采用棋手的走法,另外一些阶段采用随机走法。
不过总的来说,仿真需要很快速的完成,这样才能得到尽量多的仿真结果,使统计结果逼近真实的胜率。
看上图第3个树(Simulation),黑棋从 0/0 节点开始进行模拟游戏直到终局,假设黑棋输,所以得分是 0/1。
4. 反向传播(Backpropagation)
使用随机游戏的结果,更新从C到R的路径上的节点信息。
看上图第4个树(Backpropagation),从 0/0 节点开始遍历父节点,直到根节点R,这条路径上的每个节点都添加一个 0/1。
使用蒙特卡洛树做决策
当构建了一棵蒙特卡洛树以后,需要用它来做决策时,应该选择访问量最大的节点,而不是胜率最高的节点,也不是UCB分数最高的节点。
访问量不够大的节点,即使胜率高,也不够可靠(因为模拟次数不够多)。而访问量最大的节点,通常也有一定的胜率,想想UCB公式,如果胜率不高是不会经常被选中的(访问量不会大)。所以采用访问量最大的节点,AI的表现会更加稳定。
AlphaGO
对于围棋AI,仅使用蒙特卡洛树搜索是不够的,尤其是 AlphaGO 这样的顶级AI,更多分析请参考:
左右互搏,青出于蓝而胜于蓝?阿尔法狗原理解析
参考
28 天自制你的 AlphaGo(五)
AlphaGo背后的力量:蒙特卡洛树搜索入门指南
蒙特卡洛树搜索(MCTS)算法
维基百科——蒙特卡洛树搜索
维基百科——蒙特卡罗方法