Redis分布式锁(图解 - 秒懂 - 史上最全)
文章很长,建议收藏起来,慢慢读! 高并发 发烧友社群:疯狂创客圈 为小伙伴奉上以下珍贵的学习资源:
-
疯狂创客圈 经典升级 : 极致经典 《 Java 高并发 三部曲 》 面试必备 + 大厂必备 + 涨薪必备
-
疯狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 免费领
-
疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 面试必备 + 大厂必备 + 涨薪必备 免费领
-
疯狂创客圈 资源宝库: Java 必备 百度网盘资源大合集 价值>1000元 【免费取 】
推荐: 疯狂创客圈 必看/必收/高质量/博文
| 史上最全 分布式锁 2 大篇 | 图解 + 史上最全 + 吐血推荐 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 史上最全 Java 面试题 21 个专题 | 阿里、京东、美团、头条… 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| 分布式 高并发 必读 的精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| Zookeeper 分布式锁 (图解+秒懂+史上最全) | Webflux(史上最全) |
| SpringCloud gateway (史上最全) | TCP/IP(图解+秒懂+史上最全) |
| 10分钟看懂, Java NIO 底层原理 | Feign原理 (图解) |
| 大厂必备之:Reactor模式 | 更多精彩博文 … 请参见【 疯狂创客圈 高并发 总目录 】 |
跨JVM的线程安全问题
在单体的应用开发场景中,在多线程的环境下,涉及并发同步的时候,为了保证一个代码块在同一时间只能由一个线程访问,我们一般可以使用synchronized语法和ReetrantLock去保证,这实际上是本地锁的方式。
也就是说,在同一个JVM内部,大家往往采用synchronized或者Lock的方式来解决多线程间的安全问题。但在分布式集群工作的开发场景中,在JVM之间,那么就需要一种更加高级的锁机制,来处理种跨JVM进程之间的线程安全问题.
解决方案是:使用分布式锁
总之,对于分布式场景,我们可以使用分布式锁,它是控制分布式系统之间互斥访问共享资源的一种方式。
比如说在一个分布式系统中,多台机器上部署了多个服务,当客户端一个用户发起一个数据插入请求时,如果没有分布式锁机制保证,那么那多台机器上的多个服务可能进行并发插入操作,导致数据重复插入,对于某些不允许有多余数据的业务来说,这就会造成问题。而分布式锁机制就是为了解决类似这类问题,保证多个服务之间互斥的访问共享资源,如果一个服务抢占了分布式锁,其他服务没获取到锁,就不进行后续操作。
大致意思如下图所示(不一定准确):
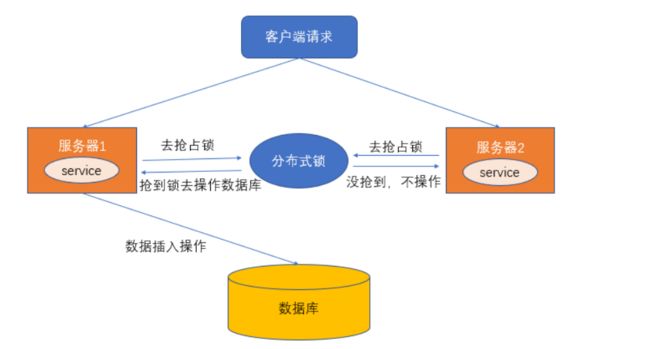
何为分布式锁?
何为分布式锁?
- 当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
分布式锁的条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的 Redis 节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
分布式锁的实现:
分布式锁的实现由很多种,文件锁、数据库、redis等等,比较多;分布式锁常见的多种实现方式:
- 数据库悲观锁、
- 数据库乐观锁;
- 基于Redis的分布式锁;
- 基于ZooKeeper的分布式锁。
在实践中,还是redis做分布式锁性能会高一些
数据库悲观锁
所谓悲观锁,悲观锁是对数据被的修改持悲观态度(认为数据在被修改的时候一定会存在并发问题),因此在整个数据处理过程中将数据锁定。
悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在应用层中实现了加锁机制,也无法保证外部系统不会修改数据)。
数据库的行锁、表锁、排他锁等都是悲观锁,这里以行锁为例,进行介绍。以我们常用的MySQL为例,我们通过使用select…for update语句, 执行该语句后,会在表上加持行锁,一直到事务提交,解除行锁。
使用场景举例:
在秒杀案例中,生成订单和扣减库存的操作,可以通过商品记录的行锁,进行保护。们通过使用select…for update语句,在查询商品表库存时将该条记录加锁,待下单减库存完成后,再释放锁。
示例的SQL如下:
//0.开始事务
begin;
//1.查询出商品信息
select stockCount from seckill_good where id=1 for update;
//2.根据商品信息生成订单
insert into seckill_order (id,good_id) values (null,1);
//3.修改商品stockCount减一
update seckill_good set stockCount=stockCount-1 where id=1;
//4.提交事务
commit;
以上,在对id = 1的记录修改前,先通过for update的方式进行加锁,然后再进行修改。这就是比较典型的悲观锁策略。
如果以上修改库存的代码发生并发,同一时间只有一个线程可以开启事务并获得id=1的锁,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
我们使用select_for_update,另外一定要写在事务中.
注意:要使用悲观锁,我们必须关闭mysql数据库中自动提交的属性,命令set autocommit=0;即可关闭,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
- 在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 其间如果有其他事务对该记录做加锁的操作,都要等待当前事务解锁或直接抛出异常。
数据库乐观锁
使用乐观锁就不需要借助数据库的锁机制了。
乐观锁的概念中其实已经阐述了他的具体实现细节:主要就是两个步骤:冲突检测和数据更新。其实现方式有一种比较典型的就是Compare and Swap(CAS)技术。
CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
CAS的实现中,在表中增加一个version字段,操作前先查询version信息,在数据提交时检查version字段是否被修改,如果没有被修改则进行提交,否则认为是过期数据。
比如前面的扣减库存问题,通过乐观锁可以实现如下:
//1.查询出商品信息
select stockCount, version from seckill_good where id=1;
//2.根据商品信息生成订单
insert into seckill_order (id,good_id) values (null,1);
//3.修改商品库存
update seckill_good set stockCount=stockCount-1, version = version+1 where id=1, version=version;
以上,我们在更新之前,先查询一下库存表中当前版本(version),然后在做update的时候,以version 作为一个修改条件。
当我们提交更新的时候,判断数据库表对应记录的当前version与第一次取出来的version进行比对,如果数据库表当前version与第一次取出来的version相等,则予以更新,否则认为是过期数据。
CAS 乐观锁有两个问题:
(1) CAS 存在一个比较重要的问题,即ABA问题. 解决的办法是version字段顺序递增。
(2) 乐观锁的方式,在高并发时,只有一个线程能执行成功,会造成大量的失败,这给用户的体验显然是很不好的。
Zookeeper分布式锁
除了在数据库层面加分布式锁,通常还可以使用以下更高性能、更高可用的分布式锁:
- 分布式缓存(如redis)锁
- 分布式协调(如zookeeper)锁
有关zookeeper分布式锁的原理和实现,具体请参见下面的博客:
Zookeeper 分布式锁 (图解+秒懂+史上最全)
或者阅读笔者的《Java高并发核心编程(卷1)》

Redis分布式锁
本文重点介绍Redis分布式锁,分为两个维度进行介绍:
(1)基于Jedis手工造轮子分布式锁
(2)介绍Redission 分布式锁的使用和原理。
分布式锁一般有如下的特点:
- 互斥性: 同一时刻只能有一个线程持有锁
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
手工造轮子:基于Jedis 的API实现分布式锁
我们首先讲解 Jedis 普通分布式锁实现,并且是纯手工的模式,从最为基础的Redis命令开始。
只有充分了解与分布式锁相关的普通Redis命令,才能更好的了解高级的Redis分布式锁的实现,因为高级的分布式锁的实现完全基于普通Redis命令。
Redis几种架构
Redis发展到现在,几种常见的部署架构有:
- 单机模式;
- 主从模式;
- 哨兵模式;
- 集群模式;
从分布式锁的角度来说, 无论是单机模式、主从模式、哨兵模式、集群模式,其原理都是类同的。 只是主从模式、哨兵模式、集群模式的更加的高可用、或者更加高并发。
所以,接下来先基于单机模式,基于Jedis手工造轮子实现自己的分布式锁。
首先看两个命令:
Redis分布式锁机制,主要借助setnx和expire两个命令完成。
setnx命令:
SETNX 是SET if Not eXists的简写。将 key 的值设为 value,当且仅当 key 不存在; 若给定的 key 已经存在,则 SETNX 不做任何动作。
下面为客户端使用示例:
127.0.0.1:6379> set lock "unlock"
OK
127.0.0.1:6379> setnx lock "unlock"
(integer) 0
127.0.0.1:6379> setnx lock "lock"
(integer) 0
127.0.0.1:6379>
expire命令:
expire命令为 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除. 其格式为:
EXPIRE key seconds
下面为客户端使用示例:
127.0.0.1:6379> expire lock 10
(integer) 1
127.0.0.1:6379> ttl lock
8
基于Jedis API的分布式锁的总体流程:
通过Redis的setnx、expire命令可以实现简单的锁机制:
- key不存在时创建,并设置value和过期时间,返回值为1;成功获取到锁;
- 如key存在时直接返回0,抢锁失败;
- 持有锁的线程释放锁时,手动删除key; 或者过期时间到,key自动删除,锁释放。
线程调用setnx方法成功返回1认为加锁成功,其他线程要等到当前线程业务操作完成释放锁后,才能再次调用setnx加锁成功。

以上简单redis分布式锁的问题:
如果出现了这么一个问题:如果setnx是成功的,但是expire设置失败,一旦出现了释放锁失败,或者没有手工释放,那么这个锁永远被占用,其他线程永远也抢不到锁。
所以,需要保障setnx和expire两个操作的原子性,要么全部执行,要么全部不执行,二者不能分开。
解决的办法有两种:
- 使用set的命令时,同时设置过期时间,不再单独使用 expire命令
- 使用lua脚本,将加锁的命令放在lua脚本中原子性的执行
简单加锁:使用set的命令时,同时设置过期时间
使用set的命令时,同时设置过期时间的示例如下:
127.0.0.1:6379> set unlock "234" EX 100 NX
(nil)
127.0.0.1:6379>
127.0.0.1:6379> set test "111" EX 100 NX
OK
这样就完美的解决了分布式锁的原子性; set 命令的完整格式:
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置失效时长,单位秒
PX milliseconds:设置失效时长,单位毫秒
NX:key不存在时设置value,成功返回OK,失败返回(nil)
XX:key存在时设置value,成功返回OK,失败返回(nil)
使用set命令实现加锁操作,先展示加锁的简单代码实习,再带大家慢慢解释为什么这样实现。
加锁的简单代码实现
package com.crazymaker.springcloud.standard.lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisCommandLock {
private RedisTemplate redisTemplate;
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
可以看到,我们加锁用到了Jedis的set Api:
jedis.set(String key, String value, String nxxx, String expx, int time)
这个set()方法一共有五个形参:
-
第一个为key,我们使用key来当锁,因为key是唯一的。
-
第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?原因就是我们在上面讲到可靠性时,分布式锁要满足第四个条件解铃还须系铃人,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。
requestId可以使用
UUID.randomUUID().toString()方法生成。 -
第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
-
第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
-
第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:
- 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。
- 已有锁存在,不做任何操作。
心细的童鞋就会发现了,我们的加锁代码满足前面描述的四个条件中的三个。
-
首先,set()加入了NX参数,可以保证如果已有key存在,则函数不会调用成功,也就是只有一个客户端能持有锁,满足互斥性。
-
其次,由于我们对锁设置了过期时间,即使锁的持有者后续发生崩溃而没有解锁,锁也会因为到了过期时间而自动解锁(即key被删除),不会被永远占用(而发生死锁)。
-
最后,因为我们将value赋值为requestId,代表加锁的客户端请求标识,那么在客户端在解锁的时候就可以进行校验是否是同一个客户端。
-
由于我们只考虑Redis单机部署的场景,所以容错性我们暂不考虑。
基于Jedis 的API实现简单解锁代码
还是先展示代码,再带大家慢慢解释为什么这样实现。
解锁的简单代码实现:
package com.crazymaker.springcloud.standard.lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisCommandLock {
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
那么这段Lua代码的功能是什么呢?
其实很简单,首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁(解锁)。
第一行代码,我们写了一个简单的Lua脚本代码。
第二行代码,我们将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。eval()方法是将Lua代码交给Redis服务端执行。
那么为什么要使用Lua语言来实现呢?
因为要确保上述操作是原子性的。那么为什么执行eval()方法可以确保原子性,源于Redis的特性.
简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命
错误示例1
最常见的解锁代码就是直接使用 jedis.del() 方法删除锁,这种不先判断锁的拥有者而直接解锁的方式,会导致任何客户端都可以随时进行解锁,即使这把锁不是它的。
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {
jedis.del(lockKey);
}
错误示例2
这种解锁代码乍一看也是没问题,甚至我之前也差点这样实现,与正确姿势差不多,唯一区别的是分成两条命令去执行,代码如下:
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {
// 判断加锁与解锁是不是同一个客户端
if (requestId.equals(jedis.get(lockKey))) {
// 若在此时,这把锁突然不是这个客户端的,则会误解锁
jedis.del(lockKey);
}
}
再造轮子:基于Lua脚本实现分布式锁
lua脚本的好处
前面提到,在redis中执行lua脚本,有如下的好处:
那么为什么要使用Lua语言来实现呢?
因为要确保上述操作是原子性的。那么为什么执行eval()方法可以确保原子性,源于Redis的特性.
简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命
所以:
大部分的开源框架(如 redission)中的分布式锁组件,都是用纯lua脚本实现的。
题外话: lua脚本是高并发、高性能的必备脚本语言
有关lua的详细介绍,请参见以下书籍:

那么,我们也来模拟一下
基于纯Lua脚本的分布式锁的执行流程
加锁和删除锁的操作,使用纯lua进行封装,保障其执行时候的原子性。
基于纯Lua脚本实现分布式锁的执行流程,大致如下:

加锁的Lua脚本: lock.lua
--- -1 failed
--- 1 success
---
local key = KEYS[1]
local requestId = KEYS[2]
local ttl = tonumber(KEYS[3])
local result = redis.call('setnx', key, requestId)
if result == 1 then
--PEXPIRE:以毫秒的形式指定过期时间
redis.call('pexpire', key, ttl)
else
result = -1;
-- 如果value相同,则认为是同一个线程的请求,则认为重入锁
local value = redis.call('get', key)
if (value == requestId) then
result = 1;
redis.call('pexpire', key, ttl)
end
end
-- 如果获取锁成功,则返回 1
return result
解锁的Lua脚本: unlock.lua:
--- -1 failed
--- 1 success
-- unlock key
local key = KEYS[1]
local requestId = KEYS[2]
local value = redis.call('get', key)
if value == requestId then
redis.call('del', key);
return 1;
end
return -1
两个文件,放在资源文件夹下备用:
在Java中调用lua脚本,完成加锁操作
下一步,实现Lock接口, 完成JedisLock的分布式锁。
其加锁操作,通过调用 lock.lua脚本完成,代码如下:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.exception.BusinessException;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisLock implements Lock {
private RedisTemplate redisTemplate;
RedisScript lockScript = null;
RedisScript unLockScript = null;
public static final int DEFAULT_TIMEOUT = 2000;
public static final Long LOCKED = Long.valueOf(1);
public static final Long UNLOCKED = Long.valueOf(1);
public static final Long WAIT_GAT = Long.valueOf(200);
public static final int EXPIRE = 2000;
String key;
String lockValue; // lockValue 锁的value ,代表线程的uuid
/**
* 默认为2000ms
*/
long expire = 2000L;
public JedisLock(String lockKey, String lockValue) {
this.key = lockKey;
this.lockValue = lockValue;
}
private volatile boolean isLocked = false;
private Thread thread;
/**
* 获取一个分布式锁 , 超时则返回失败
*
* @return 获锁成功 - true | 获锁失败 - false
*/
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
//本地可重入
if (isLocked && thread == Thread.currentThread()) {
return true;
}
expire = unit != null ? unit.toMillis(time) : DEFAULT_TIMEOUT;
long startMillis = System.currentTimeMillis();
Long millisToWait = expire;
boolean localLocked = false;
int turn = 1;
while (!localLocked) {
localLocked = this.lockInner(expire);
if (!localLocked) {
millisToWait = millisToWait - (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if (millisToWait > 0L) {
/**
* 还没有超时
*/
ThreadUtil.sleepMilliSeconds(WAIT_GAT);
log.info("睡眠一下,重新开始,turn:{},剩余时间:{}", turn++, millisToWait);
} else {
log.info("抢锁超时");
return false;
}
} else {
isLocked = true;
localLocked = true;
}
}
return isLocked;
}
/**
* 有返回值的抢夺锁
*
* @param millisToWait
*/
public boolean lockInner(Long millisToWait) {
if (null == key) {
return false;
}
try {
List redisKeys = new ArrayList<>();
redisKeys.add(key);
redisKeys.add(lockValue);
redisKeys.add(String.valueOf(millisToWait));
Long res = (Long) redisTemplate.execute(lockScript, redisKeys);
return res != null && res.equals(LOCKED);
} catch (Exception e) {
e.printStackTrace();
throw BusinessException.builder().errMsg("抢锁失败").build();
}
}
}
在Java中调用lua脚本,完成解锁操作
其解锁操作,通过调用unlock.lua脚本完成,代码如下:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.exception.BusinessException;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisLock implements Lock {
private RedisTemplate redisTemplate;
RedisScript lockScript = null;
RedisScript unLockScript = null;
//释放锁
@Override
public void unlock() {
if (key == null || requestId == null) {
return;
}
try {
List redisKeys = new ArrayList<>();
redisKeys.add(key);
redisKeys.add(requestId);
Long res = (Long) redisTemplate.execute(unLockScript, redisKeys);
} catch (Exception e) {
e.printStackTrace();
throw BusinessException.builder().errMsg("释放锁失败").build();
}
}
}
编写RedisLockService用于管理JedisLock
编写个分布式锁服务,用于加载lua脚本,创建 分布式锁,代码如下:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.util.IOUtil;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
public class RedisLockService
{
private RedisTemplate redisTemplate;
static String lockLua = "script/lock.lua";
static String unLockLua = "script/unlock.lua";
static RedisScript lockScript = null;
static RedisScript unLockScript = null;
{
String script = IOUtil.loadJarFile(RedisLockService.class.getClassLoader(),lockLua);
// String script = FileUtil.readString(lockLua, Charset.forName("UTF-8" ));
if(StringUtils.isEmpty(script))
{
log.error("lua load failed:"+lockLua);
}
lockScript = new DefaultRedisScript<>(script, Long.class);
// script = FileUtil.readString(unLockLua, Charset.forName("UTF-8" ));
script = IOUtil.loadJarFile(RedisLockService.class.getClassLoader(),unLockLua);
if(StringUtils.isEmpty(script))
{
log.error("lua load failed:"+unLockLua);
}
unLockScript = new DefaultRedisScript<>(script, Long.class);
}
public RedisLockService(RedisTemplate redisTemplate)
{
this.redisTemplate = redisTemplate;
}
public Lock getLock(String lockKey, String lockValue) {
JedisLock lock=new JedisLock(lockKey,lockValue);
lock.setRedisTemplate(redisTemplate);
lock.setLockScript(lockScript);
lock.setUnLockScript(unLockScript);
return lock;
}
}
测试用例
接下来,终于可以上测试用例了
package com.crazymaker.springcloud.lock;
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {DemoCloudApplication.class})
// 指定启动类
public class RedisLockTest {
@Resource
RedisLockService redisLockService;
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLock() {
int threads = 10;
final int[] count = {0};
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
String lockValue = UUID.randomUUID().toString();
try {
Lock lock = redisLockService.getLock("test:lock:1", lockValue);
boolean locked = lock.tryLock(10, TimeUnit.SECONDS);
if (locked) {
for (int j = 0; j < 1000; j++) {
count[0]++;
}
log.info("count = " + count[0]);
lock.unlock();
} else {
System.out.println("抢锁失败");
}
} catch (Exception e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10个线程每个累加1000为: = " + count[0]);
//输出统计结果
float time = System.currentTimeMillis() - start;
System.out.println("运行的时长为(ms):" + time);
System.out.println("每一次执行的时长为(ms):" + time / count[0]);
}
}
执行用例,结果如下:
2021-05-04 23:02:11.900 INFO 22120 --- [pool-1-thread-7] c.c.springcloud.lock.RedisLockTest LN:50 count = 6000
2021-05-04 23:02:11.901 INFO 22120 --- [pool-1-thread-1] c.c.springcloud.standard.lock.JedisLock LN:81 睡眠一下,重新开始,turn:3,剩余时间:9585
2021-05-04 23:02:11.902 INFO 22120 --- [pool-1-thread-1] c.c.springcloud.lock.RedisLockTest LN:50 count = 7000
2021-05-04 23:02:12.100 INFO 22120 --- [pool-1-thread-4] c.c.springcloud.standard.lock.JedisLock LN:81 睡眠一下,重新开始,turn:3,剩余时间:9586
2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.standard.lock.JedisLock LN:81 睡眠一下,重新开始,turn:3,剩余时间:9585
2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-8] c.c.springcloud.standard.lock.JedisLock LN:81 睡眠一下,重新开始,turn:3,剩余时间:9585
2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-4] c.c.springcloud.lock.RedisLockTest LN:50 count = 8000
2021-05-04 23:02:12.102 INFO 22120 --- [pool-1-thread-8] c.c.springcloud.lock.RedisLockTest LN:50 count = 9000
2021-05-04 23:02:12.304 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.standard.lock.JedisLock LN:81 睡眠一下,重新开始,turn:4,剩余时间:9383
2021-05-04 23:02:12.307 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.lock.RedisLockTest LN:50 count = 10000
10个线程每个累加1000为: = 10000
运行的时长为(ms):827.0
每一次执行的时长为(ms):0.0827
STW导致的锁过期问题
下面有一个简单的使用锁的例子,在10秒内占着锁:
//写数据到文件
function writeData(filename, data) {
boolean locked = lock.tryLock(10, TimeUnit.SECONDS);
if (!locked) {
throw 'Failed to acquire lock';
}
try {
//将数据写到文件
var file = storage.readFile(filename);
var updated = updateContents(file, data);
storage.writeFile(filename, updated);
} finally {
lock.unlock();
}
}
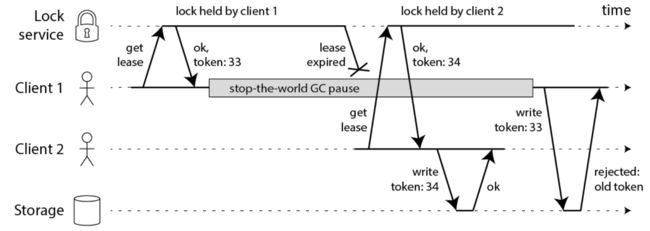
问题是:如果在写文件过程中,发生了 fullGC,并且其时间跨度较长, 超过了10秒, 那么,分布式就自动释放了。
在此过程中,client2 抢到锁,写了文件。
client1 的fullGC完成后,也继续写文件,注意,此时client1 的并没有占用锁,此时写入会导致文件数据错乱,发生线程安全问题。
这就是STW导致的锁过期问题。
STW导致的锁过期问题,具体如下图所示:

STW导致的锁过期问题,大概的解决方案,有:
1: 模拟CAS乐观锁的方式,增加版本号
2:watch dog自动延期机制
1: 模拟CAS乐观锁的方式,增加版本号(如下图中的token)
此方案如果要实现,需要调整业务逻辑,与之配合,所以会入侵代码。
2:watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
redission,采用的就是这种方案, 此方案不会入侵业务代码。
为啥推荐使用Redission
作为 Java 开发人员,我们若想在程序中集成 Redis,必须使用 Redis 的第三方库。目前大家使用的最多的第三方库是jedis。
和SpringCloud gateway一样,Redisson也是基于Netty实现的,是更高性能的第三方库。 所以,这里推荐大家使用Redission替代 jedis。
在使用Redission之前,建议大家先掌握Netty的知识。
推荐大家阅读被很多小伙伴评价为史上最为易懂的NIO、Netty书籍:《Java高并发核心编程(卷1)》
Redisson简介
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还实现了可重入锁(Reentrant Lock)、公平锁(Fair Lock、联锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)等,还提供了许多分布式服务。

Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。

Redisson与Jedis的对比
1.概况对比
Jedis是Redis的java实现的客户端,其API提供了比较全面的的Redis命令的支持,Redisson实现了分布式和可扩展的的java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序,事物,管道,分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中的放在处理业务逻辑上。
2.可伸缩性
Jedis使用阻塞的I/O,且其方法调用都是同步的,程序流程要等到sockets处理完I/O才能执行,不支持异步,Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Redisson使用非阻塞的I/O和基于Netty框架的事件驱动的通信层,其方法调用时异步的。Redisson的API是线程安全的,所以操作单个Redisson连接来完成各种操作。
3.第三方框架整合
Redisson在Redis的基础上实现了java缓存标准规范;Redisson还提供了Spring Session回话管理器的实现。
Redission 的源码地址:
官网: https://redisson.org/
github: https://github.com/redisson/redisson#quick-start

特性 & 功能:
-
支持 Redis 单节点(single)模式、哨兵(sentinel)模式、主从(Master/Slave)模式以及集群(Redis Cluster)模式
-
程序接口调用方式采用异步执行和异步流执行两种方式
-
数据序列化,Redisson 的对象编码类是用于将对象进行序列化和反序列化,以实现对该对象在 Redis 里的读取和存储
-
单个集合数据分片,在集群模式下,Redisson 为单个 Redis 集合类型提供了自动分片的功能
-
提供多种分布式对象,如:Object Bucket,Bitset,AtomicLong,Bloom Filter 和 HyperLogLog 等
-
提供丰富的分布式集合,如:Map,Multimap,Set,SortedSet,List,Deque,Queue 等
-
分布式锁和同步器的实现,可重入锁(Reentrant Lock),公平锁(Fair Lock),联锁(MultiLock),红锁(Red Lock),信号量(Semaphonre),可过期性信号锁(PermitExpirableSemaphore)等
-
提供先进的分布式服务,如分布式远程服务(Remote Service),分布式实时对象(Live Object)服务,分布式执行服务(Executor Service),分布式调度任务服务(Schedule Service)和分布式映射归纳服务(MapReduce)
Redisson的使用
如何安装 Redisson
安装 Redisson 最便捷的方法是使用 Maven 或者 Gradle:
•Maven
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.4</version>
</dependency>
•Gradle
compile group: 'org.redisson', name: 'redisson', version: '3.11.4'
目前 Redisson 最新版是 3.11.4,当然你也可以通过搜索 Maven 中央仓库 mvnrepository[1] 来找到 Redisson 的各种版本。
获取RedissonClient对象
RedissonClient有多种模式,主要的模式有:
-
单节点模式
-
哨兵模式
-
主从模式
-
集群模式
首先介绍单节点模式。
单节点模式的程序化配置方法,大致如下:
Config config = new Config();
config.useSingleServer().setAddress("redis://myredisserver:6379");
RedissonClient redisson = Redisson.create(config);xxxxxxxxxx Config config = new Config();config.useSingleServer().setAddress("redis://myredisserver:6379");RedissonClient redisson = Redisson.create(config);// connects to 127.0.0.1:6379 by defaultRedissonClient redisson = Redisson.create();
SingleServerConfig singleConfig = config.useSingleServer();
SingleServerConfig类的设置参数如下:
address(节点地址)
可以通过
host:port的格式来指定节点地址。subscriptionConnectionMinimumIdleSize(发布和订阅连接的最小空闲连接数)
默认值:
1用于发布和订阅连接的最小保持连接数(长连接)。Redisson内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(发布和订阅连接池大小)
默认值:
50用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
connectionMinimumIdleSize(最小空闲连接数)
默认值:
32最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
connectionPoolSize(连接池大小)
默认值:
64连接池最大容量。连接池的连接数量自动弹性伸缩。
dnsMonitoring(是否启用DNS监测)
默认值:
false在启用该功能以后,Redisson将会监测DNS的变化情况。
dnsMonitoringInterval(DNS监测时间间隔,单位:毫秒)
默认值:
5000监测DNS的变化情况的时间间隔。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:
10000如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:
10000同节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:
3000等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:
3如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:
1500在一条命令发送失败以后,等待重试发送的时间间隔。时间单位是毫秒。
reconnectionTimeout(重新连接时间间隔,单位:毫秒)
默认值:
3000当与某个节点的连接断开时,等待与其重新建立连接的时间间隔。时间单位是毫秒。
failedAttempts(执行失败最大次数)
默认值:
3在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:
0尝试连接的数据库编号。
password(密码)
默认值:
null用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:
5每个连接的最大订阅数量。
clientName(客户端名称)
默认值:
null在Redis节点里显示的客户端名称。
sslEnableEndpointIdentification(启用SSL终端识别)
默认值:
true开启SSL终端识别能力。
sslProvider(SSL实现方式)
默认值:
JDK确定采用哪种方式(JDK或OPENSSL)来实现SSL连接。
sslTruststore(SSL信任证书库路径)
默认值:
null指定SSL信任证书库的路径。
sslTruststorePassword(SSL信任证书库密码)
默认值:
null指定SSL信任证书库的密码。
sslKeystore(SSL钥匙库路径)
默认值:
null指定SSL钥匙库的路径。
sslKeystorePassword(SSL钥匙库密码)
默认值:
null指定SSL钥匙库的密码。
SpringBoot整合Redisson
Redisson有多种模式,首先介绍单机模式的整合。
一、导入Maven依赖
org.redisson
redisson-spring-boot-starter
3.11.4
二、核心配置文件
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 5000
三、添加配置类
RedissonConfig.java
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
@Autowired
private RedisProperties redisProperties;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
String redisUrl = String.format("redis://%s:%s", redisProperties.getHost() + "", redisProperties.getPort() + "");
config.useSingleServer().setAddress(redisUrl).setPassword(redisProperties.getPassword());
config.useSingleServer().setDatabase(3);
return Redisson.create(config);
}
}
自定义starter
由于redission可以有多种模式,处于学习的目的,将多种模式封装成一个start,可以学习一下starter的制作。

封装一个RedissonManager,通过策略模式,根据不同的配置类型,创建 RedissionConfig实例,然后创建RedissionClient对象。

使用RBucket操作分布式对象
Redission模拟了Java的面向对象编程思想,可以简单理解为一切皆为对象。
每一个 Redisson 对象 实现了RObject and RExpirable 两个interfaces.
Usage example:
RObject object = redisson.get...()
object.sizeInMemory();
object.delete();
object.rename("newname");
object.isExists();
// catch expired event
object.addListener(new ExpiredObjectListener() {
...
});
// catch delete event
object.addListener(new DeletedObjectListener() {
...
});
每一个Redisson 对象的名字,就是 Redis中的 Key.
RMap map = redisson.getMap("mymap");
map.getName(); // = mymap
可以通过 RKeys 接口操作Redis中的keys.
Usage example:
RKeys keys = redisson.getKeys();
Iterable allKeys = keys.getKeys();
Iterable foundedKeys = keys.getKeysByPattern('key*');
long numOfDeletedKeys = keys.delete("obj1", "obj2", "obj3");
long deletedKeysAmount = keys.deleteByPattern("test?");
String randomKey = keys.randomKey();
long keysAmount = keys.count();
keys.flushall();
keys.flushdb();
Redisson通过RBucket接口代表可以访问任何类型的基础对象,或者普通对象。
RBucket有一系列的工具方法,如compareAndSet(),get(),getAndDelete(),getAndSet(),set(),size(),trySet()等等,用于设值/取值/获取尺寸。
RBucket普通对象的最大大小,为512兆字节。
RBucket bucket = redisson.getBucket("anyObject");
bucket.set(new AnyObject(1));
AnyObject obj = bucket.get();
bucket.trySet(new AnyObject(3));
bucket.compareAndSet(new AnyObject(4), new AnyObject(5));
bucket.getAndSet(new AnyObject(6));
下面是一个完整的实例:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRBucketExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient client = redissonManager.getRedisson();
// RList 继承了 java.util.List 接口
RBucket<String> rstring = client.getBucket("redission:test:bucket:string");
rstring.set("this is a string");
RBucket<UserDTO> ruser = client.getBucket("redission:test:bucket:user");
UserDTO dto = new UserDTO();
dto.setToken(UUID.randomUUID().toString());
ruser.set(dto);
System.out.println("string is: " + rstring.get());
System.out.println("dto is: " + ruser.get());
client.shutdown();
}
}
运行上面的代码时,可以获得以下输出:
string is: this is a string
dto is: UserDTO(id=null, userId=null, username=null, password=null, nickname=null, token=183b6eeb-65a8-4b2a-80c6-cf17c08332ce, createTime=null, updateTime=null, headImgUrl=null, mobile=null, sex=null, enabled=null, type=null, openId=null, isDel=false)

使用 RList 操作 Redis 列表
下面的代码简单演示了如何在 Redisson 中使用 RList 对象。RList 是 Java 的 List 集合的分布式并发实现。
考虑以下代码:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testListExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient client = redissonManager.getRedisson();
// RList 继承了 java.util.List 接口
RList<String> nameList = client.getList("redission:test:nameList");
nameList.clear();
nameList.add("张三");
nameList.add("李四");
nameList.add("王五");
nameList.remove(-1);
System.out.println("List size: " + nameList.size());
boolean contains = nameList.contains("李四");
System.out.println("Is list contains name '李四': " + contains);
nameList.forEach(System.out::println);
client.shutdown();
}
}
运行上面的代码时,可以获得以下输出:
List size: 2
Is list contains name '李四': true
张三
李四

使用 RMap 操作 Redis 哈希
Redisson 还包括 RMap,它是 Java Map 集合的分布式并发实现,考虑以下代码:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testListExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient client = redissonManager.getRedisson();
// RMap 继承了 java.util.concurrent.ConcurrentMap 接口
RMap<String, Object> map = client.getMap("redission:test:personalMap");
map.put("name", "张三");
map.put("address", "北京");
map.put("age", new Integer(50));
System.out.println("Map size: " + map.size());
boolean contains = map.containsKey("age");
System.out.println("Is map contains key 'age': " + contains);
String value = String.valueOf(map.get("name"));
System.out.println("Value mapped by key 'name': " + value);
client.shutdown();
}
}
运行上面的代码时,将会看到以下输出:
Map size: 3
Is map contains key 'age': true
Value mapped by key 'name': 张三

执行 Lua脚本
Lua是一种开源、简单易学、轻量小巧的脚本语言,用标准C语言编写。
其设计的目的就是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Redis从2.6版本开始支持Lua脚本,Redis使用Lua可以:
- 原子操作。Redis会将整个脚本作为一个整体执行,不会被中断。可以用来批量更新、批量插入
- 减少网络开销。多个Redis操作合并为一个脚本,减少网络时延
- 代码复用。客户端发送的脚本可以存储在Redis中,其他客户端可以根据脚本的id调用。
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testLuaExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient redisson = redissonManager.getRedisson();
redisson.getBucket("redission:test:foo").set("bar");
String r = redisson.getScript().eval(RScript.Mode.READ_ONLY,
"return redis.call('get', 'redission:test:foo')", RScript.ReturnType.VALUE);
System.out.println("foo: " + r);
// 通过预存的脚本进行同样的操作
RScript s = redisson.getScript();
// 首先将脚本加载到Redis
String sha1 = s.scriptLoad("return redis.call('get', 'redission:test:foo')");
// 返回值 res == 282297a0228f48cd3fc6a55de6316f31422f5d17
System.out.println("sha1: " + sha1);
// 再通过SHA值调用脚本
Future<Object> r1 = redisson.getScript().evalShaAsync(RScript.Mode.READ_ONLY,
sha1,
RScript.ReturnType.VALUE,
Collections.emptyList());
try {
System.out.println("res: " + r1.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
client.shutdown();
}
}
运行上面的代码时,将会看到以下输出:
foo: bar
sha1: 282297a0228f48cd3fc6a55de6316f31422f5d17
res: bar
使用 RLock 实现 Redis 分布式锁
RLock 是 Java 中可重入锁的分布式实现,下面的代码演示了 RLock 的用法:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testLockExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient redisson = redissonManager.getRedisson();
// RLock 继承了 java.util.concurrent.locks.Lock 接口
RLock lock = redisson.getLock("redission:test:lock:1");
final int[] count = {
0};
int threads = 10;
ExecutorService pool = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
for (int j = 0; j < 1000; j++) {
lock.lock();
count[0]++;
lock.unlock();
}
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10个线程每个累加1000为: = " + count[0]);
//输出统计结果
float time = System.currentTimeMillis() - start;
System.out.println("运行的时长为:" + time);
System.out.println("每一次执行的时长为:" + time/count[0]);
}
}
此代码将产生以下输出:
10个线程每个累加1000为: = 10000
运行的时长为:14172.0
每一次执行的时长为:1.4172
使用 RAtomicLong 实现 Redis 原子操作
RAtomicLong 是 Java 中 AtomicLong 类的分布式“替代品”,用于在并发环境中保存长值。以下示例代码演示了 RAtomicLong 的用法:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRAtomicLongExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient redisson = redissonManager.getRedisson();
RAtomicLong atomicLong = redisson.getAtomicLong("redission:test:myLong");
// 线程数
final int threads = 10;
// 每条线程的执行轮数
final int turns = 1000;
ExecutorService pool = Executors.newFixedThreadPool(threads);
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
atomicLong.incrementAndGet();
}
} catch (Exception e)
{
e.printStackTrace();
}
});
}
ThreadUtil.sleepSeconds(5);
System.out.println("atomicLong: " + atomicLong.get());
redisson.shutdown();
}
}
此代码的输出将是:
atomicLong: 10000

整长型累加器(LongAdder)
基于Redis的Redisson分布式整长型累加器(LongAdder)采用了与java.util.concurrent.atomic.LongAdder类似的接口。通过利用客户端内置的LongAdder对象,为分布式环境下递增和递减操作提供了很高得性能。据统计其性能最高比分布式AtomicLong对象快 12000 倍。
完美适用于分布式统计计量场景。下面是RLongAdder的使用案例:
RLongAdder atomicLong = redisson.getLongAdder("myLongAdder");
atomicLong.add(12);
atomicLong.increment();
atomicLong.decrement();
atomicLong.sum();
以下示例代码演示了 RLongAdder 的用法:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRAtomicLongExamples() {
// 默认连接上 127.0.0.1:6379
RedissonClient redisson = redissonManager.getRedisson();
RAtomicLong atomicLong = redisson.getAtomicLong("redission:test:myLong");
// 线程数
final int threads = 10;
// 每条线程的执行轮数
final int turns = 1000;
ExecutorService pool = Executors.newFixedThreadPool(threads);
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
atomicLong.incrementAndGet();
}
} catch (Exception e)
{
e.printStackTrace();
}
});
}
ThreadUtil.sleepSeconds(5);
System.out.println("atomicLong: " + atomicLong.get());
redisson.shutdown();
}
}
此代码将产生以下输出:
longAdder: 10000
运行的时长为:5085.0
每一次执行的时长为:0.5085
当不再使用整长型累加器对象的时候应该自行手动销毁,如果Redisson对象被关闭(shutdown)了,则不用手动销毁。
RLongAdder atomicLong = ...
atomicLong.destroy();
序列化
Redisson的对象编码类是用于将对象进行序列化和反序列化,以实现对该对象在Redis里的读取和存储。Redisson提供了以下几种的对象编码应用,以供大家选择:
| 编码类名称 | 说明 |
|---|---|
org.redisson.codec.JsonJacksonCodec |
Jackson JSON 编码 默认编码 |
org.redisson.codec.AvroJacksonCodec |
Avro 一个二进制的JSON编码 |
org.redisson.codec.SmileJacksonCodec |
Smile 另一个二进制的JSON编码 |
org.redisson.codec.CborJacksonCodec |
CBOR 又一个二进制的JSON编码 |
org.redisson.codec.MsgPackJacksonCodec |
MsgPack 再来一个二进制的JSON编码 |
org.redisson.codec.IonJacksonCodec |
Amazon Ion 亚马逊的Ion编码,格式与JSON类似 |
org.redisson.codec.KryoCodec |
Kryo 二进制对象序列化编码 |
org.redisson.codec.SerializationCodec |
JDK序列化编码 |
org.redisson.codec.FstCodec |
FST 10倍于JDK序列化性能而且100%兼容的编码 |
org.redisson.codec.LZ4Codec |
LZ4 压缩型序列化对象编码 |
org.redisson.codec.SnappyCodec |
Snappy 另一个压缩型序列化对象编码 |
org.redisson.client.codec.JsonJacksonMapCodec |
基于Jackson的映射类使用的编码。可用于避免序列化类的信息,以及用于解决使用byte[]遇到的问题。 |
org.redisson.client.codec.StringCodec |
纯字符串编码(无转换) |
org.redisson.client.codec.LongCodec |
纯整长型数字编码(无转换) |
org.redisson.client.codec.ByteArrayCodec |
字节数组编码 |
org.redisson.codec.CompositeCodec |
用来组合多种不同编码在一起 |
由Redisson默认的编码器为二进制编码器,为了序列化后的内容可见,需要使用Json文本序列化编码工具类。Redisson提供了编码器 JsonJacksonCodec,作为Json文本序列化编码工具类。
问题是:JsonJackson在序列化有双向引用的对象时,会出现无限循环异常。而fastjson在检查出双向引用后会自动用引用符$ref替换,终止循环。
所以,一些特殊场景中:用fastjson能 正常序列化到redis,而JsonJackson则抛出无限循环异常。
为了序列化后的内容可见,所以不用redission其他自带的,自行实现fastjson编码器:
package com.crayon.distributedredissionspringbootstarter.codec;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufInputStream;
import io.netty.buffer.ByteBufOutputStream;
import org.redisson.client.codec.BaseCodec;
import org.redisson.client.protocol.Decoder;
import org.redisson.client.protocol.Encoder;
import java.io.IOException;
public class FastjsonCodec extends BaseCodec {
private final Encoder encoder = in -> {
ByteBuf out = ByteBufAllocator.DEFAULT.buffer();
try {
ByteBufOutputStream os = new ByteBufOutputStream(out);
JSON.writeJSONString(os, in, SerializerFeature.WriteClassName);
return os.buffer();
} catch (IOException e) {
out.release();
throw e;
} catch (Exception e) {
out.release();
throw new IOException(e);
}
};
private final Decoder<Object> decoder = (buf, state) ->
JSON.parseObject(new ByteBufInputStream(buf), Object.class);
@Override
public Decoder<Object> getValueDecoder() {
return decoder;
}
@Override
public Encoder getValueEncoder() {
return encoder;
}
}
替换的方法如下:
*/
@Slf4j
public class StandaloneConfigImpl implements RedissonConfigService {
@Override
public Config createRedissonConfig(RedissonConfig redissonConfig) {
Config config = new Config();
try {
String address = redissonConfig.getAddress();
String password = redissonConfig.getPassword();
int database = redissonConfig.getDatabase();
String redisAddr = GlobalConstant.REDIS_CONNECTION_PREFIX.getConstant_value() + address;
config.useSingleServer().setAddress(redisAddr);
config.useSingleServer().setDatabase(database);
//密码可以为空
if (!StringUtils.isEmpty(password)) {
config.useSingleServer().setPassword(password);
}
log.info("初始化[单机部署]方式Config,redisAddress:" + address);
// config.setCodec( new FstCodec());
config.setCodec( new FastjsonCodec());
} catch (Exception e) {
log.error("单机部署 Redisson init error", e);
}
return config;
}
}
哨兵模式
哨兵模式即sentinel模式,配置Redis哨兵服务的官方文档在这里。
哨兵模式实现代码和单机模式几乎一样,唯一的不同就是Config的构造.
程序化配置哨兵模式的方法如下:
Config config = new Config();
config.useSentinelServers()
.setMasterName("mymaster")
// use "rediss://" for SSL connection
.addSentinelAddress("redis://127.0.0.1:26389", "redis://127.0.0.1:26379")
.addSentinelAddress("redis://127.0.0.1:26319");
RedissonClient redisson = Redisson.create(config);
Redisson的哨兵模式的使用方法如下:
SentinelServersConfig sentinelConfig = config.useSentinelServers();
SentinelServersConfig配置参数如下:
配置Redis哨兵服务的官方文档在这里。Redisson的哨兵模式的使用方法如下:
SentinelServersConfig sentinelConfig = config.useSentinelServers();
SentinelServersConfig类的设置参数如下:dnsMonitoringInterval(DNS监控间隔,单位:毫秒)
默认值:
5000用来指定检查节点DNS变化的时间间隔。使用的时候应该确保JVM里的DNS数据的缓存时间保持在足够低的范围才有意义。用
-1来禁用该功能。masterName(主服务器的名称)
主服务器的名称是哨兵进程中用来监测主从服务切换情况的。
addSentinelAddress(添加哨兵节点地址)
可以通过
host:port的格式来指定哨兵节点的地址。多个节点可以一次性批量添加。readMode(读取操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里读取)注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里读取。MASTER- 只在主服务节点里读取。MASTER_SLAVE- 在主从服务节点里都可以读取。subscriptionMode(订阅操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里订阅)设置订阅操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里订阅。MASTER- 只在主服务节点里订阅。loadBalancer(负载均衡算法类的选择)
默认值:
org.redisson.connection.balancer.RoundRobinLoadBalancer在使用多个Redis服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点:
org.redisson.connection.balancer.WeightedRoundRobinBalancer- 权重轮询调度算法org.redisson.connection.balancer.RoundRobinLoadBalancer- 轮询调度算法org.redisson.connection.balancer.RandomLoadBalancer- 随机调度算法subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:
1多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:
50多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:
32多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:
64多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:
32多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:
64主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:
10000如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:
10000同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:
3000等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:
3如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:
1500在一条命令发送失败以后,等待重试发送的时间间隔。时间单位是毫秒。
reconnectionTimeout(重新连接时间间隔,单位:毫秒)
默认值:
3000当与某个节点的连接断开时,等待与其重新建立连接的时间间隔。时间单位是毫秒。
failedAttempts(执行失败最大次数)
默认值:
3在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:
0尝试连接的数据库编号。
password(密码)
默认值:
null用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:
5每个连接的最大订阅数量。
clientName(客户端名称)
默认值:
null在Redis节点里显示的客户端名称。
sslEnableEndpointIdentification(启用SSL终端识别)
默认值:
true开启SSL终端识别能力。
sslProvider(SSL实现方式)
默认值:
JDK确定采用哪种方式(JDK或OPENSSL)来实现SSL连接。
sslTruststore(SSL信任证书库路径)
默认值:
null指定SSL信任证书库的路径。
sslTruststorePassword(SSL信任证书库密码)
默认值:
null指定SSL信任证书库的密码。
sslKeystore(SSL钥匙库路径)
默认值:
null指定SSL钥匙库的路径。
sslKeystorePassword(SSL钥匙库密码)
默认值:
null指定SSL钥匙库的密码。
通过属性文件,配置的示例如下:
--- sentinelServersConfig: idleConnectionTimeout: 10000 connectTimeout: 10000 timeout: 3000 retryAttempts: 3 retryInterval: 1500 failedSlaveReconnectionInterval: 3000 failedSlaveCheckInterval: 60000 password: null subscriptionsPerConnection: 5 clientName: null loadBalancer: !{} subscriptionConnectionMinimumIdleSize: 1 subscriptionConnectionPoolSize: 50 slaveConnectionMinimumIdleSize: 24 slaveConnectionPoolSize: 64 masterConnectionMinimumIdleSize: 24 masterConnectionPoolSize: 64 readMode: "SLAVE" subscriptionMode: "SLAVE" sentinelAddresses: - "redis://127.0.0.1:26379" - "redis://127.0.0.1:26389" masterName: "mymaster" database: 0 threads: 16 nettyThreads: 32 codec: ! {} transportMode: "NIO"
主从模式
介绍配置Redis主从服务组态的文档在这里.
程序化配置主从模式的方法如下:
Config config = new Config();
config.useMasterSlaveServers()
// use "rediss://" for SSL connection
.setMasterAddress("redis://127.0.0.1:6379")
.addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
.addSlaveAddress("redis://127.0.0.1:6399");
RedissonClient redisson = Redisson.create(config);
主从模式使用到MasterSlaveServersConfig :
MasterSlaveServersConfig masterSlaveConfig = config.useMasterSlaveServers();
MasterSlaveServersConfig 类的设置参数如下:
dnsMonitoringInterval(DNS监控间隔,单位:毫秒)
默认值:
5000用来指定检查节点DNS变化的时间间隔。使用的时候应该确保JVM里的DNS数据的缓存时间保持在足够低的范围才有意义。用
-1来禁用该功能。masterAddress(主节点地址)
可以通过
host:port的格式来指定主节点地址。addSlaveAddress(添加从主节点地址)
可以通过
host:port的格式来指定从节点的地址。多个节点可以一次性批量添加。readMode(读取操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里读取)注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里读取。MASTER- 只在主服务节点里读取。MASTER_SLAVE- 在主从服务节点里都可以读取。subscriptionMode(订阅操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里订阅)设置订阅操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里订阅。MASTER- 只在主服务节点里订阅。loadBalancer(负载均衡算法类的选择)
默认值:
org.redisson.connection.balancer.RoundRobinLoadBalancer在使用多个Redis服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点:
org.redisson.connection.balancer.WeightedRoundRobinBalancer- 权重轮询调度算法org.redisson.connection.balancer.RoundRobinLoadBalancer- 轮询调度算法org.redisson.connection.balancer.RandomLoadBalancer- 随机调度算法subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:
1多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:
50多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:
32多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:
64多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:
32多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:
64主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:
10000如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:
10000同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:
3000等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:
3如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:
1500在一条命令发送失败以后,等待重试发送的时间间隔。时间单位是毫秒。
reconnectionTimeout(重新连接时间间隔,单位:毫秒)
默认值:
3000当与某个节点的连接断开时,等待与其重新建立连接的时间间隔。时间单位是毫秒。
failedAttempts(执行失败最大次数)
默认值:
3在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:
0尝试连接的数据库编号。
password(密码)
默认值:
null用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:
5每个连接的最大订阅数量。
clientName(客户端名称)
默认值:
null在Redis节点里显示的客户端名称。
sslEnableEndpointIdentification(启用SSL终端识别)
默认值:
true开启SSL终端识别能力。
sslProvider(SSL实现方式)
默认值:
JDK确定采用哪种方式(JDK或OPENSSL)来实现SSL连接。
sslTruststore(SSL信任证书库路径)
默认值:
null指定SSL信任证书库的路径。
sslTruststorePassword(SSL信任证书库密码)
默认值:
null指定SSL信任证书库的密码。
sslKeystore(SSL钥匙库路径)
默认值:
null指定SSL钥匙库的路径。
sslKeystorePassword(SSL钥匙库密码)
默认值:
null指定SSL钥匙库的密码。
集群模式
集群模式除了适用于Redis集群环境,也适用于任何云计算服务商提供的集群模式,例如AWS ElastiCache集群版、Azure Redis Cache和阿里云(Aliyun)的云数据库Redis版。
介绍配置Redis集群组态的文档在这里。 Redis集群组态的最低要求是必须有三个主节点。
集群模式构造Config如下:
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
//可以用"rediss://"来启用SSL连接
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);
集群模式使用到ClusterServersConfig :
ClusterServersConfig clusterConfig = config.useClusterServers();
ClusterServersConfig 配置参数如下:
nodeAddresses(添加节点地址)
可以通过
host:port的格式来添加Redis集群节点的地址。多个节点可以一次性批量添加。scanInterval(集群扫描间隔时间)
默认值:
1000对Redis集群节点状态扫描的时间间隔。单位是毫秒。
slots(分片数量)
默认值:
231用于指定数据分片过程中的分片数量。支持数据分片/框架结构有:集(Set)、映射(Map)、BitSet、Bloom filter, Spring Cache和Hibernate Cache等.readMode(读取操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里读取)注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里读取。MASTER- 只在主服务节点里读取。MASTER_SLAVE- 在主从服务节点里都可以读取。subscriptionMode(订阅操作的负载均衡模式)
默认值:
SLAVE(只在从服务节点里订阅)设置订阅操作选择节点的模式。可用值为:
SLAVE- 只在从服务节点里订阅。MASTER- 只在主服务节点里订阅。loadBalancer(负载均衡算法类的选择)
默认值:
org.redisson.connection.balancer.RoundRobinLoadBalancer在多Redis服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点:
org.redisson.connection.balancer.WeightedRoundRobinBalancer- 权重轮询调度算法org.redisson.connection.balancer.RoundRobinLoadBalancer- 轮询调度算法org.redisson.connection.balancer.RandomLoadBalancer- 随机调度算法subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:
1多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:
50多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:
32多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:
64多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:
32多节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:
64多主节点的环境里,每个 主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:
10000如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:
10000同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:
3000等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:
3如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:
1500在一条命令发送失败以后,等待重试发送的时间间隔。时间单位是毫秒。
reconnectionTimeout(重新连接时间间隔,单位:毫秒)
默认值:
3000当与某个节点的连接断开时,等待与其重新建立连接的时间间隔。时间单位是毫秒。
failedAttempts(执行失败最大次数)
默认值:
3在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
password(密码)
默认值:
null用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:
5每个连接的最大订阅数量。
clientName(客户端名称)
默认值:
null在Redis节点里显示的客户端名称。
sslEnableEndpointIdentification(启用SSL终端识别)
默认值:
true开启SSL终端识别能力。
sslProvider(SSL实现方式)
默认值:
JDK确定采用哪种方式(JDK或OPENSSL)来实现SSL连接。
sslTruststore(SSL信任证书库路径)
默认值:
null指定SSL信任证书库的路径。
sslTruststorePassword(SSL信任证书库密码)
默认值:
null指定SSL信任证书库的密码。
sslKeystore(SSL钥匙库路径)
默认值:
null指定SSL钥匙库的路径。
sslKeystorePassword(SSL钥匙库密码)
默认值:
null指定SSL钥匙库的密码。
简单Redision锁的原理
Redis发展到现在,几种常见的部署架构有:
- 单机模式;
- 哨兵模式;
- 集群模式;
先介绍,基于单机模式的简单Redision锁的使用。
简单Redision锁的使用
单机模式下,简单Redision锁的使用如下:
// 构造redisson实现分布式锁必要的Config
Config config = new Config();
config.useSingleServer().setAddress("redis://172.29.1.180:5379").setPassword("a123456").setDatabase(0);
// 构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 设置锁定资源名称
RLock disLock = redissonClient.getLock("DISLOCK");
//尝试获取分布式锁
boolean isLock= disLock.tryLock(500, 15000, TimeUnit.MILLISECONDS);
if (isLock) {
try {
//TODO if get lock success, do something;
Thread.sleep(15000);
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
disLock.unlock();
}
}
通过代码可知,经过Redisson的封装,实现Redis分布式锁非常方便,和显式锁的使用方法是一样的。RLock接口继承了 Lock接口。
我们再看一下Redis中的value是啥,和前文分析一样,hash结构, redis 的key就是资源名称。
hash结构的key就是UUID+threadId,hash结构的value就是重入值,在分布式锁时,这个值为1(Redisson还可以实现重入锁,那么这个值就取决于重入次数了):
172.29.1.180:5379> hgetall DISLOCK
1) "01a6d806-d282-4715-9bec-f51b9aa98110:1"
2) "1"
使用客户端工具看到的效果如下:

getLock()方法

可以看到,调用getLock()方法后实际返回一个RedissonLock对象
tryLock方法
下面来看下tryLock方法,源码如下:
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
current = System.currentTimeMillis();
RFuture subscribeFuture = subscribe(threadId);
if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.onComplete((res, e) -> {
if (e == null) {
unsubscribe(subscribeFuture, threadId);
}
});
}
acquireFailed(threadId);
return false;
}
try {
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
}
} finally {
unsubscribe(subscribeFuture, threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}
以上代码使用了异步回调模式,RFuture 继承了 java.util.concurrent.Future, CompletionStage两大接口,异步回调模式的基础知识,请参见 《Java高并发核心编程 卷2 》

tryAcquire()方法
在RedissonLock对象的lock()方法主要调用tryAcquire()方法

tryLockInnerAsync
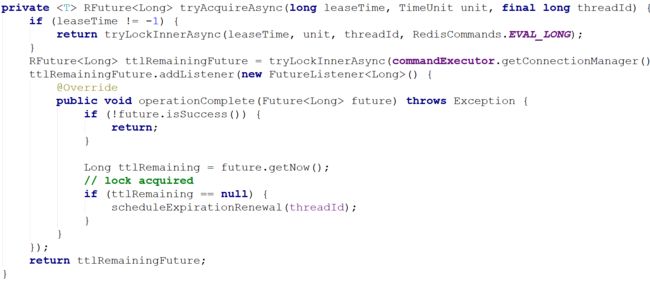
由于leaseTime == -1,于是走tryLockInnerAsync()方法,这个方法才是关键
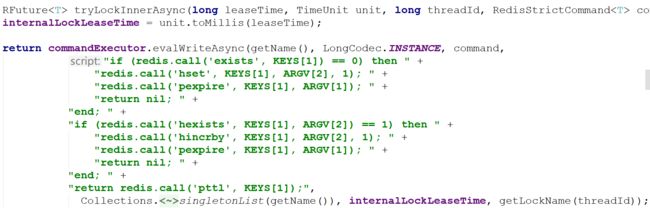
首先,看一下evalWriteAsync方法的定义
RFuture evalWriteAsync(String key, Codec codec, RedisCommand evalCommandType, String script, List 这和前面的jedis调用lua脚本类似,最后两个参数分别是keys和params。
单独将调用的那一段摘出来看,实际调用是这样的:
commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.结合上面的参数声明,我们可以知道,这里KEYS[1]就是getName(),ARGV[2]是getLockName(threadId)
假设:
- 前面获取锁时传的name是“DISLOCK”,
- 假设调用的线程ID是1,
- 假设成员变量UUID类型的id是01a6d806-d282-4715-9bec-f51b9aa98110
那么KEYS[1]=DISLOCK,ARGV[2]=01a6d806-d282-4715-9bec-f51b9aa98110:1
因此,这段脚本的意思是
1、判断有没有一个叫“DISLOCK”的key
2、如果没有,则在其下设置一个字段为“01a6d806-d282-4715-9bec-f51b9aa98110:1”,值为“1”的键值对 ,并设置它的过期时间
3、如果存在,则进一步判断“01a6d806-d282-4715-9bec-f51b9aa98110:1”是否存在,若存在,则其值加1,并重新设置过期时间
4、返回“DISLOCK”的生存时间(毫秒)
原理:加锁机制
这里用的数据结构是hash,hash的结构是: key 字段1 值1 字段2 值2 。。。
用在锁这个场景下,key就表示锁的名称,也可以理解为临界资源,字段就表示当前获得锁的线程
所有竞争这把锁的线程都要判断在这个key下有没有自己线程的字段,如果没有则不能获得锁,如果有,则相当于重入,字段值加1(次数)

Lua脚本的详解
为何要使用lua语言?
因为一大堆复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性

回顾一下evalWriteAsync方法的定义
RFuture evalWriteAsync(String key, Codec codec, RedisCommand evalCommandType, String script, List 注意,其最后两个参数分别是keys和params。
关于 lua脚本的参数解释:
**KEYS[1]**代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock(“DISLOCK”);
这里你自己设置了加锁的那个锁key就是“DISLOCK”。
**ARGV[1]**代表的就是锁key的默认生存时间
调用的时候,传递的参数为 internalLockLeaseTime ,该值默认30秒。
**ARGV[2]**代表的是加锁的客户端的ID,类似于下面这样:
01a6d806-d282-4715-9bec-f51b9aa98110:1
lua脚本的第一段if判断语句,就是用“exists DISLOCK”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的redis命令:
hset DISLOCK 01a6d806-d282-4715-9bec-f51b9aa98110:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
DISLOCK:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
}
接着会执行“pexpire DISLOCK 30000”命令,设置DISLOCK这个锁key的生存时间是30秒(默认)
锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists DISLOCK”,发现DISLOCK 这个锁key已经存在了。
接着第二个if判断,判断一下,DISLOCK锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl DISLOCK返回的一个数字,这个数字代表了DISLOCK 这个锁key的**剩余生存时间。**比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
可重入加锁机制
如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
RLock lock = redisson.getLock("DISLOCK")
lock.lock();
//业务代码
lock.lock();
//业务代码
lock.unlock();
lock.unlock();
分析上面那段lua脚本。
第一个if判断肯定不成立,“exists DISLOCK”会显示锁key已经存在了。
第二个if判断会成立,因为DISLOCK的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby DISLOCK
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时DISLOCK数据结构变为下面这样:
DISLOCK:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 2
}
释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对DISLOCK数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del DISLOCK”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
unlock 源码
@Override
public void unlock() {
try {
get(unlockAsync(Thread.currentThread().getId()));
} catch (RedisException e) {
if (e.getCause() instanceof IllegalMonitorStateException) {
throw (IllegalMonitorStateException) e.getCause();
} else {
throw e;
}
}
// Future future = unlockAsync();
// future.awaitUninterruptibly();
// if (future.isSuccess()) {
// return;
// }
// if (future.cause() instanceof IllegalMonitorStateException) {
// throw (IllegalMonitorStateException)future.cause();
// }
// throw commandExecutor.convertException(future);
}
再深入一下,实际调用的是unlockInnerAsync方法
unlockInnerAsync方法

原理:Redision 解锁机制
上图没有截取完整,完整的源码如下:
protected RFuture unlockInnerAsync(long threadId) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays. 我们还是假设name=DISLOCK,假设线程ID是1
同理,我们可以知道
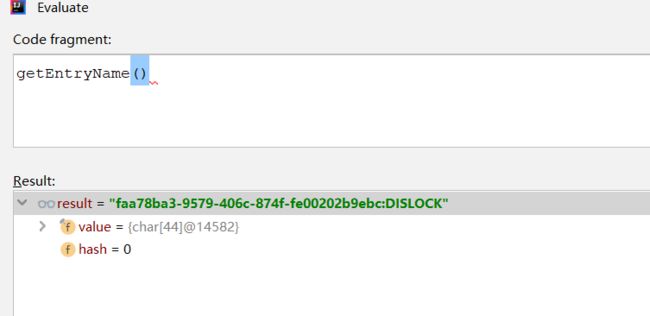
KEYS[1]是getName(),即KEYS[1]=DISLOCK
KEYS[2]是getChannelName(),即KEYS[2]=redisson_lock__channel:{DISLOCK}
ARGV[1]是LockPubSub.unlockMessage,即ARGV[1]=0
ARGV[2]是生存时间
ARGV[3]是getLockName(threadId),即ARGV[3]=8743c9c0-0795-4907-87fd-6c719a6b4586:1
因此,上面脚本的意思是:
1、判断是否存在一个叫“DISLOCK”的key
2、如果不存在,返回nil
3、如果存在,使用Redis Hincrby 命令用于为哈希表中的字段值加上指定增量值 -1 ,代表减去1
4、若counter >,返回空,若字段存在,则字段值减1
5、若减完以后,counter > 0 值仍大于0,则返回0
6、减完后,若字段值小于或等于0,则用 publish 命令广播一条消息,广播内容是0,并返回1;
可以猜测,广播0表示资源可用,即通知那些等待获取锁的线程现在可以获得锁了

通过redis Channel 解锁订阅
以上是正常情况下获取到锁的情况,那么当无法立即获取到锁的时候怎么办呢?
再回到前面获取锁的位置
@Override
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
// 订阅
RFuture future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
protected static final LockPubSub PUBSUB = new LockPubSub();
protected RFuture subscribe(long threadId) {
return PUBSUB.subscribe(getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
protected void unsubscribe(RFuture future, long threadId) {
PUBSUB.unsubscribe(future.getNow(), getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
这里会订阅Channel,当资源可用时可以及时知道,并抢占,防止无效的轮询而浪费资源
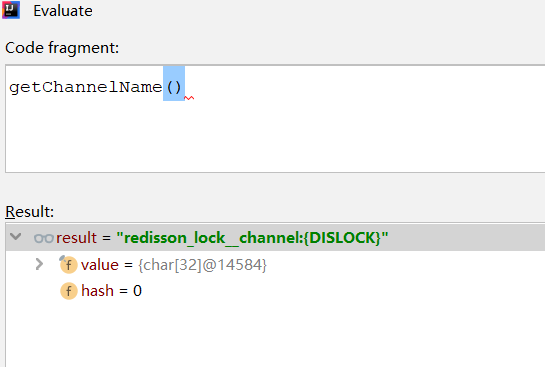
这里的channel为:
redisson_lock__channel:{DISLOCK}
当资源可用用的时候,循环去尝试获取锁,由于多个线程同时去竞争资源,所以这里用了信号量,对于同一个资源只允许一个线程获得锁,其它的线程阻塞
这点,有点儿类似 Zookeeper分布式锁:
有关zookeeper分布式锁的原理和实现,具体请参见下面的博客:
Zookeeper 分布式锁 (图解+秒懂+史上最全)
watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
使用watchDog机制实现锁的续期
但是聪明的同学肯定会问:
有效时间设置多长,假如我的业务操作比有效时间长,我的业务代码还没执行完,就自动给我解锁了,不就完蛋了吗。
这个问题就有点棘手了,在网上也有很多讨论:
第一种解决方法就是靠程序员自己去把握,预估一下业务代码需要执行的时间,然后设置有效期时间比执行时间长一些,保证不会因为自动解锁影响到客户端业务代码的执行。
但是这并不是万全之策,比如网络抖动这种情况是无法预测的,也有可能导致业务代码执行的时间变长,所以并不安全。
第二种方法,使用监事狗watchDog机制实现锁的续期。
第二种方法比较靠谱一点,而且无业务入侵。
在Redisson框架实现分布式锁的思路,就使用watchDog机制实现锁的续期。
当加锁成功后,同时开启守护线程,默认有效期是30秒,每隔10秒就会给锁续期到30秒,只要持有锁的客户端没有宕机,就能保证一直持有锁,直到业务代码执行完毕由客户端自己解锁,如果宕机了自然就在有效期失效后自动解锁。
这里,和前面解决 JVM STW的锁过期问题有点类似,只不过,watchDog自动续期,也没有完全解决JVM STW的锁过期问题。
如何彻底解决 JVM STW的锁过期问题,可以来疯狂创客圈的社群讨论。
redisson watchdog 使用和原理
实际上,redisson加锁的基本流程图如下:

这里专注于介绍watchdog。
首先watchdog的具体思路是 加锁时,默认加锁 30秒,每10秒钟检查一次,如果存在就重新设置 过期时间为30秒。
然后设置默认加锁时间的参数是 lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
官方文档描述如下
lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
默认值:
30000监控锁的看门狗超时时间单位为毫秒。该参数只适用于分布式锁的加锁请求中未明确使用
leaseTimeout参数的情况。如果该看门狗未使用lockWatchdogTimeout去重新调整一个分布式锁的lockWatchdogTimeout超时,那么这个锁将变为失效状态。这个参数可以用来避免由Redisson客户端节点宕机或其他原因造成死锁的情况。
需要注意的是
1.watchDog 只有在未显示指定加锁时间时才会生效。(这点很重要)
2.lockWatchdogTimeout设定的时间不要太小 ,比如我之前设置的是 100毫秒,由于网络直接导致加锁完后,watchdog去延期时,这个key在redis中已经被删除了。
tryAcquireAsync原理
在调用lock方法时,会最终调用到tryAcquireAsync。详细解释如下:
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
//如果指定了加锁时间,会直接去加锁
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
//没有指定加锁时间 会先进行加锁,并且默认时间就是 LockWatchdogTimeout的时间
//这个是异步操作 返回RFuture 类似netty中的future
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
//这里也是类似netty Future 的addListener,在future内容执行完成后执行
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
//这里是定时执行 当前锁自动延期的动作
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
}
scheduleExpirationRenewal 中会调用renewExpiration。
renewExpiration执行延期动作
这里我们可以看到是 启用了一个timeout定时,去执行延期动作
private void renewExpiration() {
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
//如果 没有报错,就再次定时延期
// reschedule itself
renewExpiration();
}
});
}
// 这里我们可以看到定时任务 是 lockWatchdogTimeout 的1/3时间去执行 renewExpirationAsync
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
最终 scheduleExpirationRenewal会调用到 renewExpirationAsync,
renewExpirationAsync
执行下面这段 lua脚本。他主要判断就是 这个锁是否在redis中存在,如果存在就进行 pexpire 延期。
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getName()),
internalLockLeaseTime, getLockName(threadId));
}
watchLog总结
1.要使 watchLog机制生效 ,lock时 不要设置 过期时间
2.watchlog的延时时间 可以由 lockWatchdogTimeout指定默认延时时间,但是不要设置太小。如100
3.watchdog 会每 lockWatchdogTimeout/3时间,去延时。
4.watchdog 通过 类似netty的 Future功能来实现异步延时
5.watchdog 最终还是通过 lua脚本来进行延时
Redisson框架的分布式锁
Redisson框架十分强大,除了前面介绍的 getLock方法获取的分布式锁(输入可重入锁的类型),还有很多其他的分布式锁类型。
总体的Redisson框架的分布式锁类型,大致如下:
- 可重入锁
- 公平锁
- 联锁
- 红锁
- 读写锁
- 信号量
- 可过期信号量
- 闭锁(/倒数闩)
1.可重入锁(Reentrant Lock)
Redisson的分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口,同时还支持自动过期解锁。
public void testReentrantLock(RedissonClient redisson){
RLock lock = redisson.getLock("anyLock");
try{
// 1. 最常见的使用方法
//lock.lock();
// 2. 支持过期解锁功能,10秒钟以后自动解锁, 无需调用unlock方法手动解锁
//lock.lock(10, TimeUnit.SECONDS);
// 3. 尝试加锁,最多等待3秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(3, 10, TimeUnit.SECONDS);
if(res){
//成功
// do your business
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
Redisson同时还为分布式锁提供了异步执行的相关方法:
public void testAsyncReentrantLock(RedissonClient redisson){
RLock lock = redisson.getLock("anyLock");
try{
lock.lockAsync();
lock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = lock.tryLockAsync(3, 10, TimeUnit.SECONDS);
if(res.get()){
// do your business
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
2.公平锁(Fair Lock)
Redisson分布式可重入公平锁也是实现了java.util.concurrent.locks.Lock接口的一种RLock对象。在提供了自动过期解锁功能的同时,保证了当多个Redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。
public void testFairLock(RedissonClient redisson){
RLock fairLock = redisson.getFairLock("anyLock");
try{
// 最常见的使用方法
fairLock.lock();
// 支持过期解锁功能, 10秒钟以后自动解锁,无需调用unlock方法手动解锁
fairLock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
fairLock.unlock();
}
}
Redisson同时还为分布式可重入公平锁提供了异步执行的相关方法:
RLock fairLock = redisson.getFairLock("anyLock");
fairLock.lockAsync();
fairLock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = fairLock.tryLockAsync(100, 10, TimeUnit.SECONDS);
3.联锁(MultiLock)
Redisson的RedissonMultiLock对象可以将多个RLock对象关联为一个联锁,每个RLock对象实例可以来自于不同的Redisson实例。
public void testMultiLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
try {
// 同时加锁:lock1 lock2 lock3, 所有的锁都上锁成功才算成功。
lock.lock();
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
4.红锁(RedLock)
Redisson的RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock对象关联为一个红锁,每个RLock对象实例可以来自于不同的Redisson实例。
public void testRedLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
try {
// 同时加锁:lock1 lock2 lock3, 红锁在大部分节点上加锁成功就算成功。
lock.lock();
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
5.读写锁(ReadWriteLock)
Redisson的分布式可重入读写锁RReadWriteLock,Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。同时还支持自动过期解锁。该对象允许同时有多个读取锁,但是最多只能有一个写入锁。
RReadWriteLock rwlock = redisson.getLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 支持过期解锁功能
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
6.信号量(Semaphore)
Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//或
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//或
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//或
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//或
semaphore.releaseAsync();
7.可过期性信号量(PermitExpirableSemaphore)
Redisson的可过期性信号量(PermitExpirableSemaphore)实在RSemaphore对象的基础上,为每个信号增加了一个过期时间。每个信号可以通过独立的ID来辨识,释放时只能通过提交这个ID才能释放。
RPermitExpirableSemaphore semaphore = redisson.getPermitExpirableSemaphore("mySemaphore");
String permitId = semaphore.acquire();
// 获取一个信号,有效期只有2秒钟。
String permitId = semaphore.acquire(2, TimeUnit.SECONDS);
// ...
semaphore.release(permitId);
8.闭锁/倒数闩(CountDownLatch)
Redisson的分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
redis分布式锁的高可用
关于Redis分布式锁的高可用问题,大致如下:
在master- slave的集群架构中,就是如果你对某个redis master实例,写入了DISLOCK这种锁key的value,此时会异步复制给对应的master slave实例。
但是,这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。而此时的主从复制没有彻底完成…
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致脏数据的产生。
所以这个是是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:
在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
高可用的RedLock(红锁)原理
RedLock算法思想:
不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,n / 2 + 1,必须在大多数redis节点上都成功创建锁,才能算这个整体的RedLock加锁成功,避免说仅仅在一个redis实例上加锁而带来的问题。
这个场景是假设有一个 redis cluster,有 5 个 redis master 实例。然后执行如下步骤获取一把红锁:
- 获取当前时间戳,单位是毫秒;
- 跟上面类似,轮流尝试在每个 master 节点上创建锁,过期时间较短,一般就几十毫秒;
- 尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点 n / 2 + 1;
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了;
- 要是锁建立失败了,那么就依次之前建立过的锁删除;
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。

RedLock是基于redis实现的分布式锁,它能够保证以下特性:
-
互斥性:在任何时候,只能有一个客户端能够持有锁;避免死锁:
-
当客户端拿到锁后,即使发生了网络分区或者客户端宕机,也不会发生死锁;(利用key的存活时间)
-
容错性:只要多数节点的redis实例正常运行,就能够对外提供服务,加锁或者释放锁;
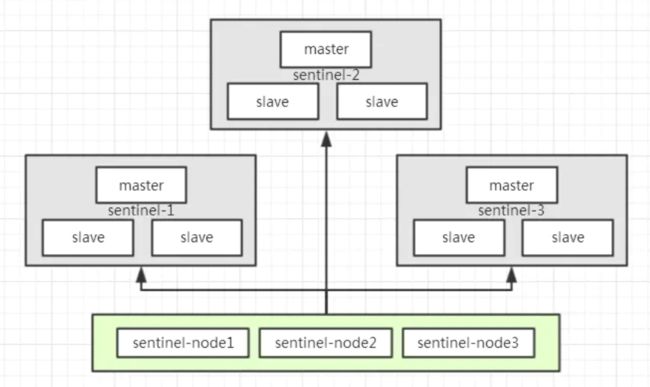
以sentinel模式架构为例,如下图所示,有sentinel-1,sentinel-2,sentinel-3总计3个sentinel模式集群,如果要获取分布式锁,那么需要向这3个sentinel集群通过EVAL命令执行LUA脚本,需要3/2+1=2,即至少2个sentinel集群响应成功,才算成功的以Redlock算法获取到分布式锁:
高可用的红锁会导致性能降低
提前说明,使用redis分布式锁,是追求高性能, 在cap理论中,追求的是 ap 而不是cp。
所以,如果追求高可用,建议使用 zookeeper分布式锁。
redis分布式锁可能导致的数据不一致性,建议使用业务补偿的方式去弥补。所以,不太建议使用红锁,但是从学习的层面来说,大家还是一定要掌握的。
实现原理
Redisson中有一个MultiLock的概念,可以将多个锁合并为一个大锁,对一个大锁进行统一的申请加锁以及释放锁
而Redisson中实现RedLock就是基于MultiLock 去做的,接下来就具体看看对应的实现吧
RedLock使用案例
先看下官方的代码使用:
(https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers#84-redlock)
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RLock redLock = anyRedisson.getRedLock(lock1, lock2, lock3);
// traditional lock method
redLock.lock();
// or acquire lock and automatically unlock it after 10 seconds
redLock.lock(10, TimeUnit.SECONDS);
// or wait for lock aquisition up to 100 seconds
// and automatically unlock it after 10 seconds
boolean res = redLock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
redLock.unlock();
}
}
这里是分别对3个redis实例加锁,然后获取一个最后的加锁结果。
RedissonRedLock实现原理
上面示例中使用redLock.lock()或者tryLock()最终都是执行RedissonRedLock中方法。
RedissonRedLock 继承自RedissonMultiLock, 实现了其中的一些方法:
public class RedissonRedLock extends RedissonMultiLock {
public RedissonRedLock(RLock... locks) {
super(locks);
}
/**
* 锁可以失败的次数,锁的数量-锁成功客户端最小的数量
*/
@Override
protected int failedLocksLimit() {
return locks.size() - minLocksAmount(locks);
}
/**
* 锁的数量 / 2 + 1,例如有3个客户端加锁,那么最少需要2个客户端加锁成功
*/
protected int minLocksAmount(final List locks) {
return locks.size()/2 + 1;
}
/**
* 计算多个客户端一起加锁的超时时间,每个客户端的等待时间
* remainTime默认为4.5s
*/
@Override
protected long calcLockWaitTime(long remainTime) {
return Math.max(remainTime / locks.size(), 1);
}
@Override
public void unlock() {
unlockInner(locks);
}
}
看到locks.size()/2 + 1 ,例如我们有3个客户端实例,那么最少2个实例加锁成功才算分布式锁加锁成功。
接着我们看下lock()的具体实现
RedissonMultiLock实现原理
public class RedissonMultiLock implements Lock {
final List locks = new ArrayList();
public RedissonMultiLock(RLock... locks) {
if (locks.length == 0) {
throw new IllegalArgumentException("Lock objects are not defined");
}
this.locks.addAll(Arrays.asList(locks));
}
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1;
if (leaseTime != -1) {
// 如果等待时间设置了,那么将等待时间 * 2
newLeaseTime = unit.toMillis(waitTime)*2;
}
// time为当前时间戳
long time = System.currentTimeMillis();
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
// 计算锁的等待时间,RedLock中:如果remainTime=-1,那么lockWaitTime为1
long lockWaitTime = calcLockWaitTime(remainTime);
// RedLock中failedLocksLimit即为n/2 + 1
int failedLocksLimit = failedLocksLimit();
List acquiredLocks = new ArrayList(locks.size());
// 循环每个redis客户端,去获取锁
for (ListIterator iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
// 调用tryLock方法去获取锁,如果获取锁成功,则lockAcquired=true
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
long awaitTime = Math.min(lockWaitTime, remainTime);
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (Exception e) {
lockAcquired = false;
}
// 如果获取锁成功,将锁加入到list集合中
if (lockAcquired) {
acquiredLocks.add(lock);
} else {
// 如果获取锁失败,判断失败次数是否等于失败的限制次数
// 比如,3个redis客户端,最多只能失败1次
// 这里locks.size = 3, 3-x=1,说明只要成功了2次就可以直接break掉循环
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
// 如果最大失败次数等于0
if (failedLocksLimit == 0) {
// 释放所有的锁,RedLock加锁失败
unlockInner(acquiredLocks);
if (waitTime == -1 && leaseTime == -1) {
return false;
}
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
// 重置迭代器 重试再次获取锁
while (iterator.hasPrevious()) {
iterator.previous();
}
} else {
// 失败的限制次数减一
// 比如3个redis实例,最大的限制次数是1,如果遍历第一个redis实例,失败了,那么failedLocksLimit会减成0
// 如果failedLocksLimit就会走上面的if逻辑,释放所有的锁,然后返回false
failedLocksLimit--;
}
}
if (remainTime != -1) {
remainTime -= (System.currentTimeMillis() - time);
time = System.currentTimeMillis();
if (remainTime <= 0) {
unlockInner(acquiredLocks);
return false;
}
}
}
if (leaseTime != -1) {
List> futures = new ArrayList>(acquiredLocks.size());
for (RLock rLock : acquiredLocks) {
RFuture future = rLock.expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);
futures.add(future);
}
for (RFuture rFuture : futures) {
rFuture.syncUninterruptibly();
}
}
return true;
}
}
核心代码都已经加了注释,实现原理其实很简单,基于RedLock思想,遍历所有的Redis客户端,然后依次加锁,最后统计成功的次数来判断是否加锁成功。
文章核心内容和源码来源
图书:《Netty Zookeeper Redis 高并发实战》 图书简介 - 疯狂创…
参考文档:
图书:《Netty Zookeeper Redis 高并发实战》 图书简介 - 疯狂创…
Distributed locks with Redis
how-to-do-distributed-locking
redisson watchdog 使用和原理
zookeeper实现分布式锁_java_脚本之家
基于Zookeeper 的分布式锁实现 - SegmentFault 思否
分布式锁用 Redis 还是 Zookeeper - 知乎
ZooKeeper分布式锁的实现原理 - 菜鸟奋斗史 - 博客园
https://blog.csdn.net/men_wen/article/details/72853078
本文的问题交流:疯狂创客圈社群
